浙教版(2019)信息技术教材一轮复习课件(共32张PPT)——大数据 大数据处理 文本数据处理复习
文档属性
| 名称 | 浙教版(2019)信息技术教材一轮复习课件(共32张PPT)——大数据 大数据处理 文本数据处理复习 |

|
|
| 格式 | pptx | ||
| 文件大小 | 15.9MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2023-01-12 00:00:00 | ||
图片预览










文档简介
(共32张PPT)
大数据处理+文本数据处理复习
处
据
数
理
应
用
与
大数据
一
一、大数据概念及思维
数据体量巨大(Volumme)
速度快(Velocity)
数据类型多(Variety)
价值密度低(Value)
★ 大数据:代表着数据量大、速度快、种类繁多的信息资产,需要特定的技术和分析方法将其转化为价值。
结构化——数据库中数据
非结构化——word、ppt、图片和视频等
半结构化——电子邮件等
大数据要分析的是全体数据,而不是抽样数据。
对于数据不再追求精确性,而是能够接受数据的混杂性。
不一定强调对事物因果关系的探求,而是更加注重它们的相关性。
对比项 采集方法 分析方法 表示方法 ……
大数据
传统数据
采用自动化方法采集数据
采用分布式数据库对数据进行处理
PB(拍字节)以上数量级表示
GB(吉字节)或TB(太字节)表示
采用手工方法采集数据
大多采用关系型数据库和并行数据仓库即可处理
大数据:认识全面、信息详尽
传统数据:样本随机、结论不准
大数据:关注关联,较为准确
传统数据:样本少、局限多
传统数据:容错低、数据量小
大数据:容错强、弱化个体样本的影响
二、大数据与传统数据的区别
三、大数据对社会生活的影响
1. 大数据让生活更便利——热力图,导航路况
2. 大数据让决策更精准——政府、教育、经济、卫生等等领域
3. 大数据带来新的就业需求——系统研发工程师、数据分析师等
4. 大数据带来新的社会问题——信息泄露、数据安全、个人隐私、伦理
★ 下列关于大数据思维的描述,错误的是( )
A. 大数据时代,人们可以采集全体数据进行分析,避免样本不同导致结论不同
B.基于大数据技术,我们能够接受数据的混杂性,个别数据的不准确不影响数据分析
C.数据总量变大会导致大量不相干的数据增加,大数据具有价值密度低的特点
D.使用大数据思维,我们更强调事物因果关系的探求,而不仅仅是数据之间的相关性
课堂练习
D
★ 下列数据中属于大数据的是( )
①各地交通摄像头记录的全部数据②学生网上高考报名数据③电商平台的用户浏览、交易时产生的数据④全体手机用户的联网信息、实时定位数据
A.①②③ B.①②④ C.①③④ D.②③④
C
★ 当人们在社交平台上表达自己对股票市场的情绪或观点时,美国华尔街的炒股高手们却正在利用大数据技术分析人们的想法,先人一步预判市场走势,而且取得了不俗的收益。关于这一实例,下列说法不正确的是( )
A.人们在上网获取数据的同时,本身也在产生数据
B.每个人在社交平台中发布的观点等数据都蕴含着巨大的价值
C.用户在网络中浏览信息、发表观点搜索信息时都有可能泄露个人隐私
D.很多社交软件都是依据采集到的个人用户的网络行为进行“个性化推荐”
课堂练习
B
大数据处理
二
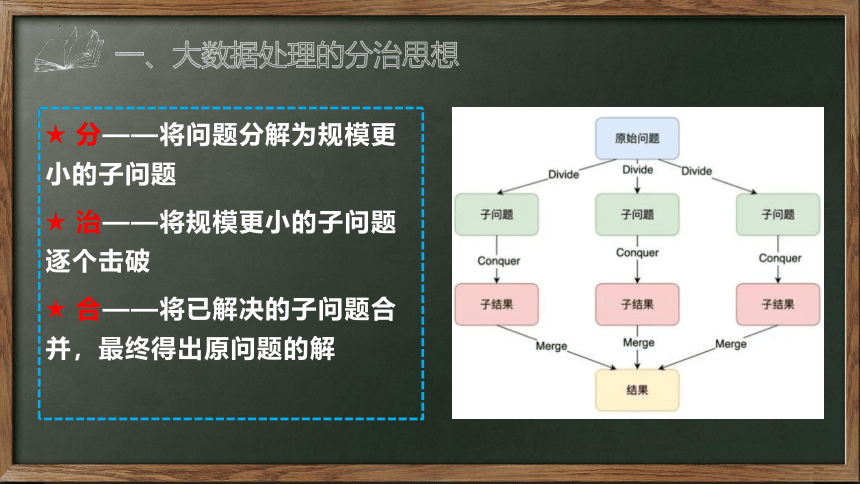
★ 分——将问题分解为规模更小的子问题
★ 治——将规模更小的子问题逐个击破
★ 合——将已解决的子问题合并,最终得出原问题的解
一、大数据处理的分治思想
大数据处理
静态数据
流数据
图数据
批处理计算(Hadoop、spark等)
流计算(storm、heron等)
图计算(pregel、graphx等)
二、大数据处理分类
★静态数据:在处理时已收集完成、在计算式不会发生改变的数据
★流数据:是指不间断地、持续地到达的实时数据,随着时间的流逝,流数据的价值也随之降低,通过实时分析计算可以得到更有价值的分析的结果
★图数据:以社交网络、道路交通等数据为例的众多以图为数据呈现形式的数据,或者转化为图之后再进行分析的
Hadoop是一个运行于计算机集群上的分布式系统基础架构,适用于静态数据的批处理计算。
Spark是一种与hadoop相似的,应用较广的开源分布式计算架构。Spark启用了内存存储中间结果,运行速度比hadoop快。
三、大数据处理分类——批处理计算
三、大数据处理分类——Hadoop的组成
HDFS是一个高度容错性的系统,不需要运行在昂贵并且高可靠的硬件上。
比如:云盘、网盘的底层一般采用HDFS实现
Hbase是一个高可靠,高性能,可伸缩,分布式的列式数据库,是谷歌BigTable数据库的开源实现。采用基于列的存储方式,主要用来存储非结构化或半结构化数据。
三、大数据处理分类——分布式并行计算模型MapReduce
MapReduce主要用于处理大规模数据集的并行运算,由Map(映射)和Reduce(归纳)两部分组成。
它的核心思想就是将任务分解并发到多个节点上进行处理,最后汇总输出。
四、大数据处理整合
2014年9月,Twitter大数据处理系统summingbird开源新工具,它实现了批处理和流计算的整合(Hadoop+storm)。
平台的整合缩短了批处理与流处理之间的切换延时时间,有利于减少系统的开销,降低使用成本。
课堂练习
★ 下列关于Hadoop架构的描述正确的是( )
A.是一个对大数据进行聚合式处理的基础软件框架
B.不能运行于大规模计算机集群上
C.采用NTFS文件系统管理数据文件
D.采用MapReduce编程模型处理大规模数据集
D
★ 下列软件主要用于进行流计算的有( )
A.Hadoop B.Storm
C.Pregel D.Spark
B
课堂练习
★ 下列关于流数据的描述不正确的是( )
A.数据在处理时已经采集完成
B.数据价值随着时间的流逝降低
C.实时分析流数据可以得到更有价值的结果
D.可以采用流计算进行实时分析
A
课堂练习
★ 下列关于大数据的说法,正确的是( )
A.大数据包括静态数据、流数据两种类型
B.大数据蕴含着巨大的价值,但其价值密度较低
C.分布式数据库 HBase 主要用来存储结构化数据
D.大数据给生活带来便利,也让用户的个人隐私受到更好的保护
B
课堂练习
★ 下列应用的数据属于图计算处理的是( )
A.某传染病的传播路径
B.高速公路每时每刻的车流量
C.购物网站的广告推荐
D.已经搜集的某商品的月成交额
A
★ 下列选项中,哪个不是大数据的典型应用( )
A.基于交易大数据分析用户的购买习惯
B.基于搜索引擎的搜索关键词分析社会热点
C.基于道路摄像头、地感线圈等数据分析城市交通情况
D.基于科技文献数据库检索某一领域研究进展
D
文本处理
三
为富不仁的老财主请教书先生为酒店写对联。
问题提出
一、文本数据处理指什么?
实现任何程度或者级别的人工智能所必需的最大突破之一就是拥有可以处理文本数据的机器。值得庆幸的是,全世界文本数据的数量在最近几年已经实现指数级增长。这也迫切需要人们从文本数据中挖掘新知识、新观点。从社交媒体分析到风险管理和网络犯罪保护,处理文本数据已经变得前所未有的重要。
简书文章:https://www./p/37e529c8baa9
文本数据处理是大数据处理的重要分支之一,目的是从大规模的文本数据中提取出符合需要的、感兴趣的和隐藏的信息。目前,文本数据处理主要应用在搜索引擎、情报分析、自动摘要、自动校对、论文查重、文本分类、垃圾邮件过滤、机器翻译、自动应答等方面。
二、文本数据处理的一般过程
据资料表明,非结构化文本数据占文本数据总量的80%以上,而计算机只认识“符号语言”,并不能直接处理非结构化形式的“自然语言”。
非结构化数据
结构化数据
分词
数据分析
文本数据源
特征提取
结果呈现
三、文本数据处理——分词
(1)基于词典的分词方法,也称作基于字符匹配的分词方法,即在分析句子时与词典中的词语进行对比,词典中出现的就划分为词。例如:Python中文分词模块jieba。
import jieba
data=“今天是2035年1月1日,星期一,天气晴朗!"
jg=jieba.cut(data,cut_all=False)
jg="/".join(jg) #结果显示
print(jg)
1. jg = jieba.cut(待分词对象,cut_all=True), 全模式
2. jg = jieba.cut(待分词对象,cut_all=False), 精确模式
3. jg = jieba.cut_for_search(待分词对象), 搜索引擎模式
三、文本数据处理——分词
(2)基于统计的分词方法,统计分词的思想是依据上下文中相邻字出现的频率统计,同时出现的次数越高就越可能组成一个词。在实际应用中,一般是将其与基于词典的分词方法结合使用。
(3)基于规则的分词方法,通过让计算机模拟人的理解方式,根据大量的现有资料和规则进行学习,达到对文字进行分词的效果。由于中文语言知识的笼统性、复杂性,这种分词方法目前还处于试验阶段。
名称 简介
Jieba分词 Python开源项目
IKAnalyzer Java开源分词工具包
NLPIR 北京理工大学大数据搜索与挖掘实验室,非商业应用免费
语言云 哈尔滨工业大学社会计算与信息检索研究中心,在线API接口调用
BosonNLP 玻森中文语义开放平台,在线API接口或库调用
四、文本数据处理——特征提取
※ 特征词:
在中文文本分析中可以采用字、词或短语作为表示文本的特征项。目前,大多数中文文本分析中都采用词作为特征项,这种词称作特征词。
※ 特征提取:
通常可直接用分词算法和词频统计得出的结果作为特征词。通过特征提取来找出最具代表性、最有效的文本特征,从而减少特征词的数量,提高文本处理的速度和效率。
※ 特征提取方式:
特征提取一般采用的方式为根据专家的知识挑选有价值的特征,或者用数学建模的方法构造评估函数自动选取特征等。目前大多采用评估函数进行特征提取的方式,评估函数大多是基于概率统计设计的,这就需要用庞大的训练数据集才能获得对分类起关键作用的特征。随着深度学习、大数据分析等技术的发展,文本特征提取将更加准确、科学。
五、文本数据处理——分析与应用
(1)标签云(文本可视化的一种方式)标签云用词频表现文本特征,将关键词按照一定的顺序和规律排列,如频度递减、字母顺序等,并以文字大小的形式代表词语的重要性,如图所示标签云广泛应用于报纸、杂志等传统媒体和互联网。
五、文本数据处理——分析与应用
(2)文本情感分析,指通过计算机技术对文本的主观性、观点、情绪、极性进行挖掘和分析,对文本的情感倾向做出分类判断。文本情感分析作为一个多学科交叉的研究领域,涉及自然语言处理、信息检索、机器学习、人工智能等领域。
文本情感分析根据分析的粒度不同,分为词语级、语句级、整篇文章级三类。词语级是在分词的基础上,根据情感词典进行特征提取与分类,再分别给特征词赋予权重进行统计分析。特征词的权重,例如,满意+5;差-5等。
文本情感分析主要应用于网络舆情监控、用户评论分析与决策、信息预测等众多领域。
1.文本数据处理的主要步骤包括:
①数据分析 ②特征提取 ③分词 ④结果呈现 ⑤文本数据获取
下列文本数据处理顺序正确的是( )
A.①⑤②③④ B.②⑤③①④
C.⑤①③②④ D.⑤③②①④
2. 下列关于中文分词方法的描述中,属于基于词典的分词方法的是( )
A.在分析句子时与词典中的词语进行对比,词典中出现的就划分为词
B.依据上下文中相邻字出现的频率统计,同时出现的次数越高就越可能组成一个词
C.让计算机模拟人的理解方式,根据大量的现有资料和规则进行学习,然后分词
D.依据词语与词语之间的空格进行分词
D
A
课堂练习
3. 在中文文本分析中,一般不用做文本的特征项的是( )
A.字 B.词 C.短语 D.段落
4. 下列数据分析中可能涉及文本情感分析的是( )
A.博主地域分析 B.微博评论内容分析
C.微博发布设备分析 D.博主男女比例分析
D
B
课堂练习
5.某文本数据集的标签云如图所示,下列说法正确的是( )
A.对数据集中文本分词后可直接创建标签云,无须特征提取
B.标签云须显示该数据集包含的全部词语
C.该数据集中,词语“玩偶”比“注意力”的出现频率高
D.最能表现该数据集中文本特征的词有“车顶”“玩偶”“路口”
C
课堂练习
观
谢
谢
看
大数据处理+文本数据处理复习
处
据
数
理
应
用
与
大数据
一
一、大数据概念及思维
数据体量巨大(Volumme)
速度快(Velocity)
数据类型多(Variety)
价值密度低(Value)
★ 大数据:代表着数据量大、速度快、种类繁多的信息资产,需要特定的技术和分析方法将其转化为价值。
结构化——数据库中数据
非结构化——word、ppt、图片和视频等
半结构化——电子邮件等
大数据要分析的是全体数据,而不是抽样数据。
对于数据不再追求精确性,而是能够接受数据的混杂性。
不一定强调对事物因果关系的探求,而是更加注重它们的相关性。
对比项 采集方法 分析方法 表示方法 ……
大数据
传统数据
采用自动化方法采集数据
采用分布式数据库对数据进行处理
PB(拍字节)以上数量级表示
GB(吉字节)或TB(太字节)表示
采用手工方法采集数据
大多采用关系型数据库和并行数据仓库即可处理
大数据:认识全面、信息详尽
传统数据:样本随机、结论不准
大数据:关注关联,较为准确
传统数据:样本少、局限多
传统数据:容错低、数据量小
大数据:容错强、弱化个体样本的影响
二、大数据与传统数据的区别
三、大数据对社会生活的影响
1. 大数据让生活更便利——热力图,导航路况
2. 大数据让决策更精准——政府、教育、经济、卫生等等领域
3. 大数据带来新的就业需求——系统研发工程师、数据分析师等
4. 大数据带来新的社会问题——信息泄露、数据安全、个人隐私、伦理
★ 下列关于大数据思维的描述,错误的是( )
A. 大数据时代,人们可以采集全体数据进行分析,避免样本不同导致结论不同
B.基于大数据技术,我们能够接受数据的混杂性,个别数据的不准确不影响数据分析
C.数据总量变大会导致大量不相干的数据增加,大数据具有价值密度低的特点
D.使用大数据思维,我们更强调事物因果关系的探求,而不仅仅是数据之间的相关性
课堂练习
D
★ 下列数据中属于大数据的是( )
①各地交通摄像头记录的全部数据②学生网上高考报名数据③电商平台的用户浏览、交易时产生的数据④全体手机用户的联网信息、实时定位数据
A.①②③ B.①②④ C.①③④ D.②③④
C
★ 当人们在社交平台上表达自己对股票市场的情绪或观点时,美国华尔街的炒股高手们却正在利用大数据技术分析人们的想法,先人一步预判市场走势,而且取得了不俗的收益。关于这一实例,下列说法不正确的是( )
A.人们在上网获取数据的同时,本身也在产生数据
B.每个人在社交平台中发布的观点等数据都蕴含着巨大的价值
C.用户在网络中浏览信息、发表观点搜索信息时都有可能泄露个人隐私
D.很多社交软件都是依据采集到的个人用户的网络行为进行“个性化推荐”
课堂练习
B
大数据处理
二
★ 分——将问题分解为规模更小的子问题
★ 治——将规模更小的子问题逐个击破
★ 合——将已解决的子问题合并,最终得出原问题的解
一、大数据处理的分治思想
大数据处理
静态数据
流数据
图数据
批处理计算(Hadoop、spark等)
流计算(storm、heron等)
图计算(pregel、graphx等)
二、大数据处理分类
★静态数据:在处理时已收集完成、在计算式不会发生改变的数据
★流数据:是指不间断地、持续地到达的实时数据,随着时间的流逝,流数据的价值也随之降低,通过实时分析计算可以得到更有价值的分析的结果
★图数据:以社交网络、道路交通等数据为例的众多以图为数据呈现形式的数据,或者转化为图之后再进行分析的
Hadoop是一个运行于计算机集群上的分布式系统基础架构,适用于静态数据的批处理计算。
Spark是一种与hadoop相似的,应用较广的开源分布式计算架构。Spark启用了内存存储中间结果,运行速度比hadoop快。
三、大数据处理分类——批处理计算
三、大数据处理分类——Hadoop的组成
HDFS是一个高度容错性的系统,不需要运行在昂贵并且高可靠的硬件上。
比如:云盘、网盘的底层一般采用HDFS实现
Hbase是一个高可靠,高性能,可伸缩,分布式的列式数据库,是谷歌BigTable数据库的开源实现。采用基于列的存储方式,主要用来存储非结构化或半结构化数据。
三、大数据处理分类——分布式并行计算模型MapReduce
MapReduce主要用于处理大规模数据集的并行运算,由Map(映射)和Reduce(归纳)两部分组成。
它的核心思想就是将任务分解并发到多个节点上进行处理,最后汇总输出。
四、大数据处理整合
2014年9月,Twitter大数据处理系统summingbird开源新工具,它实现了批处理和流计算的整合(Hadoop+storm)。
平台的整合缩短了批处理与流处理之间的切换延时时间,有利于减少系统的开销,降低使用成本。
课堂练习
★ 下列关于Hadoop架构的描述正确的是( )
A.是一个对大数据进行聚合式处理的基础软件框架
B.不能运行于大规模计算机集群上
C.采用NTFS文件系统管理数据文件
D.采用MapReduce编程模型处理大规模数据集
D
★ 下列软件主要用于进行流计算的有( )
A.Hadoop B.Storm
C.Pregel D.Spark
B
课堂练习
★ 下列关于流数据的描述不正确的是( )
A.数据在处理时已经采集完成
B.数据价值随着时间的流逝降低
C.实时分析流数据可以得到更有价值的结果
D.可以采用流计算进行实时分析
A
课堂练习
★ 下列关于大数据的说法,正确的是( )
A.大数据包括静态数据、流数据两种类型
B.大数据蕴含着巨大的价值,但其价值密度较低
C.分布式数据库 HBase 主要用来存储结构化数据
D.大数据给生活带来便利,也让用户的个人隐私受到更好的保护
B
课堂练习
★ 下列应用的数据属于图计算处理的是( )
A.某传染病的传播路径
B.高速公路每时每刻的车流量
C.购物网站的广告推荐
D.已经搜集的某商品的月成交额
A
★ 下列选项中,哪个不是大数据的典型应用( )
A.基于交易大数据分析用户的购买习惯
B.基于搜索引擎的搜索关键词分析社会热点
C.基于道路摄像头、地感线圈等数据分析城市交通情况
D.基于科技文献数据库检索某一领域研究进展
D
文本处理
三
为富不仁的老财主请教书先生为酒店写对联。
问题提出
一、文本数据处理指什么?
实现任何程度或者级别的人工智能所必需的最大突破之一就是拥有可以处理文本数据的机器。值得庆幸的是,全世界文本数据的数量在最近几年已经实现指数级增长。这也迫切需要人们从文本数据中挖掘新知识、新观点。从社交媒体分析到风险管理和网络犯罪保护,处理文本数据已经变得前所未有的重要。
简书文章:https://www./p/37e529c8baa9
文本数据处理是大数据处理的重要分支之一,目的是从大规模的文本数据中提取出符合需要的、感兴趣的和隐藏的信息。目前,文本数据处理主要应用在搜索引擎、情报分析、自动摘要、自动校对、论文查重、文本分类、垃圾邮件过滤、机器翻译、自动应答等方面。
二、文本数据处理的一般过程
据资料表明,非结构化文本数据占文本数据总量的80%以上,而计算机只认识“符号语言”,并不能直接处理非结构化形式的“自然语言”。
非结构化数据
结构化数据
分词
数据分析
文本数据源
特征提取
结果呈现
三、文本数据处理——分词
(1)基于词典的分词方法,也称作基于字符匹配的分词方法,即在分析句子时与词典中的词语进行对比,词典中出现的就划分为词。例如:Python中文分词模块jieba。
import jieba
data=“今天是2035年1月1日,星期一,天气晴朗!"
jg=jieba.cut(data,cut_all=False)
jg="/".join(jg) #结果显示
print(jg)
1. jg = jieba.cut(待分词对象,cut_all=True), 全模式
2. jg = jieba.cut(待分词对象,cut_all=False), 精确模式
3. jg = jieba.cut_for_search(待分词对象), 搜索引擎模式
三、文本数据处理——分词
(2)基于统计的分词方法,统计分词的思想是依据上下文中相邻字出现的频率统计,同时出现的次数越高就越可能组成一个词。在实际应用中,一般是将其与基于词典的分词方法结合使用。
(3)基于规则的分词方法,通过让计算机模拟人的理解方式,根据大量的现有资料和规则进行学习,达到对文字进行分词的效果。由于中文语言知识的笼统性、复杂性,这种分词方法目前还处于试验阶段。
名称 简介
Jieba分词 Python开源项目
IKAnalyzer Java开源分词工具包
NLPIR 北京理工大学大数据搜索与挖掘实验室,非商业应用免费
语言云 哈尔滨工业大学社会计算与信息检索研究中心,在线API接口调用
BosonNLP 玻森中文语义开放平台,在线API接口或库调用
四、文本数据处理——特征提取
※ 特征词:
在中文文本分析中可以采用字、词或短语作为表示文本的特征项。目前,大多数中文文本分析中都采用词作为特征项,这种词称作特征词。
※ 特征提取:
通常可直接用分词算法和词频统计得出的结果作为特征词。通过特征提取来找出最具代表性、最有效的文本特征,从而减少特征词的数量,提高文本处理的速度和效率。
※ 特征提取方式:
特征提取一般采用的方式为根据专家的知识挑选有价值的特征,或者用数学建模的方法构造评估函数自动选取特征等。目前大多采用评估函数进行特征提取的方式,评估函数大多是基于概率统计设计的,这就需要用庞大的训练数据集才能获得对分类起关键作用的特征。随着深度学习、大数据分析等技术的发展,文本特征提取将更加准确、科学。
五、文本数据处理——分析与应用
(1)标签云(文本可视化的一种方式)标签云用词频表现文本特征,将关键词按照一定的顺序和规律排列,如频度递减、字母顺序等,并以文字大小的形式代表词语的重要性,如图所示标签云广泛应用于报纸、杂志等传统媒体和互联网。
五、文本数据处理——分析与应用
(2)文本情感分析,指通过计算机技术对文本的主观性、观点、情绪、极性进行挖掘和分析,对文本的情感倾向做出分类判断。文本情感分析作为一个多学科交叉的研究领域,涉及自然语言处理、信息检索、机器学习、人工智能等领域。
文本情感分析根据分析的粒度不同,分为词语级、语句级、整篇文章级三类。词语级是在分词的基础上,根据情感词典进行特征提取与分类,再分别给特征词赋予权重进行统计分析。特征词的权重,例如,满意+5;差-5等。
文本情感分析主要应用于网络舆情监控、用户评论分析与决策、信息预测等众多领域。
1.文本数据处理的主要步骤包括:
①数据分析 ②特征提取 ③分词 ④结果呈现 ⑤文本数据获取
下列文本数据处理顺序正确的是( )
A.①⑤②③④ B.②⑤③①④
C.⑤①③②④ D.⑤③②①④
2. 下列关于中文分词方法的描述中,属于基于词典的分词方法的是( )
A.在分析句子时与词典中的词语进行对比,词典中出现的就划分为词
B.依据上下文中相邻字出现的频率统计,同时出现的次数越高就越可能组成一个词
C.让计算机模拟人的理解方式,根据大量的现有资料和规则进行学习,然后分词
D.依据词语与词语之间的空格进行分词
D
A
课堂练习
3. 在中文文本分析中,一般不用做文本的特征项的是( )
A.字 B.词 C.短语 D.段落
4. 下列数据分析中可能涉及文本情感分析的是( )
A.博主地域分析 B.微博评论内容分析
C.微博发布设备分析 D.博主男女比例分析
D
B
课堂练习
5.某文本数据集的标签云如图所示,下列说法正确的是( )
A.对数据集中文本分词后可直接创建标签云,无须特征提取
B.标签云须显示该数据集包含的全部词语
C.该数据集中,词语“玩偶”比“注意力”的出现频率高
D.最能表现该数据集中文本特征的词有“车顶”“玩偶”“路口”
C
课堂练习
观
谢
谢
看
同课章节目录