第五章 数据处理和可视化表达——数据采集的基本概念和方法 课件 2022—2023学年粤教版(2019)高中信息技术必修1(13张PPT)
文档属性
| 名称 | 第五章 数据处理和可视化表达——数据采集的基本概念和方法 课件 2022—2023学年粤教版(2019)高中信息技术必修1(13张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 2.3MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 粤教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2023-01-12 00:00:00 | ||
图片预览




文档简介
(共13张PPT)
数据采集的基本概念和方法
数据采集
数据采集的基本概念和方法
数据采集
数据采集,即根据需求采用适当的方法和工具获取所需要的数据。
数据采集的概念
数据采集的概念
数据采集的数据来源十分广泛(主要是来自互联网和物联网),可以从传感器和智能设备、企业在线系统、企业离线系统、社交网络和互联网平台等获取。
常见的数据包括 RFID 数据、传感器数据、用户行为数据、社交网络交互数据及移动互联网数据等各种类型的结构化、半结构化及非结构化的海量数据。
数据采集
数据采集的概念
数据采集的基本步骤
数据采集的概念
可以从需求分析问题、研究内容、期望达成的目标来进行考虑,然后列出需要采集的目标数据目录。
企业系统:客户关系管理系统、企业资源计划系统、库存系统、销售系统等。
机器系统:智能仪表、工业设备传感器、智能设备、视频监控系统等。
互联网系统:电商系统、服务行业业务系统、政府监管系统等。
社交系统:微信、QQ、微博、博客、新闻网站、朋友圈等。
数据库采集
系统日志采集
网络数据采集
感知设备数据采集
数据采集
数据采集的方法
数据采集
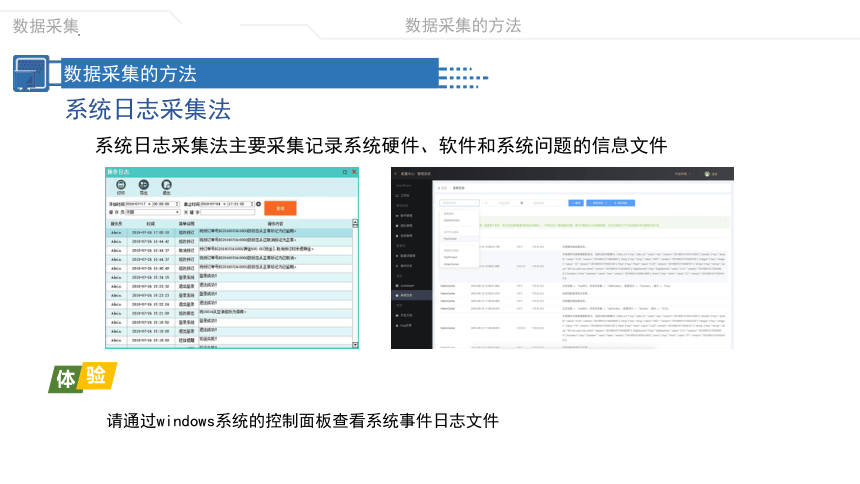
系统日志采集法主要采集记录系统硬件、软件和系统问题的信息文件
数据采集的方法
系统日志采集法
数据采集的方法
体
验
请通过windows系统的控制面板查看系统事件日志文件
数据采集
感知设备数据采集是指通过传感器、摄像头和其他智能终端自动采集信号、图片或录像来获取数据。感知设备数据采集的数据通常是物联网的数据。
数据采集的方法
感知设备数据采集
数据采集的方法
数据采集
传统企业会使用传统的关系型数据库 MySQL 和 Oracle 等来存储数据。随着大数据时代的到来,Redis、MongoDB 和 HBase 等 NoSQL 数据库也常用于数据的采集。企业通过在采集端部署大量数据库,并在这些数据库之间进行负载均衡和分片,来完成大数据采集工作。
数据采集的方法
数据库采集
数据采集的方法
数据采集
网络数据采集是指通过网络爬虫或网站公开 API 等方式从网站上获取数据信息的过程。
数据采集的方法
网络数据采集
数据采集的方法
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
体
验
打开一个你熟悉的网址,在网址后加robots.txt,可以查看本网页是否能被爬取。例如: https://www./robots.txt
数据采集
网络爬虫典型的有百度爬虫Baiduspider,百度就是通过Baiduspider在其它网站采集网站数据(关键字、内容、网址等信息),如何保存到百度的索引数据库中;用户使用百度时其实检索的是百度的索引数据库中的信息。
数据采集的方法
网络数据采集
数据采集的方法
百度spider
用户
其他网站
索引
索引数据库
检索
保存
关键字 主要内容 网址 时间
数据采集
数据采集的方法
网络数据采集
数据采集的方法
观
察
讨
论
观看视频《什么是网络爬虫》
网络数据采集中使用网络爬虫有什么优缺点?
数据采集
网络爬虫的基本工作流程
数据采集的方法
网络数据采集
数据采集的方法
首先选取一部分精心挑选的种子URL(https://movie.douban.com/chart);
将这些URL放入待抓取URL队列;
从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
数据采集
数据采集的方法
网络爬虫的具体案例实践
数据采集的方法
在python环境下运行程序pachong.py,体验网络爬虫自动采集“豆瓣电影排名”的数据的过程。
运行前,你需要在pachong.py同目录下建立以下文件夹:
.\data\excel
.\data\html
需要安装好以下扩展库:numpy库、matplotlib库、pylab库
体
验
数据采集的基本概念和方法
数据采集
数据采集的基本概念和方法
数据采集
数据采集,即根据需求采用适当的方法和工具获取所需要的数据。
数据采集的概念
数据采集的概念
数据采集的数据来源十分广泛(主要是来自互联网和物联网),可以从传感器和智能设备、企业在线系统、企业离线系统、社交网络和互联网平台等获取。
常见的数据包括 RFID 数据、传感器数据、用户行为数据、社交网络交互数据及移动互联网数据等各种类型的结构化、半结构化及非结构化的海量数据。
数据采集
数据采集的概念
数据采集的基本步骤
数据采集的概念
可以从需求分析问题、研究内容、期望达成的目标来进行考虑,然后列出需要采集的目标数据目录。
企业系统:客户关系管理系统、企业资源计划系统、库存系统、销售系统等。
机器系统:智能仪表、工业设备传感器、智能设备、视频监控系统等。
互联网系统:电商系统、服务行业业务系统、政府监管系统等。
社交系统:微信、QQ、微博、博客、新闻网站、朋友圈等。
数据库采集
系统日志采集
网络数据采集
感知设备数据采集
数据采集
数据采集的方法
数据采集
系统日志采集法主要采集记录系统硬件、软件和系统问题的信息文件
数据采集的方法
系统日志采集法
数据采集的方法
体
验
请通过windows系统的控制面板查看系统事件日志文件
数据采集
感知设备数据采集是指通过传感器、摄像头和其他智能终端自动采集信号、图片或录像来获取数据。感知设备数据采集的数据通常是物联网的数据。
数据采集的方法
感知设备数据采集
数据采集的方法
数据采集
传统企业会使用传统的关系型数据库 MySQL 和 Oracle 等来存储数据。随着大数据时代的到来,Redis、MongoDB 和 HBase 等 NoSQL 数据库也常用于数据的采集。企业通过在采集端部署大量数据库,并在这些数据库之间进行负载均衡和分片,来完成大数据采集工作。
数据采集的方法
数据库采集
数据采集的方法
数据采集
网络数据采集是指通过网络爬虫或网站公开 API 等方式从网站上获取数据信息的过程。
数据采集的方法
网络数据采集
数据采集的方法
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
体
验
打开一个你熟悉的网址,在网址后加robots.txt,可以查看本网页是否能被爬取。例如: https://www./robots.txt
数据采集
网络爬虫典型的有百度爬虫Baiduspider,百度就是通过Baiduspider在其它网站采集网站数据(关键字、内容、网址等信息),如何保存到百度的索引数据库中;用户使用百度时其实检索的是百度的索引数据库中的信息。
数据采集的方法
网络数据采集
数据采集的方法
百度spider
用户
其他网站
索引
索引数据库
检索
保存
关键字 主要内容 网址 时间
数据采集
数据采集的方法
网络数据采集
数据采集的方法
观
察
讨
论
观看视频《什么是网络爬虫》
网络数据采集中使用网络爬虫有什么优缺点?
数据采集
网络爬虫的基本工作流程
数据采集的方法
网络数据采集
数据采集的方法
首先选取一部分精心挑选的种子URL(https://movie.douban.com/chart);
将这些URL放入待抓取URL队列;
从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
数据采集
数据采集的方法
网络爬虫的具体案例实践
数据采集的方法
在python环境下运行程序pachong.py,体验网络爬虫自动采集“豆瓣电影排名”的数据的过程。
运行前,你需要在pachong.py同目录下建立以下文件夹:
.\data\excel
.\data\html
需要安装好以下扩展库:numpy库、matplotlib库、pylab库
体
验
同课章节目录
- 第一章 数据与信息
- 项目范例 体验庆祝国庆多媒体作品的数据与信息处理
- 1.1 数据及其特征
- 1.2 数据编码
- 1.3 信息及其特征
- 第二章 知识与数字化学习
- 项目范例 运用数字化工具探究数理知识
- 2.1 知识与智慧
- 2.2 数字化学习与创新
- 第三章 算法基础
- 项目范例 设计从A市到B市耗时最少的旅行路线方案
- 3.1 体验计算机解决问题的过程
- 3.2 算法及其描述
- 3.3 计算机程序与程序设计语言
- 第四章 程序设计基础
- 项目范例 设计购买纪念品的最佳方案
- 4.1 程序设计语言的基础知识
- 4.2 运用顺序结构描述问题求解过程
- 4.3 运用选择结构描述问题求解过程
- 4.4 运用循环结构描述问题求解过程
- 第五章 数据处理和可视化表达
- 项目范例 网络购物平台客户行为数据分析和可视化表达
- 5.1 认识大数据
- 5.2 数据的采集
- 5.3 数据的分析
- 5.4 数据的可视化表达
- 第六章 人工智能及其应用
- 项目范例 剖析空调企业智能客服机器人
- 6.1 认识人工智能
- 6.2 人工智能的应用