专题六 6.4.1 统计与统计案例 课件(共60张PPT)
文档属性
| 名称 | 专题六 6.4.1 统计与统计案例 课件(共60张PPT) |  | |
| 格式 | pptx | ||
| 文件大小 | 2.7MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 人教A版(2019) | ||
| 科目 | 数学 | ||
| 更新时间 | 2022-05-20 01:08:20 | ||
图片预览









文档简介
(共60张PPT)
6.4.1 统计与统计案例
第三部分
内容索引
01
02
必备知识 精要梳理
关键能力 学案突破
必备知识 精要梳理
1.变量间的相关关系
(1)如果散点图中的点从整体上看大致分布在一条直线的附近,那么我们说变量x和y具有线性相关关系.
(2)线性回归方程:若变量x与y具有线性相关关系,有n个样本数据
(3)相关系数:r= ,当r>0时,表示两个变量正相关;当
r<0时,表示两个变量负相关.|r|越接近1,表明两个变量相关性越强;当|r|接近0时,表明两个变量几乎不存在相关性.
2.独立性检验
对于取值分别是{x1,x2}和{y1,y2}的分类变量X和Y,其样本频数列联表是:
y1 y2 总计
x1 a b a+b
x2 c d c+d
总计 a+c b+d n
关键能力 学案突破
热点一
样本的数字特征的应用
【例1】(2019全国Ⅱ,文19)某行业主管部门为了解本行业中小企业的生产情况,随机调查了100个企业,得到这些企业第一季度相对于前一年第一季度产值增长率y的频数分布表.
y的分组 [-0.20,0) [0,0.20) [0.20,0.40) [0.40,0.60) [0.60,0.80)
企业数 2 24 53 14 7
(1)分别估计这类企业中产值增长率不低于40%的企业比例、产值负增长的企业比例;
(2)求这类企业产值增长率的平均数与标准差的估计值(同一组中的数据用该组区间的中点值为代表).(精确到0.01)
解题心得(1)在预测总体数据的平均值时,常用样本数据的平均值估计,从而做出合理的判断.
(2)平均数反映了数据取值的平均水平,标准差、方差描述了一组数据围绕平均数波动的大小.标准差、方差越大,数据的离散程度越大,越不稳定.
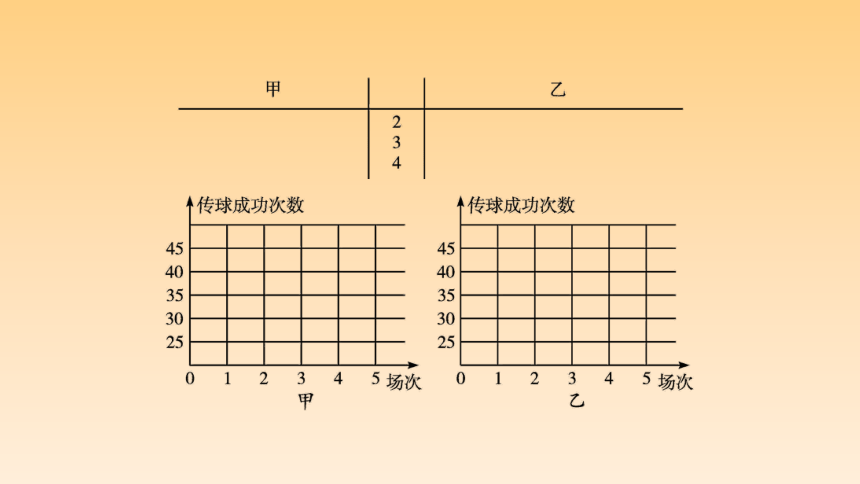
【对点训练1】(2020辽宁辽南协作校二模,18)数据的收集和整理在当今社会起到了举足轻重的作用,它用统计的方法来帮助人们分析以往的经验数据,进而指导人们接下来的行动.某支足球队的主教练打算从预备球员甲、乙两人中选一人为正式球员,他收集了甲、乙两名球员近期5场比赛的传球成功次数,如下表:
场次 第一场 第二场 第三场 第四场 第五场
甲 28 33 36 38 45
乙 39 31 43 39 33
(1)根据这两名球员近期5场比赛的传球成功次数,完成茎叶图(茎表示十位,叶表示个位);分别在平面直角坐标系中画出两名球员的传球成功次数的散点图;
(2)求出甲、乙两名球员近期5场比赛的传球成功次数的平均值和方差;
(3)主教练根据球员每场比赛的传球成功次数分析出球员在场上的积极程度和技术水平,同时根据多场比赛的数据也可以分析出球员的状态和潜力.你认为主教练应选哪位球员 并说明理由.
解 (1)茎叶图如图
散点图如图:
热点二
线性回归分析
【例2】改革开放以来,我国经济持续高速增长.如图给出了我国2003年至2012年第二产业增加值与第一产业增加值的差值(以下简称为:产业差值)的折线图,记产业差值为y(单位:万亿元).
(1)求出y关于年份代码t的线性回归方程;
(2)利用(1)中的回归方程,分析2003年至2012年我国产业差值的变化情况,并预测我国产业差值在哪一年约为34万亿元;
(3)结合折线图,试求出除去2007年产业差值后剩余的9年产业差值的平均值及方差(结果精确到0.1).
解题心得线性回归分析问题的类型及解题方法
1.求回归直线方程:
2.对变量值预测:
(1)若已知回归直线方程(方程中无参数),进而预测时,可以直接将数值代入求得特定要求下的预测值;
(2)若回归直线方程中有参数,则根据回归直线一定经过点( ),求出参数值,得到回归直线方程,进而完成预测.
【对点训练2】(2020河北石家庄模拟,19)下表是我国大陆地区从2013年至2019年国内生产总值(GDP)近似值(单位:万亿元人民币)的数据表格:
年份 2013 2014 2015 2016 2017 2018 2019
年份代号x 1 2 3 4 5 6 7
中国大陆地区GDP:y(单位:万亿元人民币) 59.3 64.1 68.6 74.0 82.1 90.0 99.1
(1)判断y=b1x+a1与y=a2+b2ln x哪一个更适宜作为国内生产总值(GDP)近似值y关于年份代号x的回归方程,并说明理由;
(2)根据(1)的判断结果及表中数据,求出y关于年份代号x的回归方程(系数精确到0.01);
(3)党的十九大报告中指出:从2020年到2035年,在全面建成小康社会的基础上,再奋斗15年,基本实现社会主义现代化.若到2035年底我国人口增长为14.4亿人,假设到2035年世界主要中等发达国家的人均国民生产总值的频率直方图如图所示.
以(2)的结论为依据,预测我国在2035年底人均国民生产总值是否可以超过假设的2035年世界主要中等发达国家的人均国民生产总值平均数的估计值.
(3)到2035年底对应的年份代号为23,由(2)的回归方程 =6.60x+50.36得我国国内生产总值约为6.60×23+50.36=202.16(万亿元人民币),又14.04,所以到2035年底我国人均国民生产总值约为14.04万元人民币,由直方图,假设的2035年世界主要中等发达国家的人均国民生产总值平均数的估计值为7.5×0.3+12.5×0.35+17.5×0.2+22.5×0.1+27.5×0.05=13.75,又13.75<14.04,所以以(2)的结论为依据,可预测我国在2035年底人均国民生产总值可以超过假设的2035年世界主要中等发达国家的人均国民生产总值平均数的估计值.
热点三
非线性回归分析
【例3】(2020山东聊城二模,21)个人所得税是国家对本国公民、居住在本国境内的个人的所得和境外个人来源于本国的所得征收的一种所得税.我国在1980年9月10日第五届全国人民代表大会第三次会议通过并公布了《中华人民共和国个人所得税法》.公民依法诚信纳税是义务,更是责任.现将自2013年至2017年的个人所得税收入统计如下:
年份 2013 2014 2015 2016 2017
时间代号x 1 2 3 4 5
个税收入y(千亿元) 6.53 7.38 8.62 10.09 11.97
并制作了时间代号x与个人所得税收入的如图所示的散点图:
根据散点图判断,可用①y=menx与②y=px2+q作为年个人所得税收入y关于时间代号x的回归方程,经过数据运算和处理,得到如下数据:
以下计算过程中四舍五入保留两位小数.
(1)根据所给数据,分别求出①,②中y关于x的回归方程;
(2)已知2018年个人所得税收入为13.87千亿元,用2018年的数据验证(1)中所得的两个回归方程,哪个更适宜作为y关于时间代号x的回归方程
(3)你还能从统计学哪些角度来进一步确认哪个回归方程更适宜 (只需叙述,不必计算)
附:对于一组数据(u1,y1),(u2,y2),…,(un,yn)其回归直线y=α+βu的斜率和截距
(3)还可以计算两个回归方程的残差,残差的平方和越小,拟合效果越好.
解题心得非线性回归方程的求法:
(1)根据原始数据做出散点图;
(2)根据散点图,选择恰当的拟合函数;
(3)作恰当变换,将其转化成线性函数,求线性回归方程;
(4)在(3)的基础上通过相应变换,即可得非线性回归方程.
【对点训练3】某公司为确定下一年度投入某种产品的宣传费,需了解年宣传费x(单位:千元)对年销售量y(单位:t)和年利润z(单位:千元)的影响.对近8年的年宣传费xi和年销售量yi(i=1,2,…,8)数据作了初步处理,得到下面的散点图及一些统计量的值.
(1)根据散点图判断,y=a+bx与y=c+d 哪一个适宜作为年销售量y关于年宣传费x的回归方程类型 (给出判断即可,不必说明理由)
(2)根据(1)的判断结果及表中数据,建立y关于x的回归方程;
(3)已知这种产品的年利润z与x,y的关系为z=0.2y-x.根据(2)的结果回答下列问题:
①年宣传费x=49时,年销售量及年利润的预报值是多少
②年宣传费x为何值时,年利润的预报值最大
热点四
样本的相关系数的应用
【例4】(2020全国Ⅱ,理18)某沙漠地区经过治理,生态系统得到很大改善,野生动物数量有所增加,为调查该地区某种野生动物的数量,将其分成面积相近的200个地块,从这些地块中用简单随机抽样的方法抽取20个作为样区,调查得到样本数据(xi,yi)(i=1,2,…,20),其中xi和yi分别表示第i个样区的植物覆盖面积(单位:公顷)和这种野生动物的数量,并计算得
(1)求该地区这种野生动物数量的估计值(这种野生动物数量的估计值等于样区这种野生动物数量的平均数乘以地块数);
(2)求样本(xi,yi)(i=1,2,…,20)的相关系数(精确到0.01);
(3)根据现有统计资料,各地块间植物覆盖面积差异很大.为提高样本的代表性以获得该地区这种野生动物数量更准确的估计,请给出一种你认为更合理的抽样方法.并说明理由.
(3)分层抽样:根据植物覆盖面积的大小对地块分层,再对200个地块进行分层抽样.
理由如下:由(2)知各样区的这种野生动物数量与植物覆盖面积有很强的正相关.由于各地块间植物覆盖面积差异很大,从而各地块间这种野生动物数量差异也很大,采用分层抽样的方法较好地保持了样本结构与总体结构的一致性,提高了样本的代表性,从而可以获得该地区这种野生动物数量更准确的估计.
解题心得对于样本的相关系数的应用题目,题目一般都给出样本(xi,yi)(i=1,2,…,n)的相关系数r的表达式,以及有关的数据,解决这类题的关键是在有关的数据中选择题目需要的数据代入公式即可.
【对点训练4】(2020河北唐山高三联考,19)近年来,共享单车在我国各城市迅猛发展,为人们的出行提供了便利,但也给城市的交通管理带来了一些困难,为掌握共享单车在C省的发展情况,某调查机构从该省抽取了5个城市,并统计了共享单车的A指标x和B指标y,数据如下表所示:
城市1 城市2 城市3 城市4 城市5
A指标 2 4 5 6 8
B指标 3 4 4 4 5
(1)试求y与x间的相关系数r,并说明y与x是否具有较强的线性相关关系(若|r|≥0.75,则认为y与x具有较强的线性相关关系,否则认为没有较强的线性相关关系).
(2)建立y关于x的回归方程,并预测当A指标为7时,B指标的估计值.
(3)若某城市的共享单车A指标x在区间 的右侧,则认为该城市共享单车数量过多,对城市的交通管理有较大的影响,交通管理部门将进行治理,直至A指标x在区间 内.现在已知C省某城市共享单车的A指标为13,则该城市的交通管理部门是否需要进行治理 试说明理由.
热点五
独立性检验
【例5】(2020河北衡水中学高三调研,19)某城市先后采用甲、乙两种方案治理空气污染各一年,各自随机抽取一年(365天)内100天的空气质量指数API的检测数据进行分析,若空气质量指数值在[0,300]内为合格,否则为不合格.表1是甲方案检测数据样本的频数分布表,如图是乙方案检测数据样本的频率分布直方图.
表1:
API值 [0,50] (50,100] (100,150] (150,200] (200,250] (250,300] 大于300
天数 9 13 19 30 14 11 4
(1)将频率视为概率,求乙方案样本的频率分布直方图中a的值,以及乙方案样本的空气质量不合格天数;
(2)求乙方案样本的中位数;
(3)填写下面2×2列联表(表2),并根据列联表判断是否有90%的把握认为该城市的空气质量指数值与两种方案的选择有关.
表2:
甲方案 乙方案 合计
合格天数
不合格天数
合计
P(K2≥k) 0.10 0.05 0.025
k 2.706 3.841 5.024
解 (1)由频率分布直方图知,(0.001 0+0.003 0+0.004 0+0.005 0+0.003 0
+0.001 8+a)×50=1,解得a=0.002 2,
∴乙方案样本中不合格天数为0.002 2×50×100=11(天);
(2)根据题中的频率分布直方图,得(0.001 0+0.003 0+0.004 0)×50=0.4,又0.005 0×50=0.25,∵0.4+0.25=0.65,∴中位数在(150,200]之间,设中位数为x,则0.4+(x-150)×0.005 0=0.5,解得x=170,∴乙方案样本的中位数为170;
(3)由题意填写2×2列联表如下,
甲方案 乙方案 合计
合格天数 96 89 185
不合格天数 4 11 15
合计 100 100 200
∵3.532>2.706,∴有90%的把握认为该城市的空气质量指数值与两种方案的选择有关.
解题心得有关独立性检验的问题解题步骤:(1)作出2×2列联表;(2)计算随机变量K2的值;(3)查临界值,检验作答.
【对点训练5】(2020山东,19)为加强环境保护,治理空气污染,环境监测部门对某市空气质量进行调研,随机抽查了100天空气中的PM2.5和SO2浓度(单位:μg/m3),得下表:
SO2 PM2.5 [0,50] (50,150] (150,475]
[0,35] 32 18 4
(35,75] 6 8 12
(75,115] 3 7 10
(1)估计事件“该市一天空气中PM2.5浓度不超过75,且SO2浓度不超过150”的概率;
(2)根据所给数据,完成下面的2×2列联表:
SO2 PM2.5 [0,150] (150,475]
[0,75]
(75,115]
(3)根据(2)中的列联表,判断是否有99%的把握认为该市一天空气中PM2.5浓度与SO2浓度有关
P(K2≥k) 0.050 0.010 0.001
k 3.841 6.635 10.828
解 (1)根据抽查数据,该市100天空气中PM2.5浓度不超过75,且SO2浓度不超过150的天数为32+18+6+8=64,因此,该市一天空气中PM2.5浓度不超过75,且SO2浓度不超过150的概率的估计值为
(2)根据抽查数据,可得2×2列联表:
SO2 PM2.5 [0,150] (150,475]
[0,75] 64 16
(75,115] 10 10
由于7.484>6.635,故有99%的把握认为该市一天空气中PM2.5浓度与SO2浓度有关.
6.4.1 统计与统计案例
第三部分
内容索引
01
02
必备知识 精要梳理
关键能力 学案突破
必备知识 精要梳理
1.变量间的相关关系
(1)如果散点图中的点从整体上看大致分布在一条直线的附近,那么我们说变量x和y具有线性相关关系.
(2)线性回归方程:若变量x与y具有线性相关关系,有n个样本数据
(3)相关系数:r= ,当r>0时,表示两个变量正相关;当
r<0时,表示两个变量负相关.|r|越接近1,表明两个变量相关性越强;当|r|接近0时,表明两个变量几乎不存在相关性.
2.独立性检验
对于取值分别是{x1,x2}和{y1,y2}的分类变量X和Y,其样本频数列联表是:
y1 y2 总计
x1 a b a+b
x2 c d c+d
总计 a+c b+d n
关键能力 学案突破
热点一
样本的数字特征的应用
【例1】(2019全国Ⅱ,文19)某行业主管部门为了解本行业中小企业的生产情况,随机调查了100个企业,得到这些企业第一季度相对于前一年第一季度产值增长率y的频数分布表.
y的分组 [-0.20,0) [0,0.20) [0.20,0.40) [0.40,0.60) [0.60,0.80)
企业数 2 24 53 14 7
(1)分别估计这类企业中产值增长率不低于40%的企业比例、产值负增长的企业比例;
(2)求这类企业产值增长率的平均数与标准差的估计值(同一组中的数据用该组区间的中点值为代表).(精确到0.01)
解题心得(1)在预测总体数据的平均值时,常用样本数据的平均值估计,从而做出合理的判断.
(2)平均数反映了数据取值的平均水平,标准差、方差描述了一组数据围绕平均数波动的大小.标准差、方差越大,数据的离散程度越大,越不稳定.
【对点训练1】(2020辽宁辽南协作校二模,18)数据的收集和整理在当今社会起到了举足轻重的作用,它用统计的方法来帮助人们分析以往的经验数据,进而指导人们接下来的行动.某支足球队的主教练打算从预备球员甲、乙两人中选一人为正式球员,他收集了甲、乙两名球员近期5场比赛的传球成功次数,如下表:
场次 第一场 第二场 第三场 第四场 第五场
甲 28 33 36 38 45
乙 39 31 43 39 33
(1)根据这两名球员近期5场比赛的传球成功次数,完成茎叶图(茎表示十位,叶表示个位);分别在平面直角坐标系中画出两名球员的传球成功次数的散点图;
(2)求出甲、乙两名球员近期5场比赛的传球成功次数的平均值和方差;
(3)主教练根据球员每场比赛的传球成功次数分析出球员在场上的积极程度和技术水平,同时根据多场比赛的数据也可以分析出球员的状态和潜力.你认为主教练应选哪位球员 并说明理由.
解 (1)茎叶图如图
散点图如图:
热点二
线性回归分析
【例2】改革开放以来,我国经济持续高速增长.如图给出了我国2003年至2012年第二产业增加值与第一产业增加值的差值(以下简称为:产业差值)的折线图,记产业差值为y(单位:万亿元).
(1)求出y关于年份代码t的线性回归方程;
(2)利用(1)中的回归方程,分析2003年至2012年我国产业差值的变化情况,并预测我国产业差值在哪一年约为34万亿元;
(3)结合折线图,试求出除去2007年产业差值后剩余的9年产业差值的平均值及方差(结果精确到0.1).
解题心得线性回归分析问题的类型及解题方法
1.求回归直线方程:
2.对变量值预测:
(1)若已知回归直线方程(方程中无参数),进而预测时,可以直接将数值代入求得特定要求下的预测值;
(2)若回归直线方程中有参数,则根据回归直线一定经过点( ),求出参数值,得到回归直线方程,进而完成预测.
【对点训练2】(2020河北石家庄模拟,19)下表是我国大陆地区从2013年至2019年国内生产总值(GDP)近似值(单位:万亿元人民币)的数据表格:
年份 2013 2014 2015 2016 2017 2018 2019
年份代号x 1 2 3 4 5 6 7
中国大陆地区GDP:y(单位:万亿元人民币) 59.3 64.1 68.6 74.0 82.1 90.0 99.1
(1)判断y=b1x+a1与y=a2+b2ln x哪一个更适宜作为国内生产总值(GDP)近似值y关于年份代号x的回归方程,并说明理由;
(2)根据(1)的判断结果及表中数据,求出y关于年份代号x的回归方程(系数精确到0.01);
(3)党的十九大报告中指出:从2020年到2035年,在全面建成小康社会的基础上,再奋斗15年,基本实现社会主义现代化.若到2035年底我国人口增长为14.4亿人,假设到2035年世界主要中等发达国家的人均国民生产总值的频率直方图如图所示.
以(2)的结论为依据,预测我国在2035年底人均国民生产总值是否可以超过假设的2035年世界主要中等发达国家的人均国民生产总值平均数的估计值.
(3)到2035年底对应的年份代号为23,由(2)的回归方程 =6.60x+50.36得我国国内生产总值约为6.60×23+50.36=202.16(万亿元人民币),又14.04,所以到2035年底我国人均国民生产总值约为14.04万元人民币,由直方图,假设的2035年世界主要中等发达国家的人均国民生产总值平均数的估计值为7.5×0.3+12.5×0.35+17.5×0.2+22.5×0.1+27.5×0.05=13.75,又13.75<14.04,所以以(2)的结论为依据,可预测我国在2035年底人均国民生产总值可以超过假设的2035年世界主要中等发达国家的人均国民生产总值平均数的估计值.
热点三
非线性回归分析
【例3】(2020山东聊城二模,21)个人所得税是国家对本国公民、居住在本国境内的个人的所得和境外个人来源于本国的所得征收的一种所得税.我国在1980年9月10日第五届全国人民代表大会第三次会议通过并公布了《中华人民共和国个人所得税法》.公民依法诚信纳税是义务,更是责任.现将自2013年至2017年的个人所得税收入统计如下:
年份 2013 2014 2015 2016 2017
时间代号x 1 2 3 4 5
个税收入y(千亿元) 6.53 7.38 8.62 10.09 11.97
并制作了时间代号x与个人所得税收入的如图所示的散点图:
根据散点图判断,可用①y=menx与②y=px2+q作为年个人所得税收入y关于时间代号x的回归方程,经过数据运算和处理,得到如下数据:
以下计算过程中四舍五入保留两位小数.
(1)根据所给数据,分别求出①,②中y关于x的回归方程;
(2)已知2018年个人所得税收入为13.87千亿元,用2018年的数据验证(1)中所得的两个回归方程,哪个更适宜作为y关于时间代号x的回归方程
(3)你还能从统计学哪些角度来进一步确认哪个回归方程更适宜 (只需叙述,不必计算)
附:对于一组数据(u1,y1),(u2,y2),…,(un,yn)其回归直线y=α+βu的斜率和截距
(3)还可以计算两个回归方程的残差,残差的平方和越小,拟合效果越好.
解题心得非线性回归方程的求法:
(1)根据原始数据做出散点图;
(2)根据散点图,选择恰当的拟合函数;
(3)作恰当变换,将其转化成线性函数,求线性回归方程;
(4)在(3)的基础上通过相应变换,即可得非线性回归方程.
【对点训练3】某公司为确定下一年度投入某种产品的宣传费,需了解年宣传费x(单位:千元)对年销售量y(单位:t)和年利润z(单位:千元)的影响.对近8年的年宣传费xi和年销售量yi(i=1,2,…,8)数据作了初步处理,得到下面的散点图及一些统计量的值.
(1)根据散点图判断,y=a+bx与y=c+d 哪一个适宜作为年销售量y关于年宣传费x的回归方程类型 (给出判断即可,不必说明理由)
(2)根据(1)的判断结果及表中数据,建立y关于x的回归方程;
(3)已知这种产品的年利润z与x,y的关系为z=0.2y-x.根据(2)的结果回答下列问题:
①年宣传费x=49时,年销售量及年利润的预报值是多少
②年宣传费x为何值时,年利润的预报值最大
热点四
样本的相关系数的应用
【例4】(2020全国Ⅱ,理18)某沙漠地区经过治理,生态系统得到很大改善,野生动物数量有所增加,为调查该地区某种野生动物的数量,将其分成面积相近的200个地块,从这些地块中用简单随机抽样的方法抽取20个作为样区,调查得到样本数据(xi,yi)(i=1,2,…,20),其中xi和yi分别表示第i个样区的植物覆盖面积(单位:公顷)和这种野生动物的数量,并计算得
(1)求该地区这种野生动物数量的估计值(这种野生动物数量的估计值等于样区这种野生动物数量的平均数乘以地块数);
(2)求样本(xi,yi)(i=1,2,…,20)的相关系数(精确到0.01);
(3)根据现有统计资料,各地块间植物覆盖面积差异很大.为提高样本的代表性以获得该地区这种野生动物数量更准确的估计,请给出一种你认为更合理的抽样方法.并说明理由.
(3)分层抽样:根据植物覆盖面积的大小对地块分层,再对200个地块进行分层抽样.
理由如下:由(2)知各样区的这种野生动物数量与植物覆盖面积有很强的正相关.由于各地块间植物覆盖面积差异很大,从而各地块间这种野生动物数量差异也很大,采用分层抽样的方法较好地保持了样本结构与总体结构的一致性,提高了样本的代表性,从而可以获得该地区这种野生动物数量更准确的估计.
解题心得对于样本的相关系数的应用题目,题目一般都给出样本(xi,yi)(i=1,2,…,n)的相关系数r的表达式,以及有关的数据,解决这类题的关键是在有关的数据中选择题目需要的数据代入公式即可.
【对点训练4】(2020河北唐山高三联考,19)近年来,共享单车在我国各城市迅猛发展,为人们的出行提供了便利,但也给城市的交通管理带来了一些困难,为掌握共享单车在C省的发展情况,某调查机构从该省抽取了5个城市,并统计了共享单车的A指标x和B指标y,数据如下表所示:
城市1 城市2 城市3 城市4 城市5
A指标 2 4 5 6 8
B指标 3 4 4 4 5
(1)试求y与x间的相关系数r,并说明y与x是否具有较强的线性相关关系(若|r|≥0.75,则认为y与x具有较强的线性相关关系,否则认为没有较强的线性相关关系).
(2)建立y关于x的回归方程,并预测当A指标为7时,B指标的估计值.
(3)若某城市的共享单车A指标x在区间 的右侧,则认为该城市共享单车数量过多,对城市的交通管理有较大的影响,交通管理部门将进行治理,直至A指标x在区间 内.现在已知C省某城市共享单车的A指标为13,则该城市的交通管理部门是否需要进行治理 试说明理由.
热点五
独立性检验
【例5】(2020河北衡水中学高三调研,19)某城市先后采用甲、乙两种方案治理空气污染各一年,各自随机抽取一年(365天)内100天的空气质量指数API的检测数据进行分析,若空气质量指数值在[0,300]内为合格,否则为不合格.表1是甲方案检测数据样本的频数分布表,如图是乙方案检测数据样本的频率分布直方图.
表1:
API值 [0,50] (50,100] (100,150] (150,200] (200,250] (250,300] 大于300
天数 9 13 19 30 14 11 4
(1)将频率视为概率,求乙方案样本的频率分布直方图中a的值,以及乙方案样本的空气质量不合格天数;
(2)求乙方案样本的中位数;
(3)填写下面2×2列联表(表2),并根据列联表判断是否有90%的把握认为该城市的空气质量指数值与两种方案的选择有关.
表2:
甲方案 乙方案 合计
合格天数
不合格天数
合计
P(K2≥k) 0.10 0.05 0.025
k 2.706 3.841 5.024
解 (1)由频率分布直方图知,(0.001 0+0.003 0+0.004 0+0.005 0+0.003 0
+0.001 8+a)×50=1,解得a=0.002 2,
∴乙方案样本中不合格天数为0.002 2×50×100=11(天);
(2)根据题中的频率分布直方图,得(0.001 0+0.003 0+0.004 0)×50=0.4,又0.005 0×50=0.25,∵0.4+0.25=0.65,∴中位数在(150,200]之间,设中位数为x,则0.4+(x-150)×0.005 0=0.5,解得x=170,∴乙方案样本的中位数为170;
(3)由题意填写2×2列联表如下,
甲方案 乙方案 合计
合格天数 96 89 185
不合格天数 4 11 15
合计 100 100 200
∵3.532>2.706,∴有90%的把握认为该城市的空气质量指数值与两种方案的选择有关.
解题心得有关独立性检验的问题解题步骤:(1)作出2×2列联表;(2)计算随机变量K2的值;(3)查临界值,检验作答.
【对点训练5】(2020山东,19)为加强环境保护,治理空气污染,环境监测部门对某市空气质量进行调研,随机抽查了100天空气中的PM2.5和SO2浓度(单位:μg/m3),得下表:
SO2 PM2.5 [0,50] (50,150] (150,475]
[0,35] 32 18 4
(35,75] 6 8 12
(75,115] 3 7 10
(1)估计事件“该市一天空气中PM2.5浓度不超过75,且SO2浓度不超过150”的概率;
(2)根据所给数据,完成下面的2×2列联表:
SO2 PM2.5 [0,150] (150,475]
[0,75]
(75,115]
(3)根据(2)中的列联表,判断是否有99%的把握认为该市一天空气中PM2.5浓度与SO2浓度有关
P(K2≥k) 0.050 0.010 0.001
k 3.841 6.635 10.828
解 (1)根据抽查数据,该市100天空气中PM2.5浓度不超过75,且SO2浓度不超过150的天数为32+18+6+8=64,因此,该市一天空气中PM2.5浓度不超过75,且SO2浓度不超过150的概率的估计值为
(2)根据抽查数据,可得2×2列联表:
SO2 PM2.5 [0,150] (150,475]
[0,75] 64 16
(75,115] 10 10
由于7.484>6.635,故有99%的把握认为该市一天空气中PM2.5浓度与SO2浓度有关.
同课章节目录