3.2 数据采集与整理 课件(共36张PPT)2022—2023学年人教_中图版(2019)高中信息技术必修1
文档属性
| 名称 | 3.2 数据采集与整理 课件(共36张PPT)2022—2023学年人教_中图版(2019)高中信息技术必修1 |

|
|
| 格式 | pptx | ||
| 文件大小 | 3.3MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 人教中图版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2023-03-06 00:00:00 | ||
图片预览









文档简介
(共36张PPT)
3.2 数据采集与整理
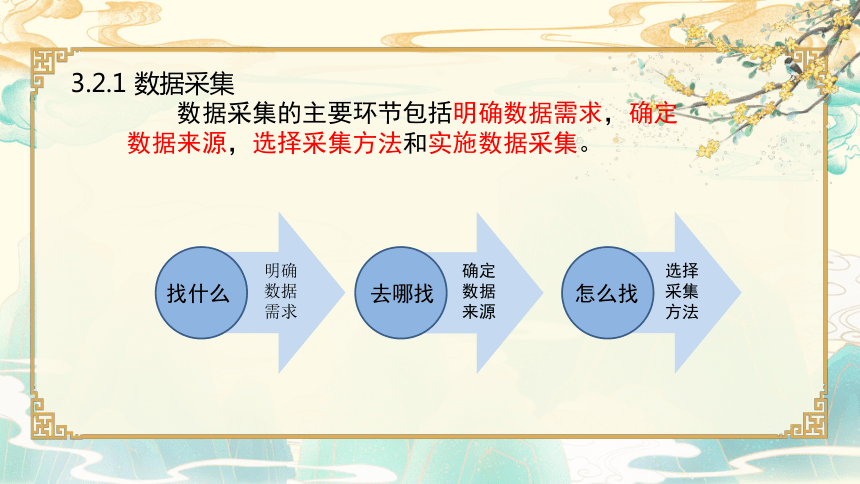
3.2.1 数据采集
数据采集,即根据需求采用适当的方法和工具获取所需要的数据。
3.2.1 数据采集
数据采集的主要环节包括明确数据需求,确定数据来源,选择采集方法和实施数据采集。
找什么 去哪找 怎么找
明确数据需求
确定数据来源
选择采集方法
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
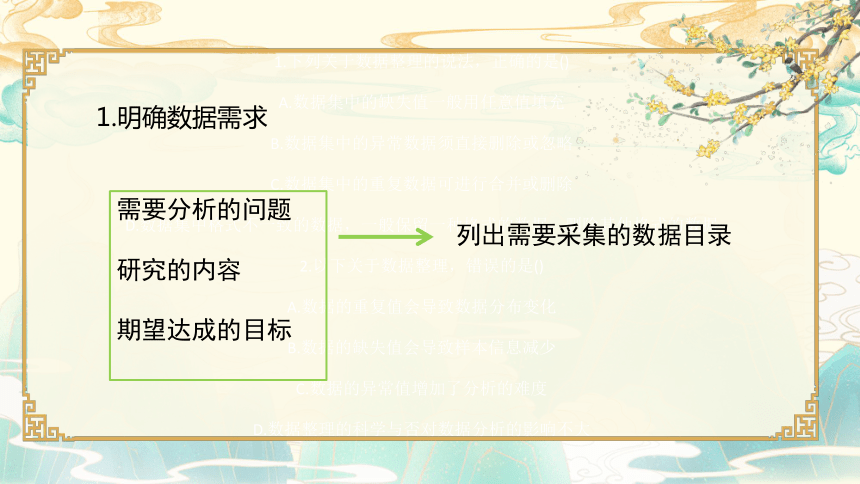
1.明确数据需求
需要分析的问题
研究的内容
期望达成的目标
列出需要采集的数据目录
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
2.确定数据来源
社会调查
公众媒体
科学实验
实践活动
官网平台
物联网
社交网络
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
(1)传感器采集数据
传感器是一种检测装置,能感受到被测量的信息,并能将信息按一定规律转换成电信号或其他所需形式的信息输出。
常见的传感器:温度传感器、压力传感器、红外传感器、距离传感器、声音传感器。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
(2)网络获取数据
利用互联网搜索引擎技术实现有针对性、行业性的数据抓取,并按照一定规则和筛选标准进行数据归类,最终形成数据库文件。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
①网络获取数据的方式
a.网络爬虫
网络爬虫,是按照一定的规则,自动抓取互联网内容的程序。
网络爬虫的主要功能是自动采集其可以访问到的网页内容。
搜索引擎是一种能为用户提供检索服务,并将检索结果呈现给用户的系统。网络爬虫是搜索引擎的重要部分。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
①网络获取数据的方式
b.在线问卷
通过在线调查问卷网站完成问卷的设计、发放、回收和分析等工作。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
②实现互联网数据采集流程的三个步骤:
a.获取网页
获取网页的工作主要是获取网页的源代码。获取源代码的关键就是构造一个请求并发送给服务器,然后在接收到服务器的响应后将其解析出来。
Python中提供了许多库来帮助我们实现这个操作,如urllib、Request等。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
②实现互联网数据采集流程的三个步骤:
b.解析网页
可以利用一些用于提取网页信息的库(如Beatiful Soup、PyQuery、lxml等),高效快速地提取网页信息。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
②实现互联网数据采集流程的三个步骤:
c.保存数据
提取数据后,我们一般会将其保存,以便后续使用。保存的形式多种多样,如文件存储、数据库存储或网络存储等。
3.2.2 数据整理
1.意义:
数据整理的目的是对数据进行校验和标准化。
整理过程的是否科学、结果能否真实地反映客观实际,将直接影响数据处理的质量,影响整个数据分析的准确性。
3.2.2 数据整理
在Python中,pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
使用下面格式约定,引入pandas包:
import pandas as pd
pandas有两个主要数据结构:Series和DataFrame。
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
Series的创建
pd.Series(list,index=[ ]),第二个参数是Series中数据的索引,可以省略。
见99页
3.2.2 数据整理
DataFrame
DataFrame是一个表格型的数据类型,每列值类型可以不同,是最常用的pandas对象。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
DataFrame的创建
pd.DataFrame(data,columns = [ ],index = [ ]):
columns和index为指定的列、行索引,并按照顺序排列。
3.2.2 数据整理
使用pandas做数据处理的第一步就是读取数据,数据源可以来自于各种地方,csv文件便是其中之一。而读取csv文件,pandas也提供了非常强力的支持,参数有四五十个。这些参数中,有的很容易被忽略,但是在实际工作中却用处很大。比如:
文件读取时设置某些列为时间类型
导入文件, 含有重复列
过滤某些列
每次迭代指定的行数
值替换
utf-8编码包含全世界所有国家需要用的字符,它比较灵活,长度在1-6个字节,utf-8编码格式很强大,支持所有国家的语言,正是因为它的强大,才会导致它占用的空间大小要比gbk大,对于网站打开速度而言,也是有一定影响的。
gbk编码主要用中文编码,包含全部中文字符,gbk的长度为2个字节,所以和gbk相比,utf-8会占用更多的数据库储存空间。对于gbk编码格式,虽然它的功能少,仅限于中文字符,但它所占用的空间大小会随着它的功能而减少,打开网页的速度比较快。
3.2.2 数据整理
pandas.read_csv 读取CSV文件
pandas.DataFrame.to_csv 导出数据到CSV文件
pandas. DataFrame.colums 描述DataFrame列
pandas. DataFrame.loc 通过行与列标签选择一个值
pandas. DataFrame.shape 返回DataFrame的行数和列数
pandas. DataFrame.drop_duplicates 删除重复的数据
3.2.2 数据整理
2.数据整理的内容:
(1)检测与处理重复值
记录重复:某几条记录的一个或多个特征值完全相同。
特征重复:存在一个或者多个特征名称不同,但数据完全相同的情况。
处理办法:对重复数据进行处理前,需要分析重复数据产生的原因以及去除这部分数据后可能造成的不良影响。
Python的数据分析核心库Pandas提供了一个名为drop_duplicates()的去重方法。
3.2.2 数据整理
2.数据整理的内容:
(2)检测与处理缺失值
缺失值是指数据中的某个或多个特征的值是不完整的。
处理方法:
删除法是常用的缺失值处理方法,它通过减少样本量来换取信息完整度,是一种较简单的缺失值处理方法。
Pandas库提供了识别缺失值的方法isnull()和识别非缺失值的方法notnull()以及简便的删除缺失值的方法dropna()。
3.2.2 数据整理
2.数据整理的内容:
(3)检测与处理异常值
异常值是指数据中个别值的数值明显偏离其余的数值。有时候也称为离群点。检测异常值就是检验数据中是否有输入错误以及是否含有不合理的数据。
处理方法:
直接将含有异常值的记录删除。用前后两个观测值的平均值修正该异常值;将异常值视为缺失值,利用处理缺失值的方法进行处理。
3.2.2 数据整理
2.数据整理的内容:
(4)数据读取与存储
不同的数据源需要使用不同的函数来读取。
Pandas内置了十余种数据源读取函数和对应的数据写入函数。
常见的数据源有文本文件(包括一般文本文件和CSV文件)、电子表格文件等。
文本文件的读取: Pandas 提供了read_CSV()函数来读取CSV文件。
文本文件的存储:对于结构化数据,可以通过Pandas 库中to_csv()函数实现以CSV文件格式进行存储。
3.2.3 数据安全
数据安全的威胁:
人为因素
非人为因素
计算机病毒
黑客攻击
数据存储介质损坏
个人失误
3.2.3 数据安全
数据保护的方法:
1.数据备份
概念:数据备份是将需要备份的数据从应用主机的硬盘或磁盘阵列复制到其他的存储介质或不同位置存储空间的过程。
目的:在设备发生故障或发生其他威胁数据安全的灾害后,利用备份进行恢复,从而达到保护数据的目的。
常见方法:可移动存储设备备份和网络备份。
3.2.3 数据安全
数据保护的方法:
2.数据加密
概念:数据加密是使用特定算法把敏感的明文数据变换成难以识别的密文数据。
常见方法:可以为数据文件设置密码,加密系统利用设定的密码将整个文件进行加密处理。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
P92
习 题
C
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
P94
习 题
手机中有许多传感器,例如:
加速度传感器——计步、判断手机朝向;
光线传感器——自动调节手机屏幕的亮度;
指纹传感器——手指指纹解锁、支付等;
陀螺仪一体感、摇一摇、游戏中控制视角等。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
P99
(4)实践活动:编写程序删除用水量数据中的重复值
#导入pandas模块并设置别名为pd
import pandas as pd
#用pandas模块中的read_csv函数打开数据文件,指定文件的文字编码方式,指定包含列
df=pd.DataFrame(pd.read_csv('yongshui.csv',encoding='gbk',header=1))
df1=df.drop_duplicates()
df1.to_csv('yongshuixin.csv',encoding='gbk')
df2=pd.read_csv('yongshuixin.csv',encoding='gbk')
print(df2)
习 题
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
P100
1.网上行为数据可能存储在本地或云空间。数据泄露可能造成个人信息被窃取,财产损失等诸多问题。
2.通过提高数据安全意识、重视保护个人隐私数据、设置安全强度高的密码、安装杀毒软件,及时备份等方法都可以起到保护数据安全的作用。
习 题
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
1.例如,如果只在国家统计局的网站上查找水资源数据,则可以在百度搜索框中输入
“水资源site:www.stats.”,将只返回从这个网站检索的数据。
2.可使用“后羿采集器”从腾讯体育网站抓取中国男篮球员的相关数据。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
②专用采集工具和在线平台
为更加方便、快捷地获取网络上的海量数据,人们还开发了各种专门用于采集数据的工具,如“后羿采集器”“八爪鱼采集器”“熊猫采集器”“火车头采集器”和“集搜客”等,借助这些专用工具可以从网页上获取数据。这些专用工具通常具有功能强大的网络爬虫,适合大数据的采集。这里以“后羿采集器”为例,介绍如何使用专用软件快速、精准地采集网页数据。采集任务为从腾讯网批量下载NBA球员数据。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
②专用采集工具和在线平台
a.启动“后羿采集器”。通过网络下载“后羿采集器”,安装并运行。
b.确定采集模式,输入网址。“后羿采集器”有两种工作模式:流程图模式和智能模式。通常,可采用简单有效的智能模式。单击智能模式下的“开始采集”按钮,单击“批量生成”。在“输入网址”处输入腾讯网NBA球员数据所在的网址。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
②专用采集工具和在线平台
通过观察腾讯网NBA球员的网页,可以发现每支球队球员数据所在的网页地址不同,但是这些网址符合一定的规则。例如,本例中每支球队网址的区别只是最后的数字不同。因此,要采集多个球队球员的数据,就可以通过批量生成的方式来采集,而不必逐一手动输入网址。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
②专用采集工具和在线平台
c.进行数据采集。单击“开始采集”和“启动”按钮后,数据采集开始。由于数据量较大,数据采集需要一定的时间。
d.导出数据。采集完成后,设置导出方式,导出采集到的数据。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.假设学生签到数据保存在“xuesheng.csv”文件中,删除重复数据的程序代码如下。
import pandas as pd
df=pd.DataFrame(pd.read_csv('xuesheng.csv',encoding='gbk',header=0))
df1=df.drop_duplicates( )
df1.to_csv('xueshengxin.csv',encoding='gbk’)
df2=pd.read_csv('xueshengxin.csv',encoding='gbk’)
print(df2)
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
4.可根据教科书中设置密码应遵循的规则进行原因分析和方案设计。例如,密码长度是否大于8位,是否使用了生日等用户信息作为密码等。
5.压缩软件WinRAR除了文件压缩功能之外,另一个常用的功能是使用密码对文件进行加密,在加密的同时还可以使用加密文件名的方式,提供更高级的文件保护措施。
练习提升P104
3.2 数据采集与整理
3.2.1 数据采集
数据采集,即根据需求采用适当的方法和工具获取所需要的数据。
3.2.1 数据采集
数据采集的主要环节包括明确数据需求,确定数据来源,选择采集方法和实施数据采集。
找什么 去哪找 怎么找
明确数据需求
确定数据来源
选择采集方法
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
1.明确数据需求
需要分析的问题
研究的内容
期望达成的目标
列出需要采集的数据目录
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
2.确定数据来源
社会调查
公众媒体
科学实验
实践活动
官网平台
物联网
社交网络
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
(1)传感器采集数据
传感器是一种检测装置,能感受到被测量的信息,并能将信息按一定规律转换成电信号或其他所需形式的信息输出。
常见的传感器:温度传感器、压力传感器、红外传感器、距离传感器、声音传感器。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
(2)网络获取数据
利用互联网搜索引擎技术实现有针对性、行业性的数据抓取,并按照一定规则和筛选标准进行数据归类,最终形成数据库文件。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
①网络获取数据的方式
a.网络爬虫
网络爬虫,是按照一定的规则,自动抓取互联网内容的程序。
网络爬虫的主要功能是自动采集其可以访问到的网页内容。
搜索引擎是一种能为用户提供检索服务,并将检索结果呈现给用户的系统。网络爬虫是搜索引擎的重要部分。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
①网络获取数据的方式
b.在线问卷
通过在线调查问卷网站完成问卷的设计、发放、回收和分析等工作。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
②实现互联网数据采集流程的三个步骤:
a.获取网页
获取网页的工作主要是获取网页的源代码。获取源代码的关键就是构造一个请求并发送给服务器,然后在接收到服务器的响应后将其解析出来。
Python中提供了许多库来帮助我们实现这个操作,如urllib、Request等。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
②实现互联网数据采集流程的三个步骤:
b.解析网页
可以利用一些用于提取网页信息的库(如Beatiful Soup、PyQuery、lxml等),高效快速地提取网页信息。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.选择采集方法
②实现互联网数据采集流程的三个步骤:
c.保存数据
提取数据后,我们一般会将其保存,以便后续使用。保存的形式多种多样,如文件存储、数据库存储或网络存储等。
3.2.2 数据整理
1.意义:
数据整理的目的是对数据进行校验和标准化。
整理过程的是否科学、结果能否真实地反映客观实际,将直接影响数据处理的质量,影响整个数据分析的准确性。
3.2.2 数据整理
在Python中,pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
使用下面格式约定,引入pandas包:
import pandas as pd
pandas有两个主要数据结构:Series和DataFrame。
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
Series的创建
pd.Series(list,index=[ ]),第二个参数是Series中数据的索引,可以省略。
见99页
3.2.2 数据整理
DataFrame
DataFrame是一个表格型的数据类型,每列值类型可以不同,是最常用的pandas对象。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
DataFrame的创建
pd.DataFrame(data,columns = [ ],index = [ ]):
columns和index为指定的列、行索引,并按照顺序排列。
3.2.2 数据整理
使用pandas做数据处理的第一步就是读取数据,数据源可以来自于各种地方,csv文件便是其中之一。而读取csv文件,pandas也提供了非常强力的支持,参数有四五十个。这些参数中,有的很容易被忽略,但是在实际工作中却用处很大。比如:
文件读取时设置某些列为时间类型
导入文件, 含有重复列
过滤某些列
每次迭代指定的行数
值替换
utf-8编码包含全世界所有国家需要用的字符,它比较灵活,长度在1-6个字节,utf-8编码格式很强大,支持所有国家的语言,正是因为它的强大,才会导致它占用的空间大小要比gbk大,对于网站打开速度而言,也是有一定影响的。
gbk编码主要用中文编码,包含全部中文字符,gbk的长度为2个字节,所以和gbk相比,utf-8会占用更多的数据库储存空间。对于gbk编码格式,虽然它的功能少,仅限于中文字符,但它所占用的空间大小会随着它的功能而减少,打开网页的速度比较快。
3.2.2 数据整理
pandas.read_csv 读取CSV文件
pandas.DataFrame.to_csv 导出数据到CSV文件
pandas. DataFrame.colums 描述DataFrame列
pandas. DataFrame.loc 通过行与列标签选择一个值
pandas. DataFrame.shape 返回DataFrame的行数和列数
pandas. DataFrame.drop_duplicates 删除重复的数据
3.2.2 数据整理
2.数据整理的内容:
(1)检测与处理重复值
记录重复:某几条记录的一个或多个特征值完全相同。
特征重复:存在一个或者多个特征名称不同,但数据完全相同的情况。
处理办法:对重复数据进行处理前,需要分析重复数据产生的原因以及去除这部分数据后可能造成的不良影响。
Python的数据分析核心库Pandas提供了一个名为drop_duplicates()的去重方法。
3.2.2 数据整理
2.数据整理的内容:
(2)检测与处理缺失值
缺失值是指数据中的某个或多个特征的值是不完整的。
处理方法:
删除法是常用的缺失值处理方法,它通过减少样本量来换取信息完整度,是一种较简单的缺失值处理方法。
Pandas库提供了识别缺失值的方法isnull()和识别非缺失值的方法notnull()以及简便的删除缺失值的方法dropna()。
3.2.2 数据整理
2.数据整理的内容:
(3)检测与处理异常值
异常值是指数据中个别值的数值明显偏离其余的数值。有时候也称为离群点。检测异常值就是检验数据中是否有输入错误以及是否含有不合理的数据。
处理方法:
直接将含有异常值的记录删除。用前后两个观测值的平均值修正该异常值;将异常值视为缺失值,利用处理缺失值的方法进行处理。
3.2.2 数据整理
2.数据整理的内容:
(4)数据读取与存储
不同的数据源需要使用不同的函数来读取。
Pandas内置了十余种数据源读取函数和对应的数据写入函数。
常见的数据源有文本文件(包括一般文本文件和CSV文件)、电子表格文件等。
文本文件的读取: Pandas 提供了read_CSV()函数来读取CSV文件。
文本文件的存储:对于结构化数据,可以通过Pandas 库中to_csv()函数实现以CSV文件格式进行存储。
3.2.3 数据安全
数据安全的威胁:
人为因素
非人为因素
计算机病毒
黑客攻击
数据存储介质损坏
个人失误
3.2.3 数据安全
数据保护的方法:
1.数据备份
概念:数据备份是将需要备份的数据从应用主机的硬盘或磁盘阵列复制到其他的存储介质或不同位置存储空间的过程。
目的:在设备发生故障或发生其他威胁数据安全的灾害后,利用备份进行恢复,从而达到保护数据的目的。
常见方法:可移动存储设备备份和网络备份。
3.2.3 数据安全
数据保护的方法:
2.数据加密
概念:数据加密是使用特定算法把敏感的明文数据变换成难以识别的密文数据。
常见方法:可以为数据文件设置密码,加密系统利用设定的密码将整个文件进行加密处理。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
P92
习 题
C
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
P94
习 题
手机中有许多传感器,例如:
加速度传感器——计步、判断手机朝向;
光线传感器——自动调节手机屏幕的亮度;
指纹传感器——手指指纹解锁、支付等;
陀螺仪一体感、摇一摇、游戏中控制视角等。
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
P99
(4)实践活动:编写程序删除用水量数据中的重复值
#导入pandas模块并设置别名为pd
import pandas as pd
#用pandas模块中的read_csv函数打开数据文件,指定文件的文字编码方式,指定包含列
df=pd.DataFrame(pd.read_csv('yongshui.csv',encoding='gbk',header=1))
df1=df.drop_duplicates()
df1.to_csv('yongshuixin.csv',encoding='gbk')
df2=pd.read_csv('yongshuixin.csv',encoding='gbk')
print(df2)
习 题
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
P100
1.网上行为数据可能存储在本地或云空间。数据泄露可能造成个人信息被窃取,财产损失等诸多问题。
2.通过提高数据安全意识、重视保护个人隐私数据、设置安全强度高的密码、安装杀毒软件,及时备份等方法都可以起到保护数据安全的作用。
习 题
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
1.例如,如果只在国家统计局的网站上查找水资源数据,则可以在百度搜索框中输入
“水资源site:www.stats.”,将只返回从这个网站检索的数据。
2.可使用“后羿采集器”从腾讯体育网站抓取中国男篮球员的相关数据。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
②专用采集工具和在线平台
为更加方便、快捷地获取网络上的海量数据,人们还开发了各种专门用于采集数据的工具,如“后羿采集器”“八爪鱼采集器”“熊猫采集器”“火车头采集器”和“集搜客”等,借助这些专用工具可以从网页上获取数据。这些专用工具通常具有功能强大的网络爬虫,适合大数据的采集。这里以“后羿采集器”为例,介绍如何使用专用软件快速、精准地采集网页数据。采集任务为从腾讯网批量下载NBA球员数据。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
②专用采集工具和在线平台
a.启动“后羿采集器”。通过网络下载“后羿采集器”,安装并运行。
b.确定采集模式,输入网址。“后羿采集器”有两种工作模式:流程图模式和智能模式。通常,可采用简单有效的智能模式。单击智能模式下的“开始采集”按钮,单击“批量生成”。在“输入网址”处输入腾讯网NBA球员数据所在的网址。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
②专用采集工具和在线平台
通过观察腾讯网NBA球员的网页,可以发现每支球队球员数据所在的网页地址不同,但是这些网址符合一定的规则。例如,本例中每支球队网址的区别只是最后的数字不同。因此,要采集多个球队球员的数据,就可以通过批量生成的方式来采集,而不必逐一手动输入网址。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
②专用采集工具和在线平台
c.进行数据采集。单击“开始采集”和“启动”按钮后,数据采集开始。由于数据量较大,数据采集需要一定的时间。
d.导出数据。采集完成后,设置导出方式,导出采集到的数据。
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
3.假设学生签到数据保存在“xuesheng.csv”文件中,删除重复数据的程序代码如下。
import pandas as pd
df=pd.DataFrame(pd.read_csv('xuesheng.csv',encoding='gbk',header=0))
df1=df.drop_duplicates( )
df1.to_csv('xueshengxin.csv',encoding='gbk’)
df2=pd.read_csv('xueshengxin.csv',encoding='gbk’)
print(df2)
练习提升P104
1.下列关于数据整理的说法,正确的是()
A.数据集中的缺失值一般用任意值填充
B.数据集中的异常数据须直接删除或忽略
C.数据集中的重复数据可进行合并或删除
D.数据集中格式不一致的数据,一般保留一种格式的数据,删除其他格式的数据
2.以下关于数据整理,错误的是()
A.数据的重复值会导致数据分布变化
B.数据的缺失值会导致样本信息减少
C.数据的异常值增加了分析的难度
D.数据整理的科学与否对数据分析的影响不大
4.可根据教科书中设置密码应遵循的规则进行原因分析和方案设计。例如,密码长度是否大于8位,是否使用了生日等用户信息作为密码等。
5.压缩软件WinRAR除了文件压缩功能之外,另一个常用的功能是使用密码对文件进行加密,在加密的同时还可以使用加密文件名的方式,提供更高级的文件保护措施。
练习提升P104
同课章节目录
- 第1章 认识数据与大数据
- 主题学习项目:体质数据促健康
- 1.1 数据、信息与知识
- 1.2 数字化与编码
- 1.3 数据科学与大数据
- 第2章 算法与程序实现
- 主题学习项目:编程控灯利出行
- 2.1 解决问题的一般过程和用计算机解决问题
- 2.2 算法的概念及描述
- 2.3 程序设计基本知识
- 2.4 常见算法的程序实现
- 第3章 数据处理与应用
- 主题学习项目:用水分析助决策
- 3.1 数据处理的一般过程
- 3.2 数据采集与整理
- 3.3 数据分析与可视化
- 3.4 数据分析报告与应用
- 第4章 走进智能时代
- 主题学习项目:智能交互益拓展
- 4.1 认识人工智能
- 4.2 利用智能工具解决问题
- 4.3 人工智能的应用与影响