8.3 分类变量与列联表 导学案 高中数学新人教A版选择性必修第三册(2022年) (word含答案)
文档属性
| 名称 | 8.3 分类变量与列联表 导学案 高中数学新人教A版选择性必修第三册(2022年) (word含答案) |

|
|
| 格式 | zip | ||
| 文件大小 | 2.3MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 人教A版(2019) | ||
| 科目 | 数学 | ||
| 更新时间 | 2022-02-17 00:00:00 | ||
图片预览


文档简介
8.3 分类变量与列联表
学习目标
1.通过对典型案例的探究,了解独立性检验(只要求2×2列联表)的基本思想、方法
及初步应用.
2.通过对数据的收集、整理和分析,增强学生的社会实践能力,培养学生分析问题、
解决问题的能力.
重点难点
重点:了解独立性检验(只要求2×2列联表)的应用.
难点:独立性检验(只要求2×2列联表)的基本思想、方法
知识梳理
1. 分类变量
为了表述方便,我们经常会使用一种特殊的随机变量,以区别不同的现象或性质,这类随机变量称为分类变量.分类变量的取值可以用实数表示,例如,学生所在的班级可以用1,2,3等表示,男性、女性可以用1,0表示,等等.
2. 2×2列联表
表是关于分类变量X和Y的抽样数据的2×2列联表:最后一行的前两个数分别是事件{Y=0}和{Y=1}的频数;最后一列的前两个数分别是事件{X=0}和{X=1}的频数;中间的四个数a,b,c,d是事件{X=x,Y=y}(x, y=0,1)的频数;右下角格中的数n是样本容量。
X Y 合计
Y=0 Y=1
X=0 a b a+b
X=1 c d c+d
合计 a+c b+d n=a+b+c+d
3.两个分类变量之间关联关系的定性分析的方法:
(1)频率分析法:通过对样本的每个分类变量的不同类别事件发生的频率大小进行比较来分析分类变量之间是否有关联关系.如可以通过列联表中值的大小粗略地判断分类变量x和Y之间有无关系.一般其值相差越大,分类变量有关系的可能性越大.
(2)图形分析法:与表格相比,图形更能直观地反映出两个分类变 量间是否互相影响,常用等高堆积条形图展示列联表数据的频率特征.将列联表中的数据用高度相同的两个条形图表示出来,其中两列的数据分别对应不同的颜色,这就是等高堆积条形图.
等高堆积条形图可以展示列联表数据的频率特征,能够直观地反映出两个分类变量间是否相互影响.
4.独立性检验公式及定义:
提出零假设(原假设)H0:分类变量X和Y独立,假定我们通过简单随机抽样得到了X和Y的抽样数据列联表,在列联表中,如果零假设H0成立,则应满足,即ad-bc≈0.因此|ad bc|越小,说明两个分类变量之间关系越弱;|ad bc|越大,说明两个分类变量之间关系越强.
为了使不同样本容量的数据有统一的评判标准,基于上述分析,我们构造一个随机变量.
X Y 合计
Y=0 Y=1
X=0 a b a+b
X=1 c d c+d
合计 a+c b+d n=a+b+c+d
5.临界值的定义:
对于任何小概率值α,可以找到相应的正实数xα,使得P(χ2≥xα)=α成立,我们称xα为α的临界值,这个临界值可作为判断χ2大小的标准,概率值α越小,临界值xα越大.
基于小概率值α的检验规则:
当χ2≥xα时,我们就推断H0不成立,即认为X和Y不独立,该推断犯错误的概率不超过α;
当χ2用χ2取值的大小作为判断零假设H0是否成立的依据,当它比较大时推断H0不成立,否则认为H0成立。这种利用χ2的取值推断分类变量X和Y是否独立的方法称为χ2独立性检验,读作“卡方独立性检验”,简称独立性检验.
χ2独立性检验中几个常用的小概率值和相应的临界值
α 0.1 0.05 0.01 0.005 0.001
xα 2.706 3.841 6.635 7.879 10.858
学习过程
问题探究
前面两节所讨论的变量,如人的身高、树的胸径、树的高度、短跑100m世界纪录和创纪录的时间等,都是数值变量,数值变量的取值为实数.其大小和运算都有实际含义.
在现实生活中,人们经常需要回答一定范围内的两种现象或性质之间是否存在关联性或相互影响的问题.例如,就读不同学校是否对学生的成绩有影响,不同班级学生用于体育锻炼的时间是否有差别,吸烟是否会增加患肺癌的风险,等等,本节将要学习的独立性检验方法为我们提供了解决这类问题的方案。
在讨论上述问题时,为了表述方便,我们经常会使用一种特殊的随机变量,以区别不同的现象或性质,这类随机变量称为分类变量.分类变量的取值可以用实数表示,例如,学生所在的班级可以用1,2,3等表示,男性、女性可以用1,0表示,等等.在很多时候,这些数值只作为编号使用,并没有通常的大小和运算意义,本节我们主要讨论取值于{0,1}的分类变量的关联性问题.
问题1. 为了有针对性地提高学生体育锻炼的积极性,某中学需要了解性别因素是否对本校学生体育锻炼的经常性有影响,为此对学生是否经常锻炼的情况进行了普查,全校学生的普查数据如下:523名女生中有331名经常锻炼;601名男生中有473名经常锻炼。你能利用这些数据,说明该校女生和男生在体育锻炼的经常性方面是否存在差异吗
二、典例解析
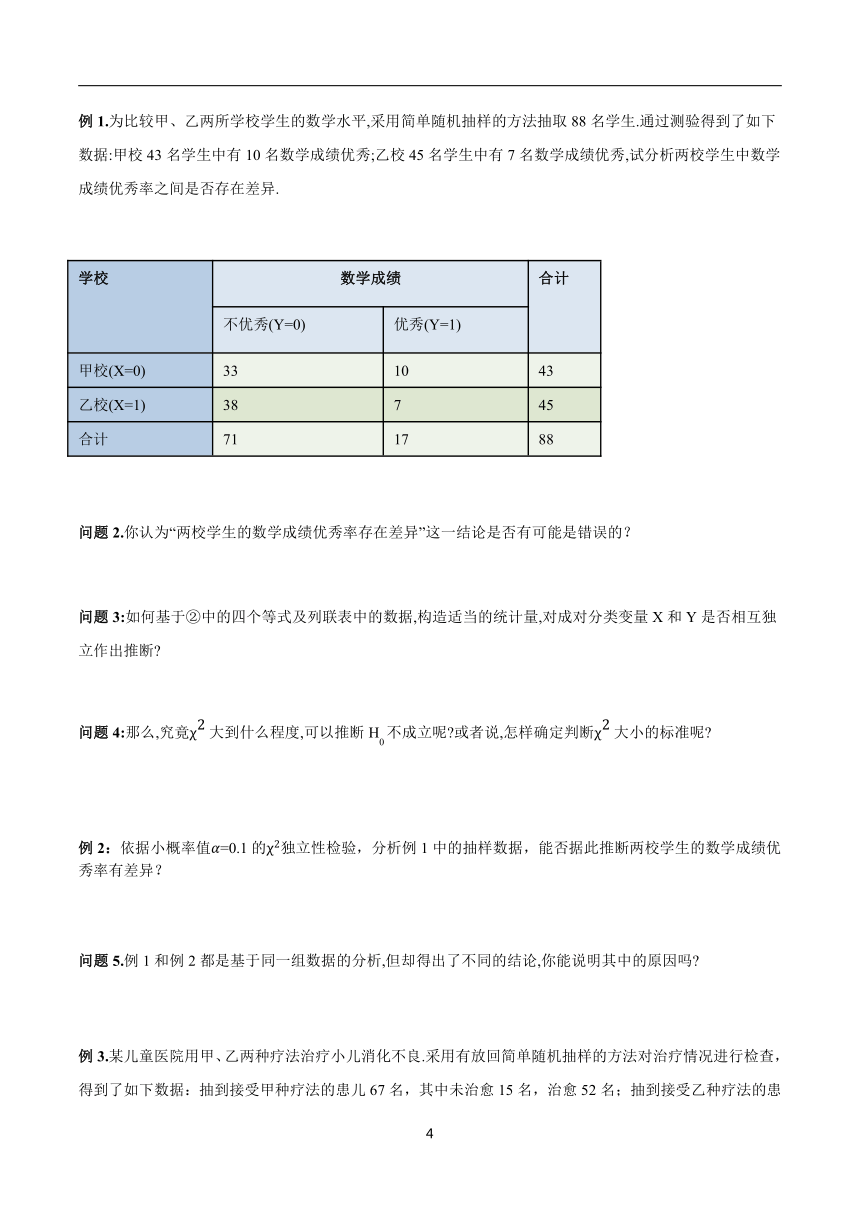
例1.为比较甲、乙两所学校学生的数学水平,采用简单随机抽样的方法抽取88名学生.通过测验得到了如下数据:甲校43名学生中有10名数学成绩优秀;乙校45名学生中有7名数学成绩优秀,试分析两校学生中数学成绩优秀率之间是否存在差异.
学校 数学成绩 合计
不优秀(Y=0) 优秀(Y=1)
甲校(X=0) 33 10 43
乙校(X=1) 38 7 45
合计 71 17 88
问题2.你认为“两校学生的数学成绩优秀率存在差异”这一结论是否有可能是错误的?
问题3:如何基于②中的四个等式及列联表中的数据,构造适当的统计量,对成对分类变量X和Y是否相互独立作出推断
问题4:那么,究竟大到什么程度,可以推断H0不成立呢 或者说,怎样确定判断大小的标准呢
例2:依据小概率值=0.1的独立性检验,分析例1中的抽样数据,能否据此推断两校学生的数学成绩优秀率有差异?
问题5.例1和例2都是基于同一组数据的分析,但却得出了不同的结论,你能说明其中的原因吗
例3.某儿童医院用甲、乙两种疗法治疗小儿消化不良.采用有放回简单随机抽样的方法对治疗情况进行检查,得到了如下数据:抽到接受甲种疗法的患儿67名,其中未治愈15名,治愈52名;抽到接受乙种疗法的患儿69名,其中未治愈6名,治愈63名.试根据小概率值=0.005的独立性检验,分析乙种疗法的效果是否比甲种疗法好.
问题6.若对调两种疗法的位置或对调两种疗效的位置,这样做会影响取值的计算结果吗?
例4.为了调查吸烟是否对肺癌有影响,某肿瘤研究所采取有放回简单随机抽样,调查了9965人,得到如下结果(单位:人)依据小概率值α=0.001的独立性检验,分析吸烟是否会增加患肺癌的风险。
吸烟 肺癌 合计
非肺癌患者 肺癌患者
非吸烟者 7775 42 7817
吸烟者 2099 49 2148
合计 9874 91 9965
应用独立性检验解决实际问题大致应包括以下几个主要环节:
(1)提出零假设H0:X和Y相互独立,并给出在问题中的解释.
(2)根据抽样数据整理出2×2列联表,计算的值,并与临界值比较.
(3)根据检验规则得出推断结论.
(4)在X和Y不独立的情况下,根据需要,通过比较相应的频率,分析X和Y间的影响规律.
注意:上述几个环节的内容可以根据不同情况进行调整,
例如,在有些时候,分类变量的抽样数据列联表是问题中给定的.
P(χ2≥x0) 0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005 0.001
x0 0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828
归纳总结
跟踪训练1.某校对学生的课外活动进行调查,结果整理成下表:
体育 文娱 总计
男生 21 23 44
女生 6 29 35
总计 27 52 79
试用你所学过的知识分析:能否在犯错误的概率不超过0.005的前提下,认为“喜欢体育还是文娱与性别有关系”?
达标检测
1.给出下列实际问题:
①一种药物对某种病的治愈率;②两种药物治疗同一种病是否有区别;
③吸烟者得肺病的概率;④吸烟是否与性别有关系;
⑤网吧与青少年的犯罪是否有关系.其中用独立性检验可以解决的问题有( )
A.①②③ B.②④⑤ C.②③④⑤ D.①②③④⑤
2.某班主任对全班50名学生进行了作业量多少的调查,数据如下表:
下列叙述中,正确的是( )
认为作业多 认为作业不多 总数
喜欢玩电脑游戏 18 9 27
不喜欢玩电脑游戏 8 15 23
总数 26 24 50
A.有99%的把握认为“喜欢玩电脑游戏与认为作业量的多少有关系”
B.有95%的把握认为“喜欢玩电脑游戏与认为作业量的多少无关系”
C.有99%的把握认为“喜欢玩电脑游戏与认为作业量的多少无关系”
D.有95%的把握认为“喜欢玩电脑游戏与认为作业量的多少有关系”
3.某高校《统计》课程的教师随机调查了选该课的一些学生情况,具体数据如下表:
为了判断主修统计专业是否与性别有关系,根据表中的数据,得到
专业 性别 非统计专业 统计专业
男 13 10
女 7 20
因为4.844>3.841,所以有 的把握判定主修统计专业与性别有关系.
4.在500人身上试验某种血清预防感冒作用,把他们一年中的感冒记录与另外500名未用血清的人的感冒记录作比较,结果如表所示。问:该种血清能否起到预防感冒的作用?
未感冒 感冒 合计
使用血清 258 242 500
未使用血清 216 284 500
合计 474 526 1000
5.随着工业化以及城市车辆的增加,城市的空气污染越来越严重,空气质量指数API一直居高不下,对人体的呼吸系统造成了严重的影响.现调查了某市500名居民的工作场所和呼吸系统健康情况,得到2×2列联表如下:
室外工作 室内工作 总计
有呼吸系统疾病 150
无呼吸系统疾病 100
总 计 200
(1)补全2×2列联表;
(2)能否在犯错误的概率不超过0.05的前提下认为感染呼吸系统疾病与工作场所有关
(3)现采用分层抽样从室内工作的居民中抽取一个容量为6的样本,将该样本看成一个总体,从中随机地抽取两人,求两人都有呼吸系统疾病的概率.
课堂小结
参考答案
知识梳理
学习过程
问题探究
问题1. 这是一个简单的统计问题,最直接的解答方法是,比较经常锻炼的学生在女生和男生中的比率,为了方便,我们设=, =
那么,只要求出f0和f1的值,通过比较这两个值的大小,就可以知道女生和男生在锻炼的经常性方面是否有差异,由所给的数据,经计算得到=≈0.633, =.
由f1-f0 0.787-0.633=0.154可知,男生经常锻炼的比率比女生高出15.4个百分点.
所以该校的女生和男生在体育锻等的经常性方面有差异,而且男生更经常锻炼.
用n表示该校全体学生构成的集合,这是我们所关心的对象的总体,考虑以n为样本空间的古典概型,并定义一对分类变量X和Y如下:对于Ω中的每一名学生,
分别令,,
“性别对体育锻炼的经常性没有影响”可以描述为P(Y=1|X=0)=P(Y=1|X=1);
“性别对体育锻炼的经常性有影响”可以描述为P(Y=1|X=0)≠P(Y=1|X=1).
我们希望通过比较条件概率P(Y=1|X=0)和P(Y=1|X=1)回答上面的问题.按照条件本概率的直观解释,
如果从该校女生和男生中各随机选取一名学生,那么该女生属于经常锻炼群体的概率是P(Y=1|X=0),
而该男生属于经常锻炼群体的概率是P(Y=1|X=1).
为了清楚起见,我们用表格整理数据
性别 锻炼 合计
不经常(Y=0) 经常(Y=1)
女生(X=0) 192 331 523
男生(X=1) 128 473 601
合计 320 804 1124
我们用{X=0,Y=1}表示事件{X=0}和{Y=1}的积事件,用{X=1,Y=1}表示事件{X=1}和{Y=1}的积事件,根据古典概型和条件概率的计算公式,我们有
P(Y=1|X=0)==≈0.633
P(Y=1|X=1)==≈0.787
由P(Y=1|X=1)>P(Y=1|X=0)
可以作出判断,在该校的学生中,性别对体育锻炼的经常性有影响,即该校的女生和男生在体育锻炼的经常性方面存在差异,而且男生更经常锻炼。
在实践中,由于保存原始数据的成本较高,人们经常按研究问题的需要,将数据分类统计,并做成表格加以保存,我们将下表这种形式的数据统计表称为2×2列联表(contingency table).
2×2列联表给出了成对分类变量数据的交叉分类频数,以右表为例,它包含了X和Y的如下信息:
最后一行的前两个数分别是事件{Y=0}和{Y=1}中样本点的个数;
最后一列的前两个数分别是事件{X=0}和{X=1}中样本点的个数;
中间的四个格中的数是表格的核心部分,给出了事件{X=x,Y=y}(x,y=0,1)中样本点的个数;
右下角格中的数是样本空间中样本点的总数。
性别 锻炼 合计
不经常(Y=0) 经常(Y=1)
女生(X=0) 192 331 523
男生(X=1) 128 473 601
合计 320 804 1124
二、典例解析
例1.解:用Ω表示两所学校的全体学生构成的集合.考虑以Ω为样本空间的古典概型.对于Ω中每一名学生,定义分类变量X和Y如下:,,
学校 数学成绩 合计
不优秀(Y=0) 优秀(Y=1)
甲校(X=0) 33 10 43
乙校(X=1) 38 7 45
合计 71 17 88
我们将所给数据整理成表(单位:人)
表是关于分类变量X和Y的抽样数据的2×2列联表:最后一行的前两个数分别是事件(Y=0)和(Y=1)的频数;最后一列的前两个数分别是事件(X=0)和(X=1)的频数;中间的四个格中的数是事件(X=x,Y=y)(x,y=0,1)的频数;
甲校学生中数学成绩不优秀和数学成绩优秀的频率分别为≈0.7674和≈ 0.2326;
乙校学生中数学成绩不优秀和数学成绩优秀的频率分别为≈ 0.8444和≈ 0.1556
我们可以用等高堆积条形图直观地展示上述计算结果,如图所示
左边的蓝色和红色条的高度分别是甲校学生中数学成绩不优秀和数学成绩优秀的频率;右边的蓝色和红色条的高度分别是乙校学生中数学成绩不优秀和数学成绩优秀的频率,通过比较发现,两个学校学生抽样数据中数学成绩优秀的频率存在差异,甲校的频率明显高于乙校的频率,依据频率稳定于概率的原理,我们可以推断P(Y=1|X=0)>P(Y=1|X=1).
也就是说,如果从甲校和乙校各随机选取一名学生,那么甲校学生数学成绩优秀的概率大于乙校学生数学成绩优秀的概率,因此,可以认为两校学生的数学成绩优秀率存在差异,甲校学生的数学成绩优秀率比乙校学生的高。
学校 数学成绩 合计
不优秀(Y=0) 优秀(Y=1)
甲校(X=0) 33 10 43
乙校(X=1) 38 7 45
合计 71 17 88
问题2.有可能; “两校学生的数学成绩优秀率存在差异”这个结论是根据两个频率间存在差异推断出来的.有可能出现这种情况:在随机抽取的这个样本中,两个频率间确实存在差异,但两校学生的数学成绩优秀率实际上是没有差别的.对于随机样本而言,因为频率具有随机性,频率与概率之间存在误差,所以我们的推断可能犯错误,而且在样本容量较小时,犯错误的可能性会较大.因此,需要找到一种更为合理的推断方法,同时也希望能对出现错误推断的概率有一定的控制或估算.
考虑以Ω为样本空间的古典概型,设X和Y为定义在Ω上,取值于{0,1}的成对分类变量,我们希望判断事件{X=1}和{Y=1}之间是否有关联。注意到{X=0}和{X=1}, {Y=0}和{Y=1}都是互对立事件,与前面的讨论类似,我们需要判断下面的假定关系H0:P(Y=1|X=0)=P(Y=1|X=1)是否成立,通常称H0为零假设或原假设(null hypothesis).
P(Y=1|X=0)表示从{X=0}中随机选取一个样本点,该样本点属于{X=0,Y=1}的概率;
P(Y=1|X=1)表示从{X=1}中随机选取一个样本点,该样本点属于{X=1,Y=1}的概率。
由条件概率的定义可知,零假设H0等价于=
或P(X=0,Y=1)P(X=1)=P(X=1,Y=1)P(X=0). ①
考虑以Ω为样本空间的古典概型,设X和Y为定义在Ω上,取值于{0,1}的成对分类变量,我们希望判断事件{X=1}和{Y=1}之间是否有关联。注意到{X=0}和{X=1}, {Y=0}和{Y=1}都是互对立事件,与前面的讨论类似,我们需要判断下面的假定关系H0:P(Y=1|X=0)=P(Y=1|X=1)是否成立,通常称H0为零假设或原假设(null hypothesis).
P(Y=1|X=0)表示从{X=0}中随机选取一个样本点,该样本点属于{X=0,Y=1}的概率;
P(Y=1|X=1)表示从{X=1}中随机选取一个样本点,该样本点属于{X=1,Y=1}的概率。
由条件概率的定义可知,零假设H0等价于=
或P(X=0,Y=1)P(X=1)=P(X=1,Y=1)P(X=0). ①
注意到(X=0)和(X=1)为对立事件,于是P(X=0)=1-P(X=1).
再由概率的性质,我们有P(X=0,Y=1)=P(Y=1)-P(X=1,Y=1).
由此推得①式等价于P(X=1)P(Y=1)=P(X=1,Y=1).
因此,零假设H0等价于{X=1}与{Y=1}独立。
根据已经学过的概率知识,下面的四条性质彼此等价:
{ X=0}与{Y=0}独立;{X=0}与{Y=1}独立;{X=1}与{Y=0}独立;{X=1}与{Y=1}独立。
以上性质成立,我们就称分类变量X和Y独立,这相当于下面四个等式成立;
P(X=0,Y=0)=P(X=0)P(Y=0); P(X=0,Y=1)=P(X=0)P(Y=1);
P(X=1,Y=0)=P(X=1)P(Y=0); P(X=1,Y=1)=P(X=1)P(Y=1). ②
我们可以用概率语言,将零假设改述为H0:分类变量X和Y独立.
假定我们通过简单随机抽样得到了X和Y的抽样数据列联表,如下表所示。
表是关于分类变量X和Y的抽样数据的2×2列联表:最后一行的前两个数分别是事件{Y=0}和{Y=1}的频数;最后一列的前两个数分别是事件{X=0}和{X=1}的频数;中间的四个数a,b,c,d是事件{X=x,Y=y}(x, y=0,1)的频数;右下角格中的数n是样本容量。
X Y 合计
Y=0 Y=1
X=0 a b a+b
X=1 c d c+d
合计 a+c b+d n=a+b+c+d
问题3:在零假设H0成立的条件下,根据频率稳定于概率的原理,由②中的第一个等式,我们可以用概率P(X=0)和P(Y=0)对应的频率的乘积估计概率P(X=0,Y=0),而把视为事件{X=0.Y=0}发生的频数的期望值(或预期值).
这样,该频数的观测值a和期望值应该比较接近.
综合②中的四个式子,如果零假设H0成立,下面四个量的取值都不应该太大:
|, |, |, | ③
反之,当这些量的取值较大时,就可以推断H0不成立。
分别考虑③中的四个差的绝对值很困难,我们需要找到一个既合理又能够计算分布的统计量,来推断H0是否成立.
一般来说,若频数的期望值较大,则③中相应的差的绝对值也会较大;
而若频数的期望值较小,则③中相应的差的绝对值也会较小.
为了合理地平衡这种影响,我们将四个差的绝对值取平方后分别除以相应的期望值再求和,得到如下的统计量:
该表达式可化简为:.
统计学家建议,用随机变量取值的大小作为判断零假设H0是否成立的依据,当它比较大时推断H0不成立,否则认为H0成立.
问题4:那么,究竟大到什么程度,可以推断H0不成立呢 或者说,怎样确定判断大小的标准呢
根据小概率事件在一次试验中不大可能发生的规律, 可以通过确定一个与H0相矛盾的小概率事件来实现,在假定H0的条件下,对于有放回简单随机抽样,当样本容量n充分大时,统计学家得到了的近似分布,忽略的实际分布与该近似分布的误差后,对于任何小概率值α,可以找到相应的正实数xα,
使得下面关系成立:P(≥xα)=α ④
我们称xα为α的临界值,这个临界值就可作为判断大小的标准,概率值α越小,临界值xα越大,当总体很大时,抽样有、无放回对的分布影响较小.因此,在应用中往往不严格要求抽样必须是有放回的.
由④式可知,只要把概率值α取得充分小,在假设H0成立的情况下,事件不大可能发生的.根据这个规律,如果该事件发生,我们就可以推断H0不成立.不过这个推断有可能犯错误,但犯错误的概率不会超过α.
例2: 解:零假设为H0:分类变量X与Y相互独立,即两校学生的数学成绩优秀率无差异.
因为
学校 数学成绩 合计
不优秀(Y=0) 优秀(Y=1)
甲校(X=0) 33 10 43
乙校(X=1) 38 7 45
合计 71 17 88
所以x0.1
根据小概率值=0.1的独立性检验,没有充分证据推断H0不成立,因此可以认为H0成立,即认为两校的数学成绩优秀率没有差异。
问题5.例1只是根据一个样本的两个频率间存在差异得出两校学生数学成绩优秀率有差异的结论,并没有考虑由样本随机性可能导致的错误,所以那里的推断依据不太充分,在本例中,我们用独立性检验对零假设H0进行了检验,通过计算,发现≈0.837小于α=0.1所对应的临界值2.706,因此认为没有充分证据推断H0不成立,所以接受H0,推断出两校学生的数学优秀率没有显著差异的结论,
这个检验结果意味着,抽样数据中两个频率的差异很有可能是由样本随机性导致的,因此,只根据频率的差异得出两校学生的数学成绩优秀率有差异的结论是不可靠的。
由此可见,相对于简单比较两个频率的推断,用独立性检验得到的结果更理性、更全面,理论依据也更充分。
当我们接受零假设H0时,也可能犯错误。我们不知道犯这类错误的概率p的大小,但是知道,若α越大,则p越小
例3.解:零假设为H0:疗法与疗效独立,即两种疗法效果没有差异.
将所给数据进行整理,得到两种疗法治疗数据的列联表,
疗法 疗效 合计
未治愈 治愈
甲 15 52 67
乙 6 63 69
合计 21 115 136
根据列联表中的数据,经计算得到
根据小概率值=0.005的独立性检验,没有充分证据推断 H0不成立,因此可以认为 H0成立,即认为两种疗法效果没有差异.
问题6.若对调两种疗法的位置或对调两种疗效的位置,这样做会影响取值的计算结果吗?
疗法 疗效 合计
未治愈 治愈
甲 15 52 67
乙 6 63 69
合计 21 115 136
疗法 疗效 合计
未治愈 治愈
乙 6 63 69
甲 15 52 67
合计 21 115 136
疗法 疗效 合计
治愈 未治愈
甲 52 15 67
乙 63 6 69
合计 115 21 136
不影响
例4. 解:零假设为H0:吸烟和患肺癌之间没有关系根据列联表中的数据,经计算的
吸烟 肺癌 合计
非肺癌患者 肺癌患者
非吸烟者 7775 42 7817
吸烟者 2099 49 2148
合计 9874 91 9965
根据小概率值α=0.001的独立性检验,推断H0不成立,即认为吸 烟与患肺癌有关联,此推断犯错误的概率不大于0.001,即我们有99.9%的把握认为“吸烟与患肺癌有关系”.
根据表中的数据计算不吸烟者中不患肺癌和患肺癌的频率分别为
吸烟者中不患肺癌和患肺癌的评率分别为
,
由
可见,在被调查者中,吸烟者患肺癌的频率是不吸烟者患肺癌频率的4倍以上。于是,根据频率稳定于概率的原理,我们可以认为吸烟者患肺癌的概率明显大于不吸烟者患肺癌概率,即吸烟更容易引发肺癌。
跟踪训练1. 解:∵a=21,b=23,c=6,d=29,n=79,
∴=.=≈8.106,
且P(≥7.879)≈0.005,
即我们得到的的观测值χ≈8.106超过7.879这就意味着:“喜欢体育还是文娱与性别没有关系”这一结论成立的可能性小于0.005,即在犯错误的概率不超过0.005的前提下认为“喜欢体育还是喜欢文娱与性别有关.”
P(χ≥x0) 0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005 0.001
x0 0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828
达标检测
1. 解析:独立性检验是判断两个分类变量是否有关系的方法,而①③都是概率问题,不能用独立性检验解决.
答案:B
2.计算得χ2=≈5.059>3.841.
答案:D
3. χ2=≈4.844.
答案:95%
4. 解:设H0:感冒与是否使用该血清没有关系。
因当H0成立时, χ2≥6.635的概率约为0.01,故有99%的把握认为该血清能起到预防感冒的作用。
P(χ≥x0) 0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005 0.001
x0 0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828
5.解:(1)列联表如下:
所以能在犯错误的概率不超过0.05的前提下认为感染呼吸系统疾病与工作场所有关.
室外工作 室内工作 总计
有呼吸系统疾病 150 200 350
无呼吸系统疾病 50 100 150
总 计 200 300 500
(2)χ2=≈3.968>3.841.
(3)采用分层抽样从室内工作的居民中抽取6名,其中有呼吸系统疾病的抽4人,无呼吸系统疾病的抽2人,设A为“从中随机地抽取两人,两人都有呼吸系统疾病”,则
P(A)=.
1
学习目标
1.通过对典型案例的探究,了解独立性检验(只要求2×2列联表)的基本思想、方法
及初步应用.
2.通过对数据的收集、整理和分析,增强学生的社会实践能力,培养学生分析问题、
解决问题的能力.
重点难点
重点:了解独立性检验(只要求2×2列联表)的应用.
难点:独立性检验(只要求2×2列联表)的基本思想、方法
知识梳理
1. 分类变量
为了表述方便,我们经常会使用一种特殊的随机变量,以区别不同的现象或性质,这类随机变量称为分类变量.分类变量的取值可以用实数表示,例如,学生所在的班级可以用1,2,3等表示,男性、女性可以用1,0表示,等等.
2. 2×2列联表
表是关于分类变量X和Y的抽样数据的2×2列联表:最后一行的前两个数分别是事件{Y=0}和{Y=1}的频数;最后一列的前两个数分别是事件{X=0}和{X=1}的频数;中间的四个数a,b,c,d是事件{X=x,Y=y}(x, y=0,1)的频数;右下角格中的数n是样本容量。
X Y 合计
Y=0 Y=1
X=0 a b a+b
X=1 c d c+d
合计 a+c b+d n=a+b+c+d
3.两个分类变量之间关联关系的定性分析的方法:
(1)频率分析法:通过对样本的每个分类变量的不同类别事件发生的频率大小进行比较来分析分类变量之间是否有关联关系.如可以通过列联表中值的大小粗略地判断分类变量x和Y之间有无关系.一般其值相差越大,分类变量有关系的可能性越大.
(2)图形分析法:与表格相比,图形更能直观地反映出两个分类变 量间是否互相影响,常用等高堆积条形图展示列联表数据的频率特征.将列联表中的数据用高度相同的两个条形图表示出来,其中两列的数据分别对应不同的颜色,这就是等高堆积条形图.
等高堆积条形图可以展示列联表数据的频率特征,能够直观地反映出两个分类变量间是否相互影响.
4.独立性检验公式及定义:
提出零假设(原假设)H0:分类变量X和Y独立,假定我们通过简单随机抽样得到了X和Y的抽样数据列联表,在列联表中,如果零假设H0成立,则应满足,即ad-bc≈0.因此|ad bc|越小,说明两个分类变量之间关系越弱;|ad bc|越大,说明两个分类变量之间关系越强.
为了使不同样本容量的数据有统一的评判标准,基于上述分析,我们构造一个随机变量.
X Y 合计
Y=0 Y=1
X=0 a b a+b
X=1 c d c+d
合计 a+c b+d n=a+b+c+d
5.临界值的定义:
对于任何小概率值α,可以找到相应的正实数xα,使得P(χ2≥xα)=α成立,我们称xα为α的临界值,这个临界值可作为判断χ2大小的标准,概率值α越小,临界值xα越大.
基于小概率值α的检验规则:
当χ2≥xα时,我们就推断H0不成立,即认为X和Y不独立,该推断犯错误的概率不超过α;
当χ2
χ2独立性检验中几个常用的小概率值和相应的临界值
α 0.1 0.05 0.01 0.005 0.001
xα 2.706 3.841 6.635 7.879 10.858
学习过程
问题探究
前面两节所讨论的变量,如人的身高、树的胸径、树的高度、短跑100m世界纪录和创纪录的时间等,都是数值变量,数值变量的取值为实数.其大小和运算都有实际含义.
在现实生活中,人们经常需要回答一定范围内的两种现象或性质之间是否存在关联性或相互影响的问题.例如,就读不同学校是否对学生的成绩有影响,不同班级学生用于体育锻炼的时间是否有差别,吸烟是否会增加患肺癌的风险,等等,本节将要学习的独立性检验方法为我们提供了解决这类问题的方案。
在讨论上述问题时,为了表述方便,我们经常会使用一种特殊的随机变量,以区别不同的现象或性质,这类随机变量称为分类变量.分类变量的取值可以用实数表示,例如,学生所在的班级可以用1,2,3等表示,男性、女性可以用1,0表示,等等.在很多时候,这些数值只作为编号使用,并没有通常的大小和运算意义,本节我们主要讨论取值于{0,1}的分类变量的关联性问题.
问题1. 为了有针对性地提高学生体育锻炼的积极性,某中学需要了解性别因素是否对本校学生体育锻炼的经常性有影响,为此对学生是否经常锻炼的情况进行了普查,全校学生的普查数据如下:523名女生中有331名经常锻炼;601名男生中有473名经常锻炼。你能利用这些数据,说明该校女生和男生在体育锻炼的经常性方面是否存在差异吗
二、典例解析
例1.为比较甲、乙两所学校学生的数学水平,采用简单随机抽样的方法抽取88名学生.通过测验得到了如下数据:甲校43名学生中有10名数学成绩优秀;乙校45名学生中有7名数学成绩优秀,试分析两校学生中数学成绩优秀率之间是否存在差异.
学校 数学成绩 合计
不优秀(Y=0) 优秀(Y=1)
甲校(X=0) 33 10 43
乙校(X=1) 38 7 45
合计 71 17 88
问题2.你认为“两校学生的数学成绩优秀率存在差异”这一结论是否有可能是错误的?
问题3:如何基于②中的四个等式及列联表中的数据,构造适当的统计量,对成对分类变量X和Y是否相互独立作出推断
问题4:那么,究竟大到什么程度,可以推断H0不成立呢 或者说,怎样确定判断大小的标准呢
例2:依据小概率值=0.1的独立性检验,分析例1中的抽样数据,能否据此推断两校学生的数学成绩优秀率有差异?
问题5.例1和例2都是基于同一组数据的分析,但却得出了不同的结论,你能说明其中的原因吗
例3.某儿童医院用甲、乙两种疗法治疗小儿消化不良.采用有放回简单随机抽样的方法对治疗情况进行检查,得到了如下数据:抽到接受甲种疗法的患儿67名,其中未治愈15名,治愈52名;抽到接受乙种疗法的患儿69名,其中未治愈6名,治愈63名.试根据小概率值=0.005的独立性检验,分析乙种疗法的效果是否比甲种疗法好.
问题6.若对调两种疗法的位置或对调两种疗效的位置,这样做会影响取值的计算结果吗?
例4.为了调查吸烟是否对肺癌有影响,某肿瘤研究所采取有放回简单随机抽样,调查了9965人,得到如下结果(单位:人)依据小概率值α=0.001的独立性检验,分析吸烟是否会增加患肺癌的风险。
吸烟 肺癌 合计
非肺癌患者 肺癌患者
非吸烟者 7775 42 7817
吸烟者 2099 49 2148
合计 9874 91 9965
应用独立性检验解决实际问题大致应包括以下几个主要环节:
(1)提出零假设H0:X和Y相互独立,并给出在问题中的解释.
(2)根据抽样数据整理出2×2列联表,计算的值,并与临界值比较.
(3)根据检验规则得出推断结论.
(4)在X和Y不独立的情况下,根据需要,通过比较相应的频率,分析X和Y间的影响规律.
注意:上述几个环节的内容可以根据不同情况进行调整,
例如,在有些时候,分类变量的抽样数据列联表是问题中给定的.
P(χ2≥x0) 0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005 0.001
x0 0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828
归纳总结
跟踪训练1.某校对学生的课外活动进行调查,结果整理成下表:
体育 文娱 总计
男生 21 23 44
女生 6 29 35
总计 27 52 79
试用你所学过的知识分析:能否在犯错误的概率不超过0.005的前提下,认为“喜欢体育还是文娱与性别有关系”?
达标检测
1.给出下列实际问题:
①一种药物对某种病的治愈率;②两种药物治疗同一种病是否有区别;
③吸烟者得肺病的概率;④吸烟是否与性别有关系;
⑤网吧与青少年的犯罪是否有关系.其中用独立性检验可以解决的问题有( )
A.①②③ B.②④⑤ C.②③④⑤ D.①②③④⑤
2.某班主任对全班50名学生进行了作业量多少的调查,数据如下表:
下列叙述中,正确的是( )
认为作业多 认为作业不多 总数
喜欢玩电脑游戏 18 9 27
不喜欢玩电脑游戏 8 15 23
总数 26 24 50
A.有99%的把握认为“喜欢玩电脑游戏与认为作业量的多少有关系”
B.有95%的把握认为“喜欢玩电脑游戏与认为作业量的多少无关系”
C.有99%的把握认为“喜欢玩电脑游戏与认为作业量的多少无关系”
D.有95%的把握认为“喜欢玩电脑游戏与认为作业量的多少有关系”
3.某高校《统计》课程的教师随机调查了选该课的一些学生情况,具体数据如下表:
为了判断主修统计专业是否与性别有关系,根据表中的数据,得到
专业 性别 非统计专业 统计专业
男 13 10
女 7 20
因为4.844>3.841,所以有 的把握判定主修统计专业与性别有关系.
4.在500人身上试验某种血清预防感冒作用,把他们一年中的感冒记录与另外500名未用血清的人的感冒记录作比较,结果如表所示。问:该种血清能否起到预防感冒的作用?
未感冒 感冒 合计
使用血清 258 242 500
未使用血清 216 284 500
合计 474 526 1000
5.随着工业化以及城市车辆的增加,城市的空气污染越来越严重,空气质量指数API一直居高不下,对人体的呼吸系统造成了严重的影响.现调查了某市500名居民的工作场所和呼吸系统健康情况,得到2×2列联表如下:
室外工作 室内工作 总计
有呼吸系统疾病 150
无呼吸系统疾病 100
总 计 200
(1)补全2×2列联表;
(2)能否在犯错误的概率不超过0.05的前提下认为感染呼吸系统疾病与工作场所有关
(3)现采用分层抽样从室内工作的居民中抽取一个容量为6的样本,将该样本看成一个总体,从中随机地抽取两人,求两人都有呼吸系统疾病的概率.
课堂小结
参考答案
知识梳理
学习过程
问题探究
问题1. 这是一个简单的统计问题,最直接的解答方法是,比较经常锻炼的学生在女生和男生中的比率,为了方便,我们设=, =
那么,只要求出f0和f1的值,通过比较这两个值的大小,就可以知道女生和男生在锻炼的经常性方面是否有差异,由所给的数据,经计算得到=≈0.633, =.
由f1-f0 0.787-0.633=0.154可知,男生经常锻炼的比率比女生高出15.4个百分点.
所以该校的女生和男生在体育锻等的经常性方面有差异,而且男生更经常锻炼.
用n表示该校全体学生构成的集合,这是我们所关心的对象的总体,考虑以n为样本空间的古典概型,并定义一对分类变量X和Y如下:对于Ω中的每一名学生,
分别令,,
“性别对体育锻炼的经常性没有影响”可以描述为P(Y=1|X=0)=P(Y=1|X=1);
“性别对体育锻炼的经常性有影响”可以描述为P(Y=1|X=0)≠P(Y=1|X=1).
我们希望通过比较条件概率P(Y=1|X=0)和P(Y=1|X=1)回答上面的问题.按照条件本概率的直观解释,
如果从该校女生和男生中各随机选取一名学生,那么该女生属于经常锻炼群体的概率是P(Y=1|X=0),
而该男生属于经常锻炼群体的概率是P(Y=1|X=1).
为了清楚起见,我们用表格整理数据
性别 锻炼 合计
不经常(Y=0) 经常(Y=1)
女生(X=0) 192 331 523
男生(X=1) 128 473 601
合计 320 804 1124
我们用{X=0,Y=1}表示事件{X=0}和{Y=1}的积事件,用{X=1,Y=1}表示事件{X=1}和{Y=1}的积事件,根据古典概型和条件概率的计算公式,我们有
P(Y=1|X=0)==≈0.633
P(Y=1|X=1)==≈0.787
由P(Y=1|X=1)>P(Y=1|X=0)
可以作出判断,在该校的学生中,性别对体育锻炼的经常性有影响,即该校的女生和男生在体育锻炼的经常性方面存在差异,而且男生更经常锻炼。
在实践中,由于保存原始数据的成本较高,人们经常按研究问题的需要,将数据分类统计,并做成表格加以保存,我们将下表这种形式的数据统计表称为2×2列联表(contingency table).
2×2列联表给出了成对分类变量数据的交叉分类频数,以右表为例,它包含了X和Y的如下信息:
最后一行的前两个数分别是事件{Y=0}和{Y=1}中样本点的个数;
最后一列的前两个数分别是事件{X=0}和{X=1}中样本点的个数;
中间的四个格中的数是表格的核心部分,给出了事件{X=x,Y=y}(x,y=0,1)中样本点的个数;
右下角格中的数是样本空间中样本点的总数。
性别 锻炼 合计
不经常(Y=0) 经常(Y=1)
女生(X=0) 192 331 523
男生(X=1) 128 473 601
合计 320 804 1124
二、典例解析
例1.解:用Ω表示两所学校的全体学生构成的集合.考虑以Ω为样本空间的古典概型.对于Ω中每一名学生,定义分类变量X和Y如下:,,
学校 数学成绩 合计
不优秀(Y=0) 优秀(Y=1)
甲校(X=0) 33 10 43
乙校(X=1) 38 7 45
合计 71 17 88
我们将所给数据整理成表(单位:人)
表是关于分类变量X和Y的抽样数据的2×2列联表:最后一行的前两个数分别是事件(Y=0)和(Y=1)的频数;最后一列的前两个数分别是事件(X=0)和(X=1)的频数;中间的四个格中的数是事件(X=x,Y=y)(x,y=0,1)的频数;
甲校学生中数学成绩不优秀和数学成绩优秀的频率分别为≈0.7674和≈ 0.2326;
乙校学生中数学成绩不优秀和数学成绩优秀的频率分别为≈ 0.8444和≈ 0.1556
我们可以用等高堆积条形图直观地展示上述计算结果,如图所示
左边的蓝色和红色条的高度分别是甲校学生中数学成绩不优秀和数学成绩优秀的频率;右边的蓝色和红色条的高度分别是乙校学生中数学成绩不优秀和数学成绩优秀的频率,通过比较发现,两个学校学生抽样数据中数学成绩优秀的频率存在差异,甲校的频率明显高于乙校的频率,依据频率稳定于概率的原理,我们可以推断P(Y=1|X=0)>P(Y=1|X=1).
也就是说,如果从甲校和乙校各随机选取一名学生,那么甲校学生数学成绩优秀的概率大于乙校学生数学成绩优秀的概率,因此,可以认为两校学生的数学成绩优秀率存在差异,甲校学生的数学成绩优秀率比乙校学生的高。
学校 数学成绩 合计
不优秀(Y=0) 优秀(Y=1)
甲校(X=0) 33 10 43
乙校(X=1) 38 7 45
合计 71 17 88
问题2.有可能; “两校学生的数学成绩优秀率存在差异”这个结论是根据两个频率间存在差异推断出来的.有可能出现这种情况:在随机抽取的这个样本中,两个频率间确实存在差异,但两校学生的数学成绩优秀率实际上是没有差别的.对于随机样本而言,因为频率具有随机性,频率与概率之间存在误差,所以我们的推断可能犯错误,而且在样本容量较小时,犯错误的可能性会较大.因此,需要找到一种更为合理的推断方法,同时也希望能对出现错误推断的概率有一定的控制或估算.
考虑以Ω为样本空间的古典概型,设X和Y为定义在Ω上,取值于{0,1}的成对分类变量,我们希望判断事件{X=1}和{Y=1}之间是否有关联。注意到{X=0}和{X=1}, {Y=0}和{Y=1}都是互对立事件,与前面的讨论类似,我们需要判断下面的假定关系H0:P(Y=1|X=0)=P(Y=1|X=1)是否成立,通常称H0为零假设或原假设(null hypothesis).
P(Y=1|X=0)表示从{X=0}中随机选取一个样本点,该样本点属于{X=0,Y=1}的概率;
P(Y=1|X=1)表示从{X=1}中随机选取一个样本点,该样本点属于{X=1,Y=1}的概率。
由条件概率的定义可知,零假设H0等价于=
或P(X=0,Y=1)P(X=1)=P(X=1,Y=1)P(X=0). ①
考虑以Ω为样本空间的古典概型,设X和Y为定义在Ω上,取值于{0,1}的成对分类变量,我们希望判断事件{X=1}和{Y=1}之间是否有关联。注意到{X=0}和{X=1}, {Y=0}和{Y=1}都是互对立事件,与前面的讨论类似,我们需要判断下面的假定关系H0:P(Y=1|X=0)=P(Y=1|X=1)是否成立,通常称H0为零假设或原假设(null hypothesis).
P(Y=1|X=0)表示从{X=0}中随机选取一个样本点,该样本点属于{X=0,Y=1}的概率;
P(Y=1|X=1)表示从{X=1}中随机选取一个样本点,该样本点属于{X=1,Y=1}的概率。
由条件概率的定义可知,零假设H0等价于=
或P(X=0,Y=1)P(X=1)=P(X=1,Y=1)P(X=0). ①
注意到(X=0)和(X=1)为对立事件,于是P(X=0)=1-P(X=1).
再由概率的性质,我们有P(X=0,Y=1)=P(Y=1)-P(X=1,Y=1).
由此推得①式等价于P(X=1)P(Y=1)=P(X=1,Y=1).
因此,零假设H0等价于{X=1}与{Y=1}独立。
根据已经学过的概率知识,下面的四条性质彼此等价:
{ X=0}与{Y=0}独立;{X=0}与{Y=1}独立;{X=1}与{Y=0}独立;{X=1}与{Y=1}独立。
以上性质成立,我们就称分类变量X和Y独立,这相当于下面四个等式成立;
P(X=0,Y=0)=P(X=0)P(Y=0); P(X=0,Y=1)=P(X=0)P(Y=1);
P(X=1,Y=0)=P(X=1)P(Y=0); P(X=1,Y=1)=P(X=1)P(Y=1). ②
我们可以用概率语言,将零假设改述为H0:分类变量X和Y独立.
假定我们通过简单随机抽样得到了X和Y的抽样数据列联表,如下表所示。
表是关于分类变量X和Y的抽样数据的2×2列联表:最后一行的前两个数分别是事件{Y=0}和{Y=1}的频数;最后一列的前两个数分别是事件{X=0}和{X=1}的频数;中间的四个数a,b,c,d是事件{X=x,Y=y}(x, y=0,1)的频数;右下角格中的数n是样本容量。
X Y 合计
Y=0 Y=1
X=0 a b a+b
X=1 c d c+d
合计 a+c b+d n=a+b+c+d
问题3:在零假设H0成立的条件下,根据频率稳定于概率的原理,由②中的第一个等式,我们可以用概率P(X=0)和P(Y=0)对应的频率的乘积估计概率P(X=0,Y=0),而把视为事件{X=0.Y=0}发生的频数的期望值(或预期值).
这样,该频数的观测值a和期望值应该比较接近.
综合②中的四个式子,如果零假设H0成立,下面四个量的取值都不应该太大:
|, |, |, | ③
反之,当这些量的取值较大时,就可以推断H0不成立。
分别考虑③中的四个差的绝对值很困难,我们需要找到一个既合理又能够计算分布的统计量,来推断H0是否成立.
一般来说,若频数的期望值较大,则③中相应的差的绝对值也会较大;
而若频数的期望值较小,则③中相应的差的绝对值也会较小.
为了合理地平衡这种影响,我们将四个差的绝对值取平方后分别除以相应的期望值再求和,得到如下的统计量:
该表达式可化简为:.
统计学家建议,用随机变量取值的大小作为判断零假设H0是否成立的依据,当它比较大时推断H0不成立,否则认为H0成立.
问题4:那么,究竟大到什么程度,可以推断H0不成立呢 或者说,怎样确定判断大小的标准呢
根据小概率事件在一次试验中不大可能发生的规律, 可以通过确定一个与H0相矛盾的小概率事件来实现,在假定H0的条件下,对于有放回简单随机抽样,当样本容量n充分大时,统计学家得到了的近似分布,忽略的实际分布与该近似分布的误差后,对于任何小概率值α,可以找到相应的正实数xα,
使得下面关系成立:P(≥xα)=α ④
我们称xα为α的临界值,这个临界值就可作为判断大小的标准,概率值α越小,临界值xα越大,当总体很大时,抽样有、无放回对的分布影响较小.因此,在应用中往往不严格要求抽样必须是有放回的.
由④式可知,只要把概率值α取得充分小,在假设H0成立的情况下,事件不大可能发生的.根据这个规律,如果该事件发生,我们就可以推断H0不成立.不过这个推断有可能犯错误,但犯错误的概率不会超过α.
例2: 解:零假设为H0:分类变量X与Y相互独立,即两校学生的数学成绩优秀率无差异.
因为
学校 数学成绩 合计
不优秀(Y=0) 优秀(Y=1)
甲校(X=0) 33 10 43
乙校(X=1) 38 7 45
合计 71 17 88
所以x0.1
根据小概率值=0.1的独立性检验,没有充分证据推断H0不成立,因此可以认为H0成立,即认为两校的数学成绩优秀率没有差异。
问题5.例1只是根据一个样本的两个频率间存在差异得出两校学生数学成绩优秀率有差异的结论,并没有考虑由样本随机性可能导致的错误,所以那里的推断依据不太充分,在本例中,我们用独立性检验对零假设H0进行了检验,通过计算,发现≈0.837小于α=0.1所对应的临界值2.706,因此认为没有充分证据推断H0不成立,所以接受H0,推断出两校学生的数学优秀率没有显著差异的结论,
这个检验结果意味着,抽样数据中两个频率的差异很有可能是由样本随机性导致的,因此,只根据频率的差异得出两校学生的数学成绩优秀率有差异的结论是不可靠的。
由此可见,相对于简单比较两个频率的推断,用独立性检验得到的结果更理性、更全面,理论依据也更充分。
当我们接受零假设H0时,也可能犯错误。我们不知道犯这类错误的概率p的大小,但是知道,若α越大,则p越小
例3.解:零假设为H0:疗法与疗效独立,即两种疗法效果没有差异.
将所给数据进行整理,得到两种疗法治疗数据的列联表,
疗法 疗效 合计
未治愈 治愈
甲 15 52 67
乙 6 63 69
合计 21 115 136
根据列联表中的数据,经计算得到
根据小概率值=0.005的独立性检验,没有充分证据推断 H0不成立,因此可以认为 H0成立,即认为两种疗法效果没有差异.
问题6.若对调两种疗法的位置或对调两种疗效的位置,这样做会影响取值的计算结果吗?
疗法 疗效 合计
未治愈 治愈
甲 15 52 67
乙 6 63 69
合计 21 115 136
疗法 疗效 合计
未治愈 治愈
乙 6 63 69
甲 15 52 67
合计 21 115 136
疗法 疗效 合计
治愈 未治愈
甲 52 15 67
乙 63 6 69
合计 115 21 136
不影响
例4. 解:零假设为H0:吸烟和患肺癌之间没有关系根据列联表中的数据,经计算的
吸烟 肺癌 合计
非肺癌患者 肺癌患者
非吸烟者 7775 42 7817
吸烟者 2099 49 2148
合计 9874 91 9965
根据小概率值α=0.001的独立性检验,推断H0不成立,即认为吸 烟与患肺癌有关联,此推断犯错误的概率不大于0.001,即我们有99.9%的把握认为“吸烟与患肺癌有关系”.
根据表中的数据计算不吸烟者中不患肺癌和患肺癌的频率分别为
吸烟者中不患肺癌和患肺癌的评率分别为
,
由
可见,在被调查者中,吸烟者患肺癌的频率是不吸烟者患肺癌频率的4倍以上。于是,根据频率稳定于概率的原理,我们可以认为吸烟者患肺癌的概率明显大于不吸烟者患肺癌概率,即吸烟更容易引发肺癌。
跟踪训练1. 解:∵a=21,b=23,c=6,d=29,n=79,
∴=.=≈8.106,
且P(≥7.879)≈0.005,
即我们得到的的观测值χ≈8.106超过7.879这就意味着:“喜欢体育还是文娱与性别没有关系”这一结论成立的可能性小于0.005,即在犯错误的概率不超过0.005的前提下认为“喜欢体育还是喜欢文娱与性别有关.”
P(χ≥x0) 0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005 0.001
x0 0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828
达标检测
1. 解析:独立性检验是判断两个分类变量是否有关系的方法,而①③都是概率问题,不能用独立性检验解决.
答案:B
2.计算得χ2=≈5.059>3.841.
答案:D
3. χ2=≈4.844.
答案:95%
4. 解:设H0:感冒与是否使用该血清没有关系。
因当H0成立时, χ2≥6.635的概率约为0.01,故有99%的把握认为该血清能起到预防感冒的作用。
P(χ≥x0) 0.50 0.40 0.25 0.15 0.10 0.05 0.025 0.010 0.005 0.001
x0 0.455 0.708 1.323 2.072 2.706 3.841 5.024 6.635 7.879 10.828
5.解:(1)列联表如下:
所以能在犯错误的概率不超过0.05的前提下认为感染呼吸系统疾病与工作场所有关.
室外工作 室内工作 总计
有呼吸系统疾病 150 200 350
无呼吸系统疾病 50 100 150
总 计 200 300 500
(2)χ2=≈3.968>3.841.
(3)采用分层抽样从室内工作的居民中抽取6名,其中有呼吸系统疾病的抽4人,无呼吸系统疾病的抽2人,设A为“从中随机地抽取两人,两人都有呼吸系统疾病”,则
P(A)=.
1