5.3 数据的分析 课件 2022—2023学年高中信息技术粤教版(2019)必修1(32张PPT)
文档属性
| 名称 | 5.3 数据的分析 课件 2022—2023学年高中信息技术粤教版(2019)必修1(32张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 36.1MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 粤教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2022-10-18 00:00:00 | ||
图片预览






文档简介
(共32张PPT)
5.3 数据的分析
必修一 《数据与计算》
5.3 数据分析
高中信息技术必修1 数据与计算
5.3 数据的分析
什么是数据分析?
数据分析是在一大批杂乱无章的数据中,运用数字化工具和技术,探索数据内在的结构和规律,构建数学模型,并进行可视化表达,通过验证将模型转化为知识,为诊断过去、预测未来发挥作用。
高中信息技术必修1 数据与计算
5.3 数据的分析
什么是数据分析?
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
水资源分布现状
过去旅游业的发展情况
了解事物的现状
诊断过去的发展历程
预测房价走向
预测未来的走向
数据分析
高中信息技术必修1 数据与计算
5.3 数据的分析
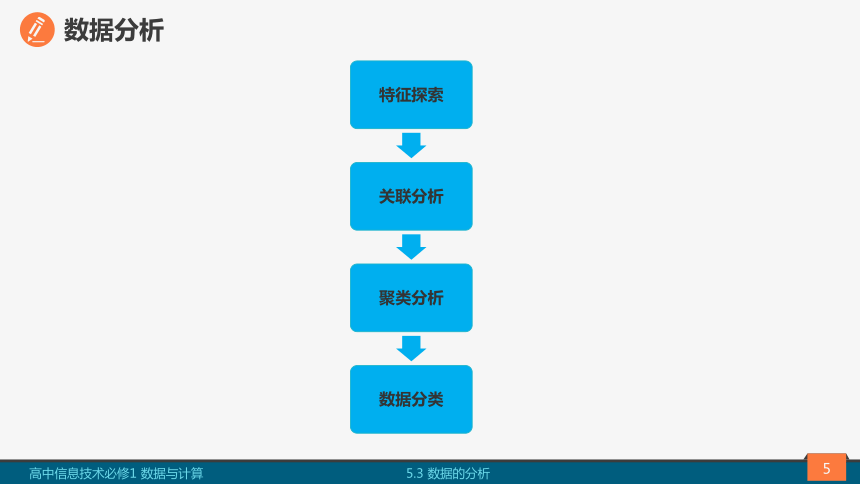
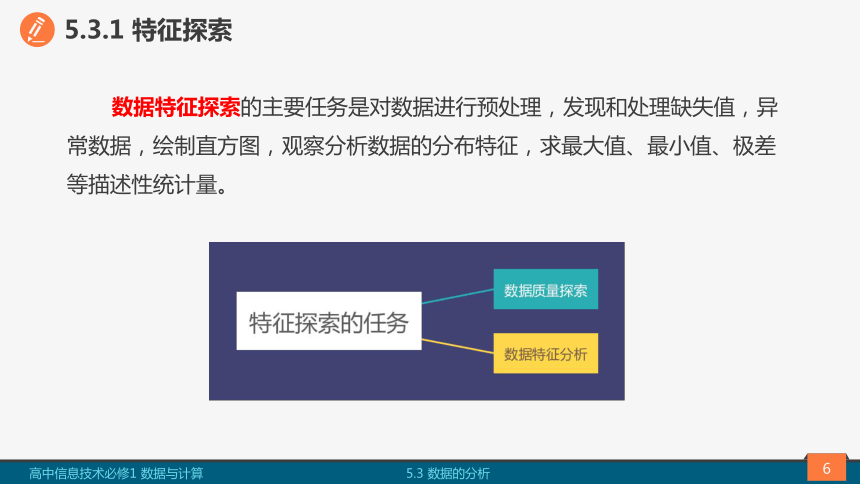
5.3.1 特征探索
数据特征探索的主要任务是对数据进行预处理,发现和处理缺失值,异常数据,绘制直方图,观察分析数据的分布特征,求最大值、最小值、极差等描述性统计量。
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.1 特征探索
高中信息技术必修1 数据与计算
5.3 数据的分析
数据质量探索、数据特征分析
143 81 30
200 86 29
50 77 30
5.3.1 特征探索
高中信息技术必修1 数据与计算
5.3 数据的分析
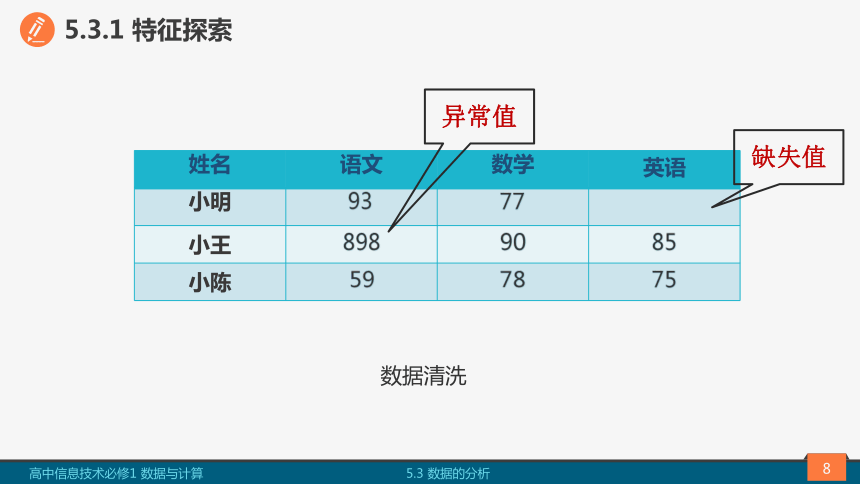
姓名 语文 数学 英语
小明 93 77
小王 898 90 85
小陈 59 78 75
缺失值
异常值
数据清洗
5.3.1 特征探索
数据特征探索程序
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.1 特征探索
探究活动一(暂停课程视频5分钟):
打开并运行配套学习资源包“第五章\课本素材\程序5-3数据预处理”,观察数据预处理结果。
高中信息技术必修1 数据与计算
5.3 数据的分析
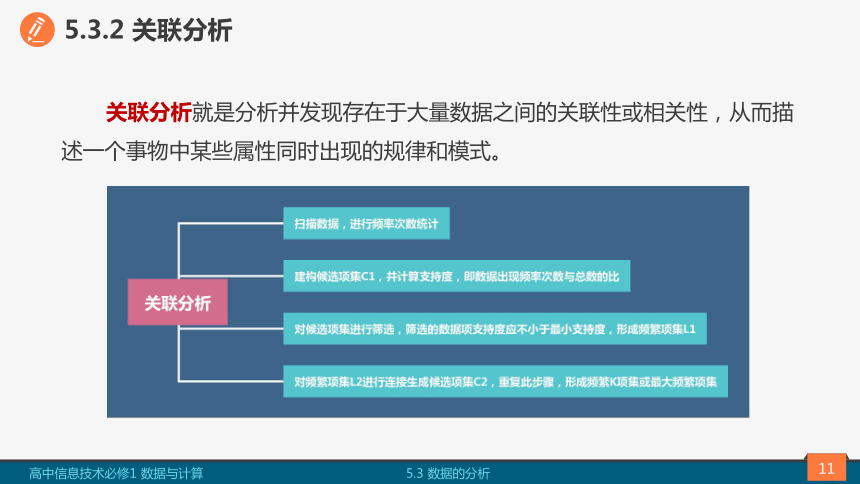
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
关联分析就是分析并发现存在于大量数据之间的关联性或相关性,从而描述一个事物中某些属性同时出现的规律和模式。
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
购物篮分析一一了解顾客购买习惯一一给商家提供销售策略
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
67%
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
序号 商品
1 可乐,鸡蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
4 尿布,啤酒
计算机如何对数据进行关联分析
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
购物篮分析
步骤一:扫描数据,建立项集
序号 商品
1 可乐,鸡蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
4 尿布,啤酒
c1项集:
[可乐]
[鸡蛋]
[火腿]
[尿布]
[啤酒]
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
购物篮分析
步骤二:计算各个集合的支持度,即数据出现频率次数/总数
序号 商品
1 可乐,料蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
4 尿布,啤酒
C1项集 支持度
[可乐] 3/4=0.75
[鸡蛋] 1/4=0.25
[火腿] 2/4=0.50
[尿布] 3/4=0.75
[啤酒] 3/4=0.75
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
购物篮分析
步骤三:设置最小支持度=0.4
序号 商品
1 可乐,鸡蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
4 尿布,啤酒
c1项集:
[可乐]
[鸡蛋]
[火腿]
[尿布]
[啤酒]
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
步骤三:设置最小支持度=0.4
C1项集 支持度
[可乐] 3/4=0.75
[鸡蛋] 1/4=0.25
[火腿] 2/4=0.50
[尿布] 3/4=0.75
[啤酒] 3/4=0.75
频繁项集L1
[可乐] [火腿]
[尿布]
[啤酒]
购物篮分析
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
C1项集 支持度
[可乐] 3/4=0.75
[鸡蛋] 1/4=0.25
[火腿] 2/4=0.50
[尿布] 3/4=0.75
[啤酒] 3/4=0.75
频繁项集L1
[可乐] [火腿]
[尿布]
[啤酒]
C2项集 支持度
[可乐,火腿] 2/4=0.50
[可乐,尿布] 2/4=0.50
[可乐,啤酒] 2/4=0.50
[火腿,尿布] 1/4=0.25
[火腿,啤酒] 1/4=0.25
[尿布,啤酒] 3/4=0.75
频繁项集L2
[可乐,火腿] [可乐,尿布][可乐,啤酒]
[尿布,啤酒]
步骤四:将L1中的数据两两拼接
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
C1项集 支持度
[可乐] 3/4=0.75
[鸡蛋] 1/4=0.25
[火腿] 2/4=0.50
[尿布] 3/4=0.75
[啤酒] 3/4=0.75
频繁项集L1
[可乐] [火腿]
[尿布]
[啤酒]
C2项集 支持度
[可乐,火腿] 2/4=0.50
[可乐,尿布] 2/4=0.50
[可乐,啤酒] 2/4=0.50
[火腿,尿布] 1/4=0.25
[火腿,啤酒] 1/4=0.25
[尿布,啤酒] 3/4=0.75
频繁项集L2
[可乐,火腿] [可乐,尿布][可乐,啤酒]
[尿布,啤酒]
C3项集 支持度
[可乐,火腿,尿布] 2/4=0.50
[可乐,火腿,啤酒] 2/4=0.50
[可乐,尿布,啤酒] 2/4=0.50
频繁项集L3
...Lk
步骤五:将L2中的数据两两拼接,得到C3
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
探究活动二(暂停课程视频5分钟):
理解关联分析的过程,根据下表,按步骤计算商品的关联性。
序号 商品
1 可乐,鸡蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
5.3.3 聚类分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
5.3.3 聚类分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
聚类分析K-平均算法
K-平均算法的基本思想就是在空间N个点中,初始选择K个点作为中心聚类点,然后将N个点分别与K个点计算距离,选择自己最近的点作为自己的中心点,再不断更新中心聚集点,以达到“物以类聚,人以群分”的效果。
5.3.3 聚类分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
聚类分析的基本算法:
(1)从数据点集合中随机选择K个点作为初始的聚集中心,每个中心点代表着每个聚集中心的平均值。
(2)对其余的每个数据点,依次判断其与K个中心点的距离,距离最近的表明它属于这项聚类。
(3)重新计算新的聚簇集合的平均值即中心点。整个过程不断迭代计算,直到达到预先设定的迭代次数或中心点不再频繁波动。
5.3.3 聚类分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.4 数据分类
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
数据分类是数据分析处理中最基本的方法。数据分类通常的做法是,基于样本数据先训练构建分类函数或者分类模型(也称为分类器),该分类器具有将待分类数据项映射到某一特点类别的功能。数据分类和回归分析都可用于预测,预测是指从基于样本数据记录,根据分类准则自动给出对未知数据的推广描述,从而实现对未知数据进行预测。
5.3.4 数据分类
高中信息技术必修1 数据与计算
5.3 数据的分析
采集数据
建立分类的模型
对新数据进行 分类
5.3.4 数据分类
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
贝叶斯分类技术在众多分类技术中占有重要地位,也属于统计学分类的范畴,是一种非规则的分类方法。贝叶斯分类技术通过对已分类的样本子集进行训练,学习归纳出分类函数(对离散变量的预测称作分类,对连续变量的分类称为回归),利用训练得到的分类器实现对未分类数据的分类。
5.3.4 数据分类
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
如表所示是某网络商城客户购物行为特征的一组统计资料。已知某客户购物行为特征A为数值182.8,特征B为数值58.9,特征C为数值26,请问这人是重要客户还是普通客户?
客户 特征A 特征B 特征C
重要客户 182.8 81.6 30
重要客户 180.4 86.1 29
重要客户 170.0 77.1 30
重要客户 180.4 74.8 28
普通客户 152.4 45.3 24
普通客户 167.6 68.0 26
普通客户 165.2 58.9 25
普通客户 175.2 68.0 27
5.3.4 数据分类
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.4 数据分类
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
import numpy as np
X=np.array([[182.8,81.6,30],[180.4,86.1,29],[170.0,77.1,30],[180.4,74.8,28],
[152.4,45.3,24],[167.6,68.0,26],[165.2,58.9,25],[175.2,68.0,27]])
Y=np.array([1,1,1,1,0,0,0,0])
from sklearn.naive_bayes import GaussianNB
clf=GaussianNB().fit(X,Y)
print(clf.predict([[182.8,58,9,26]]))
程序结果为:[0]
为普通客户
5.3 数据的分析
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3 数据的分析
必修一 《数据与计算》
5.3 数据分析
高中信息技术必修1 数据与计算
5.3 数据的分析
什么是数据分析?
数据分析是在一大批杂乱无章的数据中,运用数字化工具和技术,探索数据内在的结构和规律,构建数学模型,并进行可视化表达,通过验证将模型转化为知识,为诊断过去、预测未来发挥作用。
高中信息技术必修1 数据与计算
5.3 数据的分析
什么是数据分析?
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
水资源分布现状
过去旅游业的发展情况
了解事物的现状
诊断过去的发展历程
预测房价走向
预测未来的走向
数据分析
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.1 特征探索
数据特征探索的主要任务是对数据进行预处理,发现和处理缺失值,异常数据,绘制直方图,观察分析数据的分布特征,求最大值、最小值、极差等描述性统计量。
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.1 特征探索
高中信息技术必修1 数据与计算
5.3 数据的分析
数据质量探索、数据特征分析
143 81 30
200 86 29
50 77 30
5.3.1 特征探索
高中信息技术必修1 数据与计算
5.3 数据的分析
姓名 语文 数学 英语
小明 93 77
小王 898 90 85
小陈 59 78 75
缺失值
异常值
数据清洗
5.3.1 特征探索
数据特征探索程序
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.1 特征探索
探究活动一(暂停课程视频5分钟):
打开并运行配套学习资源包“第五章\课本素材\程序5-3数据预处理”,观察数据预处理结果。
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
关联分析就是分析并发现存在于大量数据之间的关联性或相关性,从而描述一个事物中某些属性同时出现的规律和模式。
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
购物篮分析一一了解顾客购买习惯一一给商家提供销售策略
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
67%
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
序号 商品
1 可乐,鸡蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
4 尿布,啤酒
计算机如何对数据进行关联分析
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
购物篮分析
步骤一:扫描数据,建立项集
序号 商品
1 可乐,鸡蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
4 尿布,啤酒
c1项集:
[可乐]
[鸡蛋]
[火腿]
[尿布]
[啤酒]
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
购物篮分析
步骤二:计算各个集合的支持度,即数据出现频率次数/总数
序号 商品
1 可乐,料蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
4 尿布,啤酒
C1项集 支持度
[可乐] 3/4=0.75
[鸡蛋] 1/4=0.25
[火腿] 2/4=0.50
[尿布] 3/4=0.75
[啤酒] 3/4=0.75
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
购物篮分析
步骤三:设置最小支持度=0.4
序号 商品
1 可乐,鸡蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
4 尿布,啤酒
c1项集:
[可乐]
[鸡蛋]
[火腿]
[尿布]
[啤酒]
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
步骤三:设置最小支持度=0.4
C1项集 支持度
[可乐] 3/4=0.75
[鸡蛋] 1/4=0.25
[火腿] 2/4=0.50
[尿布] 3/4=0.75
[啤酒] 3/4=0.75
频繁项集L1
[可乐] [火腿]
[尿布]
[啤酒]
购物篮分析
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
C1项集 支持度
[可乐] 3/4=0.75
[鸡蛋] 1/4=0.25
[火腿] 2/4=0.50
[尿布] 3/4=0.75
[啤酒] 3/4=0.75
频繁项集L1
[可乐] [火腿]
[尿布]
[啤酒]
C2项集 支持度
[可乐,火腿] 2/4=0.50
[可乐,尿布] 2/4=0.50
[可乐,啤酒] 2/4=0.50
[火腿,尿布] 1/4=0.25
[火腿,啤酒] 1/4=0.25
[尿布,啤酒] 3/4=0.75
频繁项集L2
[可乐,火腿] [可乐,尿布][可乐,啤酒]
[尿布,啤酒]
步骤四:将L1中的数据两两拼接
5.3.2 关联分析
高中信息技术必修1 数据与计算
5.3 数据的分析
C1项集 支持度
[可乐] 3/4=0.75
[鸡蛋] 1/4=0.25
[火腿] 2/4=0.50
[尿布] 3/4=0.75
[啤酒] 3/4=0.75
频繁项集L1
[可乐] [火腿]
[尿布]
[啤酒]
C2项集 支持度
[可乐,火腿] 2/4=0.50
[可乐,尿布] 2/4=0.50
[可乐,啤酒] 2/4=0.50
[火腿,尿布] 1/4=0.25
[火腿,啤酒] 1/4=0.25
[尿布,啤酒] 3/4=0.75
频繁项集L2
[可乐,火腿] [可乐,尿布][可乐,啤酒]
[尿布,啤酒]
C3项集 支持度
[可乐,火腿,尿布] 2/4=0.50
[可乐,火腿,啤酒] 2/4=0.50
[可乐,尿布,啤酒] 2/4=0.50
频繁项集L3
...Lk
步骤五:将L2中的数据两两拼接,得到C3
5.3.2 关联分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
探究活动二(暂停课程视频5分钟):
理解关联分析的过程,根据下表,按步骤计算商品的关联性。
序号 商品
1 可乐,鸡蛋,火腿
2 可乐,尿布,啤酒
3 可乐,尿布,啤酒,火腿
5.3.3 聚类分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
5.3.3 聚类分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
聚类分析K-平均算法
K-平均算法的基本思想就是在空间N个点中,初始选择K个点作为中心聚类点,然后将N个点分别与K个点计算距离,选择自己最近的点作为自己的中心点,再不断更新中心聚集点,以达到“物以类聚,人以群分”的效果。
5.3.3 聚类分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
聚类分析的基本算法:
(1)从数据点集合中随机选择K个点作为初始的聚集中心,每个中心点代表着每个聚集中心的平均值。
(2)对其余的每个数据点,依次判断其与K个中心点的距离,距离最近的表明它属于这项聚类。
(3)重新计算新的聚簇集合的平均值即中心点。整个过程不断迭代计算,直到达到预先设定的迭代次数或中心点不再频繁波动。
5.3.3 聚类分析
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.4 数据分类
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
数据分类是数据分析处理中最基本的方法。数据分类通常的做法是,基于样本数据先训练构建分类函数或者分类模型(也称为分类器),该分类器具有将待分类数据项映射到某一特点类别的功能。数据分类和回归分析都可用于预测,预测是指从基于样本数据记录,根据分类准则自动给出对未知数据的推广描述,从而实现对未知数据进行预测。
5.3.4 数据分类
高中信息技术必修1 数据与计算
5.3 数据的分析
采集数据
建立分类的模型
对新数据进行 分类
5.3.4 数据分类
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
贝叶斯分类技术在众多分类技术中占有重要地位,也属于统计学分类的范畴,是一种非规则的分类方法。贝叶斯分类技术通过对已分类的样本子集进行训练,学习归纳出分类函数(对离散变量的预测称作分类,对连续变量的分类称为回归),利用训练得到的分类器实现对未分类数据的分类。
5.3.4 数据分类
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
如表所示是某网络商城客户购物行为特征的一组统计资料。已知某客户购物行为特征A为数值182.8,特征B为数值58.9,特征C为数值26,请问这人是重要客户还是普通客户?
客户 特征A 特征B 特征C
重要客户 182.8 81.6 30
重要客户 180.4 86.1 29
重要客户 170.0 77.1 30
重要客户 180.4 74.8 28
普通客户 152.4 45.3 24
普通客户 167.6 68.0 26
普通客户 165.2 58.9 25
普通客户 175.2 68.0 27
5.3.4 数据分类
高中信息技术必修1 数据与计算
5.3 数据的分析
5.3.4 数据分类
李海青
高中信息技术必修1 数据与计算
5.3 数据的分析
import numpy as np
X=np.array([[182.8,81.6,30],[180.4,86.1,29],[170.0,77.1,30],[180.4,74.8,28],
[152.4,45.3,24],[167.6,68.0,26],[165.2,58.9,25],[175.2,68.0,27]])
Y=np.array([1,1,1,1,0,0,0,0])
from sklearn.naive_bayes import GaussianNB
clf=GaussianNB().fit(X,Y)
print(clf.predict([[182.8,58,9,26]]))
程序结果为:[0]
为普通客户
5.3 数据的分析
高中信息技术必修1 数据与计算
5.3 数据的分析
同课章节目录
- 第一章 数据与信息
- 项目范例 体验庆祝国庆多媒体作品的数据与信息处理
- 1.1 数据及其特征
- 1.2 数据编码
- 1.3 信息及其特征
- 第二章 知识与数字化学习
- 项目范例 运用数字化工具探究数理知识
- 2.1 知识与智慧
- 2.2 数字化学习与创新
- 第三章 算法基础
- 项目范例 设计从A市到B市耗时最少的旅行路线方案
- 3.1 体验计算机解决问题的过程
- 3.2 算法及其描述
- 3.3 计算机程序与程序设计语言
- 第四章 程序设计基础
- 项目范例 设计购买纪念品的最佳方案
- 4.1 程序设计语言的基础知识
- 4.2 运用顺序结构描述问题求解过程
- 4.3 运用选择结构描述问题求解过程
- 4.4 运用循环结构描述问题求解过程
- 第五章 数据处理和可视化表达
- 项目范例 网络购物平台客户行为数据分析和可视化表达
- 5.1 认识大数据
- 5.2 数据的采集
- 5.3 数据的分析
- 5.4 数据的可视化表达
- 第六章 人工智能及其应用
- 项目范例 剖析空调企业智能客服机器人
- 6.1 认识人工智能
- 6.2 人工智能的应用