5.3.2 数据排序——排序算法的程序实现 课件(17张PPT)
文档属性
| 名称 | 5.3.2 数据排序——排序算法的程序实现 课件(17张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 860.7KB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2021-10-26 00:00:00 | ||
图片预览




文档简介
(共17张PPT)
选择性必修一《数据与数据结构》
第五章 数据结构与算法
5.3.2 排序算法的程序实现
知识回顾
请写出冒泡排序的第一遍手动过程
返回
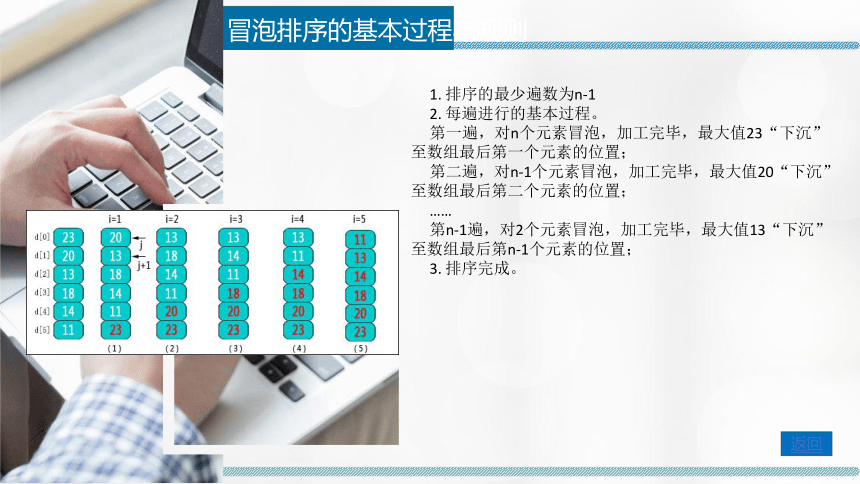
冒泡排序的基本过程与规则
1. 排序的最少遍数为n-1
2. 每遍进行的基本过程。
第一遍,对n个元素冒泡,加工完毕,最大值23“下沉”至数组最后第一个元素的位置;
第二遍,对n-1个元素冒泡,加工完毕,最大值20“下沉”至数组最后第二个元素的位置;
……
第n-1遍,对2个元素冒泡,加工完毕,最大值13“下沉”至数组最后第n-1个元素的位置;
3. 排序完成。
深化排序
返回
排序过程中,按下面的方式使用变量i和j:
i:记录正进行的处理遍数,第1遍处理时值为1,第2遍处理时值为2,依次类推。
j:记录当前数组元素的下标。每遍处理过程中,j值总是从第一个数组元素的下标值0开始,按每次加1的方式,直至j=n-i-1为止。每当j取定一个值后,当前数组元素d[j]将与它的后一个元素d[j+1]进行比较,若d[j] >d[j+1],则互换这两个数组元素中的数据。
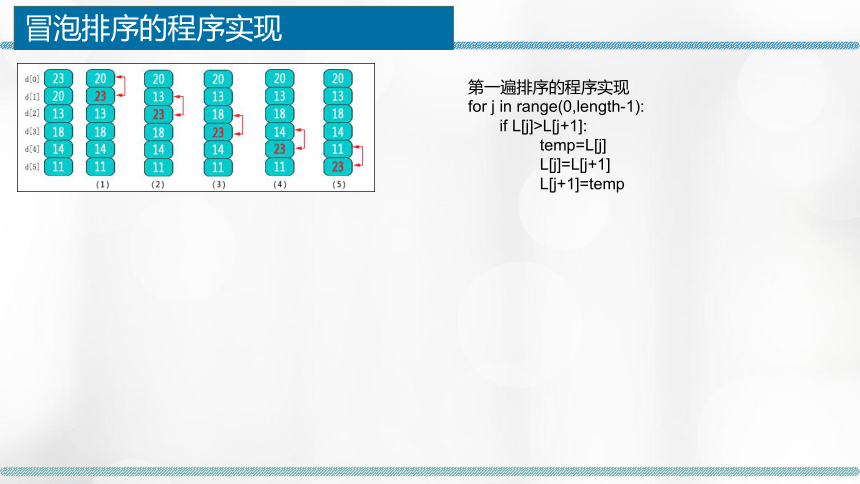
冒泡排序的程序实现
第一遍排序的程序实现
for j in range(0,length-1):
if L[j]>L[j+1]:
temp=L[j]
L[j]=L[j+1]
L[j+1]=temp
找出规律
动手编程
def bubble_sort(L):
length=len(L)
#序列长度为length,需要执行length-1遍加工
for i in range(1,length):
for j in range(0,length-i):
if L[j]>L[j+1]:
temp=L[j]
L[j]=L[j+1]
L[j+1]=temp
小组讨论:迭代式如何来的?
冒泡排序算法的每一遍加工中,最小的元素“上浮”和最大的元素“下沉”这两种方式在程序实现时有何区别?
冒泡排序的基本过程
冒泡排序的
程序实现
冒泡排序的程序结构
选择排序的程序实现
课堂小结
5.3.3 数据排序的应用
情境导入
奥运排行榜部分数据(Excel数据)
编号 国家/地区 人口数量(万) 金牌 银牌 铜牌 总数
8 中国 136407 51 21 28 100
20 印度 130420 1 0 2 3
53 美国 32262 36 38 36 110
21 印度尼西亚 26110 1 1 3 5
13 巴西 20529 3 4 8 15
23 尼日利亚 18231 0 1 3 4
52 俄罗斯 14253 23 21 28 72
6 日本 12703 9 6 10 25
抽象与建模
返回
问题:从表中的数据可以看出,每个国家的信息是一条记录,包括编号、国家/地区、人口数量、各奖牌数等数据项。根据刚才的实践体验,对记录按关键字排序,交换应当如何进行?
设计算法与数据结构
返回
数据组织形式有两种,哪种更方便?
一是采用7个一维数组按列存储,即每个数组分别存储每个国家的编号、国家/地区、人口数量、各奖牌数等,如定义b数组存储表中8个国家的金牌数量,其对应的值为[51,1,36,1,3,0,23,9];
二是采用1个一维数组按行存储,每个数组元素对应某个国家的一条记录信息,如[8,中国,136407,51,21,28,100]对应中国的相关信息。
程序实现
返回
import csv
#数据读入
csvFile = open("jp.csv", "r") #打开相应数据文件
reader = csv.reader(csvFile) #建立一个读入数据的对象
a = []
for item in reader:
a.append(item)
csvFile.close()
#排序
for i in range(1,len(a)-1): #排序不包含第一行数据
for j in range(1,len(a)-i):
if int(a[j][3])temp=a[j]
a[j]=a[j+1]
a[j+1]=temp
#数据写入
csvFile2 = open('jp2.csv','w', newline='')
writer = csv.writer(csvFile2, dialect='excel')
m = len(a)
for i in range(m):
writer.writerow(a[i])
csvFile2.close()
小组讨论:排序的稳定性
一般情况下,数据规模较小,各种排序方法的时间耗费差异较小,选择面较大;当数据规模较大时,冒泡排序、选择排序的时间复杂度为O (n2),一般不会选用,常用的有快速排序、归并排序、堆排序、希尔排序等,时间复杂度为O (n log2 n),python中使用的排序方法为TimSort,它实质上是对归并排序的优化,目前认为是最优秀的排序方法。稳定性是指排序前后,相同的数据项前后关系会不会带来变化,冒泡排序是稳定的,快速排序是不稳定的;数据结构也对排序有很大影响,编程的复杂度不同,空间复杂度不同。一般情况下,降低了时间复杂度,就会带来较高的空间复杂度;降低了空间复杂度,会带来较高的时间复杂度。对较特殊的数据比如在一定范围内的整数,使用桶排序,时间复杂度达到O (n),但空间复杂度会提高,需要较多的辅助空间。
记录的关键字排序注意事项
排序算法的三步骤
不同数据组织形式对算法的实现影响
排序算法的稳定性
课堂小结
课堂作业
1.完成课后练习
选择性必修一《数据与数据结构》
第五章 数据结构与算法
5.3.2 排序算法的程序实现
知识回顾
请写出冒泡排序的第一遍手动过程
返回
冒泡排序的基本过程与规则
1. 排序的最少遍数为n-1
2. 每遍进行的基本过程。
第一遍,对n个元素冒泡,加工完毕,最大值23“下沉”至数组最后第一个元素的位置;
第二遍,对n-1个元素冒泡,加工完毕,最大值20“下沉”至数组最后第二个元素的位置;
……
第n-1遍,对2个元素冒泡,加工完毕,最大值13“下沉”至数组最后第n-1个元素的位置;
3. 排序完成。
深化排序
返回
排序过程中,按下面的方式使用变量i和j:
i:记录正进行的处理遍数,第1遍处理时值为1,第2遍处理时值为2,依次类推。
j:记录当前数组元素的下标。每遍处理过程中,j值总是从第一个数组元素的下标值0开始,按每次加1的方式,直至j=n-i-1为止。每当j取定一个值后,当前数组元素d[j]将与它的后一个元素d[j+1]进行比较,若d[j] >d[j+1],则互换这两个数组元素中的数据。
冒泡排序的程序实现
第一遍排序的程序实现
for j in range(0,length-1):
if L[j]>L[j+1]:
temp=L[j]
L[j]=L[j+1]
L[j+1]=temp
找出规律
动手编程
def bubble_sort(L):
length=len(L)
#序列长度为length,需要执行length-1遍加工
for i in range(1,length):
for j in range(0,length-i):
if L[j]>L[j+1]:
temp=L[j]
L[j]=L[j+1]
L[j+1]=temp
小组讨论:迭代式如何来的?
冒泡排序算法的每一遍加工中,最小的元素“上浮”和最大的元素“下沉”这两种方式在程序实现时有何区别?
冒泡排序的基本过程
冒泡排序的
程序实现
冒泡排序的程序结构
选择排序的程序实现
课堂小结
5.3.3 数据排序的应用
情境导入
奥运排行榜部分数据(Excel数据)
编号 国家/地区 人口数量(万) 金牌 银牌 铜牌 总数
8 中国 136407 51 21 28 100
20 印度 130420 1 0 2 3
53 美国 32262 36 38 36 110
21 印度尼西亚 26110 1 1 3 5
13 巴西 20529 3 4 8 15
23 尼日利亚 18231 0 1 3 4
52 俄罗斯 14253 23 21 28 72
6 日本 12703 9 6 10 25
抽象与建模
返回
问题:从表中的数据可以看出,每个国家的信息是一条记录,包括编号、国家/地区、人口数量、各奖牌数等数据项。根据刚才的实践体验,对记录按关键字排序,交换应当如何进行?
设计算法与数据结构
返回
数据组织形式有两种,哪种更方便?
一是采用7个一维数组按列存储,即每个数组分别存储每个国家的编号、国家/地区、人口数量、各奖牌数等,如定义b数组存储表中8个国家的金牌数量,其对应的值为[51,1,36,1,3,0,23,9];
二是采用1个一维数组按行存储,每个数组元素对应某个国家的一条记录信息,如[8,中国,136407,51,21,28,100]对应中国的相关信息。
程序实现
返回
import csv
#数据读入
csvFile = open("jp.csv", "r") #打开相应数据文件
reader = csv.reader(csvFile) #建立一个读入数据的对象
a = []
for item in reader:
a.append(item)
csvFile.close()
#排序
for i in range(1,len(a)-1): #排序不包含第一行数据
for j in range(1,len(a)-i):
if int(a[j][3])
a[j]=a[j+1]
a[j+1]=temp
#数据写入
csvFile2 = open('jp2.csv','w', newline='')
writer = csv.writer(csvFile2, dialect='excel')
m = len(a)
for i in range(m):
writer.writerow(a[i])
csvFile2.close()
小组讨论:排序的稳定性
一般情况下,数据规模较小,各种排序方法的时间耗费差异较小,选择面较大;当数据规模较大时,冒泡排序、选择排序的时间复杂度为O (n2),一般不会选用,常用的有快速排序、归并排序、堆排序、希尔排序等,时间复杂度为O (n log2 n),python中使用的排序方法为TimSort,它实质上是对归并排序的优化,目前认为是最优秀的排序方法。稳定性是指排序前后,相同的数据项前后关系会不会带来变化,冒泡排序是稳定的,快速排序是不稳定的;数据结构也对排序有很大影响,编程的复杂度不同,空间复杂度不同。一般情况下,降低了时间复杂度,就会带来较高的空间复杂度;降低了空间复杂度,会带来较高的时间复杂度。对较特殊的数据比如在一定范围内的整数,使用桶排序,时间复杂度达到O (n),但空间复杂度会提高,需要较多的辅助空间。
记录的关键字排序注意事项
排序算法的三步骤
不同数据组织形式对算法的实现影响
排序算法的稳定性
课堂小结
课堂作业
1.完成课后练习