6.1实时查询系统中数据的组织课件-2021-2022学年浙教版(2019)高中信息技术选修1(23张PPT)
文档属性
| 名称 | 6.1实时查询系统中数据的组织课件-2021-2022学年浙教版(2019)高中信息技术选修1(23张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 613.5KB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2022-05-23 00:00:00 | ||
图片预览






文档简介
(共23张PPT)
6.1 实时查询系统中数据的组织
实
时
查
询
大数据背景下,全部数据的组织、存储和处理,仅凭单个服务器和数据库
的数据组织与存储方式,无论从存储容量还是处理速度上都不能满足实际
应用的需求。
此时,采用分布式存储技术,将所有数据分别保存在不同的服务器中,
需要时从中提取并进行合并,就可以满足海量数据的存储与处理需求。
分布式存储系统利用分布在不同物理位置的服务器来分担系统存储任务,
既能提高数据存储的安全性,又能提升系统数据访问的速度,同时也具有
较好的可扩展性。当用户提出访问请求时,系统根据元数据服务器(进行
数据访问索引的服务器)将访问定位到目标数据的服务器上。
实时查询系统中的数据业务特点
1.能实现上千个请求的实时响应。网站应能做到
“即点即现”。
2.支持后续商品信息的更改。如删除、增加商品。
面对这种查询业务,为了减轻磁盘数据库访问的负
担,可事先将数据库中的商品信息读取出来并保存
在内存中,这样用户的查询就能直接面对内存进行,
大大提高数据读取的速度。
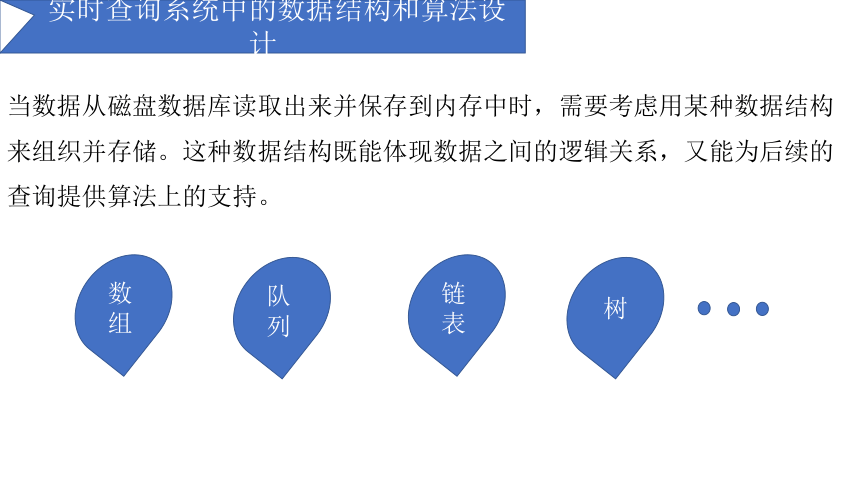
实时查询系统中的数据结构和算法设计
当数据从磁盘数据库读取出来并保存到内存中时,需要考虑用某种数据结构
来组织并存储。这种数据结构既能体现数据之间的逻辑关系,又能为后续的
查询提供算法上的支持。
数组
链表
队列
树
1.基于数据间线性关系的数据结构设计
(1)数组
数据从数据库中读取到数组后,可事先按照各个属性(如人气、销量、
信用、价格等)进行排序并分类存储,当用户发出相应的请求时,系统
就从已排序数组中选择符合用户查询要求的内容呈现给用户。
基于这种数据结构的问题主要出现在后续的商品信息维护阶段。当商家
增加了新品时,系统需要在数组中插入一个新数据并维持数组元素继续
有序。
查找:即在一个有序序列中查找新增元素的插入位置,可以采用二分查找
算法,时间复杂度为O()(n表示数组元素的总个数),速度比较快。
插入:即在找到可以插入的位置x后,将新元素插入到找到的位置x中,但
必须先将位置x到n之间的所有元素往后移一位,为新元素空出位置,这个
时间复杂度就比较大,为O(n)。当瞬间有上千名用户提出请求,同时进行
上千个这样的处理时,时效性较差。
(2)链表
针对在数组中插入新元素时引起的数据移动低效的问题,可以考虑用链表
代替数组。因为在一个链表中插入一个新元素,时间复杂度为O(1),大大优
于采用数组时O(n)的线性复杂度。
插入操作主要涉及查找和插入两个关键操作,链表虽然在插入操作时能确保
O(1)的时间复杂度,但在进行查找时(查找新元素的插入位置),却需要从
链表的一端依次遍历查找,时间复杂度为O(n)。因此,采用链表来存储数据,
虽然整体复杂度有所下降,但O(n)的复杂度还是达不到现实的需求。
2.基于链表的数据结构和算法优化设计
基于链表的处理,只是在查找时效率较低,而插入操作却完全能满足要求,所以可以在链表的基础上继续加以改进,以解决顺序查找导致的低效问题。主要考虑从查找角度来优化数据结构,这个改进可按以下思路进行。
(1)减少查找插入位置过程中的比较次数
基于链表数据结构的处理时间主要消耗在插入位置的查找中,因此,可着眼减少查找过程中的数据两两比较的次数来优化数据结构。
(2)借鉴二分查找算法的思想
二分查找算法之所以效率较高,首先是因为数据是有序的,其次是利用
有序性进行跨区间、跳跃性的比较,从而避免低效的逐个依次比较。
实现的思路是首先将数据进行有序化处理,然后想二分查找一样确定比较
的关键节点,根据新元素与关键节点的比较结果来高效地取舍剩余的查找
区间。
1
3
4
10
13
15
20
原链表
1
4
10
15
关键节点
在原链表基础上增设关键节点
1
3
4
10
13
15
20
原链表
1
4
10
15
关键节点
6
通过关键节点只需比较3次
由此可见,关键节点起到一个索引表的作用,帮助算法快速定位到一个较
小的插入区间,然后只需将索引位置对应到原链表,即可找到最终的插入
位置。
插入位置
按照同样的方法再增设一批关键节点,为原来的一级索引建立二级索引,
则可以进一步将查找速度提升2倍。
1
3
4
10
13
15
20
原链表
1
4
10
15
一级索引
1
10
二级索引
在原来基础上建立二级索引
在二级索引的基础上,若要插入新元素6,则先从二级索引中经过2次比较
确定一个大致区间,然后通过对应关系到达一级索引,最终到达原链表中
可插入的位置,这样就可将在原一级索引中的顺序比较次数减少一半。如
果数据比较多,还可以在此基础上继续增设三、四级索引,进一步提高查
找的速度。总体来说,通过对链表进行改进的数据结构可以用O()的
时间复杂度实现查找,然后进行新元素的插入,并且保证新序列仍然有序。
因为数据序列在不断地变化,所以需要对关键节点进行动态的调整,即数据
增加时增设关键节点,而数据减少时删除关键节点。对各级索引表中的关键
节点进行增加和删除的实现方法如下:
①增设关键节点
1
3
4
10
13
15
20
24
1
1
4
10
15
24
10
第一次抛硬币,结果是“正”,因此把
节点24提升到上一层索引
将新增元素24所在节点提升为关键节点
1
3
4
10
13
15
20
24
1
1
4
10
15
10
新增元素24所在节点不提升为关键节点
若通过“抛硬币”发现不需要提升为关键节点,则新的链表组织结构如图
所示(新增元素只在原链表中出现)。
②删除关键节点
随着原链表中数据元素的不断删除,各级索引中的关键节点也需要随之
删除。删除时按照查找时的层次从上往下依次进行,每当找到对应的元素,
就删除当前层的关键节点,直到最底层的原链表。若原来链表的状态如下图
所示,现在要删除原链表中的元素10,则从顶层索引开始,依次往下删除
各层的元素10。
1
3
4
10
13
15
20
原链表
1
4
10
15
一级索引
1
10
二级索引
删除前
1
3
4
13
15
20
原链表
1
4
15
一级索引
删除元素10之后的链表状态
二级索引中删除元素10所在的节点后,因为只剩下一个关键节点,对于区间
划分和提高查找效率没有任何意义,所以将剩下一个节点也删除,得到的最
终状态如上图所示。
因为上述数据结构是在一个有序链表中通过索引表跳跃着进行查找,所以
称为“跳跃表”,跳跃表是William Pugh于1990年发明并提出的一种数
据结构。
从数组到链表,再到跳跃表,可以发现,一个切合实际的数据结构和算法
不是一蹴而就的,而是根据问题中数据及其关系的特点,通过迭代逐步优
化得到的。
“跳跃表”是立足链表,借鉴二分查找的思想而
形成的数据结构。能否立足有序数组,借鉴链表
的思想构造一种新的数据结构来解决上述问题?
有序数组在查找数据方面的效率较高,主要的低效源于插入新数据后,该
数据后续数据元素线性复杂度的数据元素连续后移所致,因此可以针对如
何降低后移的复杂度思考优化方案。比如将原来一个数组中的数据均匀地
分解存储到k个数组中,这样就将原来O(n)的移动复杂度降为O(),虽然
数量级没变,但至少是原来的k倍速度。
其他数据组织与处理方式
人们针对磁盘数据库存在的瓶颈,发明了内存数据库。大部分的内存数据库主要从以下几个方面来提升数据的处理性能。
1.减少对磁盘的访问
内存数据库就是将需要处理的数据保存在内存中并直接操作的数据库。
因为内存的数据读写速度比磁盘高出几个数量级,所以内存数据库首先
在数据的输入和输出上极大地提高了系统的性能。相比于传统的磁盘数
据库,内存数据库可以将数据处理速度提高至少10倍以上,理想状态下
甚至可达到1000倍。
2.对数据进行分级存储
内存数据库对所有需要处理的数据重新进行组织,并根据应用需要将数据
分级,再在处理器缓存中进行分级存储。由于处理器缓存速度高于内存,
因此进一步提升了数据的存取效率。
3.采用改进后的数据结构来组织、存储数据
内存数据库还能将全部数据在内存中进行重新组织、存储,进行新的体系
结构设计,用更快速的算法来处理数据,并运用支持快速算法的数据结构
来组织数据。例如,AT&T Bell实验室的Silicon数据库核心组织用AVL树
(一种平衡树)作为索引结构来提高查找速度;Redis数据库运用了Sorted-
set技术,而Sorted-set这种有序集合技术正是对跳跃表的改进和应用。
练习
内存数据库具有传统磁盘数据库无可比拟的优点,下列说法正确的是
( )
A.减少了对磁盘的访问
B.对数据进行分级存储
C.采用了改进后的数据结构
D.内存数据库不能用于实时查询
ABC
谢 谢
6.1 实时查询系统中数据的组织
实
时
查
询
大数据背景下,全部数据的组织、存储和处理,仅凭单个服务器和数据库
的数据组织与存储方式,无论从存储容量还是处理速度上都不能满足实际
应用的需求。
此时,采用分布式存储技术,将所有数据分别保存在不同的服务器中,
需要时从中提取并进行合并,就可以满足海量数据的存储与处理需求。
分布式存储系统利用分布在不同物理位置的服务器来分担系统存储任务,
既能提高数据存储的安全性,又能提升系统数据访问的速度,同时也具有
较好的可扩展性。当用户提出访问请求时,系统根据元数据服务器(进行
数据访问索引的服务器)将访问定位到目标数据的服务器上。
实时查询系统中的数据业务特点
1.能实现上千个请求的实时响应。网站应能做到
“即点即现”。
2.支持后续商品信息的更改。如删除、增加商品。
面对这种查询业务,为了减轻磁盘数据库访问的负
担,可事先将数据库中的商品信息读取出来并保存
在内存中,这样用户的查询就能直接面对内存进行,
大大提高数据读取的速度。
实时查询系统中的数据结构和算法设计
当数据从磁盘数据库读取出来并保存到内存中时,需要考虑用某种数据结构
来组织并存储。这种数据结构既能体现数据之间的逻辑关系,又能为后续的
查询提供算法上的支持。
数组
链表
队列
树
1.基于数据间线性关系的数据结构设计
(1)数组
数据从数据库中读取到数组后,可事先按照各个属性(如人气、销量、
信用、价格等)进行排序并分类存储,当用户发出相应的请求时,系统
就从已排序数组中选择符合用户查询要求的内容呈现给用户。
基于这种数据结构的问题主要出现在后续的商品信息维护阶段。当商家
增加了新品时,系统需要在数组中插入一个新数据并维持数组元素继续
有序。
查找:即在一个有序序列中查找新增元素的插入位置,可以采用二分查找
算法,时间复杂度为O()(n表示数组元素的总个数),速度比较快。
插入:即在找到可以插入的位置x后,将新元素插入到找到的位置x中,但
必须先将位置x到n之间的所有元素往后移一位,为新元素空出位置,这个
时间复杂度就比较大,为O(n)。当瞬间有上千名用户提出请求,同时进行
上千个这样的处理时,时效性较差。
(2)链表
针对在数组中插入新元素时引起的数据移动低效的问题,可以考虑用链表
代替数组。因为在一个链表中插入一个新元素,时间复杂度为O(1),大大优
于采用数组时O(n)的线性复杂度。
插入操作主要涉及查找和插入两个关键操作,链表虽然在插入操作时能确保
O(1)的时间复杂度,但在进行查找时(查找新元素的插入位置),却需要从
链表的一端依次遍历查找,时间复杂度为O(n)。因此,采用链表来存储数据,
虽然整体复杂度有所下降,但O(n)的复杂度还是达不到现实的需求。
2.基于链表的数据结构和算法优化设计
基于链表的处理,只是在查找时效率较低,而插入操作却完全能满足要求,所以可以在链表的基础上继续加以改进,以解决顺序查找导致的低效问题。主要考虑从查找角度来优化数据结构,这个改进可按以下思路进行。
(1)减少查找插入位置过程中的比较次数
基于链表数据结构的处理时间主要消耗在插入位置的查找中,因此,可着眼减少查找过程中的数据两两比较的次数来优化数据结构。
(2)借鉴二分查找算法的思想
二分查找算法之所以效率较高,首先是因为数据是有序的,其次是利用
有序性进行跨区间、跳跃性的比较,从而避免低效的逐个依次比较。
实现的思路是首先将数据进行有序化处理,然后想二分查找一样确定比较
的关键节点,根据新元素与关键节点的比较结果来高效地取舍剩余的查找
区间。
1
3
4
10
13
15
20
原链表
1
4
10
15
关键节点
在原链表基础上增设关键节点
1
3
4
10
13
15
20
原链表
1
4
10
15
关键节点
6
通过关键节点只需比较3次
由此可见,关键节点起到一个索引表的作用,帮助算法快速定位到一个较
小的插入区间,然后只需将索引位置对应到原链表,即可找到最终的插入
位置。
插入位置
按照同样的方法再增设一批关键节点,为原来的一级索引建立二级索引,
则可以进一步将查找速度提升2倍。
1
3
4
10
13
15
20
原链表
1
4
10
15
一级索引
1
10
二级索引
在原来基础上建立二级索引
在二级索引的基础上,若要插入新元素6,则先从二级索引中经过2次比较
确定一个大致区间,然后通过对应关系到达一级索引,最终到达原链表中
可插入的位置,这样就可将在原一级索引中的顺序比较次数减少一半。如
果数据比较多,还可以在此基础上继续增设三、四级索引,进一步提高查
找的速度。总体来说,通过对链表进行改进的数据结构可以用O()的
时间复杂度实现查找,然后进行新元素的插入,并且保证新序列仍然有序。
因为数据序列在不断地变化,所以需要对关键节点进行动态的调整,即数据
增加时增设关键节点,而数据减少时删除关键节点。对各级索引表中的关键
节点进行增加和删除的实现方法如下:
①增设关键节点
1
3
4
10
13
15
20
24
1
1
4
10
15
24
10
第一次抛硬币,结果是“正”,因此把
节点24提升到上一层索引
将新增元素24所在节点提升为关键节点
1
3
4
10
13
15
20
24
1
1
4
10
15
10
新增元素24所在节点不提升为关键节点
若通过“抛硬币”发现不需要提升为关键节点,则新的链表组织结构如图
所示(新增元素只在原链表中出现)。
②删除关键节点
随着原链表中数据元素的不断删除,各级索引中的关键节点也需要随之
删除。删除时按照查找时的层次从上往下依次进行,每当找到对应的元素,
就删除当前层的关键节点,直到最底层的原链表。若原来链表的状态如下图
所示,现在要删除原链表中的元素10,则从顶层索引开始,依次往下删除
各层的元素10。
1
3
4
10
13
15
20
原链表
1
4
10
15
一级索引
1
10
二级索引
删除前
1
3
4
13
15
20
原链表
1
4
15
一级索引
删除元素10之后的链表状态
二级索引中删除元素10所在的节点后,因为只剩下一个关键节点,对于区间
划分和提高查找效率没有任何意义,所以将剩下一个节点也删除,得到的最
终状态如上图所示。
因为上述数据结构是在一个有序链表中通过索引表跳跃着进行查找,所以
称为“跳跃表”,跳跃表是William Pugh于1990年发明并提出的一种数
据结构。
从数组到链表,再到跳跃表,可以发现,一个切合实际的数据结构和算法
不是一蹴而就的,而是根据问题中数据及其关系的特点,通过迭代逐步优
化得到的。
“跳跃表”是立足链表,借鉴二分查找的思想而
形成的数据结构。能否立足有序数组,借鉴链表
的思想构造一种新的数据结构来解决上述问题?
有序数组在查找数据方面的效率较高,主要的低效源于插入新数据后,该
数据后续数据元素线性复杂度的数据元素连续后移所致,因此可以针对如
何降低后移的复杂度思考优化方案。比如将原来一个数组中的数据均匀地
分解存储到k个数组中,这样就将原来O(n)的移动复杂度降为O(),虽然
数量级没变,但至少是原来的k倍速度。
其他数据组织与处理方式
人们针对磁盘数据库存在的瓶颈,发明了内存数据库。大部分的内存数据库主要从以下几个方面来提升数据的处理性能。
1.减少对磁盘的访问
内存数据库就是将需要处理的数据保存在内存中并直接操作的数据库。
因为内存的数据读写速度比磁盘高出几个数量级,所以内存数据库首先
在数据的输入和输出上极大地提高了系统的性能。相比于传统的磁盘数
据库,内存数据库可以将数据处理速度提高至少10倍以上,理想状态下
甚至可达到1000倍。
2.对数据进行分级存储
内存数据库对所有需要处理的数据重新进行组织,并根据应用需要将数据
分级,再在处理器缓存中进行分级存储。由于处理器缓存速度高于内存,
因此进一步提升了数据的存取效率。
3.采用改进后的数据结构来组织、存储数据
内存数据库还能将全部数据在内存中进行重新组织、存储,进行新的体系
结构设计,用更快速的算法来处理数据,并运用支持快速算法的数据结构
来组织数据。例如,AT&T Bell实验室的Silicon数据库核心组织用AVL树
(一种平衡树)作为索引结构来提高查找速度;Redis数据库运用了Sorted-
set技术,而Sorted-set这种有序集合技术正是对跳跃表的改进和应用。
练习
内存数据库具有传统磁盘数据库无可比拟的优点,下列说法正确的是
( )
A.减少了对磁盘的访问
B.对数据进行分级存储
C.采用了改进后的数据结构
D.内存数据库不能用于实时查询
ABC
谢 谢