3.1 回归分析的基本思想及其初步应用 课件(共43张PPT)
文档属性
| 名称 | 3.1 回归分析的基本思想及其初步应用 课件(共43张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 1.1MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 人教新课标A版 | ||
| 科目 | 数学 | ||
| 更新时间 | 2022-12-07 00:00:00 | ||
图片预览








文档简介
(共43张PPT)
3.1 回归分析的基本思想
及其初步应用
课标要求:
1.了解残差平方和、相关指数R2的概念.
2.了解回归分析的基本步骤.
3.会用残差平方和与相关指数R2对回归模型拟合度进行评判.
4.了解简单的非线性回归分析方法.
素养达成:
通过残差分析的学习,使学生养成了建模能力、数据分析处理能力等.
问题一:线性回归模型 课本 例题1 练习册P58例1、训练1-1
问题二:线性回归分析:残差图与 练习册P58例2、训练2-1
问题三:非线性回归方程(与回归直线的联系) 课本P87例2 练习册P59例3、训练3-1
温故知新
两个变量的关系
不相关
相关关系
函数关系
线性相关
非线性相关
函数关系中的两个变量间是一种确定性关系。
相关关系是一种非确定性关系。
自变量取值一定时,因变量的取值带有一定随机性的两个变量之间的关系叫做相关关系。
1、定义:
1):相关关系是一种不确定性关系;
注
对具有相关关系的两个变量进行统计分析的方法叫回归分析。
2):
2、现实生活中存在着大量的相关关系。
如:人的身高与年龄;
产品的成本与生产数量;
商品的销售额与广告费;
家庭的支出与收入。等等
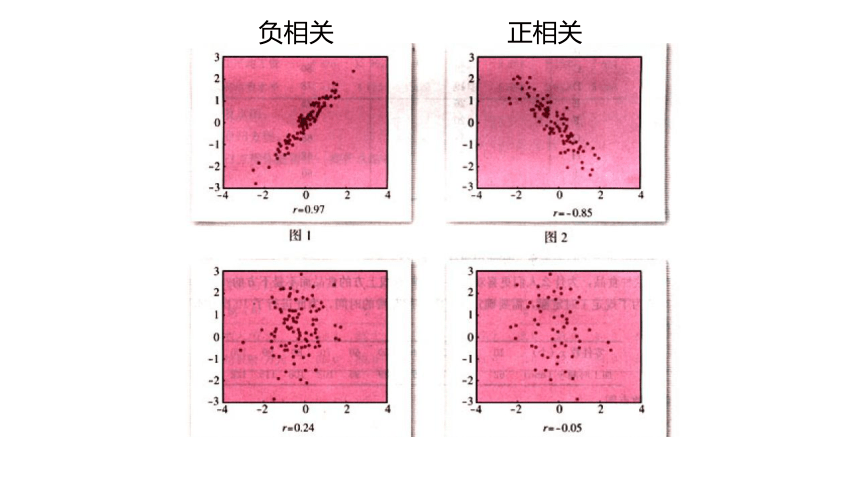
负相关
正相关
例1、某大学中随机选取8名女大学生,其身高和体重数据如下表所示.
编号 1 2 3 4 5 6 7 8
身高/cm 165 165 157 170 175 165 155 170
体重/kg 48 57 50 54 64 61 43 59
求根据女大学生的身高预报体重的回归方程,并预报一名身高为172cm的女大学生的体重.
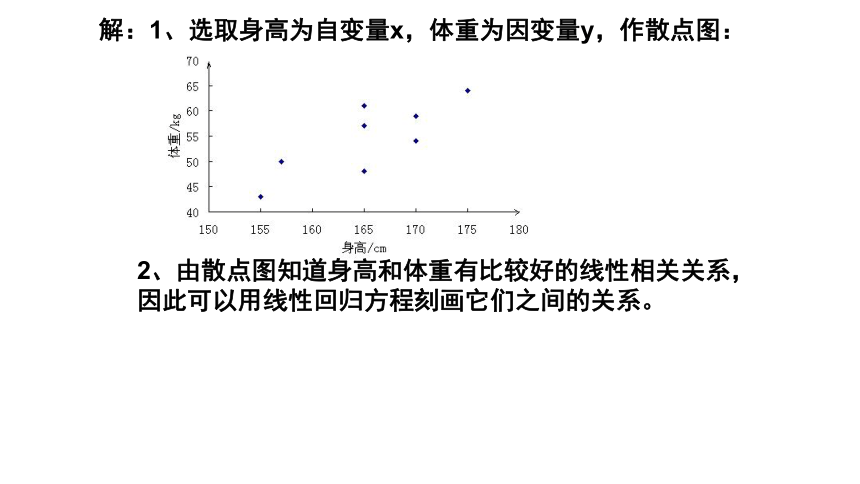
解:1、选取身高为自变量x,体重为因变量y,作散点图:
2、由散点图知道身高和体重有比较好的线性相关关系,因此可以用线性回归方程刻画它们之间的关系。
根据最小二乘法估计 和 就是未知参数a和b的最好估计,
于是有
所以回归方程是
所以,对于身高为172cm的女大学生,由回归方程可以预报其体重为
探究P4:
身高为172cm的女大学生的体重一定是60.316kg吗?如果不是,你能解析一下原因吗?
样本点呈条状分布,身高和体重有较好的线性相关关系,因此可以用回归方程来近似的刻画它们之间的关系.
解:散点图:
3、从散点图还看到,样本点散布在某一条直线的附近,而不是在一条直线上,所以不能用一次函数y=bx+a简单描述它们关系。
我们可以用下面的线性回归模型来表示:
y=bx+a+e,其中a和b为模型的未知参数,
e称为随机误差。
思考P3
产生随机误差项e
的原因是什么?
思考P3
产生随机误差项e的原因是什么?
随机误差e的来源(可以推广到一般):
1、其它因素的影响:影响体重 y 的因素不只是身高 x,可能还包括遗传基因、饮食习惯、生长环境等因素;
2、身高 x的观测误差。
线性回归模型y=bx+a+e增加了随机误差项e,因变量y的值由自变量x和随机误差项e共同确定,即自变量x只能解析部分y的变化。
在统计中,我们也把自变量x称为解析变量,因变量y为预报变量。
残差
数据点和它在回归直线上相应位置的差异 称为相应于点(xi,yi ) 的残差。
例:编号为6的女大学生,计算随机误差的效应(残差)
残差平方和
把每一个残差所得的值平方后加起来,用数学符号表示为:
称为残差平方和
在例1中,残差平方和约为128.361。
表1-4列出了女大学生身高和体重的原始数据以及相应的残差数据。
残差分析与残差图的定义:
我们可以通过残差 来判断模型拟合的效果,
判断原始数据中是否存在可疑数据,
这方面的分析工作称为残差分析。
编号 1 2 3 4 5 6 7 8
身高 165 165 157 170 175 165 155 170
体重/kg 48 57 50 54 64 61 43 59
残差 -6.373 2.627 2.419 -4.618 1.137 6.627 -2.883 0.382
我们可以利用图形来分析残差特性,作图时纵坐标为残差,横坐标可以选为样本编号,或身高数据,或体重估计值等,这样作出的图形称为残差图。
残若模型选择的正确,残差图中的点应该分布在以横轴为心的带形区域;
对于远离横轴的点,要特别注意。
身高与体重残差图
异常点
错误数据
模型问题
几点说明:
第一个样本点和第6个样本点的残差比较大,需要确认在采集过程中是否有人为的错误。如果数据采集有错误,就予以纠正,然后再重新利用线性回归模型拟合数据;如果数据采集没有错误,则需要寻找其他的原因。
另外,残差点比较均匀地落在水平的带状区域中,说明选用的模型计较合适,这样的带状区域的宽度越窄,说明模型拟合精度越高,回归方程的预报精度越高。
我们可以用相关指数R2来刻画回归的效果,其计算公式是
显然,R2的值越大,说明残差平方和越小,也就是说模型拟合效果越好。
R2越接近1,表示回归的效果越好(因为R2越接近1,表示解析变量和预报变量的线性相关性越强)
如果某组数据可能采取几种不同回归方程进行回归分析,则可以通过比较R2的值来做出选择,即选取R2较大的模型作为这组数据的模型。
总的来说:
相关指数R2是度量模型拟合效果的一种指标。
在线性模型中,它代表自变量刻画预报变量的能力。
一般地,建立回归模型的基本步骤为:
(1)确定研究对象,明确哪个变量是解析变量,哪个变量是预报变量。
(2)画出确定好的解析变量和预报变量的散点图,观察它们之间的关系(如是否存在线性关系等)。
(3)由经验确定回归方程的类型(如我们观察到数据呈线性关系,则选用线性回归方程y=bx+a).
(4)按一定规则估计回归方程中的参数(如最小二乘法)。
(5)得出结果后分析残差图是否有异常(个别数据对应残差过大,或残差呈现不随机的规律性,等等),过存在异常,则检查数据是否有误,或模型是否合适等。
例2、在一段时间内,某中商品的价格x元和需求量Y件之间的一组数据为:
求出Y对的回归直线方程,并说明拟合效果的好坏。
价格x 14 16 18 20 22
需求量Y 12 10 7 5 3
解:
例2、在一段时间内,某中商品的价格x元和需求量Y件之间的一组数据为:
求出Y对的回归直线方程,并说明拟合效果的好坏。
价格x 14 16 18 20 22
需求量Y 12 10 7 5 3
列出残差表为
0.994
因而,拟合效果较好。
0
0.3
-0.4
-0.1
0.2
4.6
2.6
-0.4
-2.4
-4.4
相关指数越大,效果越好
残差平方和越小,效果越好
探索无止境
小结
1.残差平方和与模型拟合效果关系:
2.相关指数与模型拟合效果关系
1.2.3循环语句
新课标高二数学 选修2-3
3.1回归分析的基本思想及其初步应用(二)
复习回顾
1、线性回归模型:
y=bx+a+e, (3)
其中a和b为模型的未知参数,e称为随机误差。
y=bx+a+e,
E(e)=0,D(e)= (4)
2、数据点和它在回归直线上相应位置的差异 是随机误差的效应,称 为残差。
3、对每名女大学生计算这个差异,然后分别将所得的值平方后加起来,用数学符号表示为:
称为残差平方和,它代表了随机误差的效应。
4、两个指标:
(1)类比样本方差估计总体方差的思想,可以用作
为 的估计量, 越小,预报精度越高。
(2)我们可以用相关指数R2来刻画回归的效果,其
计算公式是:
R2 1,说明回归方程拟合的越好;R2 0,说明回归方程拟合的越差。
表3-2列出了女大学生身高和体重的原始数据以及相应的残差数据。
在研究两个变量间的关系时,首先要根据散点图来粗略判断它们是否线性相关,是否可以用回归模型来拟合数据。
5、残差分析与残差图的定义:
然后,我们可以通过残差 来判断模型拟合的效果,判断原始数据中是否存在可疑数据,这方面的分析工作称为残差分析。
编号 1 2 3 4 5 6 7 8
身高/cm 165 165 157 170 175 165 155 170
体重/kg 48 57 50 54 64 61 43 59
残差 -6.373 2.627 2.419 -4.618 1.137 6.627 -2.883 0.382
我们可以利用图形来分析残差特性,作图时纵坐标为残差,横坐标可以选为样本编号,或身高数据,或体重估计值等,这样作出的图形称为残差图。
残差图的制作及作用
1、坐标纵轴为残差变量,横轴可以有不同的选择;
2、若模型选择的正确,残差图中的点应该分布在以横轴为心的带形区域;
3、对于远离横轴的点,要特别注意。
身高与体重残差图
异常点
错误数据
模型问题
几点说明:
第一个样本点和第6个样本点的残差比较大,需要确认在采集过程中是否有人为的错误。如果数据采集有错误,就予以纠正,然后再重新利用线性回归模型拟合数据;如果数据采集没有错误,则需要寻找其他的原因。
另外,残差点比较均匀地落在水平的带状区域中,说明选用的模型计较合适,这样的带状区域的宽度越窄,说明模型拟合精度越高,回归方程的预报精度越高。
6、注意回归模型的适用范围:
(1)回归方程只适用于我们所研究的样本的总体。样本数据来自哪个总体的,预报时也仅适用于这个总体。
(2)模型的时效性。利用不同时间段的样本数据建立的模型,只有用来对那段时间范围的数据进行预报。
(3)建立模型时自变量的取值范围决定了预报时模型的适用范围,通常不能超出太多。
(4)在回归模型中,因变量的值不能由自变量的值完全确定。正如前面已经指出的,某个女大学生的身高为172cm,我们不能利用所建立的模型预测她的体重,只能给出身高为172cm的女大学生的平均体重的预测值。
7、一般地,建立回归模型的基本步骤为:
(1)确定研究对象,明确哪个变量是解析变量,哪个变量是预报变量。
(2)画出确定好的解析变量和预报变量的散点图,观察它们之间的关系(如是否存在线性关系等)。
(3)由经验确定回归方程的类型(如我们观察到数据呈线性关系,则选用线性回归方程y=bx+a).
(4)按一定规则估计回归方程中的参数(如最小二乘法)。
(5)得出结果后分析残差图是否有异常(个别数据对应残差过大,或残差呈现不随机的规律性,等等),过存在异常,则检查数据是否有误,或模型是否合适等。
例1 在一段时间内,某中商品的价格x元和需求量Y件之间的一组数据为:
求出Y对的回归直线方程,并说明拟合效果的好坏。
价格x 14 16 18 20 22
需求量Y 12 10 7 5 3
解:
例1 在一段时间内,某中商品的价格x元和需求量Y件之间的一组数据为:
求出Y对的回归直线方程,并说明拟合效果的好坏。
价格x 14 16 18 20 22
需求量Y 12 10 7 5 3
列出残差表为
0.994
因而,拟合效果较好。
0
0.3
-0.4
-0.1
0.2
4.6
2.6
-0.4
-2.4
-4.4
案例2 一只红铃虫的产卵数y和温度x有关。现收集了7组观测数据列于表中:
(1)试建立产卵数y与温度x之间的回归方程;并预测温度为28oC时产卵数目。
(2)你所建立的模型中温度在多大程度上解释了产卵数的变化?
温度xoC
21
23
25
27
29
32
35
产卵数y/个
7
11
21
24
66
115
325
非线性回归问题
假设线性回归方程为 : =bx+a
选 模 型
由计算器得:线性回归方程为y=19.87x-463.73
相关指数R2=r2≈0.8642=0.7464
估计参数
解:选取气温为解释变量x,产卵数
为预报变量y。
选变量
所以,一次函数模型中温度解释了74.64%的产卵数变化。
探索新知
画散点图
0
50
100
150
200
250
300
350
0
3
6
9
12
15
18
21
24
27
30
33
36
39
方案1
分析和预测
当x=28时,y =19.87×28-463.73≈ 93
一元线性模型
奇怪?
93>66
模型不好?
y=bx2+a 变换 y=bt+a
非线性关系 线性关系
方案2
问题1
选用y=bx2+a ,还是y=bx2+cx+a ?
问题3
产卵数
气温
问题2
如何求a、b ?
合作探究
t=x2
二次函数模型
方案2解答
平方变换:令t=x2,产卵数y和温度x之间二次函数模型y=bx2+a就转化为产卵数y和温度的平方t之间线性回归模型y=bt+a
温度
21
23
25
27
29
32
35
温度的平方t
441
529
625
729
841
1024
1225
产卵数y/个
7
11
21
24
66
115
325
作散点图,并由计算器得:y和t之间的线性回归方程为y=0.367t-202.543,相关指数R2=0.802
将t=x2代入线性回归方程得:
y=0.367x2 -202.543
当x=28时,y=0.367×282-202.54≈85,且R2=0.802,
所以,二次函数模型中温度解
释了80.2%的产卵数变化。
t
问题2
变换 y=bx+a
非线性关系 线性关系
问题1
如何选取指数函数的底
产卵数
气温
指数函数模型
方案3
合作探究
对数
方案3解答
温度xoC
21
23
25
27
29
32
35
z=lny
1.946
2.398
3.045
3.178
4.190
4.745
5.784
产卵数y/个
7
11
21
24
66
115
325
x
z
当x=28oC 时,y ≈44 ,指数回归模型中温度解释了98.5%的产卵数的变化
由计算器得:z关于x的线性回归方程
为
对数变换:在 中两边取常用对数得
令 ,则
就转换为z=bx+a.
相关指数R2=0.98
最好的模型是哪个
产卵数
气温
产卵数
气温
线性模型
二次函数模型
指数函数模型
比一比
函数模型 相关指数R2
线性回归模型 0.7464
二次函数模型 0.80
指数函数模型 0.98
最好的模型是哪个
回归分析(二)
则回归方程的残差计算公式分别为:
由计算可得:
x 21 23 25 27 29 32 35
y 7 11 21 24 66 115 325
0.557 -0.101 1.875 -8.950 9.230 -13.381 34.675
47.696 19.400 -5.832 -41.000 -40.104 -58.265 77.968
因此模型(1)的拟合效果远远优于模型(2)。
下面模型(1)(2)分别是前面的指数和二次函数模型:
总 结
对于给定的样本点
两个含有未知参数的模型:
其中a和b都是未知参数。拟合效果比较的步骤为:
(1)分别建立对应于两个模型的回归方程
与 其中 和 分别是参数a和b的估计值;
(2)分别计算两个回归方程的残差平方和
与
(3)若 则 的效果比
的好;反之, 的效果不如 的好。
练习:为了研究某种细菌随时间x变化,繁殖的个数,收集数据如下:
天数x/天
1
2
3
4
5
6
繁殖个数y/个
6
12
25
49
95
190
(1)用天数作解释变量,繁殖个数作预报变量,作出这些
数据的散点图;
(2) 描述解释变量与预报变量
之间的关系;
(3) 计算残差、相关指数R2.
天数
繁殖个数
解:(1)散点图如右所示
(2)由散点图看出样本点分布在一条指数函数y= 的周围,于是令Z=lny,则
x
1
2
3
4
5
6
Z
1.79
2.48
3.22
3.89
4.55
5.25
由计数器算得 则有
6.06
12.09
24.09
48.04
95.77
190.9
y
6
12
25
49
95
190
(3)
即天数(解释变量)解释了99.99%的繁殖细菌(预报变量)的个数变化。
3.1 回归分析的基本思想
及其初步应用
课标要求:
1.了解残差平方和、相关指数R2的概念.
2.了解回归分析的基本步骤.
3.会用残差平方和与相关指数R2对回归模型拟合度进行评判.
4.了解简单的非线性回归分析方法.
素养达成:
通过残差分析的学习,使学生养成了建模能力、数据分析处理能力等.
问题一:线性回归模型 课本 例题1 练习册P58例1、训练1-1
问题二:线性回归分析:残差图与 练习册P58例2、训练2-1
问题三:非线性回归方程(与回归直线的联系) 课本P87例2 练习册P59例3、训练3-1
温故知新
两个变量的关系
不相关
相关关系
函数关系
线性相关
非线性相关
函数关系中的两个变量间是一种确定性关系。
相关关系是一种非确定性关系。
自变量取值一定时,因变量的取值带有一定随机性的两个变量之间的关系叫做相关关系。
1、定义:
1):相关关系是一种不确定性关系;
注
对具有相关关系的两个变量进行统计分析的方法叫回归分析。
2):
2、现实生活中存在着大量的相关关系。
如:人的身高与年龄;
产品的成本与生产数量;
商品的销售额与广告费;
家庭的支出与收入。等等
负相关
正相关
例1、某大学中随机选取8名女大学生,其身高和体重数据如下表所示.
编号 1 2 3 4 5 6 7 8
身高/cm 165 165 157 170 175 165 155 170
体重/kg 48 57 50 54 64 61 43 59
求根据女大学生的身高预报体重的回归方程,并预报一名身高为172cm的女大学生的体重.
解:1、选取身高为自变量x,体重为因变量y,作散点图:
2、由散点图知道身高和体重有比较好的线性相关关系,因此可以用线性回归方程刻画它们之间的关系。
根据最小二乘法估计 和 就是未知参数a和b的最好估计,
于是有
所以回归方程是
所以,对于身高为172cm的女大学生,由回归方程可以预报其体重为
探究P4:
身高为172cm的女大学生的体重一定是60.316kg吗?如果不是,你能解析一下原因吗?
样本点呈条状分布,身高和体重有较好的线性相关关系,因此可以用回归方程来近似的刻画它们之间的关系.
解:散点图:
3、从散点图还看到,样本点散布在某一条直线的附近,而不是在一条直线上,所以不能用一次函数y=bx+a简单描述它们关系。
我们可以用下面的线性回归模型来表示:
y=bx+a+e,其中a和b为模型的未知参数,
e称为随机误差。
思考P3
产生随机误差项e
的原因是什么?
思考P3
产生随机误差项e的原因是什么?
随机误差e的来源(可以推广到一般):
1、其它因素的影响:影响体重 y 的因素不只是身高 x,可能还包括遗传基因、饮食习惯、生长环境等因素;
2、身高 x的观测误差。
线性回归模型y=bx+a+e增加了随机误差项e,因变量y的值由自变量x和随机误差项e共同确定,即自变量x只能解析部分y的变化。
在统计中,我们也把自变量x称为解析变量,因变量y为预报变量。
残差
数据点和它在回归直线上相应位置的差异 称为相应于点(xi,yi ) 的残差。
例:编号为6的女大学生,计算随机误差的效应(残差)
残差平方和
把每一个残差所得的值平方后加起来,用数学符号表示为:
称为残差平方和
在例1中,残差平方和约为128.361。
表1-4列出了女大学生身高和体重的原始数据以及相应的残差数据。
残差分析与残差图的定义:
我们可以通过残差 来判断模型拟合的效果,
判断原始数据中是否存在可疑数据,
这方面的分析工作称为残差分析。
编号 1 2 3 4 5 6 7 8
身高 165 165 157 170 175 165 155 170
体重/kg 48 57 50 54 64 61 43 59
残差 -6.373 2.627 2.419 -4.618 1.137 6.627 -2.883 0.382
我们可以利用图形来分析残差特性,作图时纵坐标为残差,横坐标可以选为样本编号,或身高数据,或体重估计值等,这样作出的图形称为残差图。
残若模型选择的正确,残差图中的点应该分布在以横轴为心的带形区域;
对于远离横轴的点,要特别注意。
身高与体重残差图
异常点
错误数据
模型问题
几点说明:
第一个样本点和第6个样本点的残差比较大,需要确认在采集过程中是否有人为的错误。如果数据采集有错误,就予以纠正,然后再重新利用线性回归模型拟合数据;如果数据采集没有错误,则需要寻找其他的原因。
另外,残差点比较均匀地落在水平的带状区域中,说明选用的模型计较合适,这样的带状区域的宽度越窄,说明模型拟合精度越高,回归方程的预报精度越高。
我们可以用相关指数R2来刻画回归的效果,其计算公式是
显然,R2的值越大,说明残差平方和越小,也就是说模型拟合效果越好。
R2越接近1,表示回归的效果越好(因为R2越接近1,表示解析变量和预报变量的线性相关性越强)
如果某组数据可能采取几种不同回归方程进行回归分析,则可以通过比较R2的值来做出选择,即选取R2较大的模型作为这组数据的模型。
总的来说:
相关指数R2是度量模型拟合效果的一种指标。
在线性模型中,它代表自变量刻画预报变量的能力。
一般地,建立回归模型的基本步骤为:
(1)确定研究对象,明确哪个变量是解析变量,哪个变量是预报变量。
(2)画出确定好的解析变量和预报变量的散点图,观察它们之间的关系(如是否存在线性关系等)。
(3)由经验确定回归方程的类型(如我们观察到数据呈线性关系,则选用线性回归方程y=bx+a).
(4)按一定规则估计回归方程中的参数(如最小二乘法)。
(5)得出结果后分析残差图是否有异常(个别数据对应残差过大,或残差呈现不随机的规律性,等等),过存在异常,则检查数据是否有误,或模型是否合适等。
例2、在一段时间内,某中商品的价格x元和需求量Y件之间的一组数据为:
求出Y对的回归直线方程,并说明拟合效果的好坏。
价格x 14 16 18 20 22
需求量Y 12 10 7 5 3
解:
例2、在一段时间内,某中商品的价格x元和需求量Y件之间的一组数据为:
求出Y对的回归直线方程,并说明拟合效果的好坏。
价格x 14 16 18 20 22
需求量Y 12 10 7 5 3
列出残差表为
0.994
因而,拟合效果较好。
0
0.3
-0.4
-0.1
0.2
4.6
2.6
-0.4
-2.4
-4.4
相关指数越大,效果越好
残差平方和越小,效果越好
探索无止境
小结
1.残差平方和与模型拟合效果关系:
2.相关指数与模型拟合效果关系
1.2.3循环语句
新课标高二数学 选修2-3
3.1回归分析的基本思想及其初步应用(二)
复习回顾
1、线性回归模型:
y=bx+a+e, (3)
其中a和b为模型的未知参数,e称为随机误差。
y=bx+a+e,
E(e)=0,D(e)= (4)
2、数据点和它在回归直线上相应位置的差异 是随机误差的效应,称 为残差。
3、对每名女大学生计算这个差异,然后分别将所得的值平方后加起来,用数学符号表示为:
称为残差平方和,它代表了随机误差的效应。
4、两个指标:
(1)类比样本方差估计总体方差的思想,可以用作
为 的估计量, 越小,预报精度越高。
(2)我们可以用相关指数R2来刻画回归的效果,其
计算公式是:
R2 1,说明回归方程拟合的越好;R2 0,说明回归方程拟合的越差。
表3-2列出了女大学生身高和体重的原始数据以及相应的残差数据。
在研究两个变量间的关系时,首先要根据散点图来粗略判断它们是否线性相关,是否可以用回归模型来拟合数据。
5、残差分析与残差图的定义:
然后,我们可以通过残差 来判断模型拟合的效果,判断原始数据中是否存在可疑数据,这方面的分析工作称为残差分析。
编号 1 2 3 4 5 6 7 8
身高/cm 165 165 157 170 175 165 155 170
体重/kg 48 57 50 54 64 61 43 59
残差 -6.373 2.627 2.419 -4.618 1.137 6.627 -2.883 0.382
我们可以利用图形来分析残差特性,作图时纵坐标为残差,横坐标可以选为样本编号,或身高数据,或体重估计值等,这样作出的图形称为残差图。
残差图的制作及作用
1、坐标纵轴为残差变量,横轴可以有不同的选择;
2、若模型选择的正确,残差图中的点应该分布在以横轴为心的带形区域;
3、对于远离横轴的点,要特别注意。
身高与体重残差图
异常点
错误数据
模型问题
几点说明:
第一个样本点和第6个样本点的残差比较大,需要确认在采集过程中是否有人为的错误。如果数据采集有错误,就予以纠正,然后再重新利用线性回归模型拟合数据;如果数据采集没有错误,则需要寻找其他的原因。
另外,残差点比较均匀地落在水平的带状区域中,说明选用的模型计较合适,这样的带状区域的宽度越窄,说明模型拟合精度越高,回归方程的预报精度越高。
6、注意回归模型的适用范围:
(1)回归方程只适用于我们所研究的样本的总体。样本数据来自哪个总体的,预报时也仅适用于这个总体。
(2)模型的时效性。利用不同时间段的样本数据建立的模型,只有用来对那段时间范围的数据进行预报。
(3)建立模型时自变量的取值范围决定了预报时模型的适用范围,通常不能超出太多。
(4)在回归模型中,因变量的值不能由自变量的值完全确定。正如前面已经指出的,某个女大学生的身高为172cm,我们不能利用所建立的模型预测她的体重,只能给出身高为172cm的女大学生的平均体重的预测值。
7、一般地,建立回归模型的基本步骤为:
(1)确定研究对象,明确哪个变量是解析变量,哪个变量是预报变量。
(2)画出确定好的解析变量和预报变量的散点图,观察它们之间的关系(如是否存在线性关系等)。
(3)由经验确定回归方程的类型(如我们观察到数据呈线性关系,则选用线性回归方程y=bx+a).
(4)按一定规则估计回归方程中的参数(如最小二乘法)。
(5)得出结果后分析残差图是否有异常(个别数据对应残差过大,或残差呈现不随机的规律性,等等),过存在异常,则检查数据是否有误,或模型是否合适等。
例1 在一段时间内,某中商品的价格x元和需求量Y件之间的一组数据为:
求出Y对的回归直线方程,并说明拟合效果的好坏。
价格x 14 16 18 20 22
需求量Y 12 10 7 5 3
解:
例1 在一段时间内,某中商品的价格x元和需求量Y件之间的一组数据为:
求出Y对的回归直线方程,并说明拟合效果的好坏。
价格x 14 16 18 20 22
需求量Y 12 10 7 5 3
列出残差表为
0.994
因而,拟合效果较好。
0
0.3
-0.4
-0.1
0.2
4.6
2.6
-0.4
-2.4
-4.4
案例2 一只红铃虫的产卵数y和温度x有关。现收集了7组观测数据列于表中:
(1)试建立产卵数y与温度x之间的回归方程;并预测温度为28oC时产卵数目。
(2)你所建立的模型中温度在多大程度上解释了产卵数的变化?
温度xoC
21
23
25
27
29
32
35
产卵数y/个
7
11
21
24
66
115
325
非线性回归问题
假设线性回归方程为 : =bx+a
选 模 型
由计算器得:线性回归方程为y=19.87x-463.73
相关指数R2=r2≈0.8642=0.7464
估计参数
解:选取气温为解释变量x,产卵数
为预报变量y。
选变量
所以,一次函数模型中温度解释了74.64%的产卵数变化。
探索新知
画散点图
0
50
100
150
200
250
300
350
0
3
6
9
12
15
18
21
24
27
30
33
36
39
方案1
分析和预测
当x=28时,y =19.87×28-463.73≈ 93
一元线性模型
奇怪?
93>66
模型不好?
y=bx2+a 变换 y=bt+a
非线性关系 线性关系
方案2
问题1
选用y=bx2+a ,还是y=bx2+cx+a ?
问题3
产卵数
气温
问题2
如何求a、b ?
合作探究
t=x2
二次函数模型
方案2解答
平方变换:令t=x2,产卵数y和温度x之间二次函数模型y=bx2+a就转化为产卵数y和温度的平方t之间线性回归模型y=bt+a
温度
21
23
25
27
29
32
35
温度的平方t
441
529
625
729
841
1024
1225
产卵数y/个
7
11
21
24
66
115
325
作散点图,并由计算器得:y和t之间的线性回归方程为y=0.367t-202.543,相关指数R2=0.802
将t=x2代入线性回归方程得:
y=0.367x2 -202.543
当x=28时,y=0.367×282-202.54≈85,且R2=0.802,
所以,二次函数模型中温度解
释了80.2%的产卵数变化。
t
问题2
变换 y=bx+a
非线性关系 线性关系
问题1
如何选取指数函数的底
产卵数
气温
指数函数模型
方案3
合作探究
对数
方案3解答
温度xoC
21
23
25
27
29
32
35
z=lny
1.946
2.398
3.045
3.178
4.190
4.745
5.784
产卵数y/个
7
11
21
24
66
115
325
x
z
当x=28oC 时,y ≈44 ,指数回归模型中温度解释了98.5%的产卵数的变化
由计算器得:z关于x的线性回归方程
为
对数变换:在 中两边取常用对数得
令 ,则
就转换为z=bx+a.
相关指数R2=0.98
最好的模型是哪个
产卵数
气温
产卵数
气温
线性模型
二次函数模型
指数函数模型
比一比
函数模型 相关指数R2
线性回归模型 0.7464
二次函数模型 0.80
指数函数模型 0.98
最好的模型是哪个
回归分析(二)
则回归方程的残差计算公式分别为:
由计算可得:
x 21 23 25 27 29 32 35
y 7 11 21 24 66 115 325
0.557 -0.101 1.875 -8.950 9.230 -13.381 34.675
47.696 19.400 -5.832 -41.000 -40.104 -58.265 77.968
因此模型(1)的拟合效果远远优于模型(2)。
下面模型(1)(2)分别是前面的指数和二次函数模型:
总 结
对于给定的样本点
两个含有未知参数的模型:
其中a和b都是未知参数。拟合效果比较的步骤为:
(1)分别建立对应于两个模型的回归方程
与 其中 和 分别是参数a和b的估计值;
(2)分别计算两个回归方程的残差平方和
与
(3)若 则 的效果比
的好;反之, 的效果不如 的好。
练习:为了研究某种细菌随时间x变化,繁殖的个数,收集数据如下:
天数x/天
1
2
3
4
5
6
繁殖个数y/个
6
12
25
49
95
190
(1)用天数作解释变量,繁殖个数作预报变量,作出这些
数据的散点图;
(2) 描述解释变量与预报变量
之间的关系;
(3) 计算残差、相关指数R2.
天数
繁殖个数
解:(1)散点图如右所示
(2)由散点图看出样本点分布在一条指数函数y= 的周围,于是令Z=lny,则
x
1
2
3
4
5
6
Z
1.79
2.48
3.22
3.89
4.55
5.25
由计数器算得 则有
6.06
12.09
24.09
48.04
95.77
190.9
y
6
12
25
49
95
190
(3)
即天数(解释变量)解释了99.99%的繁殖细菌(预报变量)的个数变化。