2022年信息技术学考复习课件(129张PPT)
文档属性
| 名称 | 2022年信息技术学考复习课件(129张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 12.1MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 教科版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2022-06-24 00:00:00 | ||
图片预览








文档简介
(共129张PPT)
技术学考复习
信息技术(1)
*由于课时有限,会减少理论知识部分的内容,侧重于编程的内容。
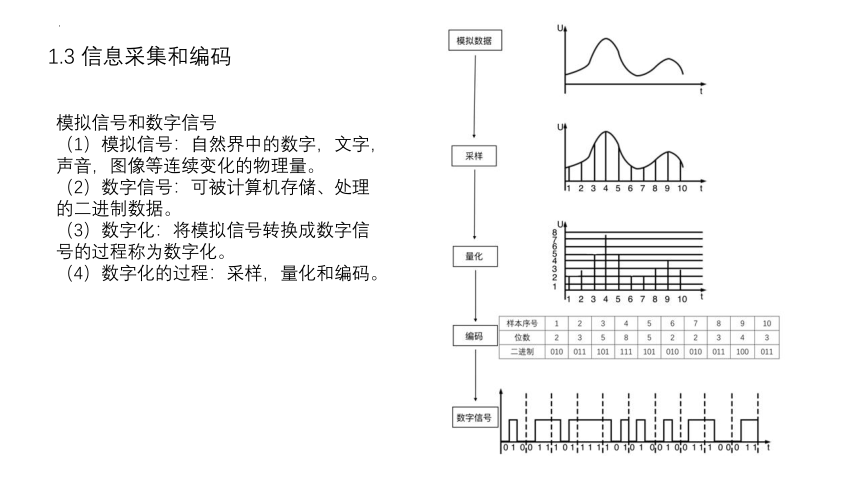
1.3 信息采集和编码
数据采集:
①传统采集方式:纸笔记录
②机器获取信息的方式:传感器
模拟信号和数字信号
(1)模拟信号:自然界中的数字,文字,声音,图像等连续变化的物理量。
(2)数字信号:可被计算机存储、处理的二件制数据。
(3)数字化:将模拟信号转换成数字信号的过程称为数字化。
(4)数字化的过程:采样,量化和编码。
1.3 信息采集和编码
模拟信号和数字信号
(1)模拟信号:自然界中的数字,文字,声音,图像等连续变化的物理量。
(2)数字信号:可被计算机存储、处理的二进制数据。
(3)数字化:将模拟信号转换成数字信号的过程称为数字化。
(4)数字化的过程:采样,量化和编码。
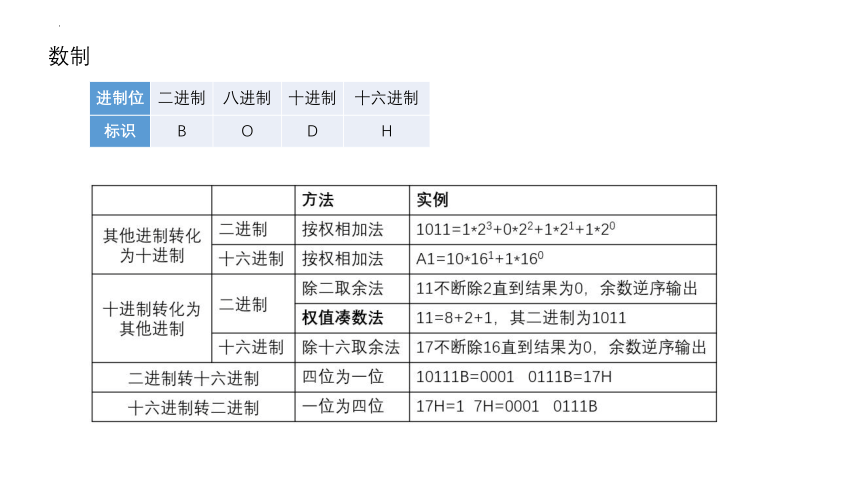
数制
进制位 二进制 八进制 十进制 十六进制
标识 B O D H
例:将十六进制数字 9FA8C 转换成十进制:
数制
例2:将二进制数字 42转换成十进制:
数制
二进制整数转换为十六进制整数时,每四位二进制数字转换为一位十六进制数字,运算的顺序是从低位向高位依次进行,高位不足四位用零补齐。下图演示了如何将二进制整数 10 1101 0101 1100 转换为十六进制:
数制
十六进制整数转换为二进制整数时,思路是相反的,每一位十六进制数字转换为四位二进制数字,运算的顺序也是从低位向高位依次进行。下图演示了如何将十六进制整数 A5D6 转换为二进制:
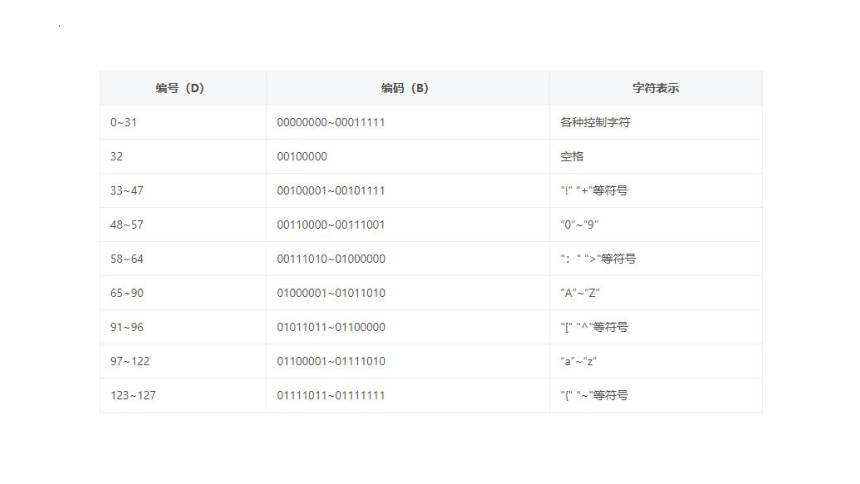
ASCII码
ASCII码全称美国信息交换标准代码,通常用来对拉丁字母进行编码。该编码使用1个字节中的低7位编码,由128个代码组成。1个ASCII码储存时占用1个字节的空间。储存ASCII码时要在最高位加0凑成八位。
小写字母的编码比对应的大写字母大32。如“A”的ASCII码为65,“a”的ASCII码为97(均为十进制)
ASCII码
怎么将字母“A”(十六进制)转换为10进制?
例1:编程将十六进制”A43D”转换为10进制
怎么用一行代码验证答案的正确性?
(一行代码十六进制转十进制)
int函数int()的语法:classint(x,base=10)参数x --字符串或数字。base --进制数,默认十进制。返回值返回整型数据。>>>int(3)3>>>int(3.6)3>>>int('12',16)#如果是带参数base的话,12要以字符串的形式进行输入,12为16进制18>>>int('0xa',16)10>>>int('10',8)8数据存储容量单位
(1) b:bit(比特),存放一位二进制数,是最小的储存容量单位。
(2) B:Byte(字节),8bit为1Byte,为一个基本单位
(3) 常用储存单位间的关系:
1 Byte(B)= 8 bit ; 1 KB = 1024B ; 1 MB = 1024 KB ; 1 GB = 1024 MB
汉字编码
我国最早颁布的汉字编码是GB2312标准。每个汉字用2个字节进行编码。
数字图像有矢量图像和位图图像。区别如下:
矢量图形文件一般比位图小,其文件大小与图形大小无关。
矢量图形放大不会影响清晰度,与分辨率无关。位图图象放大会影响清晰度。
颜色位深度:用来表示每个像素颜色的二进制数的长度。如256种颜色的图像,它的位深度为8位(28=256)。
存储容量:
储存容量=总像素×颜色位深度(位)(单位:bit)
总像素=宽像素×高像素(单位:个)
图像编码
文件的校验
文件的MD5校验是将整个文件当作个大文本信息,通过其不可逆的字符串变换算法,产生唯一的MD5信息摘要并提供给用户。用户下载完文件以后,通过专用程序计算下载文件的MD5校验码,比对前后的校验数据,判断下载文件是否完整。常见的数据校验方法有MD5、CRC、SHA-1。
数据与大数据
特征:4V——数量、速度、多样和价值
数据体量巨大:大数据收集和分析的数据量非常大
速度快:①指数据产生速度快 ②指数据处理的速度快
数据类型多:既有人工产生的,也有机器自动产生的。数据有多种类型结构,各种结构化、半结构化和非结构化数据共存是大数据的普遍现象。
价值密度低:庞大的数据中发挥作用的仅是一小部分。
Python语言基础
数据类型名 数据表现形式
整型 数学中的整数(正负皆可);十六进制数(用0x前缀),如0xff00等
浮点型 数学中的实数;用科学计数法表示的实数,如1.2e-5
字符串型 用单引号,双引号或三引号表示
布尔型 只有两种值,即True和False(开头大写)
Python语言基础
变量名
变量名可以包括字母,数字和下划线。
变量名不能以数字开头,而且字母区分大小写。
使用前不需要声明变量的数据类型。
Python语言基础
运算符 描述 实例 优先级
+ 加 - 两个对象相加 a + b 输出结果 30 3
- 减 - 得到负数或是一个数减去另一个数 a - b 输出结果 -10 3
* 乘 - 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 2
/ 除 - x除以y b / a 输出结果 2.0 2
% 取模 - 返回除法的余数 b % a 输出结果 0 2
// 取整除 - 返回商的整数部分(向下取整) >>> 9//2 4 2
** 幂 - 返回x的y次幂 a**b 为10的20次方, 输出结果 100000000000000000000 1
以下假设变量: a=10,b=20:
Python语言基础
字符串和列表(通用序列)
Python语言基础
列表
访问列表中的值
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5, 6, 7 ]
>>>list1[0]
physics
>>>list2[1:5]
[2, 3, 4, 5]
在访问单个元素的时候,访问不存在的元素,程序会报错,提示索引值越界。
修改元素:
修改列表元素的语法与访问列表元素的语法类似。要修改列表元素,可指定列表名和要修改的元素的索引,再指定该元素的新值。
motorcycles = ['honda', 'yamaha', 'suzuki']
print(motorcycles)
motorcycles[0] = 'ducati'
print(motorcycles)
Python语言基础
>>> list = ['phigros'] #空列表
>>> list.append('alpha') #使用 append() 添加元素
>>> list.append('OldSun')
>>> print(list)
['phigros','alpha', 'OldSun']
添加元素: 使用 append() 在列表末尾添加元素
使用del语句删除元素:
>>> list = ['me', 'world', 'hello']
>>> print(list)
>>> del list[1]
>>> print(list)
['me', 'world', 'hello']
['me', 'hello']
Python语言基础
Python语言基础
使用index()查询具有特定值的元素位置
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Zeppo']
>>> marxes.index('Chico')
1
使用count()记录特定值出现的次数
>>> marxes = ['Groucho', 'Chico', 'Harpo','Chico']
>>> marxes.count('Harpo')
1
>>> marxes.count('Bob')
0
>>> marxes.count('Chico')
2
字典
字典(dictionary)与列表类似,但其中元素的顺序无关紧要,因为它们不是通过像 0 或 1 的偏移量访问的。取而代之,每个元素拥有与之对应的互不相同的键(key),需要通过键来访问元素。字典是无序的,它没有固定的顺序。
用大括号({})将一系列以逗号隔开的键值对(key:value)包裹起来即可进行字典的创建。记住,字典的键必须保证互不相同,否则后加入的同键的值会覆盖前一个。
Python语言基础
字符串
在Python 中处理文本数据是使用str 对象,也称为字符串。字符串是由Unicode 码位构成的不可变序列。
字符串字面值有多种不同的写法:
单引号: ' 允许包含有" 双" 引号'
Double quotes: "allows embedded 'single' quotes"
三重引号: ''' 三重单引号’‘’ , """ 三重双引号"""
使用三重引号的字符串可以跨越多行——其中所有的空白字符都将包含在该字符串字面值中。
字符串的方法
str.capitalize()
返回原字符串的副本,其首个字符大写,其余为小写。
str.join(iterable)
返回一个由iterable 中的字符串拼接而成的字符串。
str.lower()
返回原字符串的副本,其所有区分大小写的字符4 均转换为小写。
str.replace(old, new)
返回字符串的副本,其中出现的所有子字符串old 都将被替换为new。
str.split(sep=None)
返回一个由字符串内单词组成的列表,使用sep 作为分隔字符串。
例如:
>>> '1,2,3'.split(',')
['1', '2', '3']
>>> '1,2,,3,'.split(',')
['1', '2', '', '3', '']
>>> '1 2 3'.split()
['1', '2', '3']
>>> ‘ 1 2 3 '.split()
['1', '2', '3']
如果sep 未指定或为None,则会应用另一种拆分算法:连续的空格会被视为单个分隔符,其结果将不包含开头或末尾的空字符串
str.strip()
返回原字符串的副本,移除其中的前导和末尾字符。
>>> ‘ spacious '.strip()
'spacious'
str.title()
返回原字符串的标题版本,其中每个单词第一个字母为大写,其余字母为小写。
例如:
>>> 'Hello world'.title()
'Hello World'
str.upper()
返回原字符串的副本,其中所有区分大小写的字符均转换为大写
printf 风格的字符串格式化
形式为 string % data
转义字符
在需要在字符中使用特殊字符时,python 用反斜杠\转义字符。常见转义符如下表:
\' 单引号
\" 双引号
\\ 反斜杠符号
\t 横向制表符
\n 新建行
函数 描述
print(x) 输出x的值
input([prompt]) 获取用户输入
int(object) 将字符串和数字转换成整型
float(object) 将字符串和数字转换成实型
abs(x) 返回X的绝对值
len(seq) 返回序列的长度
str(x) 将X转换成字符串
chr(x) 返回X对应的字符
ord(x) 返回x对应的ASCII值
round(x[,n]) 对x进行四舍五入(如果给定n,就将数x转换为小数点后有n位的数)
max(s.[,args...]) 返回序列的最大值(如果给定多个参数,则返回给定参数中的最大值)
min(s,[,args...]) 返回序列的最小值(如果给定多个参数,则返回给定参数中的最小值)
Python常见内置函数
Python常见内置函数
for语句
#遍历字典的键:方法1
for 变量 in 字典名:
<循环体>
#方法2
for 变量 in 字典名.keys():
<循环体>
#for遍历字典(键)
dic={"name":"OldSun","age":18,"weight":62}
for i in dic:
print(i,end="->")
#输出结果
name->age->weight->
#遍历字典的值:方法1 for 变量 in 字典名: <“字典名[变量(键)]”> #遍历字典的值:方法2
for 变量 in 字典名.values():
<循环体>
#for遍历字典值(1) dic={"name":"OldSun","age":18,"weight":62} for i in dic: print(dic[i],end="->") #for遍历字典值(2)
dic={"name":"OldSun","age":18,"weight":62}
for i in dic.values():
print(i,end="->")
结果:OldSun->18->62-> 结果:OldSun->18->62->
for语句
函数构造和定义
def compare(num1,num2):
# 返回2个参数中的较大数"
if num1>=num2:
return num1
else:
return num2
a=float(input("请输入第一个数:"))
b=float(input("请输入第二个数:"))
# 调用compare函数
print("大数为",compare(a,b))
>>>请输入第一个数:15.3
>>>请输入第二个数:21.6
大数为 21.6
range生成器
range生成器
列表生成器
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
读写文件
open (file, mode=‘r’)
读写文件open(file, mode=‘r’)打开 file 并返回对应的 file object。 如果该文件不能被打开,则引发 OSError。mode是一个可选字符串,用于指定打开文件的模式。默认值是'r',这意味着它以文本模式打开并读取。模式 'w+' 与 'w+b' 将打开文件并清空内容。 模式 'r+' 与 'r+b' 将打开文件并不清空内容。>>>f=('workfile',‘w+')在处理文件对象时,最好使用 with 关键字。 优点是当子句体结束后文件会正确关闭,即使在某个时刻引发了异常。读写文件如果你没有使用 with 关键字,那么你应该调用 f.close() 来关闭文件并立即释放它使用的所有系统资源。文件对象的方法假定你已创建名为 f 的文件对象要读取文件内容,请调用 f.read(size),它会读取一些数据并将其作为字符串(在文本模式下)或字节串对象(在二进制模式下)返回。 size 是一个可选的数值参数。如果已到达文件末尾,f.read()将返回一个空字符串('')。f.readline() 从文件中读取一行;换行符(\n)留在字符串的末尾,如果文件不以换行符结尾,则在文件的最后一行省略。这使得返回值明确无误;如果 f.readline() 返回一个空的字符串,则表示已经到达了文件末尾,而空行使用 '\n' 表示,该字符串只包含一个换行符。要从文件中读取行,你可以循环遍历文件对象。如果你想以列表的形式读取文件中的所有行,你也可以使用 list(f) 或 f.readlines()。with open()
readline() vs readlines() vs read ()
文本的处理有时候你可能需要从一个文本文件中读取独立的单词。例如,假设我们的输入文件包含两行文本:我们想把这些单词输出到终端,每行一个单词:因为没有从文件中读取一个单词的方法,你必须首先读取一行,然后将其切分成独立的单词。这可以使用split方法来完成:文本的处理当字符串行包含\n等我们不想要的字符时,如:为了删除换行符,对字符串应用rstrip方法:得到新字符串:默认地,rstrip方法创建一个新字符串,删除原字符串尾部的所有空白字符(空格、制表符、换行符)。为了删除字符串尾部的指定字符,你可以把包含那些字符的字符串参数传递给rstrip方法。例如,如果我们需要从字符串尾部删除一个圆点或一个问号,可以使用命令:文本的处理这里的split方法返回在每个空白字符处对原始字符串进行切分得到的子字符串的列表。例如,如果line包含字符串:它将被切分成5个子字符串,并且按在字符串中出现的相同顺序存储到一个列表中:文本的处理注意行尾的最后一个单词包含一个逗号。如果我们只是想输出文件中的单词而不包括标点符号,那么我们可以使用前一节中介绍的rstrip方法从子字符串中删除它们:默认地,split方法使用空白字符作为分隔符。你也可以使用不同的分隔符切分字符串。例如,如果单词之间使用冒号分隔而不是使用空白字符我们可以在使用split方法时指定冒号为分隔符函数函数是Python中的一等公民,可以把它们(返回值)赋给变量,可以作为参数被其他函数调用,也可以从其他函数中返回值。它可以帮助你在Python中实现其他语言难以实现的功能。定义一个函数run_something。它有一个参数func,这个参数是一个可以运行的函数的名字>>>def answer():... print(42)>>> def run_something(func):... func()将参数answer传到该函数,在这里像之前碰到的一样,把函数名当作数据使用:>>> run_something(answer)42注意,你传给函数的是answer ,而不是answer()。在Python中圆括号意味着调用函数。在没有圆括号的情况下,Python会把函数当作普通对象。函数我们来运行一个带参数的例子。定义函数add_args(),它会打印输出两个数值参数(arg1和arg2)的和:>>> def add_args(arg1, arg2):... print(arg1 + arg2)>>> type(add_args)<class 'function'>此刻定义一个函数run_something_with_args(),它带有三个参数:·func——可以运行的函数·arg1——func函数的第一个参数·arg2——func函数的第二个参数>>> def run_something_with_args(func, arg1, arg2):... func(arg1, arg2)当调用run_something_with_args()时,调用方传来的函数赋值给func参数,而arg1和arg2从参数列表中获得值。然后运行带参数的func(arg1, arg2)。>>> run_something_with_args(add_args, 5, 9)14退出Python解释器后,再次进入时,之前在Python解释器中定义的函数和变量就丢失了。因此,编写较长程序时,建议用文本编辑器代替解释器,执行文件中的输入内容,这就是编写脚本。随着程序越来越长,为了方便维护,最好把脚本拆分成多个文件。编写脚本还一个好处,不同程序调用同一个函数时,不用每次把函数复制到各个程序。为实现这些需求,Python把各种定义存入一个文件,在脚本或解释器的交互式实例中使用。这个文件就是模块;模块中的定义可以导入到其他模块或主模块(在顶层和计算器模式下,执行脚本中可访问的变量集)。模块模块是包含Python定义和语句的文件。其文件名是模块名加后缀名.py。在模块内部,通过全局变量__name__可以获取模块名(即字符串)。例如,用文本编辑器在当前目录下创建fibo.py文件,输入以下内容:模块deffib(n):# write Fibonacci series up to na, b=0,1whilea<n:print(a, end=' ')a, b=b, a+bprint()deffib2(n):# return Fibonacci series up to nresult=[]a, b=0,1whilea<n:result.append(a)a, b=b, a+breturnresult用文本编辑器在当前目录下创建fibo.py文件,输入以下内容:现在,进入Python解释器,用以下命令导入该模块:>>>importfibo这项操作不直接把fibo函数定义的名称导入到当前符号表,只导入模块名fibo。要使用模块名访问函数:>>>fibo.fib(1000)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987>>>fibo.fib2(100)[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]import语句有一个变体,可以直接把模块里的名称导入到另一个模块的符号表。例如:模块>>>fromfiboimportfib, fib2>>>fib(500)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377这段代码不会把模块名导入到局部符号表里(因此,本例没有定义fibo)。还有一种变体可以导入模块内定义的所有名称:>>>fromfiboimport*>>>fib(500)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377这种方式会导入所有不以下划线(_)开头的名称。大多数情况下,不要用这个功能,这种方式向解释器导入了一批未知的名称,可能会覆盖已经定义的名称。模块名后使用as时,直接把as后的名称与导入模块绑定。模块>>>importfiboasfib>>>fib.fib(500)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377与import fibo一样,这种方式也可以有效地导入模块,唯一的区别是,导入的名称是fib。from中也可以使用这种方式,效果类似:>>>fromfiboimportfibasfibonacci>>>fibonacci(500)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377ExcelExcel 2010工作界面OldSunExcel基本术语1.单元格.单元格是Excel的最小组成单位,由行和列交叉构成。横向称为行,由行号的数字1、2、3、4……分别加以命名;纵向称为列,由列标区的字母A、B、C……分别加以命 名。单元格的地址使用它所在的列标和行号表示,例如B5。2.区域.区域是一组单元格,可以是连续或不连续的。一般采用区域的左上角单元格和右下 角单元格的位置表示该区域,中间用冒号隔开。如下图所示的区域是A1:C5。OldSunExcel公式和函数公式是Excel最重要的功能之一,公式的组成一般有三部分:等号、运算项、运算符。运算项包括常量、单元格或区域引用标志、名称或参数等。公式的运算符有以下四种类型:算术运算符、比较运算符、文本运算符、引用运算符。1.算术运算算术运算符用来完成基本的数学运算,包括+(加)、-(减)、* (乘)、/(除)、% (百分比)、^(乘方)。例如:A1单元格内容为5,A2单元格内容为2,在A3单元格内输入“=A1/A2”,按Enter键后A3单元格的值为2.5。OldSunExcel公式和函数公式是Excel最重要的功能之一,公式的组成一般有三部分:等号、运算项、运算符。运算项包括常量、单元格或区域引用标志、名称或参数等。公式的运算符有以下四种类型:算术运算符、比较运算符、文本运算符、引用运算符。2.比较运算符比较运算符用来对两个数值进行比较,产生的结果为逻辑值TRUE(真)或FALSE(假)。比较运算符包括=(等于)、> (大于)、< (小于)、>=(大于等于)、<=(小于等于)、<>(不等于)。例如:A1单元格内容为5,A2单元格内容为3,在A3单元格内输入“=A1<>A2”,按Enter键后A3单元格的值为TRUE。3.文本运算符文本运算符&用来将一个或多个文本连接成为一个组合文本。例如:A1单元格内容为home, A2单元格内容为work,在A3单元格内输入"=A1&A2",按Enter键后A3单元格的值为homeworkOldSunExcelOldSunExcel函数函数的形式如下:=函数名(参数1,参数2……)。函数名后紧跟括号,括号内可以有一个或多个参数,参数间用逗号分隔。函数也可 以没有参数但函数名后的括号是必需的。函数输入后,可以在数据编辑区显示公式内容,在单元格里显示结果。OldSunExcelOldSunExcelOldSunExcelOldSunExcelOldSunExcel:单元格引用引用的作用在于标识工作表上的单元格或单元格区域,并指明公式中所使用的数据 位置。通过引用,可以在公式中使用工作表中不同部分的数据,或者在多公式中使用同 一个单元格的数值。单元格的引用主要有相对引用、绝对引用、混合引用以及三维引用。OldSunExcel:单元格引用OldSunExcel:单元格引用OldSunExcel:单元格引用OldSunPandas-Series
(一) 导入模块
import pandas as pd
(二) Series操作
Pandas-Series
自定索引匹配
s4=pd.Series([166,178,180],index=["s01","s02","s03"])
遍历对象
遍历索引
遍历值(.values可以省略)
s2:
Pandas-DataFrame
创建DataFrame对象
Pandas-DataFrame
操作 方法 说明
导入数据 pd.read_csv( "test.csv”) 读取test. csv的数据,并创建DataFrame对象
pd.read_excel( "test.xlsx”) 读取test. xlsx的数据,并创建DataFrame对象
导出数据 df.to_csv( “test.csv" ) 将数据保存为test. csv文件
df.to_excel( “test.xlsx” ) 将数据保存为test.xlsx文件
(二) 文件操作
Pandas-DataFrame
查看(取出)DataFrame对象
行索引
for i in df1.index:
print(i,end=" ")
列索引
for i in df1.columns:
print(i,end=" ")
数据
for i in df1.values:
print(i,end=" ")
(.columns可以省略)
Pandas-DataFrame
查看(取出)DataFrame对象
查看(取出)数据列
字典方式检索一列数据,返回一个Series
df["姓名"]
属性检索一列数据,返回一个Series
df.姓名
修改一列数据
df.借阅次数=[30,52,68]
Pandas-DataFrame
查看(取出)DataFrame对象
查看数据行
通过head()、tail()返回DataFrame的前n行、后n行数据,没有参数则返回5行数据
df.head() #默认返回前5行
df.tail(3) #返回后3行,不写默认五行
Pandas-DataFrame
查看(取出)DataFrame对象
查看数据行
通过索引(切片)查看指定行
df[2:5]
返回df对象中索引为2、3、4行的数据
df[2:3]
返回df对象中索引为2的行的数据
Pandas-DataFrame
查看(取出)DataFrame对象
查看数据行
布尔索引
df[df["价格"]>4]
&:查找同时满足条件的项(与)
df[(df["价格"]>4)&(df["采价点"]=="超市2")]
Pandas-DataFrame
查看(取出)DataFrame对象
查看数据行
&:查找同时满足条件的项(与)
df[(df["价格"]>4)&(df["采价点"]=="超市2")]
|:查找满足其中一个条件的项(或)
df[(df["价格"]<4)|(df["地区"]=="北京市")]
Pandas-DataFrame
DataFrame对象中行、列的编辑
追加1行数据
Pandas-DataFrame
DataFrame对象中行、列的编辑
df_delc=df.drop("规格",axis=1)
删除“规格”列数据
Pandas-DataFrame
DataFrame对象中行、列的编辑
df_delc=df.drop("规格",axis=1)
Pandas-DataFrame
DataFrame对象中行、列的编辑
df_delr=df.drop(0,axis=0)
删除索引为0行数据,axis=0可以省略
默认append()和drop()均不改变原有df对象中的数据,而是通过返回另一个对象来存放改变后的数据
Pandas-DataFrame
DataFrame对象中数据的统计与计算
可以使用count()、sum()、mean()、max()、min()、describe()、groupby()等函数对DataFrame对象中的数据进行统计与计算
Pandas-DataFrame
DataFrame对象分组
g=df.groupby("地区",as_index=False)
g.mean() #分组统计平均值
以地区分组:
分组统计价格平均值
g.价格.mean()
Pandas-DataFrame
DataFrame对象排序
按索引排序可以使用sort_index()函数
按值排序可以使用sort_values()函数。
df_sort=df.sort_index(ascending=False)
按索引降序
按“价格”列降序
df_sort=df.sort_values("价格",ascending=False)
异或 in Python
简单异或在python中用^表示
二进制 十进制
0110100 42
xor 0011110 30
结果 0101010 52
1.在BXY中输入如下代码:
from microbit import *
if button_A.is_pressed():
display.show(str(random.randint(2,5)))
elif button_B. is_pressed ():
display.show(str(random.randrange(2,5)))
下载并运行该代码,下列关于代码执行效果的 描述,正确的是 ( )
A.按下按钮A, micro:bit的LED点阵可能显示5
B.按下按钮A, micro:bit的LED点阵不可能显示2
C.按下按钮B, micro:bit的LED点阵可能显示5
D.按下按钮B, micro:bit的LED点阵不可能显示2
3.小王在BXY中输入下图中的代码,烧录成功后,下列说法正确的是( )
A.按下 micro:bit 开发板的按钮a , LED点阵滚动显示“Hello World!"
B.按下 micro:bit 开发板的按钮b , LED点阵滚动显示“Hello World!"
C.按下 micro:bit 开发板按钮b,程序结束
D.没有按任何按钮时,LED点阵滚动显示 "Hello World!"
网络协议
TCP/IP协议(传输控制协议/网际协议):网络中最基本的通信协议,TCP/IP协议不是单一协议,而是一个协议簇。使用TCP/IP协议,需要详细设置IP地址、子网掩码、默认网关、DNS服务器等操作。
网络协议
TCP/IP协议(传输控制协议/网际协议):网络中最基本的通信协议,TCP/IP协议不是单一协议,而是一个协议簇。使用TCP/IP协议,需要详细设置IP地址、子网掩码、默认网关、DNS服务器等操作。
FTP协议(文件传输协议):用于传输网络电子文件的协议。
IP地址
IP地址是指互联网协议地址(网际协议地址),是IP协议提供的一种统一的地址格式,它为互联网上的每一台主机分配一个逻辑地址,助于进行通信。
IP地址的格式
IPv4地址是一个32位的二进制数,通常被分割为4个8位二进制数(也就是4个字节)。IPv4地址通常用“点分十进制”表示成(a.b.c.d) 的形式,其中,a, b, c, d都是0 255之间的十进制整数。
例如,点分十进制IP地址“100.4.5.6",实际上是32位二进制数
“01100100.00000100.00000101.00000110"
内网的计算机可向Internet上的其他计算机发送连接请求,但Internet上其他的计算机无法向内网的计算机发送连接请求。若想让外界的计算机访问本地主机,我们可以使用内网穿透或申请公网IP两种方式。
内网IP地址
DNS服务器
DNS服务器主要用于域名解析,即将主机名解析成IP地址。互联网中的 DNS服务器是一个分层结构,由很多DNS服务器组成,里面的数据库事先存放着各种域名或主机名对应的IP地址。用户计算机发出域名解析的请求,DNS服务器就会返回对应的IP地址。
DHCP
DHCP是动态主机配置协议。DHCP服务器控制一段lP 地址范围,用于集中管理和分配IP 地址,客户机登录服务器时就可以自动获得服务器分配的lP地址和子网掩码。DHCP的主要作用是集中管理、分配IP地址,使网络环境中的主机动态地获得IP地址、默认网关地址、DNS服务器地址等信息,从而提升IP地址的利用率。
1.小王编写了一个简单的Flask程序,其中路由编写和视图函数如下,运行程序后,在浏览器中输入 http://127.0.0.1:5000/hello/People, 网页显示的内容为( )
from flask import Flask
app = Flask (_name_)
@ app.route ('/hello/’)
def hello():
return render_template ( 'hello.html', name = name)
if __name_ = '__main__' :
app.run ( host = '0.0.0.0', debug = True)
Hello Sample
{% if name %}
Hello `name`!
{% else %}
Hello World!
{ % endif %}
A.Hello World!
B.Hello Sample
C.Hello People!
D.Hello People
15.小王用Flask Web框架编写程序,访问系统的地址为http ://192.168.4.200:86 部分代码如下:
from flask import Flask, render_template
#导入Flask库
app = Flask (__name__)
① ____________
def index():
#获取数据库中传感器采集的数据,并存储在 变量temp中,代码略
return renden_template ('index, html', txt = temp)
if ②___________________:
app.run(host =③____________________)
为了完整功能,请在代码划线处填入合适的语句。
小明搭建了“运动会项目报名管理系统”,在Python环境下使用SQLite数据库文件“test.db”,其中数据表为“data”,该数据表字段结构如下表:
下列程序代码用于建立数据库文件(该文件位于当前文件夹下)和数据表,请在①②处 填写合适的代码。
import sqlite3
conn =①___________#建立数据库
cur = conn.cursor()
sql_cdb =‘②_______________________'
cur.execute (sql_cdb) # 建立数据表
conn.commit ()
cur.close ()
conn.close ()
小李用Flask框架设计了基于Web环境下的 “查阅图书信息系统”,可以通过浏览器查找图书信息,访问该系统的Web地址为“http://192.168.0.101”,部分代码如下,请在①② 处填写合适的代码。
app = Flask (__name__)
①____________
def index ():
#查阅图书信息代码略
if __name__== __main__ :
app.run (② ____________)
技术学考复习
信息技术(1)
*由于课时有限,会减少理论知识部分的内容,侧重于编程的内容。
1.3 信息采集和编码
数据采集:
①传统采集方式:纸笔记录
②机器获取信息的方式:传感器
模拟信号和数字信号
(1)模拟信号:自然界中的数字,文字,声音,图像等连续变化的物理量。
(2)数字信号:可被计算机存储、处理的二件制数据。
(3)数字化:将模拟信号转换成数字信号的过程称为数字化。
(4)数字化的过程:采样,量化和编码。
1.3 信息采集和编码
模拟信号和数字信号
(1)模拟信号:自然界中的数字,文字,声音,图像等连续变化的物理量。
(2)数字信号:可被计算机存储、处理的二进制数据。
(3)数字化:将模拟信号转换成数字信号的过程称为数字化。
(4)数字化的过程:采样,量化和编码。
数制
进制位 二进制 八进制 十进制 十六进制
标识 B O D H
例:将十六进制数字 9FA8C 转换成十进制:
数制
例2:将二进制数字 42转换成十进制:
数制
二进制整数转换为十六进制整数时,每四位二进制数字转换为一位十六进制数字,运算的顺序是从低位向高位依次进行,高位不足四位用零补齐。下图演示了如何将二进制整数 10 1101 0101 1100 转换为十六进制:
数制
十六进制整数转换为二进制整数时,思路是相反的,每一位十六进制数字转换为四位二进制数字,运算的顺序也是从低位向高位依次进行。下图演示了如何将十六进制整数 A5D6 转换为二进制:
ASCII码
ASCII码全称美国信息交换标准代码,通常用来对拉丁字母进行编码。该编码使用1个字节中的低7位编码,由128个代码组成。1个ASCII码储存时占用1个字节的空间。储存ASCII码时要在最高位加0凑成八位。
小写字母的编码比对应的大写字母大32。如“A”的ASCII码为65,“a”的ASCII码为97(均为十进制)
ASCII码
怎么将字母“A”(十六进制)转换为10进制?
例1:编程将十六进制”A43D”转换为10进制
怎么用一行代码验证答案的正确性?
(一行代码十六进制转十进制)
int函数int()的语法:classint(x,base=10)参数x --字符串或数字。base --进制数,默认十进制。返回值返回整型数据。>>>int(3)3>>>int(3.6)3>>>int('12',16)#如果是带参数base的话,12要以字符串的形式进行输入,12为16进制18>>>int('0xa',16)10>>>int('10',8)8数据存储容量单位
(1) b:bit(比特),存放一位二进制数,是最小的储存容量单位。
(2) B:Byte(字节),8bit为1Byte,为一个基本单位
(3) 常用储存单位间的关系:
1 Byte(B)= 8 bit ; 1 KB = 1024B ; 1 MB = 1024 KB ; 1 GB = 1024 MB
汉字编码
我国最早颁布的汉字编码是GB2312标准。每个汉字用2个字节进行编码。
数字图像有矢量图像和位图图像。区别如下:
矢量图形文件一般比位图小,其文件大小与图形大小无关。
矢量图形放大不会影响清晰度,与分辨率无关。位图图象放大会影响清晰度。
颜色位深度:用来表示每个像素颜色的二进制数的长度。如256种颜色的图像,它的位深度为8位(28=256)。
存储容量:
储存容量=总像素×颜色位深度(位)(单位:bit)
总像素=宽像素×高像素(单位:个)
图像编码
文件的校验
文件的MD5校验是将整个文件当作个大文本信息,通过其不可逆的字符串变换算法,产生唯一的MD5信息摘要并提供给用户。用户下载完文件以后,通过专用程序计算下载文件的MD5校验码,比对前后的校验数据,判断下载文件是否完整。常见的数据校验方法有MD5、CRC、SHA-1。
数据与大数据
特征:4V——数量、速度、多样和价值
数据体量巨大:大数据收集和分析的数据量非常大
速度快:①指数据产生速度快 ②指数据处理的速度快
数据类型多:既有人工产生的,也有机器自动产生的。数据有多种类型结构,各种结构化、半结构化和非结构化数据共存是大数据的普遍现象。
价值密度低:庞大的数据中发挥作用的仅是一小部分。
Python语言基础
数据类型名 数据表现形式
整型 数学中的整数(正负皆可);十六进制数(用0x前缀),如0xff00等
浮点型 数学中的实数;用科学计数法表示的实数,如1.2e-5
字符串型 用单引号,双引号或三引号表示
布尔型 只有两种值,即True和False(开头大写)
Python语言基础
变量名
变量名可以包括字母,数字和下划线。
变量名不能以数字开头,而且字母区分大小写。
使用前不需要声明变量的数据类型。
Python语言基础
运算符 描述 实例 优先级
+ 加 - 两个对象相加 a + b 输出结果 30 3
- 减 - 得到负数或是一个数减去另一个数 a - b 输出结果 -10 3
* 乘 - 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 2
/ 除 - x除以y b / a 输出结果 2.0 2
% 取模 - 返回除法的余数 b % a 输出结果 0 2
// 取整除 - 返回商的整数部分(向下取整) >>> 9//2 4 2
** 幂 - 返回x的y次幂 a**b 为10的20次方, 输出结果 100000000000000000000 1
以下假设变量: a=10,b=20:
Python语言基础
字符串和列表(通用序列)
Python语言基础
列表
访问列表中的值
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5, 6, 7 ]
>>>list1[0]
physics
>>>list2[1:5]
[2, 3, 4, 5]
在访问单个元素的时候,访问不存在的元素,程序会报错,提示索引值越界。
修改元素:
修改列表元素的语法与访问列表元素的语法类似。要修改列表元素,可指定列表名和要修改的元素的索引,再指定该元素的新值。
motorcycles = ['honda', 'yamaha', 'suzuki']
print(motorcycles)
motorcycles[0] = 'ducati'
print(motorcycles)
Python语言基础
>>> list = ['phigros'] #空列表
>>> list.append('alpha') #使用 append() 添加元素
>>> list.append('OldSun')
>>> print(list)
['phigros','alpha', 'OldSun']
添加元素: 使用 append() 在列表末尾添加元素
使用del语句删除元素:
>>> list = ['me', 'world', 'hello']
>>> print(list)
>>> del list[1]
>>> print(list)
['me', 'world', 'hello']
['me', 'hello']
Python语言基础
Python语言基础
使用index()查询具有特定值的元素位置
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Zeppo']
>>> marxes.index('Chico')
1
使用count()记录特定值出现的次数
>>> marxes = ['Groucho', 'Chico', 'Harpo','Chico']
>>> marxes.count('Harpo')
1
>>> marxes.count('Bob')
0
>>> marxes.count('Chico')
2
字典
字典(dictionary)与列表类似,但其中元素的顺序无关紧要,因为它们不是通过像 0 或 1 的偏移量访问的。取而代之,每个元素拥有与之对应的互不相同的键(key),需要通过键来访问元素。字典是无序的,它没有固定的顺序。
用大括号({})将一系列以逗号隔开的键值对(key:value)包裹起来即可进行字典的创建。记住,字典的键必须保证互不相同,否则后加入的同键的值会覆盖前一个。
Python语言基础
字符串
在Python 中处理文本数据是使用str 对象,也称为字符串。字符串是由Unicode 码位构成的不可变序列。
字符串字面值有多种不同的写法:
单引号: ' 允许包含有" 双" 引号'
Double quotes: "allows embedded 'single' quotes"
三重引号: ''' 三重单引号’‘’ , """ 三重双引号"""
使用三重引号的字符串可以跨越多行——其中所有的空白字符都将包含在该字符串字面值中。
字符串的方法
str.capitalize()
返回原字符串的副本,其首个字符大写,其余为小写。
str.join(iterable)
返回一个由iterable 中的字符串拼接而成的字符串。
str.lower()
返回原字符串的副本,其所有区分大小写的字符4 均转换为小写。
str.replace(old, new)
返回字符串的副本,其中出现的所有子字符串old 都将被替换为new。
str.split(sep=None)
返回一个由字符串内单词组成的列表,使用sep 作为分隔字符串。
例如:
>>> '1,2,3'.split(',')
['1', '2', '3']
>>> '1,2,,3,'.split(',')
['1', '2', '', '3', '']
>>> '1 2 3'.split()
['1', '2', '3']
>>> ‘ 1 2 3 '.split()
['1', '2', '3']
如果sep 未指定或为None,则会应用另一种拆分算法:连续的空格会被视为单个分隔符,其结果将不包含开头或末尾的空字符串
str.strip()
返回原字符串的副本,移除其中的前导和末尾字符。
>>> ‘ spacious '.strip()
'spacious'
str.title()
返回原字符串的标题版本,其中每个单词第一个字母为大写,其余字母为小写。
例如:
>>> 'Hello world'.title()
'Hello World'
str.upper()
返回原字符串的副本,其中所有区分大小写的字符均转换为大写
printf 风格的字符串格式化
形式为 string % data
转义字符
在需要在字符中使用特殊字符时,python 用反斜杠\转义字符。常见转义符如下表:
\' 单引号
\" 双引号
\\ 反斜杠符号
\t 横向制表符
\n 新建行
函数 描述
print(x) 输出x的值
input([prompt]) 获取用户输入
int(object) 将字符串和数字转换成整型
float(object) 将字符串和数字转换成实型
abs(x) 返回X的绝对值
len(seq) 返回序列的长度
str(x) 将X转换成字符串
chr(x) 返回X对应的字符
ord(x) 返回x对应的ASCII值
round(x[,n]) 对x进行四舍五入(如果给定n,就将数x转换为小数点后有n位的数)
max(s.[,args...]) 返回序列的最大值(如果给定多个参数,则返回给定参数中的最大值)
min(s,[,args...]) 返回序列的最小值(如果给定多个参数,则返回给定参数中的最小值)
Python常见内置函数
Python常见内置函数
for语句
#遍历字典的键:方法1
for 变量 in 字典名:
<循环体>
#方法2
for 变量 in 字典名.keys():
<循环体>
#for遍历字典(键)
dic={"name":"OldSun","age":18,"weight":62}
for i in dic:
print(i,end="->")
#输出结果
name->age->weight->
#遍历字典的值:方法1 for 变量 in 字典名: <“字典名[变量(键)]”> #遍历字典的值:方法2
for 变量 in 字典名.values():
<循环体>
#for遍历字典值(1) dic={"name":"OldSun","age":18,"weight":62} for i in dic: print(dic[i],end="->") #for遍历字典值(2)
dic={"name":"OldSun","age":18,"weight":62}
for i in dic.values():
print(i,end="->")
结果:OldSun->18->62-> 结果:OldSun->18->62->
for语句
函数构造和定义
def compare(num1,num2):
# 返回2个参数中的较大数"
if num1>=num2:
return num1
else:
return num2
a=float(input("请输入第一个数:"))
b=float(input("请输入第二个数:"))
# 调用compare函数
print("大数为",compare(a,b))
>>>请输入第一个数:15.3
>>>请输入第二个数:21.6
大数为 21.6
range生成器
range生成器
列表生成器
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
print输出函数
(1)输出提示内容,放在引号里面,原样输出;
(2)输出变量的值,不需要加引号;
(3)各项信息之间,逗号隔开;
(4)print默认换行,可使用end=""实现不换行
(5)输出后不带字符串的标志性引号
读写文件
open (file, mode=‘r’)
读写文件open(file, mode=‘r’)打开 file 并返回对应的 file object。 如果该文件不能被打开,则引发 OSError。mode是一个可选字符串,用于指定打开文件的模式。默认值是'r',这意味着它以文本模式打开并读取。模式 'w+' 与 'w+b' 将打开文件并清空内容。 模式 'r+' 与 'r+b' 将打开文件并不清空内容。>>>f=('workfile',‘w+')在处理文件对象时,最好使用 with 关键字。 优点是当子句体结束后文件会正确关闭,即使在某个时刻引发了异常。读写文件如果你没有使用 with 关键字,那么你应该调用 f.close() 来关闭文件并立即释放它使用的所有系统资源。文件对象的方法假定你已创建名为 f 的文件对象要读取文件内容,请调用 f.read(size),它会读取一些数据并将其作为字符串(在文本模式下)或字节串对象(在二进制模式下)返回。 size 是一个可选的数值参数。如果已到达文件末尾,f.read()将返回一个空字符串('')。f.readline() 从文件中读取一行;换行符(\n)留在字符串的末尾,如果文件不以换行符结尾,则在文件的最后一行省略。这使得返回值明确无误;如果 f.readline() 返回一个空的字符串,则表示已经到达了文件末尾,而空行使用 '\n' 表示,该字符串只包含一个换行符。要从文件中读取行,你可以循环遍历文件对象。如果你想以列表的形式读取文件中的所有行,你也可以使用 list(f) 或 f.readlines()。with open()
readline() vs readlines() vs read ()
文本的处理有时候你可能需要从一个文本文件中读取独立的单词。例如,假设我们的输入文件包含两行文本:我们想把这些单词输出到终端,每行一个单词:因为没有从文件中读取一个单词的方法,你必须首先读取一行,然后将其切分成独立的单词。这可以使用split方法来完成:文本的处理当字符串行包含\n等我们不想要的字符时,如:为了删除换行符,对字符串应用rstrip方法:得到新字符串:默认地,rstrip方法创建一个新字符串,删除原字符串尾部的所有空白字符(空格、制表符、换行符)。为了删除字符串尾部的指定字符,你可以把包含那些字符的字符串参数传递给rstrip方法。例如,如果我们需要从字符串尾部删除一个圆点或一个问号,可以使用命令:文本的处理这里的split方法返回在每个空白字符处对原始字符串进行切分得到的子字符串的列表。例如,如果line包含字符串:它将被切分成5个子字符串,并且按在字符串中出现的相同顺序存储到一个列表中:文本的处理注意行尾的最后一个单词包含一个逗号。如果我们只是想输出文件中的单词而不包括标点符号,那么我们可以使用前一节中介绍的rstrip方法从子字符串中删除它们:默认地,split方法使用空白字符作为分隔符。你也可以使用不同的分隔符切分字符串。例如,如果单词之间使用冒号分隔而不是使用空白字符我们可以在使用split方法时指定冒号为分隔符函数函数是Python中的一等公民,可以把它们(返回值)赋给变量,可以作为参数被其他函数调用,也可以从其他函数中返回值。它可以帮助你在Python中实现其他语言难以实现的功能。定义一个函数run_something。它有一个参数func,这个参数是一个可以运行的函数的名字>>>def answer():... print(42)>>> def run_something(func):... func()将参数answer传到该函数,在这里像之前碰到的一样,把函数名当作数据使用:>>> run_something(answer)42注意,你传给函数的是answer ,而不是answer()。在Python中圆括号意味着调用函数。在没有圆括号的情况下,Python会把函数当作普通对象。函数我们来运行一个带参数的例子。定义函数add_args(),它会打印输出两个数值参数(arg1和arg2)的和:>>> def add_args(arg1, arg2):... print(arg1 + arg2)>>> type(add_args)<class 'function'>此刻定义一个函数run_something_with_args(),它带有三个参数:·func——可以运行的函数·arg1——func函数的第一个参数·arg2——func函数的第二个参数>>> def run_something_with_args(func, arg1, arg2):... func(arg1, arg2)当调用run_something_with_args()时,调用方传来的函数赋值给func参数,而arg1和arg2从参数列表中获得值。然后运行带参数的func(arg1, arg2)。>>> run_something_with_args(add_args, 5, 9)14退出Python解释器后,再次进入时,之前在Python解释器中定义的函数和变量就丢失了。因此,编写较长程序时,建议用文本编辑器代替解释器,执行文件中的输入内容,这就是编写脚本。随着程序越来越长,为了方便维护,最好把脚本拆分成多个文件。编写脚本还一个好处,不同程序调用同一个函数时,不用每次把函数复制到各个程序。为实现这些需求,Python把各种定义存入一个文件,在脚本或解释器的交互式实例中使用。这个文件就是模块;模块中的定义可以导入到其他模块或主模块(在顶层和计算器模式下,执行脚本中可访问的变量集)。模块模块是包含Python定义和语句的文件。其文件名是模块名加后缀名.py。在模块内部,通过全局变量__name__可以获取模块名(即字符串)。例如,用文本编辑器在当前目录下创建fibo.py文件,输入以下内容:模块deffib(n):# write Fibonacci series up to na, b=0,1whilea<n:print(a, end=' ')a, b=b, a+bprint()deffib2(n):# return Fibonacci series up to nresult=[]a, b=0,1whilea<n:result.append(a)a, b=b, a+breturnresult用文本编辑器在当前目录下创建fibo.py文件,输入以下内容:现在,进入Python解释器,用以下命令导入该模块:>>>importfibo这项操作不直接把fibo函数定义的名称导入到当前符号表,只导入模块名fibo。要使用模块名访问函数:>>>fibo.fib(1000)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987>>>fibo.fib2(100)[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]import语句有一个变体,可以直接把模块里的名称导入到另一个模块的符号表。例如:模块>>>fromfiboimportfib, fib2>>>fib(500)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377这段代码不会把模块名导入到局部符号表里(因此,本例没有定义fibo)。还有一种变体可以导入模块内定义的所有名称:>>>fromfiboimport*>>>fib(500)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377这种方式会导入所有不以下划线(_)开头的名称。大多数情况下,不要用这个功能,这种方式向解释器导入了一批未知的名称,可能会覆盖已经定义的名称。模块名后使用as时,直接把as后的名称与导入模块绑定。模块>>>importfiboasfib>>>fib.fib(500)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377与import fibo一样,这种方式也可以有效地导入模块,唯一的区别是,导入的名称是fib。from中也可以使用这种方式,效果类似:>>>fromfiboimportfibasfibonacci>>>fibonacci(500)0 1 1 2 3 5 8 13 21 34 55 89 144 233 377ExcelExcel 2010工作界面OldSunExcel基本术语1.单元格.单元格是Excel的最小组成单位,由行和列交叉构成。横向称为行,由行号的数字1、2、3、4……分别加以命名;纵向称为列,由列标区的字母A、B、C……分别加以命 名。单元格的地址使用它所在的列标和行号表示,例如B5。2.区域.区域是一组单元格,可以是连续或不连续的。一般采用区域的左上角单元格和右下 角单元格的位置表示该区域,中间用冒号隔开。如下图所示的区域是A1:C5。OldSunExcel公式和函数公式是Excel最重要的功能之一,公式的组成一般有三部分:等号、运算项、运算符。运算项包括常量、单元格或区域引用标志、名称或参数等。公式的运算符有以下四种类型:算术运算符、比较运算符、文本运算符、引用运算符。1.算术运算算术运算符用来完成基本的数学运算,包括+(加)、-(减)、* (乘)、/(除)、% (百分比)、^(乘方)。例如:A1单元格内容为5,A2单元格内容为2,在A3单元格内输入“=A1/A2”,按Enter键后A3单元格的值为2.5。OldSunExcel公式和函数公式是Excel最重要的功能之一,公式的组成一般有三部分:等号、运算项、运算符。运算项包括常量、单元格或区域引用标志、名称或参数等。公式的运算符有以下四种类型:算术运算符、比较运算符、文本运算符、引用运算符。2.比较运算符比较运算符用来对两个数值进行比较,产生的结果为逻辑值TRUE(真)或FALSE(假)。比较运算符包括=(等于)、> (大于)、< (小于)、>=(大于等于)、<=(小于等于)、<>(不等于)。例如:A1单元格内容为5,A2单元格内容为3,在A3单元格内输入“=A1<>A2”,按Enter键后A3单元格的值为TRUE。3.文本运算符文本运算符&用来将一个或多个文本连接成为一个组合文本。例如:A1单元格内容为home, A2单元格内容为work,在A3单元格内输入"=A1&A2",按Enter键后A3单元格的值为homeworkOldSunExcelOldSunExcel函数函数的形式如下:=函数名(参数1,参数2……)。函数名后紧跟括号,括号内可以有一个或多个参数,参数间用逗号分隔。函数也可 以没有参数但函数名后的括号是必需的。函数输入后,可以在数据编辑区显示公式内容,在单元格里显示结果。OldSunExcelOldSunExcelOldSunExcelOldSunExcelOldSunExcel:单元格引用引用的作用在于标识工作表上的单元格或单元格区域,并指明公式中所使用的数据 位置。通过引用,可以在公式中使用工作表中不同部分的数据,或者在多公式中使用同 一个单元格的数值。单元格的引用主要有相对引用、绝对引用、混合引用以及三维引用。OldSunExcel:单元格引用OldSunExcel:单元格引用OldSunExcel:单元格引用OldSunPandas-Series
(一) 导入模块
import pandas as pd
(二) Series操作
Pandas-Series
自定索引匹配
s4=pd.Series([166,178,180],index=["s01","s02","s03"])
遍历对象
遍历索引
遍历值(.values可以省略)
s2:
Pandas-DataFrame
创建DataFrame对象
Pandas-DataFrame
操作 方法 说明
导入数据 pd.read_csv( "test.csv”) 读取test. csv的数据,并创建DataFrame对象
pd.read_excel( "test.xlsx”) 读取test. xlsx的数据,并创建DataFrame对象
导出数据 df.to_csv( “test.csv" ) 将数据保存为test. csv文件
df.to_excel( “test.xlsx” ) 将数据保存为test.xlsx文件
(二) 文件操作
Pandas-DataFrame
查看(取出)DataFrame对象
行索引
for i in df1.index:
print(i,end=" ")
列索引
for i in df1.columns:
print(i,end=" ")
数据
for i in df1.values:
print(i,end=" ")
(.columns可以省略)
Pandas-DataFrame
查看(取出)DataFrame对象
查看(取出)数据列
字典方式检索一列数据,返回一个Series
df["姓名"]
属性检索一列数据,返回一个Series
df.姓名
修改一列数据
df.借阅次数=[30,52,68]
Pandas-DataFrame
查看(取出)DataFrame对象
查看数据行
通过head()、tail()返回DataFrame的前n行、后n行数据,没有参数则返回5行数据
df.head() #默认返回前5行
df.tail(3) #返回后3行,不写默认五行
Pandas-DataFrame
查看(取出)DataFrame对象
查看数据行
通过索引(切片)查看指定行
df[2:5]
返回df对象中索引为2、3、4行的数据
df[2:3]
返回df对象中索引为2的行的数据
Pandas-DataFrame
查看(取出)DataFrame对象
查看数据行
布尔索引
df[df["价格"]>4]
&:查找同时满足条件的项(与)
df[(df["价格"]>4)&(df["采价点"]=="超市2")]
Pandas-DataFrame
查看(取出)DataFrame对象
查看数据行
&:查找同时满足条件的项(与)
df[(df["价格"]>4)&(df["采价点"]=="超市2")]
|:查找满足其中一个条件的项(或)
df[(df["价格"]<4)|(df["地区"]=="北京市")]
Pandas-DataFrame
DataFrame对象中行、列的编辑
追加1行数据
Pandas-DataFrame
DataFrame对象中行、列的编辑
df_delc=df.drop("规格",axis=1)
删除“规格”列数据
Pandas-DataFrame
DataFrame对象中行、列的编辑
df_delc=df.drop("规格",axis=1)
Pandas-DataFrame
DataFrame对象中行、列的编辑
df_delr=df.drop(0,axis=0)
删除索引为0行数据,axis=0可以省略
默认append()和drop()均不改变原有df对象中的数据,而是通过返回另一个对象来存放改变后的数据
Pandas-DataFrame
DataFrame对象中数据的统计与计算
可以使用count()、sum()、mean()、max()、min()、describe()、groupby()等函数对DataFrame对象中的数据进行统计与计算
Pandas-DataFrame
DataFrame对象分组
g=df.groupby("地区",as_index=False)
g.mean() #分组统计平均值
以地区分组:
分组统计价格平均值
g.价格.mean()
Pandas-DataFrame
DataFrame对象排序
按索引排序可以使用sort_index()函数
按值排序可以使用sort_values()函数。
df_sort=df.sort_index(ascending=False)
按索引降序
按“价格”列降序
df_sort=df.sort_values("价格",ascending=False)
异或 in Python
简单异或在python中用^表示
二进制 十进制
0110100 42
xor 0011110 30
结果 0101010 52
1.在BXY中输入如下代码:
from microbit import *
if button_A.is_pressed():
display.show(str(random.randint(2,5)))
elif button_B. is_pressed ():
display.show(str(random.randrange(2,5)))
下载并运行该代码,下列关于代码执行效果的 描述,正确的是 ( )
A.按下按钮A, micro:bit的LED点阵可能显示5
B.按下按钮A, micro:bit的LED点阵不可能显示2
C.按下按钮B, micro:bit的LED点阵可能显示5
D.按下按钮B, micro:bit的LED点阵不可能显示2
3.小王在BXY中输入下图中的代码,烧录成功后,下列说法正确的是( )
A.按下 micro:bit 开发板的按钮a , LED点阵滚动显示“Hello World!"
B.按下 micro:bit 开发板的按钮b , LED点阵滚动显示“Hello World!"
C.按下 micro:bit 开发板按钮b,程序结束
D.没有按任何按钮时,LED点阵滚动显示 "Hello World!"
网络协议
TCP/IP协议(传输控制协议/网际协议):网络中最基本的通信协议,TCP/IP协议不是单一协议,而是一个协议簇。使用TCP/IP协议,需要详细设置IP地址、子网掩码、默认网关、DNS服务器等操作。
网络协议
TCP/IP协议(传输控制协议/网际协议):网络中最基本的通信协议,TCP/IP协议不是单一协议,而是一个协议簇。使用TCP/IP协议,需要详细设置IP地址、子网掩码、默认网关、DNS服务器等操作。
FTP协议(文件传输协议):用于传输网络电子文件的协议。
IP地址
IP地址是指互联网协议地址(网际协议地址),是IP协议提供的一种统一的地址格式,它为互联网上的每一台主机分配一个逻辑地址,助于进行通信。
IP地址的格式
IPv4地址是一个32位的二进制数,通常被分割为4个8位二进制数(也就是4个字节)。IPv4地址通常用“点分十进制”表示成(a.b.c.d) 的形式,其中,a, b, c, d都是0 255之间的十进制整数。
例如,点分十进制IP地址“100.4.5.6",实际上是32位二进制数
“01100100.00000100.00000101.00000110"
内网的计算机可向Internet上的其他计算机发送连接请求,但Internet上其他的计算机无法向内网的计算机发送连接请求。若想让外界的计算机访问本地主机,我们可以使用内网穿透或申请公网IP两种方式。
内网IP地址
DNS服务器
DNS服务器主要用于域名解析,即将主机名解析成IP地址。互联网中的 DNS服务器是一个分层结构,由很多DNS服务器组成,里面的数据库事先存放着各种域名或主机名对应的IP地址。用户计算机发出域名解析的请求,DNS服务器就会返回对应的IP地址。
DHCP
DHCP是动态主机配置协议。DHCP服务器控制一段lP 地址范围,用于集中管理和分配IP 地址,客户机登录服务器时就可以自动获得服务器分配的lP地址和子网掩码。DHCP的主要作用是集中管理、分配IP地址,使网络环境中的主机动态地获得IP地址、默认网关地址、DNS服务器地址等信息,从而提升IP地址的利用率。
1.小王编写了一个简单的Flask程序,其中路由编写和视图函数如下,运行程序后,在浏览器中输入 http://127.0.0.1:5000/hello/People, 网页显示的内容为( )
from flask import Flask
app = Flask (_name_)
@ app.route ('/hello/
def hello():
return render_template ( 'hello.html', name = name)
if __name_ = '__main__' :
app.run ( host = '0.0.0.0', debug = True)
{% if name %}
{% else %}
{ % endif %}
A.Hello World!
B.Hello Sample
C.Hello People!
D.Hello People
15.小王用Flask Web框架编写程序,访问系统的地址为http ://192.168.4.200:86 部分代码如下:
from flask import Flask, render_template
#导入Flask库
app = Flask (__name__)
① ____________
def index():
#获取数据库中传感器采集的数据,并存储在 变量temp中,代码略
return renden_template ('index, html', txt = temp)
if ②___________________:
app.run(host =③____________________)
为了完整功能,请在代码划线处填入合适的语句。
小明搭建了“运动会项目报名管理系统”,在Python环境下使用SQLite数据库文件“test.db”,其中数据表为“data”,该数据表字段结构如下表:
下列程序代码用于建立数据库文件(该文件位于当前文件夹下)和数据表,请在①②处 填写合适的代码。
import sqlite3
conn =①___________#建立数据库
cur = conn.cursor()
sql_cdb =‘②_______________________'
cur.execute (sql_cdb) # 建立数据表
conn.commit ()
cur.close ()
conn.close ()
小李用Flask框架设计了基于Web环境下的 “查阅图书信息系统”,可以通过浏览器查找图书信息,访问该系统的Web地址为“http://192.168.0.101”,部分代码如下,请在①② 处填写合适的代码。
app = Flask (__name__)
①____________
def index ():
#查阅图书信息代码略
if __name__== __main__ :
app.run (② ____________)
同课章节目录