2021-2022学年高中信息技术粤教版(2019)必修1 字符编码课件-(共16张PPT)
文档属性
| 名称 | 2021-2022学年高中信息技术粤教版(2019)必修1 字符编码课件-(共16张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 907.5KB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 粤教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2021-10-13 00:00:00 | ||
图片预览




文档简介
(共16张PPT)
字符编码
1
交流过程不冲突
让计算机能读取与识别(二进制)
2
计算机中的字符要满足什么条件呢?
统一的编码
ASCii码
1,2,3,4...
a,b,c,d...
美国人民
!,$, ,~_
回车、换行...
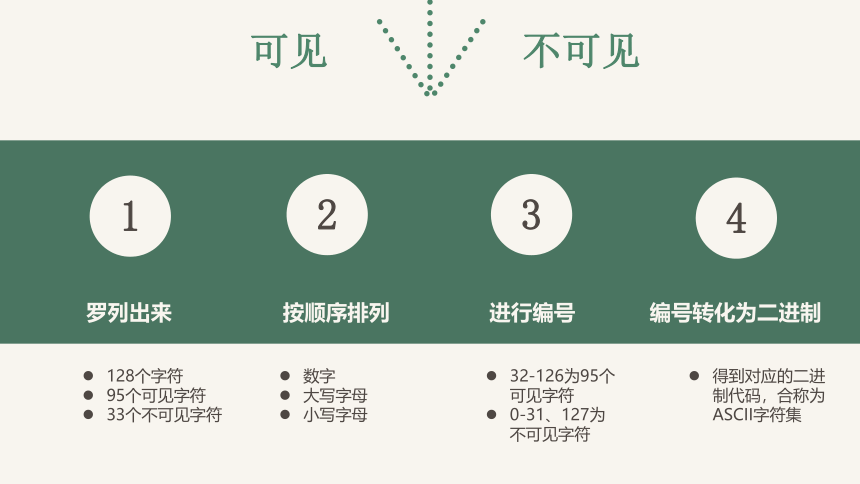
可见
1
罗列出来
128个字符
95个可见字符
33个不可见字符
按顺序排列
数字
大写字母
小写字母
2
进行编号
32-126为95个可见字符
0-31、127为不可见字符
编号转化为二进制
得到对应的二进制代码,合称为ASCII字符集
3
4
不可见
数据四
5000
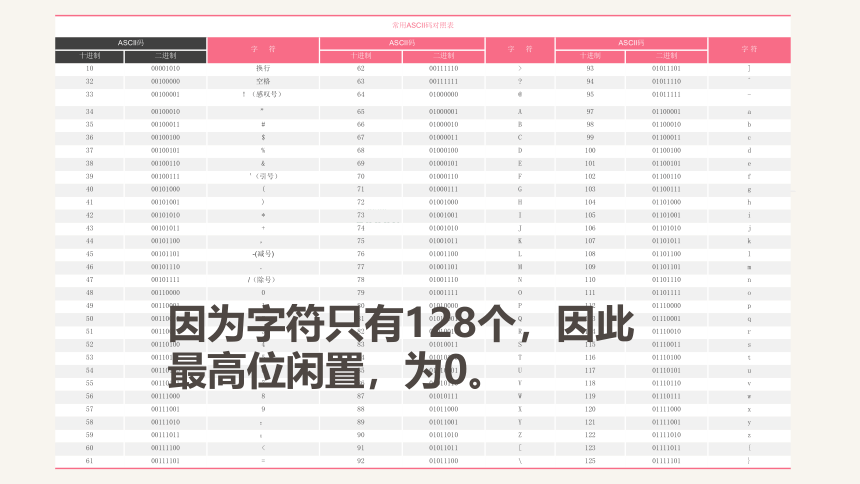
常用ASCII码对照表 ASCII码 字 符 ASCII码 字 符 ASCII码 字 符
十进制 二进制 十进制 二进制 十进制 二进制 10 00001010 换行 62 00111110 > 93 01011101 ]
32 00100000 空格 63 00111111 94 01011110 ^
33 00100001 !(感叹号) 64 01000000 @ 95 01011111 -
34 00100010 ” 65 01000001 A 97 01100001 a
35 00100011 # 66 01000010 B 98 01100010 b
36 00100100 $ 67 01000011 C 99 01100011 c
37 00100101 % 68 01000100 D 100 01100100 d
38 00100110 & 69 01000101 E 101 01100101 e
39 00100111 `(引号) 70 01000110 F 102 01100110 f
40 00101000 ( 71 01000111 G 103 01100111 g
41 00101001 ) 72 01001000 H 104 01101000 h
42 00101010 * 73 01001001 I 105 01101001 i
43 00101011 + 74 01001010 J 106 01101010 j
44 00101100 , 75 01001011 K 107 01101011 k
45 00101101 -(减号) 76 01001100 L 108 01101100 l
46 00101110 . 77 01001101 M 109 01101101 m
47 00101111 /(除号) 78 01001110 N 110 01101110 n
48 00110000 0 79 01001111 O 111 01101111 o
49 00110001 1 80 01010000 P 112 01110000 p
50 00110010 2 81 01010001 Q 113 01110001 q
51 00110011 3 82 01010010 R 114 01110010 r
52 00110100 4 83 01010011 S 115 01110011 s
53 00110101 5 84 01010100 T 116 01110100 t
54 00110110 6 85 01010101 U 117 01110101 u
55 00110111 7 86 01010110 V 118 01110110 v
56 00111000 8 87 01010111 W 119 01110111 w
57 00111001 9 88 01011000 X 120 01111000 x
58 00111010 : 89 01011001 Y 121 01111001 y
59 00111011 ; 90 01011010 Z 122 01111010 z
60 00111100 < 91 01011011 [ 123 01111011 {
61 00111101 = 92 01011100 \ 125 01111101 }
因为字符只有128个,因此最高位闲置,为0。
随着计算机的发展,计算机传入欧洲,主要有德国、法国等地区
传入欧洲
、 、 ...
$%#^@&&$...
如何解决欧洲人民的计算机字符需求呢?
办法:
扩展ASCii码
c
利用ASCII中未被利用的最高位,令最高位为1,扩展出了128个新字符
扩展ASCii码
128-255为扩展ASCII码(也称EASCII码),解决了欧洲的字符编码问题。
总数: 216=65536
能够满足中文的阅读需求
问题来了:中国文字成千上万,ASCII码只有8位,扩展后也只有256个字符,怎么办呢?
传入中国
既然8位不够,就拓展成16位
微软公司利用GB2312中闲置的空间,扩展制定了GBK编码,满足以上地区的计算机使用需求
但是
人名、古汉语等词、以及香港、台湾地区所用繁体字,日本、朝鲜所用汉字均不能显现
通行于中国大陆、新加坡等地,基本满足简体
汉字的计算机处理需要
GB2312码
少数民族的字符编码
为了满足少数民族的计算机用字需求,推出了GB18030。
共收录70244个字,支持少数民族文字
新的问题又出现了
现在互联网世界交流如此频繁,然而每个国家都有基于自己国家的字符编码方式,在跨国交流中会出现什么问题呢
使用同一编码的字符显示时会出错,出现乱码的问题
Unicode(统一码)
针对这一问题,统一码组织推出了统一码
统一码组织
ISO
措施
Unicode
把世界上所有字符都列出来,扩展出32位数据,并为他们进行统一的编号
结果
使用统一码,避免了出现乱码的问题,有利于跨国交流
THANKS
字符编码
1
交流过程不冲突
让计算机能读取与识别(二进制)
2
计算机中的字符要满足什么条件呢?
统一的编码
ASCii码
1,2,3,4...
a,b,c,d...
美国人民
!,$, ,~_
回车、换行...
可见
1
罗列出来
128个字符
95个可见字符
33个不可见字符
按顺序排列
数字
大写字母
小写字母
2
进行编号
32-126为95个可见字符
0-31、127为不可见字符
编号转化为二进制
得到对应的二进制代码,合称为ASCII字符集
3
4
不可见
数据四
5000
常用ASCII码对照表 ASCII码 字 符 ASCII码 字 符 ASCII码 字 符
十进制 二进制 十进制 二进制 十进制 二进制 10 00001010 换行 62 00111110 > 93 01011101 ]
32 00100000 空格 63 00111111 94 01011110 ^
33 00100001 !(感叹号) 64 01000000 @ 95 01011111 -
34 00100010 ” 65 01000001 A 97 01100001 a
35 00100011 # 66 01000010 B 98 01100010 b
36 00100100 $ 67 01000011 C 99 01100011 c
37 00100101 % 68 01000100 D 100 01100100 d
38 00100110 & 69 01000101 E 101 01100101 e
39 00100111 `(引号) 70 01000110 F 102 01100110 f
40 00101000 ( 71 01000111 G 103 01100111 g
41 00101001 ) 72 01001000 H 104 01101000 h
42 00101010 * 73 01001001 I 105 01101001 i
43 00101011 + 74 01001010 J 106 01101010 j
44 00101100 , 75 01001011 K 107 01101011 k
45 00101101 -(减号) 76 01001100 L 108 01101100 l
46 00101110 . 77 01001101 M 109 01101101 m
47 00101111 /(除号) 78 01001110 N 110 01101110 n
48 00110000 0 79 01001111 O 111 01101111 o
49 00110001 1 80 01010000 P 112 01110000 p
50 00110010 2 81 01010001 Q 113 01110001 q
51 00110011 3 82 01010010 R 114 01110010 r
52 00110100 4 83 01010011 S 115 01110011 s
53 00110101 5 84 01010100 T 116 01110100 t
54 00110110 6 85 01010101 U 117 01110101 u
55 00110111 7 86 01010110 V 118 01110110 v
56 00111000 8 87 01010111 W 119 01110111 w
57 00111001 9 88 01011000 X 120 01111000 x
58 00111010 : 89 01011001 Y 121 01111001 y
59 00111011 ; 90 01011010 Z 122 01111010 z
60 00111100 < 91 01011011 [ 123 01111011 {
61 00111101 = 92 01011100 \ 125 01111101 }
因为字符只有128个,因此最高位闲置,为0。
随着计算机的发展,计算机传入欧洲,主要有德国、法国等地区
传入欧洲
、 、 ...
$%#^@&&$...
如何解决欧洲人民的计算机字符需求呢?
办法:
扩展ASCii码
c
利用ASCII中未被利用的最高位,令最高位为1,扩展出了128个新字符
扩展ASCii码
128-255为扩展ASCII码(也称EASCII码),解决了欧洲的字符编码问题。
总数: 216=65536
能够满足中文的阅读需求
问题来了:中国文字成千上万,ASCII码只有8位,扩展后也只有256个字符,怎么办呢?
传入中国
既然8位不够,就拓展成16位
微软公司利用GB2312中闲置的空间,扩展制定了GBK编码,满足以上地区的计算机使用需求
但是
人名、古汉语等词、以及香港、台湾地区所用繁体字,日本、朝鲜所用汉字均不能显现
通行于中国大陆、新加坡等地,基本满足简体
汉字的计算机处理需要
GB2312码
少数民族的字符编码
为了满足少数民族的计算机用字需求,推出了GB18030。
共收录70244个字,支持少数民族文字
新的问题又出现了
现在互联网世界交流如此频繁,然而每个国家都有基于自己国家的字符编码方式,在跨国交流中会出现什么问题呢
使用同一编码的字符显示时会出错,出现乱码的问题
Unicode(统一码)
针对这一问题,统一码组织推出了统一码
统一码组织
ISO
措施
Unicode
把世界上所有字符都列出来,扩展出32位数据,并为他们进行统一的编号
结果
使用统一码,避免了出现乱码的问题,有利于跨国交流
THANKS
同课章节目录
- 第一章 数据与信息
- 项目范例 体验庆祝国庆多媒体作品的数据与信息处理
- 1.1 数据及其特征
- 1.2 数据编码
- 1.3 信息及其特征
- 第二章 知识与数字化学习
- 项目范例 运用数字化工具探究数理知识
- 2.1 知识与智慧
- 2.2 数字化学习与创新
- 第三章 算法基础
- 项目范例 设计从A市到B市耗时最少的旅行路线方案
- 3.1 体验计算机解决问题的过程
- 3.2 算法及其描述
- 3.3 计算机程序与程序设计语言
- 第四章 程序设计基础
- 项目范例 设计购买纪念品的最佳方案
- 4.1 程序设计语言的基础知识
- 4.2 运用顺序结构描述问题求解过程
- 4.3 运用选择结构描述问题求解过程
- 4.4 运用循环结构描述问题求解过程
- 第五章 数据处理和可视化表达
- 项目范例 网络购物平台客户行为数据分析和可视化表达
- 5.1 认识大数据
- 5.2 数据的采集
- 5.3 数据的分析
- 5.4 数据的可视化表达
- 第六章 人工智能及其应用
- 项目范例 剖析空调企业智能客服机器人
- 6.1 认识人工智能
- 6.2 人工智能的应用