5.2数据的采集 课件 2022—2023学年粤教版(2019)高中信息技术必修1(27张PPT)
文档属性
| 名称 | 5.2数据的采集 课件 2022—2023学年粤教版(2019)高中信息技术必修1(27张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 41.0MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 粤教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2022-09-21 00:00:00 | ||
图片预览





文档简介
(共27张PPT)
5.2
数据的采集
H01005001.0。
105
TT.11.00010
情景导入
制作反诈宣传册需要什么?
防疤电信网络非骗
防非保护自附产欢全
辆
宣传手册
不轻信
网缩广告+“购物送
3中奖
卖
电信作罪
小心谨慎
不轻信
不透露不汇
及时向公安机
诈端识别公式要主
+
>>预防电信诈
国家反诈中心
、
数据采集的方法
大数据时代,我们如何获取大量的数据?
01
系统日志采集法
网络爬虫
数据采集的
02
网络数据采集法
方法与工具
网络公开API
03
(应用程序接口)
其他数据采集法
上、
数据采集的方法)
系统日志采集法
系统日志
系统日志采集
系统日志是记录系统中硬件、
在目标主机上安装一个小
软件和系统问题的信息文件。系统
程序,将目标主机的文本、应
用程序、数据库等日志信息有
日志包括操作系统日志、应用程序
选择地定向推送到日志服务器
日志和安全日志。
进行存储、监控和管理。
、
数据采集的方法
URL
URL
网页
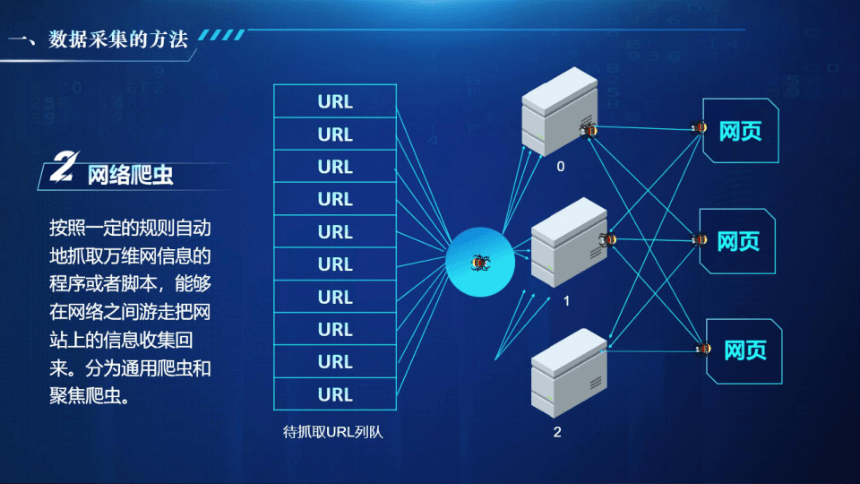
网络爬虫
URL
URL
按照一定的规则自动
URL
网页
地抓取万维网信息的
URL
程序或者脚本,能够
URL
在网络之间游走把网
站上的信息收集回
URL
网页
来。分为通用爬虫和
URL
聚焦爬虫。
URL
待抓取URL列队
2
、
数据采集的方法
2.认识模块库
requests库
re库
(正则表达式)
python的模块库,可以通过调用来
是Pythonl的内置模块库,通过匹
帮助我们实现自动爬取网页页面以
配字符串解析网页内容。
及模拟人类访问服务器,自动提交
网络请求。
数据采集的方法I
2.认识模块库
使用importi语句导入模块的语法:
import module
import
requests
import I
re
使用from importi语句导入模块内指定方法的语法:
from module import
name
from PIL import Image
from PIL import
、
数据采集的方法
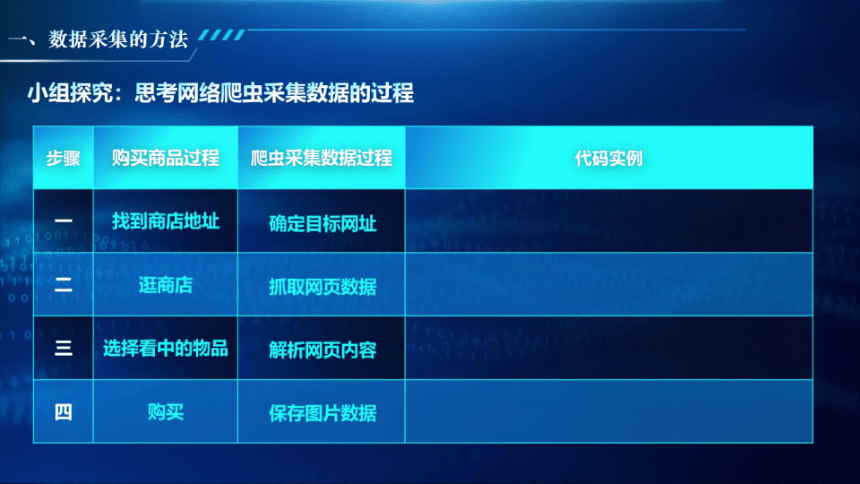
小组探究:思考网络爬虫采集数据的过程
步骤
购买商品过程
爬虫采集数据过程
代码实例
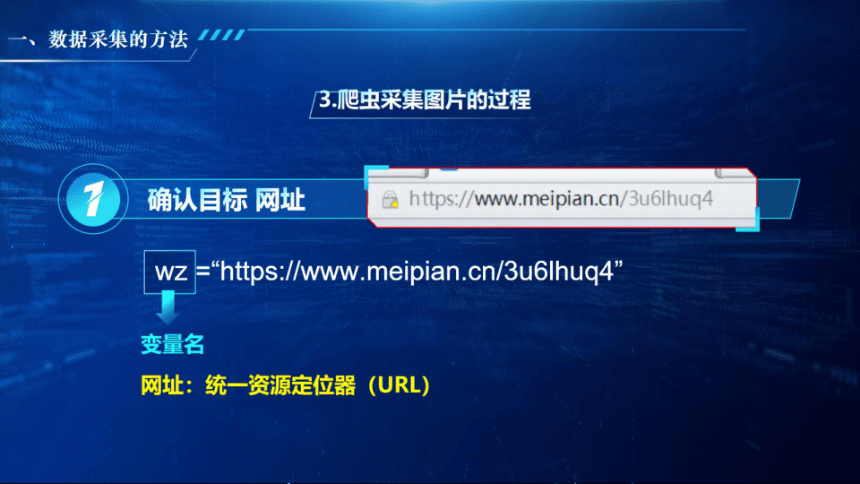
找到商店地址
确定目标网址
110
0011
84610
二
逛商店
抓取网页数据
00
10
三
选择看中的物品
解析网页内容
1019010011
111191111
四
购买
保存图片数据
5.2
数据的采集
H01005001.0。
105
TT.11.00010
情景导入
制作反诈宣传册需要什么?
防疤电信网络非骗
防非保护自附产欢全
辆
宣传手册
不轻信
网缩广告+“购物送
3中奖
卖
电信作罪
小心谨慎
不轻信
不透露不汇
及时向公安机
诈端识别公式要主
+
>>预防电信诈
国家反诈中心
、
数据采集的方法
大数据时代,我们如何获取大量的数据?
01
系统日志采集法
网络爬虫
数据采集的
02
网络数据采集法
方法与工具
网络公开API
03
(应用程序接口)
其他数据采集法
上、
数据采集的方法)
系统日志采集法
系统日志
系统日志采集
系统日志是记录系统中硬件、
在目标主机上安装一个小
软件和系统问题的信息文件。系统
程序,将目标主机的文本、应
用程序、数据库等日志信息有
日志包括操作系统日志、应用程序
选择地定向推送到日志服务器
日志和安全日志。
进行存储、监控和管理。
、
数据采集的方法
URL
URL
网页
网络爬虫
URL
URL
按照一定的规则自动
URL
网页
地抓取万维网信息的
URL
程序或者脚本,能够
URL
在网络之间游走把网
站上的信息收集回
URL
网页
来。分为通用爬虫和
URL
聚焦爬虫。
URL
待抓取URL列队
2
、
数据采集的方法
2.认识模块库
requests库
re库
(正则表达式)
python的模块库,可以通过调用来
是Pythonl的内置模块库,通过匹
帮助我们实现自动爬取网页页面以
配字符串解析网页内容。
及模拟人类访问服务器,自动提交
网络请求。
数据采集的方法I
2.认识模块库
使用importi语句导入模块的语法:
import module
import
requests
import I
re
使用from importi语句导入模块内指定方法的语法:
from module import
name
from PIL import Image
from PIL import
、
数据采集的方法
小组探究:思考网络爬虫采集数据的过程
步骤
购买商品过程
爬虫采集数据过程
代码实例
找到商店地址
确定目标网址
110
0011
84610
二
逛商店
抓取网页数据
00
10
三
选择看中的物品
解析网页内容
1019010011
111191111
四
购买
保存图片数据
同课章节目录
- 第一章 数据与信息
- 项目范例 体验庆祝国庆多媒体作品的数据与信息处理
- 1.1 数据及其特征
- 1.2 数据编码
- 1.3 信息及其特征
- 第二章 知识与数字化学习
- 项目范例 运用数字化工具探究数理知识
- 2.1 知识与智慧
- 2.2 数字化学习与创新
- 第三章 算法基础
- 项目范例 设计从A市到B市耗时最少的旅行路线方案
- 3.1 体验计算机解决问题的过程
- 3.2 算法及其描述
- 3.3 计算机程序与程序设计语言
- 第四章 程序设计基础
- 项目范例 设计购买纪念品的最佳方案
- 4.1 程序设计语言的基础知识
- 4.2 运用顺序结构描述问题求解过程
- 4.3 运用选择结构描述问题求解过程
- 4.4 运用循环结构描述问题求解过程
- 第五章 数据处理和可视化表达
- 项目范例 网络购物平台客户行为数据分析和可视化表达
- 5.1 认识大数据
- 5.2 数据的采集
- 5.3 数据的分析
- 5.4 数据的可视化表达
- 第六章 人工智能及其应用
- 项目范例 剖析空调企业智能客服机器人
- 6.1 认识人工智能
- 6.2 人工智能的应用