5.3 数据的分析 课件 2022—2023学年粤教版(2019)高中信息技术必修1(26张PPT)
文档属性
| 名称 | 5.3 数据的分析 课件 2022—2023学年粤教版(2019)高中信息技术必修1(26张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 1.4MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 粤教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2023-01-12 00:00:00 | ||
图片预览







文档简介
(共26张PPT)
数据的分析
数据的分析
数据分析的概念
数据分析
数据分析的方法
数据分析的概念
数据分析的概念
数据分析是为了获取有价值的信息,使用适当的计算方法与工具对收集来的数据进行处理,提取有用信息,形成结论从而支持决策。
数据分析可以帮助我们:
了解事物的现状
剖析事物的发展历程
预测事物未来走向
数据分析
数据分析的方法
数据分析的作用:了解事物的现状
数据分析的概念
这是一张新冠肺炎疫情当前的数据。
通过对数据的分析,我们可以发现当前我国现有确诊人数较少,疫情控制良好,主要风险来自境外输入。而且境外的疫情数据可以展示出目前全球疫情的严峻现状。
故,数据分析可以帮助我们了解事物的现状。这就是数据分析的第一个作用。
数据分析
数据分析的方法
数据分析的作用:剖析事物的发展历程
数据分析的概念
这是一张我国新冠肺炎疫情的数据图表。通过表中的病死率和治愈率,我们可以通过图中的数据可以帮助我们了解疫情发展和变化的过程。
故,数据分析的第二个作用是了解事物的发展历程,从而进一步探究问题产生的原因。
数据分析
数据分析的方法
数据分析的作用:剖析事物的发展历程
数据分析的概念
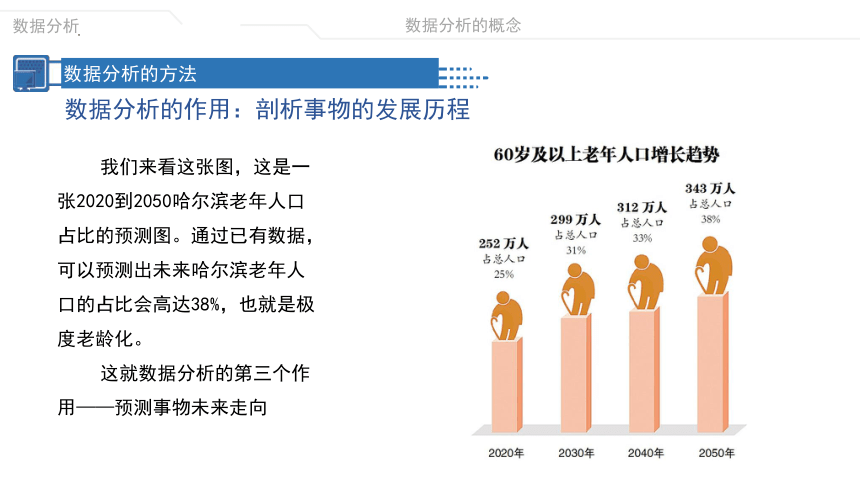
我们来看这张图,这是一张2020到2050哈尔滨老年人口占比的预测图。通过已有数据,可以预测出未来哈尔滨老年人口的占比会高达38%,也就是极度老龄化。
这就数据分析的第三个作用——预测事物未来走向
数据的分析
数据分析方法
数据分析
数据分析的方法
数据预处理(特征探索)
数据分析的方法
数据处理中常遇到数据中存在着错误或异常(偏离期望值)的数据,或者重要的数据属性没有值,数据内涵出现不一致情况(例如,作为关键字的同一学生的学号编码在不同的地方出现不同值)。因此,数据预处理主要包括数据清洗、数据集成、数据转换和数据消减。
数据清洗:指消除数据中存在的噪声及纠正其不一致的错误。
数据集成:指将来自多个数据源的数据合并到一起构成一个完整的数据集。
数据转换:指将一种格式的数据转换为另一种格式的数据。
数据消减:指通过删除冗余特征或聚类消除多余数据。
数据分析往往是80%的数据处理,20%的分析。
数据分析
数据分析的方法
数据预处理:数据清洗
数据分析的方法
数据清洗过程包括遗漏数据处理,数据随机错误处理,以及不一致数据处理,主要通过以下几个方法进行:
对于遗漏数据一般采用忽略该条记录,手工填补遗漏值,利用默认值填、均值、同类别均值填补遗漏值来处理;
对于随机错误,可以取数据点的周围点(近邻)值或者用聚类、回归分析方法取值。
对于不一致的数据,常利用数据与外部的关联,手工解决这种问题。
数据分析
数据分析的方法
数据预处理:数据集成
数据分析的方法
即将来自多个数据源的数据,如数据库、数据立方、普通文件等,结合在一起并形成一个统一数据集合,以便为数据处理工作的顺利完成提供完整的数据基础。
Excel中使用vlookup函数实现多个表的合并,注意合并前需要对多个表的数据进行数据清理。(注意教师演示)
Word中的邮件合并功能将Excel数据填充到Wrod中。(注意教师演示)
体
验
数据分析
数据分析的方法
数据预处理:数据转换
数据分析的方法
指将一种格式的数据转换为另一种格式的数据(如数字类型转换为文本类型),还包括将数据进行转换或归并,从而构成一个适合数据处理的描述形式。
格式转换:如数字类型转换为文本类型。
数据进行转换或归并:可以通过属性构造方法可以利用已有属性集构造出新的属性,如例如,根据宽、高属性,可以构造一个新属性(面积)。
数据分析
数据分析的方法
数据预处理:数据消减
数据分析的方法
数据消减技术的主要目的就是从原有巨大数据集中获得一个精简的数据集,并使这一精简数据集保持原有数据集的完整性。这样在精简数据集上进行数据挖掘就会提高效率,并且能够保证挖掘出来的结果与使用原有数据集所获得的结果基本相同。
数据分析
数据分析的方法
关联分析案例
数据分析的方法
沃尔玛数据仓库里集中了其各门店的详细原始交易数据。在这些原始交易数据的基础上,沃尔玛利用数据挖掘方法对这些数据进行分析和挖掘。一个意外的发现是:“跟尿布一起购买最多的商品竟是啤酒!”经过大量实际调查和分析,揭示了一个隐藏在“尿布与啤酒”背后的一种行为模式:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有 30% ~ 40% 的人同时也为自己买一些啤酒。
产生这一现象的原因是:美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。
数据分析
数据分析的方法
关联分析
数据分析的方法
关联分析又称关联挖掘,在数据挖掘中,有一种算法叫关联规则,关联规则是反映一个事物与其他事物之间的相互依存性、关联性或因果关系,常用于实体商店或在线电商的推荐系统,也常用于系统日志分析、成绩预测分析、学生行为分析等领域。
将上学期期末考试的各科成绩,通过SPSS软件中的相关性分析功能,分析一下各科成绩的相互影响的情况,并汇报。
体
验
观
察
观看视频《关联分析》
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
支持度(Support):支持度是两件商品(A∩B)在总销售笔数(N)中出现的概率,即A与B同时被购买的概率。类似于中学学的交集,需要元素同时满足条件。
置信度(Confidence) :置信度是购买A后再购买B的条件概率。
提升度(Lift):提升度表示先购买A对购买B的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率。如果大于1说明规则有效,小于1则无效。
关联性分析的三个要素:
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
交易号 产品
T01 啤酒
T01 尿布
T02 啤酒
T02 尿布
T03 尿布
项集包含一组产品,上面的示例包含 3 个项集,分别是:{啤酒}、{尿布}、{啤酒,尿布}。
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
计算支持度(Support)
支持表示一个项集出现的次数占总出现次数的比例:
Support({啤酒}) = 2/7=28.5%
Support({尿布}) =3/7=42.8%
Support({啤酒,尿布}) =2/7=28.5%
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
计算置信度( Confidence )
置信度是购买A后再购买B的条件概率:
概率(尿布=>啤酒)
= Support({啤酒,尿布})/Support({尿布})
= 66.7%
概率(啤酒=>尿布)
= Support({啤酒,尿布})/Support({啤酒})
= 100%
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
计算提升度(Lift)
提升度表示先购买A对购买B的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率。如果大于1说明规则有效,小于1则无效。
提升度(啤酒=>尿布)
=Support({啤酒,尿布})/ Support({啤酒}) *Support({尿布})
=28.5%/28.5%*42.8%
=2.33
数据分析
数据分析的方法
聚类分析
数据分析的方法
聚类就是针对大量数据或者样品,根据数据本身的特性研究分类方法,并遵循这个分类方法对数据进行合理的分类,最终将相似数据分为一组,也就是“同类相同、异类相异”。
将上学期期末考试的各科成绩,将成绩设置为三个类别,通过SPSS软件中的“K-均值聚类”分析功能,分析一下你的成绩处在班级中的哪个层次。
体
验
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
设置分类的数量K
K-Mcans聚类法中的K就是分组数,也就是我们希望通过聚类后得到多少个组类。比如我有下面六个数据,想要将这些数据分成两类,那么K=2 。
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
选择数据中心
这个数据中心的选择是完全随机的,也就是说怎么选择都无所谓,因为这里K=2,所以我们就以A和B两个为数据中心。
为了方便理解,我们可以制作一个散点图,将A、B作为数据中心。
题目是普通的二维数据,我们算出其他6个点距离A和B的距离,谁离得更近,谁与数据中心就是同一类。
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
第一次分类:
所以,我们可以看出,C-H距离B的距离都比距离A更近,所以第一次分组为:
第一组:A
第二组:B、C、D、E、F、G、H
得到了第一次分组的结果,我们再重复前两个步骤,重新选择每一组数据的数据中心。
第一组只有A,所以A仍然是数据中心;
第二组有7个数值,将这个7个数值的平均值作为新的数据中心,我们将其命名为P,计算平均坐标为(5.14 ,5.14)
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
还是直接计算勾股定理,计算出其他数据与A和P的欧氏距离,如下:
我们可以看出这里面有的距离A近,有的距离P近,于是第二次分组为:
第一组:A、B
第二组:C、D、E、F、G、H
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
这里就是老规矩了,继续重复前面的操作,将每一组数据的平均值作为数据中心:
第一组有两个值,平均坐标为(0.5 ,1),这是第一个新的数据中心,命名为O
第二组有六个值,平均值为(5.8 , 5.6),这是第二个新的数据中心,命名为Q
这时候我们发现,只有A与B距离O的距离更近,其他6个数据都距离Q更近,因此第三次分组为:
第一组:A、B
第二组:C、D、E、F、G、H
数据分析
数据分析的方法
数据分类
数据分析的方法
数据分类就是制定一定特征和分类要求,对事物进分类。
数据和聚类分析是不一样的,分类是事先设置好分类要求,在要求下分类,而聚类分析不必给出分类要求,让数据样本自动分类。
数据的分析
数据的分析
数据分析的概念
数据分析
数据分析的方法
数据分析的概念
数据分析的概念
数据分析是为了获取有价值的信息,使用适当的计算方法与工具对收集来的数据进行处理,提取有用信息,形成结论从而支持决策。
数据分析可以帮助我们:
了解事物的现状
剖析事物的发展历程
预测事物未来走向
数据分析
数据分析的方法
数据分析的作用:了解事物的现状
数据分析的概念
这是一张新冠肺炎疫情当前的数据。
通过对数据的分析,我们可以发现当前我国现有确诊人数较少,疫情控制良好,主要风险来自境外输入。而且境外的疫情数据可以展示出目前全球疫情的严峻现状。
故,数据分析可以帮助我们了解事物的现状。这就是数据分析的第一个作用。
数据分析
数据分析的方法
数据分析的作用:剖析事物的发展历程
数据分析的概念
这是一张我国新冠肺炎疫情的数据图表。通过表中的病死率和治愈率,我们可以通过图中的数据可以帮助我们了解疫情发展和变化的过程。
故,数据分析的第二个作用是了解事物的发展历程,从而进一步探究问题产生的原因。
数据分析
数据分析的方法
数据分析的作用:剖析事物的发展历程
数据分析的概念
我们来看这张图,这是一张2020到2050哈尔滨老年人口占比的预测图。通过已有数据,可以预测出未来哈尔滨老年人口的占比会高达38%,也就是极度老龄化。
这就数据分析的第三个作用——预测事物未来走向
数据的分析
数据分析方法
数据分析
数据分析的方法
数据预处理(特征探索)
数据分析的方法
数据处理中常遇到数据中存在着错误或异常(偏离期望值)的数据,或者重要的数据属性没有值,数据内涵出现不一致情况(例如,作为关键字的同一学生的学号编码在不同的地方出现不同值)。因此,数据预处理主要包括数据清洗、数据集成、数据转换和数据消减。
数据清洗:指消除数据中存在的噪声及纠正其不一致的错误。
数据集成:指将来自多个数据源的数据合并到一起构成一个完整的数据集。
数据转换:指将一种格式的数据转换为另一种格式的数据。
数据消减:指通过删除冗余特征或聚类消除多余数据。
数据分析往往是80%的数据处理,20%的分析。
数据分析
数据分析的方法
数据预处理:数据清洗
数据分析的方法
数据清洗过程包括遗漏数据处理,数据随机错误处理,以及不一致数据处理,主要通过以下几个方法进行:
对于遗漏数据一般采用忽略该条记录,手工填补遗漏值,利用默认值填、均值、同类别均值填补遗漏值来处理;
对于随机错误,可以取数据点的周围点(近邻)值或者用聚类、回归分析方法取值。
对于不一致的数据,常利用数据与外部的关联,手工解决这种问题。
数据分析
数据分析的方法
数据预处理:数据集成
数据分析的方法
即将来自多个数据源的数据,如数据库、数据立方、普通文件等,结合在一起并形成一个统一数据集合,以便为数据处理工作的顺利完成提供完整的数据基础。
Excel中使用vlookup函数实现多个表的合并,注意合并前需要对多个表的数据进行数据清理。(注意教师演示)
Word中的邮件合并功能将Excel数据填充到Wrod中。(注意教师演示)
体
验
数据分析
数据分析的方法
数据预处理:数据转换
数据分析的方法
指将一种格式的数据转换为另一种格式的数据(如数字类型转换为文本类型),还包括将数据进行转换或归并,从而构成一个适合数据处理的描述形式。
格式转换:如数字类型转换为文本类型。
数据进行转换或归并:可以通过属性构造方法可以利用已有属性集构造出新的属性,如例如,根据宽、高属性,可以构造一个新属性(面积)。
数据分析
数据分析的方法
数据预处理:数据消减
数据分析的方法
数据消减技术的主要目的就是从原有巨大数据集中获得一个精简的数据集,并使这一精简数据集保持原有数据集的完整性。这样在精简数据集上进行数据挖掘就会提高效率,并且能够保证挖掘出来的结果与使用原有数据集所获得的结果基本相同。
数据分析
数据分析的方法
关联分析案例
数据分析的方法
沃尔玛数据仓库里集中了其各门店的详细原始交易数据。在这些原始交易数据的基础上,沃尔玛利用数据挖掘方法对这些数据进行分析和挖掘。一个意外的发现是:“跟尿布一起购买最多的商品竟是啤酒!”经过大量实际调查和分析,揭示了一个隐藏在“尿布与啤酒”背后的一种行为模式:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有 30% ~ 40% 的人同时也为自己买一些啤酒。
产生这一现象的原因是:美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。
数据分析
数据分析的方法
关联分析
数据分析的方法
关联分析又称关联挖掘,在数据挖掘中,有一种算法叫关联规则,关联规则是反映一个事物与其他事物之间的相互依存性、关联性或因果关系,常用于实体商店或在线电商的推荐系统,也常用于系统日志分析、成绩预测分析、学生行为分析等领域。
将上学期期末考试的各科成绩,通过SPSS软件中的相关性分析功能,分析一下各科成绩的相互影响的情况,并汇报。
体
验
观
察
观看视频《关联分析》
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
支持度(Support):支持度是两件商品(A∩B)在总销售笔数(N)中出现的概率,即A与B同时被购买的概率。类似于中学学的交集,需要元素同时满足条件。
置信度(Confidence) :置信度是购买A后再购买B的条件概率。
提升度(Lift):提升度表示先购买A对购买B的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率。如果大于1说明规则有效,小于1则无效。
关联性分析的三个要素:
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
交易号 产品
T01 啤酒
T01 尿布
T02 啤酒
T02 尿布
T03 尿布
项集包含一组产品,上面的示例包含 3 个项集,分别是:{啤酒}、{尿布}、{啤酒,尿布}。
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
计算支持度(Support)
支持表示一个项集出现的次数占总出现次数的比例:
Support({啤酒}) = 2/7=28.5%
Support({尿布}) =3/7=42.8%
Support({啤酒,尿布}) =2/7=28.5%
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
计算置信度( Confidence )
置信度是购买A后再购买B的条件概率:
概率(尿布=>啤酒)
= Support({啤酒,尿布})/Support({尿布})
= 66.7%
概率(啤酒=>尿布)
= Support({啤酒,尿布})/Support({啤酒})
= 100%
数据分析
数据分析的方法
关联分析:实际案例分析(选择讲解)
数据分析的方法
计算提升度(Lift)
提升度表示先购买A对购买B的概率的提升作用,用来判断规则是否有实际价值,即使用规则后商品在购物车中出现的次数是否高于商品单独出现在购物车中的频率。如果大于1说明规则有效,小于1则无效。
提升度(啤酒=>尿布)
=Support({啤酒,尿布})/ Support({啤酒}) *Support({尿布})
=28.5%/28.5%*42.8%
=2.33
数据分析
数据分析的方法
聚类分析
数据分析的方法
聚类就是针对大量数据或者样品,根据数据本身的特性研究分类方法,并遵循这个分类方法对数据进行合理的分类,最终将相似数据分为一组,也就是“同类相同、异类相异”。
将上学期期末考试的各科成绩,将成绩设置为三个类别,通过SPSS软件中的“K-均值聚类”分析功能,分析一下你的成绩处在班级中的哪个层次。
体
验
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
设置分类的数量K
K-Mcans聚类法中的K就是分组数,也就是我们希望通过聚类后得到多少个组类。比如我有下面六个数据,想要将这些数据分成两类,那么K=2 。
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
选择数据中心
这个数据中心的选择是完全随机的,也就是说怎么选择都无所谓,因为这里K=2,所以我们就以A和B两个为数据中心。
为了方便理解,我们可以制作一个散点图,将A、B作为数据中心。
题目是普通的二维数据,我们算出其他6个点距离A和B的距离,谁离得更近,谁与数据中心就是同一类。
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
第一次分类:
所以,我们可以看出,C-H距离B的距离都比距离A更近,所以第一次分组为:
第一组:A
第二组:B、C、D、E、F、G、H
得到了第一次分组的结果,我们再重复前两个步骤,重新选择每一组数据的数据中心。
第一组只有A,所以A仍然是数据中心;
第二组有7个数值,将这个7个数值的平均值作为新的数据中心,我们将其命名为P,计算平均坐标为(5.14 ,5.14)
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
还是直接计算勾股定理,计算出其他数据与A和P的欧氏距离,如下:
我们可以看出这里面有的距离A近,有的距离P近,于是第二次分组为:
第一组:A、B
第二组:C、D、E、F、G、H
数据分析
数据分析的方法
聚类分析实际案例分析(选择讲解)
数据分析的方法
例子: K-Mcans聚类法
这里就是老规矩了,继续重复前面的操作,将每一组数据的平均值作为数据中心:
第一组有两个值,平均坐标为(0.5 ,1),这是第一个新的数据中心,命名为O
第二组有六个值,平均值为(5.8 , 5.6),这是第二个新的数据中心,命名为Q
这时候我们发现,只有A与B距离O的距离更近,其他6个数据都距离Q更近,因此第三次分组为:
第一组:A、B
第二组:C、D、E、F、G、H
数据分析
数据分析的方法
数据分类
数据分析的方法
数据分类就是制定一定特征和分类要求,对事物进分类。
数据和聚类分析是不一样的,分类是事先设置好分类要求,在要求下分类,而聚类分析不必给出分类要求,让数据样本自动分类。
同课章节目录
- 第一章 数据与信息
- 项目范例 体验庆祝国庆多媒体作品的数据与信息处理
- 1.1 数据及其特征
- 1.2 数据编码
- 1.3 信息及其特征
- 第二章 知识与数字化学习
- 项目范例 运用数字化工具探究数理知识
- 2.1 知识与智慧
- 2.2 数字化学习与创新
- 第三章 算法基础
- 项目范例 设计从A市到B市耗时最少的旅行路线方案
- 3.1 体验计算机解决问题的过程
- 3.2 算法及其描述
- 3.3 计算机程序与程序设计语言
- 第四章 程序设计基础
- 项目范例 设计购买纪念品的最佳方案
- 4.1 程序设计语言的基础知识
- 4.2 运用顺序结构描述问题求解过程
- 4.3 运用选择结构描述问题求解过程
- 4.4 运用循环结构描述问题求解过程
- 第五章 数据处理和可视化表达
- 项目范例 网络购物平台客户行为数据分析和可视化表达
- 5.1 认识大数据
- 5.2 数据的采集
- 5.3 数据的分析
- 5.4 数据的可视化表达
- 第六章 人工智能及其应用
- 项目范例 剖析空调企业智能客服机器人
- 6.1 认识人工智能
- 6.2 人工智能的应用