2.4.3 算法程序实现的综合应用 课件-2021-2022学年高中信息技术人教_中图版(2019)必修1(24张PPT)
文档属性
| 名称 | 2.4.3 算法程序实现的综合应用 课件-2021-2022学年高中信息技术人教_中图版(2019)必修1(24张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 1.2MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 中图版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2021-12-17 00:00:00 | ||
图片预览





文档简介
(共24张PPT)
2.4.3 算法与程序实现的综合应用
单位:来宾市第四中学
2.4.3 算法与程序实现的综合应用
十九大报告的“亮点”,一个“新”字贯穿整个报告。通过分析得到词云图。
醒目的“新时代”三个字以强烈的视觉冲击效果呈现在我们眼前, 该词在全文中出现36次,高居榜首。其他还有“新格局”“新形势”“新征程”“新成果”“新发展理念”等词汇也频频出现。
“词云”就是对网络文本中出现频率较高的“关键词”予以视觉上的突出,从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。
2.4.3 算法与程序实现的综合应用
问题提出:如何选取文章中出现次数最多的词呢?
学校开展经典诵读活动,小明在阅读《三国演义》时,为了分析小说的写作特色,想把小说中出现次数最多的20个词查找出来。
2.4.3 算法与程序实现的综合应用
实践探索
想一想,小明是否能从纸质小说中找出这20个高频词?如果用计算机解决该问题,又应如何实现?
学校开展经典诵读活动,小明在阅读《三国演义》时,为了分析小说的写作特色,想把小说中出现次数最多的20个词查找出来。
计算机解决:已知条件为文本文件《三国演义》,求解目标为《三国演义》中出现次数最多的20个词。
2.4.3 算法与程序实现的综合应用
分析问题
手工方法:费时费力,难度很大。
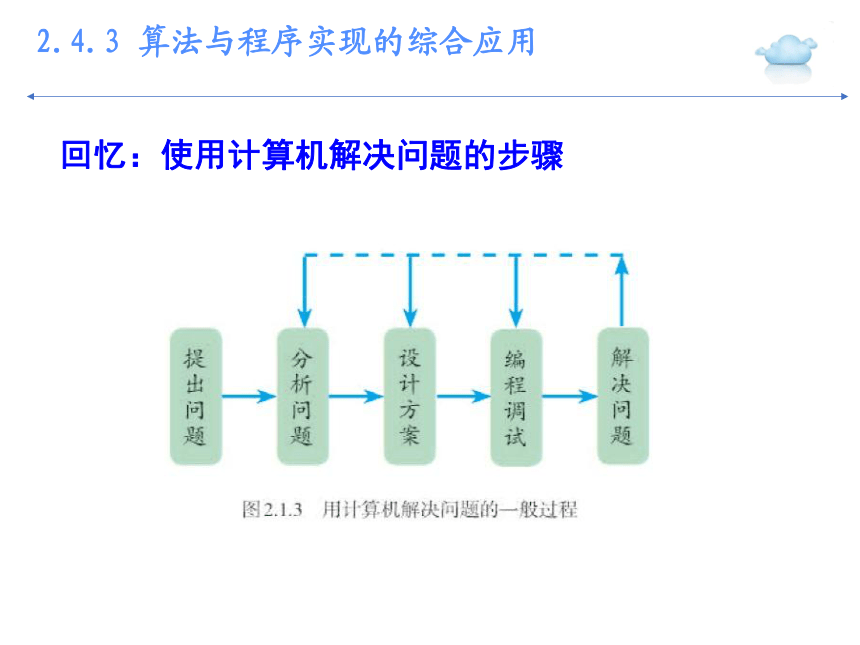
回忆:使用计算机解决问题的步骤
2.4.3 算法与程序实现的综合应用
在问题求解中,除了要完成读取文件和显示输出内容,还要重点实现分词、词频统计和排序等功能。如图所示:
2.4.3 算法与程序实现的综合应用
设计算法
由于中文文本是由连续的字序列构成,没有明显的词语界限,因此分词处理的算法比较复杂。
2.4.3 算法与程序实现的综合应用
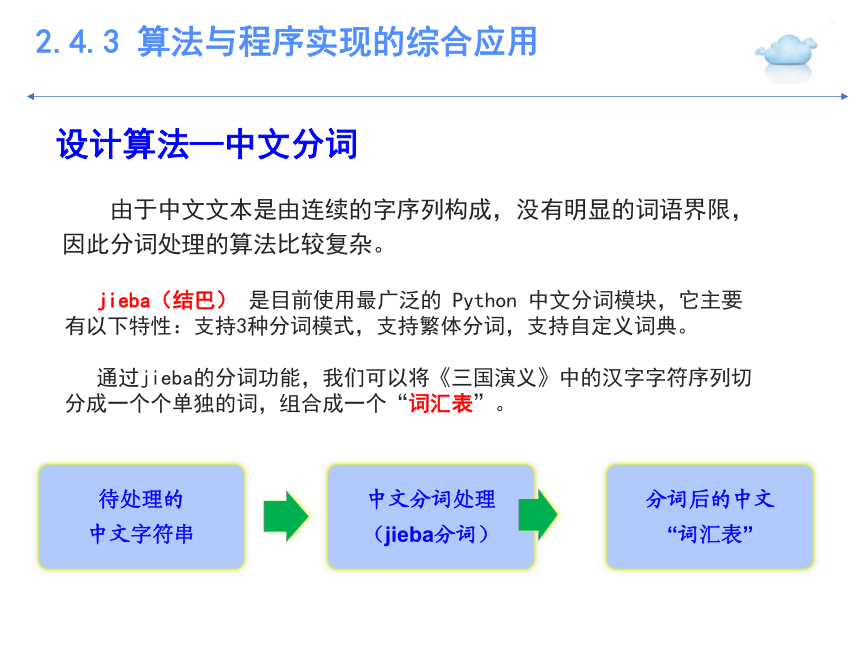
设计算法—中文分词
jieba(结巴) 是目前使用最广泛的 Python 中文分词模块,它主要有以下特性:支持3种分词模式,支持繁体分词,支持自定义词典。
通过jieba的分词功能,我们可以将《三国演义》中的汉字字符序列切分成一个个单独的词,组合成一个“词汇表”。
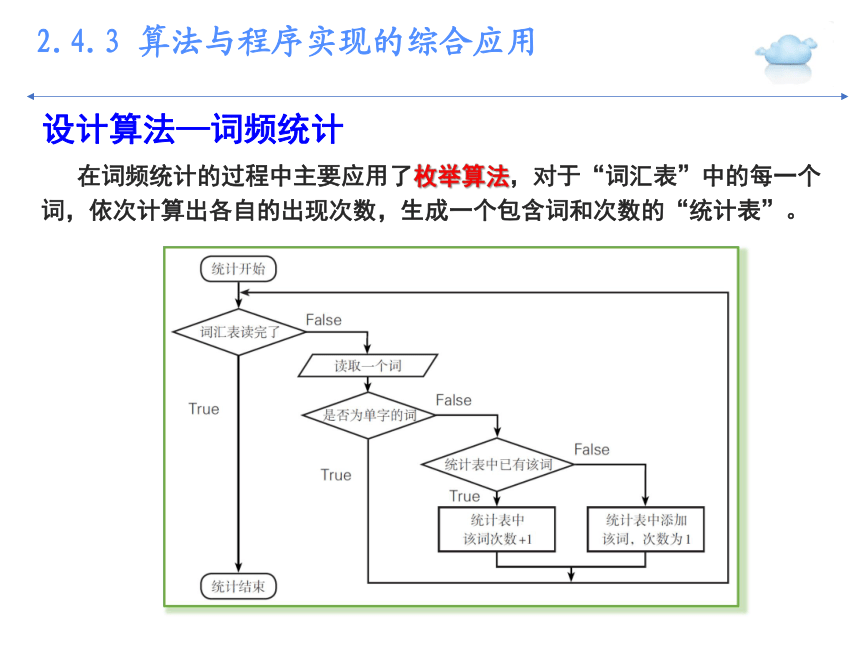
在词频统计的过程中主要应用了枚举算法,对于“词汇表”中的每一个词,依次计算出各自的出现次数,生成一个包含词和次数的“统计表”。
设计算法—词频统计
2.4.3 算法与程序实现的综合应用
要找到出现次数最多的20个词,需要对“统计表”中的词语按次数从大到小进行排序。
2.4.3 算法与程序实现的综合应用
设计算法—词频排序
可以自己设计排序算法,也可以调用Python语言中可以直接调用内置的排序函数快速实现序列排序。
设计算法—显示输出
使用print语句可以显示前20个词及它的次数。
# 打开文件python中使用open函数(参数1为打开的文件,参数2为打开方式,参数3为文件存储方式)。
f = open("三国演义.txt", "r", encoding="utf-8")
# 读取文件内容
txt = f.read()
注意:打开文件时要注意编码格式,待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8。
2.4.3 算法与程序实现的综合应用
程序编写—读取文件
# 导入jieba模块
import jieba
# 将句子拆分为词语保存到列表中
words = jieba.lcut(txt)
2.4.3 算法与程序实现的综合应用
程序编写—进行分词
# 建立空字典,用于存储词和出现次数
counts = {}
#枚举所有分词,存入字典变量counts中,并计算它次数
for word in words:
if len(word) == 1: # 单字的词语忽略不计
continue
else:
# 出现次数+1
counts[word] = counts.get(word, 0) + 1
2.4.3 算法与程序实现的综合应用
程序编写—分词统计
为保证统计结果唯一性,这里我们需要使用Python中一个特殊的数据类型,字典。
分词第一次出现,默认值为0
2.4.3 算法与程序实现的综合应用
字典是Python语言中的一种数据类型,其中每个元素都包含两部分:键和值。字典中元素用花括号括起,用冒号分隔键和值。例如,表示教师姓名及其年龄信息的数据可用字典类型表示为:
Python语言中的字典类型
teachers= {"张明":25, "王丽":32, "李强":56 , "孙玲":44}
字典与列表不同,它不是数据的序列,而是键值对的无序集合。
字典可以通过键访问值,这种方法与平时我们查字典或电话簿类似,如:
列表:t= [“张明”, “王丽”, “李强”, “孙玲“],列表访问通过索引值来访问,如: t[0]的值为”张明”,而t[“张明”]写法错误!
返回
字典与列表
teachers[“张明”]的值为 25 ,而teachers[0]写法错误!
2.4.3 算法与程序实现的综合应用
字典类型
字典是Python语言中的一种数据类型,其中每个元素都包含两部分:键和值。字典中元素用花括号括起,用冒号分隔键和值。
Python语言中的字典函数操作
返回
字典数据是无序的,需要将字典转化为列表,对列表排序。
# 字典转化为列表后才可以排序
items = list(counts.items())
# 对列表items按“次数”降序排序
items.sort(key=lambda x:x[1], reverse=True)
2.4.3 算法与程序实现的综合应用
程序编写—分词排序
Python语言中内置了多种排序方法,函数sort就是其中常用的一种。
例如,list.sort()可以对列表list进行升序排序,若要降序排列,需要设置参数:reverse = True,如list.sort(reverse = True)。
要对字典类型数据进行排序,通常先将其转换为列表类型,然后再进行排序操作。
2.4.3 算法与程序实现的综合应用
程序编写—sort函数
例如:
counts = { "Apple":25,"Orange ":40,"Green tea":28,"Coffee" : 15}
L = list(counts.items())
#L列表的值:
[("Apple",25),("Orange ",40),("Green tea",28),("Coffee" ,15)]
L.sort(key=lambda x:x[1],reverse=True)
#根据列表中的第2列进行降序排序排序后列表L的值为:
[("Orange", 40), ("Green tea",28), ("Apple",25),("Coffee", 15)]。
用于定义一种特殊的函数——匿名函数,又称lambda函数。
匿名函数并非没有名字,而是将函数名作为函数结果返回,如下:
<函数名> = lambda <参数列表>: <表达式>
lambda函数与正常函数一样,等价于下面形式:
def <函数名>(<参数列表>):
return <表达式>
2.4.3 算法与程序实现的综合应用
程序编写—lambda函数
#显示前20名
for i in range(20):
# 输出词和出现次数
print(items[i][0], items[i][1])
2.4.3 算法与程序实现的综合应用
程序编写—显示输出实现
2.4.3 算法与程序实现的综合应用
程序编写—完整代码
import jieba
f = open(“三国演义.txt”, ‘r’, encoding=‘utf-8’) #打开文件
txt = f.read() #读取文件
words=jieba.lcut(txt) #进行分词
counts={} #定义空字典
for word in words: #将分词导入字典中,并统计个数
if len(word)==1:
continue #对于一个字的分词省略掉
else:
counts[word]=counts.get(word,0)+1 #加上一个数
items=list(counts.items()) #将字典转为列表
items.sort(key=lambda x:x[1],reverse=True) #对转换后的列表进行排序
for i in range(20): #输出前20名
print(items[i][0], items[i][1])
2.4.3 算法与程序实现的综合应用
程序编写—结果显示
编程解决问题不是一蹴而就的。通常,我们要根据程序运行结果,围绕求解目标,改进算法、优化程序,以实现问题的最终有效解决。
我们可以利用Python语言中的if语句将这些词语进行合并处理,具体编码实现如下:
for word in words:
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长" :
rword = "关羽"
elif word == "玄德" or word == "玄德曰" :
rword = "刘备"
elif word == "孟德" or word == "丞相" :
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
2.4.3 算法与程序实现的综合应用
程序编写—代码完善
为了更有效地查找、修改程序中存在的错误,需要仔细阅读和分析程序语句,掌握必要的调试方法。
断点调试是一种较为直观的程序调试方式,其基本方法为:
进入调试状态;
设置断点;
检查运行状态下各个变量的值,确定错误的位置,并进行修改;
反复调试直至程序运行正确。
2.4.3 算法与程序实现的综合应用
保存文件,调试运行程序
在前面已经找到的20个高频词中,包括有“却说”“二人”“不能”等与人名无关的词语。想一想,如何去除这些词语,只显示10位出场次数最多的主要人物?尝试修改程序。
2.4.3 算法与程序实现的综合应用
课后进一步完善算法
课堂练习
尝试找出2020年政府工作报告中的10个出现最多的词?
2.4.3 算法与程序实现的综合应用
单位:来宾市第四中学
2.4.3 算法与程序实现的综合应用
十九大报告的“亮点”,一个“新”字贯穿整个报告。通过分析得到词云图。
醒目的“新时代”三个字以强烈的视觉冲击效果呈现在我们眼前, 该词在全文中出现36次,高居榜首。其他还有“新格局”“新形势”“新征程”“新成果”“新发展理念”等词汇也频频出现。
“词云”就是对网络文本中出现频率较高的“关键词”予以视觉上的突出,从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。
2.4.3 算法与程序实现的综合应用
问题提出:如何选取文章中出现次数最多的词呢?
学校开展经典诵读活动,小明在阅读《三国演义》时,为了分析小说的写作特色,想把小说中出现次数最多的20个词查找出来。
2.4.3 算法与程序实现的综合应用
实践探索
想一想,小明是否能从纸质小说中找出这20个高频词?如果用计算机解决该问题,又应如何实现?
学校开展经典诵读活动,小明在阅读《三国演义》时,为了分析小说的写作特色,想把小说中出现次数最多的20个词查找出来。
计算机解决:已知条件为文本文件《三国演义》,求解目标为《三国演义》中出现次数最多的20个词。
2.4.3 算法与程序实现的综合应用
分析问题
手工方法:费时费力,难度很大。
回忆:使用计算机解决问题的步骤
2.4.3 算法与程序实现的综合应用
在问题求解中,除了要完成读取文件和显示输出内容,还要重点实现分词、词频统计和排序等功能。如图所示:
2.4.3 算法与程序实现的综合应用
设计算法
由于中文文本是由连续的字序列构成,没有明显的词语界限,因此分词处理的算法比较复杂。
2.4.3 算法与程序实现的综合应用
设计算法—中文分词
jieba(结巴) 是目前使用最广泛的 Python 中文分词模块,它主要有以下特性:支持3种分词模式,支持繁体分词,支持自定义词典。
通过jieba的分词功能,我们可以将《三国演义》中的汉字字符序列切分成一个个单独的词,组合成一个“词汇表”。
在词频统计的过程中主要应用了枚举算法,对于“词汇表”中的每一个词,依次计算出各自的出现次数,生成一个包含词和次数的“统计表”。
设计算法—词频统计
2.4.3 算法与程序实现的综合应用
要找到出现次数最多的20个词,需要对“统计表”中的词语按次数从大到小进行排序。
2.4.3 算法与程序实现的综合应用
设计算法—词频排序
可以自己设计排序算法,也可以调用Python语言中可以直接调用内置的排序函数快速实现序列排序。
设计算法—显示输出
使用print语句可以显示前20个词及它的次数。
# 打开文件python中使用open函数(参数1为打开的文件,参数2为打开方式,参数3为文件存储方式)。
f = open("三国演义.txt", "r", encoding="utf-8")
# 读取文件内容
txt = f.read()
注意:打开文件时要注意编码格式,待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8。
2.4.3 算法与程序实现的综合应用
程序编写—读取文件
# 导入jieba模块
import jieba
# 将句子拆分为词语保存到列表中
words = jieba.lcut(txt)
2.4.3 算法与程序实现的综合应用
程序编写—进行分词
# 建立空字典,用于存储词和出现次数
counts = {}
#枚举所有分词,存入字典变量counts中,并计算它次数
for word in words:
if len(word) == 1: # 单字的词语忽略不计
continue
else:
# 出现次数+1
counts[word] = counts.get(word, 0) + 1
2.4.3 算法与程序实现的综合应用
程序编写—分词统计
为保证统计结果唯一性,这里我们需要使用Python中一个特殊的数据类型,字典。
分词第一次出现,默认值为0
2.4.3 算法与程序实现的综合应用
字典是Python语言中的一种数据类型,其中每个元素都包含两部分:键和值。字典中元素用花括号括起,用冒号分隔键和值。例如,表示教师姓名及其年龄信息的数据可用字典类型表示为:
Python语言中的字典类型
teachers= {"张明":25, "王丽":32, "李强":56 , "孙玲":44}
字典与列表不同,它不是数据的序列,而是键值对的无序集合。
字典可以通过键访问值,这种方法与平时我们查字典或电话簿类似,如:
列表:t= [“张明”, “王丽”, “李强”, “孙玲“],列表访问通过索引值来访问,如: t[0]的值为”张明”,而t[“张明”]写法错误!
返回
字典与列表
teachers[“张明”]的值为 25 ,而teachers[0]写法错误!
2.4.3 算法与程序实现的综合应用
字典类型
字典是Python语言中的一种数据类型,其中每个元素都包含两部分:键和值。字典中元素用花括号括起,用冒号分隔键和值。
Python语言中的字典函数操作
返回
字典数据是无序的,需要将字典转化为列表,对列表排序。
# 字典转化为列表后才可以排序
items = list(counts.items())
# 对列表items按“次数”降序排序
items.sort(key=lambda x:x[1], reverse=True)
2.4.3 算法与程序实现的综合应用
程序编写—分词排序
Python语言中内置了多种排序方法,函数sort就是其中常用的一种。
例如,list.sort()可以对列表list进行升序排序,若要降序排列,需要设置参数:reverse = True,如list.sort(reverse = True)。
要对字典类型数据进行排序,通常先将其转换为列表类型,然后再进行排序操作。
2.4.3 算法与程序实现的综合应用
程序编写—sort函数
例如:
counts = { "Apple":25,"Orange ":40,"Green tea":28,"Coffee" : 15}
L = list(counts.items())
#L列表的值:
[("Apple",25),("Orange ",40),("Green tea",28),("Coffee" ,15)]
L.sort(key=lambda x:x[1],reverse=True)
#根据列表中的第2列进行降序排序排序后列表L的值为:
[("Orange", 40), ("Green tea",28), ("Apple",25),("Coffee", 15)]。
用于定义一种特殊的函数——匿名函数,又称lambda函数。
匿名函数并非没有名字,而是将函数名作为函数结果返回,如下:
<函数名> = lambda <参数列表>: <表达式>
lambda函数与正常函数一样,等价于下面形式:
def <函数名>(<参数列表>):
return <表达式>
2.4.3 算法与程序实现的综合应用
程序编写—lambda函数
#显示前20名
for i in range(20):
# 输出词和出现次数
print(items[i][0], items[i][1])
2.4.3 算法与程序实现的综合应用
程序编写—显示输出实现
2.4.3 算法与程序实现的综合应用
程序编写—完整代码
import jieba
f = open(“三国演义.txt”, ‘r’, encoding=‘utf-8’) #打开文件
txt = f.read() #读取文件
words=jieba.lcut(txt) #进行分词
counts={} #定义空字典
for word in words: #将分词导入字典中,并统计个数
if len(word)==1:
continue #对于一个字的分词省略掉
else:
counts[word]=counts.get(word,0)+1 #加上一个数
items=list(counts.items()) #将字典转为列表
items.sort(key=lambda x:x[1],reverse=True) #对转换后的列表进行排序
for i in range(20): #输出前20名
print(items[i][0], items[i][1])
2.4.3 算法与程序实现的综合应用
程序编写—结果显示
编程解决问题不是一蹴而就的。通常,我们要根据程序运行结果,围绕求解目标,改进算法、优化程序,以实现问题的最终有效解决。
我们可以利用Python语言中的if语句将这些词语进行合并处理,具体编码实现如下:
for word in words:
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长" :
rword = "关羽"
elif word == "玄德" or word == "玄德曰" :
rword = "刘备"
elif word == "孟德" or word == "丞相" :
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
2.4.3 算法与程序实现的综合应用
程序编写—代码完善
为了更有效地查找、修改程序中存在的错误,需要仔细阅读和分析程序语句,掌握必要的调试方法。
断点调试是一种较为直观的程序调试方式,其基本方法为:
进入调试状态;
设置断点;
检查运行状态下各个变量的值,确定错误的位置,并进行修改;
反复调试直至程序运行正确。
2.4.3 算法与程序实现的综合应用
保存文件,调试运行程序
在前面已经找到的20个高频词中,包括有“却说”“二人”“不能”等与人名无关的词语。想一想,如何去除这些词语,只显示10位出场次数最多的主要人物?尝试修改程序。
2.4.3 算法与程序实现的综合应用
课后进一步完善算法
课堂练习
尝试找出2020年政府工作报告中的10个出现最多的词?
同课章节目录
- 第1章 认识数据与大数据
- 主题学习项目:体质数据促健康
- 1.1 数据、信息与知识
- 1.2 数字化与编码
- 1.3 数据科学与大数据
- 第2章 算法与程序实现
- 主题学习项目:编程控灯利出行
- 2.1 解决问题的一般过程和用计算机解决问题
- 2.2 算法的概念及描述
- 2.3 程序设计基本知识
- 2.4 常见算法的程序实现
- 第3章 数据处理与应用
- 主题学习项目:用水分析助决策
- 3.1 数据处理的一般过程
- 3.2 数据采集与整理
- 3.3 数据分析与可视化
- 3.4 数据分析报告与应用
- 第4章 走进智能时代
- 主题学习项目:智能交互益拓展
- 4.1 认识人工智能
- 4.2 利用智能工具解决问题
- 4.3 人工智能的应用与影响