《让机器了解语言》(课件)(共17张PPT)三年级上册信息技术 河大音像版
文档属性
| 名称 | 《让机器了解语言》(课件)(共17张PPT)三年级上册信息技术 河大音像版 |

|
|
| 格式 | pptx | ||
| 文件大小 | 2.2MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 通用版 | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2023-06-29 00:00:00 | ||
图片预览





文档简介
(共17张PPT)
让机器了解
语
言
授课教师:曹艳敏
PART 01 ∣ 自然语言的定义
PART 02 ∣自然语言的交流过程
PART 03 ∣ 自然语言的处理
PART 01
自然语言
自然地随文化演化的语言
自然语言通常是指一种自然地随文化演化的语言,是人类交流和思维的主要工具,如图所示。很多民族都有自己的语言,现在世界上已经查明的语言有五千多种,其中汉语使用人数最多,英语适用范围最广
定义
PART 02
自然语言交流过程
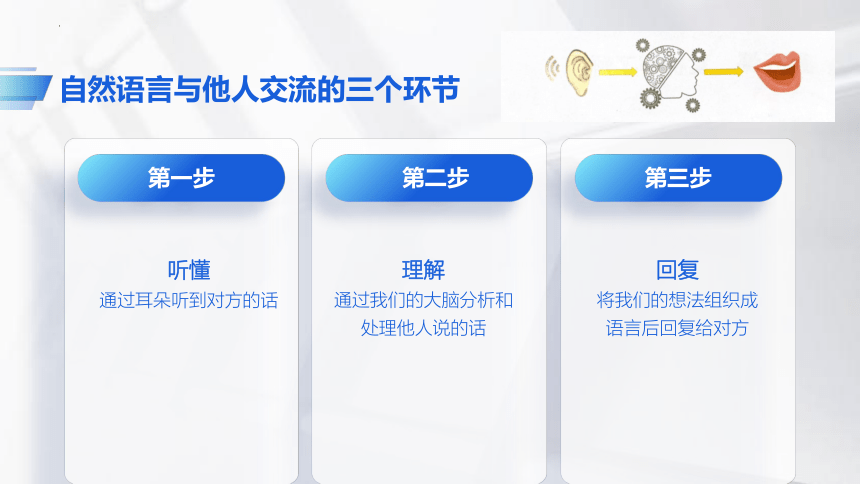
自然语言与他人交流的三个环节
回复
将我们的想法组织成语言后回复给对方
第三步
理解
通过我们的大脑分析和处理他人说的话
第二步
听懂
通过耳朵听到对方的话
第一步
PART 03
自然语言处理
让机器听懂人类语言,并能用自然语言和人类沟通,是人们长期以来的梦想。人工智能技术可以让机器处理、理解甚至运用人类的语言。
自然语言处理
听懂话意味着机器对接受的语音信息进行分析识别,这个过程称为语音识别;然后需要机器理解人说的话,这个过程叫作自然语言理解;回复话这意味着机器输出合成人类能听懂的语音,称为语音合成。
对于机器来说
在人与机器交流的过程中,我们希望机器可以像人一样能理解人说的话。然而,机器在理解人类语言过程中也遇到了一定的困难。
语言表达方式 案例
第一种语言表达方式 我要吃饭。
第二种语言表达方式 我饿了!
第三种语言表达方式 要去吃饭吗?
第四种语言表达方式 一会吃什么?
······ ······
例如,在生活中,如果想要吃饭,
人们采用的语言表达方式会有很多种
表达“吃饭”的语言方式有很多种,人们可以准确地理解不同的语言表达方式,但是要让机器理解,对机器来说是很大的挑战。在过去,机器要求用户必须输入精确的指令,比如,我们说“一会吃什么”“我饿了”,只要这些话里面没有包含提前设定好的关键词“吃饭”,机器都无法处理。
随着自然语言处理技术的发展,现在的机器已经可以从各种不同的自然语言表达中,区分哪些表达是在说同一件事情。
当前自然语言处理研究的发展趋势如下:
第一,传统的基于句法-语义规则的理性主义方法过于复杂,随着语料库建设和语料库语言学的崛起,大规模真实文本的机器学习处理成为自然语言处理的主要选择。
第二,统计数学方法越来越受到重视,自然语言处理中越来越多地使用机器自动学习的方法来获取语言知识。
第三,浅层处理与深层处理并重,统计与规则方法并重,形成混合式的系统。
第四,自然语言处理中越来越重视词汇的作用,出现了强烈的“词汇主义”的倾向。词汇知识库的建造成为了普遍关注的问题。
同词不同义
当前自然语言处理研究的发展趋势如下:
第一,传统的基于句法-语义规则的理性主义方法过于复杂,随着语料库建设和语料库语言学的崛起,大规模真实文本的机器学习处理成为自然语言处理的主要选择。
第二,统计数学方法越来越受到重视,自然语言处理中越来越多地使用机器自动学习的方法来获取语言知识。
第三,浅层处理与深层处理并重,统计与规则方法并重,形成混合式的系统。
第四,自然语言处理中越来越重视词汇的作用,出现了强烈的“词汇主义”的倾向。词汇知识库的建造成为了普遍关注的问题。
同词不同义
Microsoft
云计算
服务
数字孪生
游戏
增强现实
眼镜
混合现实
协作平台
XBOX
游戏生态
16
自然语言是指人类日常使用的语言,比如:中文、英语、日语等。自然语言灵活多变,是人类社会的重要组成部分,但它却不能被计算机很好地理解。为了实现用自然语言在人与计算机之间进行沟通,自然语言处理诞生了。自然语言处理(Natural Language Processing, NLP)是一个融合了语言学、计算机科学、数学等学科的领域,它不仅研究语言学,更研究如何让计算机处理这些语言。它主要分为两大方向:自然语言理解(Natural language Understanding, NLU)和自然语言生成(Natural language Generation, NLG),前者是听读,后者是说写。
本文将从自然语言处理的历史与发展讲起,进而分析目前深度学习在自然语言处理领域的研究进展,最后讨论自然语言处理的未来发展方向。
1950年,计算机科学之父图灵提出了“图灵测试”,标志着人工智能领域的开端。而此时,正值苏美冷战,美国政府为了更方便地破译苏联相关文件,大力投入机器翻译的研究,自然语言处理从此兴起。从这之后的一段时期内,自然语言处理主要采用基于规则的方法,这种方法依赖于语言学,它通过分析词法、语法等信息,总结这些信息之间的规则,从而达到翻译的效果。这种类似于专家系统的方法,泛化性差、不便于优化,最终进展缓慢,未能达到预期效果。
到了20世纪80、90年代,互联网飞速发展,计算机硬件也有了显著提升。同时,自然语言处理引入了统计机器学习算法,基于规则的方法逐渐被基于统计的方法所取代。在这一阶段,自然语言处理取得了实质性突破,并走向了实际应用。
而从2008年左右开始,随着深度学习神经网络在图像处理、语音识别等领域取得了显著的成果,它也开始被应用到自然语言处理领域。从最开始的词嵌入、word2vec,到RNN、GRU、LSTM等神经网络模型,再到最近的注意力机制、预训练语言模型等等。伴随着深度学习的加持,自然语言处理也迎来了突飞猛进。
接下来,我将介绍自然语言处理与深度学习结合后的相关进展。
在自然语言中,词是最基本的单元。为了让计算机理解并处理自然语言,我们首先就要对词进行编码。由于自然语言中词的数量是有限的,那就可以对每个词指定一个唯一序号,比如:英文单词word的序号可以是1156。而为了方便计算,通常会将序号转换成统一的向量。简单做法是对单词序号进行one-hot编码,每个单词都对应一个长度为N(单词总数)的向量(一维数组),向量中只有该单词序号对应位置的元素值为1,其它都为0。
虽然使用one-hot编码构造词向量十分容易,但并不是一个较好的方法。主要原因是无法很好地表示词的语义,比如苹果和橘子是相似单词(都是水果),但one-hot向量就无法体现这种相似关系。
为了解决上述问题,Google的Mikolov等人于2013年发表了两篇与word2vec相关的原始论文[1][2]。word2vec将词表示成一个定长的向量,并通过上下文学习词的语义信息,使得这些向量能表达词特征、词之间关系等语义信息。word2vec包含两个模型:跳字模型(Skip-gram)[1] 和连续词袋模型(continuous bag of words,CBOW)[2],它们的作用分别是:通过某个中心词预测上下文、通过上下文预测某个中心词。比如,有一句话"I drink apple juice",Skip-gram模型是用apple预测其它词,CBOW模型则是用其它词预测出apple。
首先介绍CBOW模型,它是一个三层神经网络,通过上下文预测中心词。以某个训练数据"I drink apple juice"为例,可以把apple作为标签值先剔除,将"I drink juice"作为输入,apple作为待预测的中心词。
Skip-gram模型与CBOW类似,也是一个三层神经网络模型。不同在于,它是通过中心词预测上下文,即通过"apple"预测出"I drink juice"。接下来简单介绍Skip-gram模型中各层:
两种模型训练结束后,会取 作为词向量矩阵,第i行就代表词库中第i个词的词向量。词向量可用来计算词之间的相似度(词向量点乘)。比如,输入 I drink _ juice 上下文,预测出中心词为apple、orange的概率可能都很高,原因就是在 中apple和orange对应的词向量十分相似,即相似度高。词向量还可以用于机器翻译、命名实体识别、关系抽取等等。
其实这两种模型的原型在2003年就已出现[3],而Mikolov在13年的论文中主要是简化了模型,且提出了负采样与层序softmax方法,使得训练更加高效。
词向量提出的同时,深度学习RNN框架也被应用到NLP中,并结合词向量取得了巨大成效。但是,RNN网络也存在一些问题,比如:难以并行化、难以建立长距离和层级化的依赖关系。而这些问题都在2017年发表的论文《Attention Is All You Need》[4]中得到有效解决。正是在这篇论文中,提出了Transformer模型。Transformer中抛弃了传统的复杂的CNN和RNN,整个网络结构完全由注意力机制组成。
Transformer最核心的内容是自注意力机制(Self-Attention),它是注意力机制(Attention)的变体。注意力的作用是从大量信息中筛选出少量重要信息,并聚焦在这些信息上,比如:人在看一幅图像时,会重点关注较为吸引的部分,而忽略其它信息,这就是注意力的体现。但注意力机制会关注全局信息,即关注输入数据与输出数据以及中间产物的相关性。而自注意力机制则减少了对外部其它数据的关注,只关注输入数据本身,更擅长捕捉数据内部的相关性。
自注意力机制的算法过程如下:
自注意力机制不仅建立了输入数据中词与词之间的关系,还能并行地高效地计算出每个词的输出。
Transformer的总体架构如下:
它分为两部分:编码器(Encoder)和解码器(Decoder)。
编码器的输入是词向量加上位置编码(表明这个词是在哪个位置),再通过多头自注意力操作(Multi-Head Attention)、全连接网络(Feed Forward)两部分得到输出。其中,多头自注意力就是输入的每个词对应多组q、k、v,每组之间互不影响,最终每个词产生多个输出b值,组成一个向量。编码器是transformer的核心,它通常会有多层,前一层的输出会作为下一层的输入,最后一层的输出会作为解码器的一部分输入。
解码器包含两个不同的多头自注意力操作(Masked Multi-Head Attention和Multi-Head Attention)、全连接网络(Feed Forward)三部分。解码器会运行多次,每次只输出一个单词,直到输出完整的目标文本。已输出的部分会组合起来,作为下一次解码器的输入。其中,Masked Multi-Head Attention是将输入中未得到的部分遮掩起来,再进行多头自注意力操作。比如原有5个输入,但某次只有2个输入,那么q1和q2只会与k1、k2相乘,。
如果深度学习的应用,让NLP有了第一次飞跃。那预训练模型的出现,让NLP有了第二次的飞跃。预训练通过自监督学习(不需要标注)从大规模语料数据中学习出一个强大的语言模型,再通过微调迁移到具体任务,最终达成显著效果。
预训练模型的优势如下:
预训练模型的关键技术有三个:
关于预训练模型的架构,以Bert为例:输入是词的one-hot编码向量,乘上词向量矩阵后,再经过多层transformer中的Encoder模块,最终得到输出。
本文介绍了NLP领域的流行研究进展,其中transformer和预训练模型的出现,具有划时代的意义。但随着预训练模型越来越庞大,也将触及硬件瓶颈。另外,NLP在一些阅读理解、文本推理等任务上的表示,也差强人意。总而言之,NLP领域依旧存在着巨大的前景与挑战,仍然需要大家的长期努力。
感
谢
观
看
THANKS
让机器了解
语
言
授课教师:曹艳敏
PART 01 ∣ 自然语言的定义
PART 02 ∣自然语言的交流过程
PART 03 ∣ 自然语言的处理
PART 01
自然语言
自然地随文化演化的语言
自然语言通常是指一种自然地随文化演化的语言,是人类交流和思维的主要工具,如图所示。很多民族都有自己的语言,现在世界上已经查明的语言有五千多种,其中汉语使用人数最多,英语适用范围最广
定义
PART 02
自然语言交流过程
自然语言与他人交流的三个环节
回复
将我们的想法组织成语言后回复给对方
第三步
理解
通过我们的大脑分析和处理他人说的话
第二步
听懂
通过耳朵听到对方的话
第一步
PART 03
自然语言处理
让机器听懂人类语言,并能用自然语言和人类沟通,是人们长期以来的梦想。人工智能技术可以让机器处理、理解甚至运用人类的语言。
自然语言处理
听懂话意味着机器对接受的语音信息进行分析识别,这个过程称为语音识别;然后需要机器理解人说的话,这个过程叫作自然语言理解;回复话这意味着机器输出合成人类能听懂的语音,称为语音合成。
对于机器来说
在人与机器交流的过程中,我们希望机器可以像人一样能理解人说的话。然而,机器在理解人类语言过程中也遇到了一定的困难。
语言表达方式 案例
第一种语言表达方式 我要吃饭。
第二种语言表达方式 我饿了!
第三种语言表达方式 要去吃饭吗?
第四种语言表达方式 一会吃什么?
······ ······
例如,在生活中,如果想要吃饭,
人们采用的语言表达方式会有很多种
表达“吃饭”的语言方式有很多种,人们可以准确地理解不同的语言表达方式,但是要让机器理解,对机器来说是很大的挑战。在过去,机器要求用户必须输入精确的指令,比如,我们说“一会吃什么”“我饿了”,只要这些话里面没有包含提前设定好的关键词“吃饭”,机器都无法处理。
随着自然语言处理技术的发展,现在的机器已经可以从各种不同的自然语言表达中,区分哪些表达是在说同一件事情。
当前自然语言处理研究的发展趋势如下:
第一,传统的基于句法-语义规则的理性主义方法过于复杂,随着语料库建设和语料库语言学的崛起,大规模真实文本的机器学习处理成为自然语言处理的主要选择。
第二,统计数学方法越来越受到重视,自然语言处理中越来越多地使用机器自动学习的方法来获取语言知识。
第三,浅层处理与深层处理并重,统计与规则方法并重,形成混合式的系统。
第四,自然语言处理中越来越重视词汇的作用,出现了强烈的“词汇主义”的倾向。词汇知识库的建造成为了普遍关注的问题。
同词不同义
当前自然语言处理研究的发展趋势如下:
第一,传统的基于句法-语义规则的理性主义方法过于复杂,随着语料库建设和语料库语言学的崛起,大规模真实文本的机器学习处理成为自然语言处理的主要选择。
第二,统计数学方法越来越受到重视,自然语言处理中越来越多地使用机器自动学习的方法来获取语言知识。
第三,浅层处理与深层处理并重,统计与规则方法并重,形成混合式的系统。
第四,自然语言处理中越来越重视词汇的作用,出现了强烈的“词汇主义”的倾向。词汇知识库的建造成为了普遍关注的问题。
同词不同义
Microsoft
云计算
服务
数字孪生
游戏
增强现实
眼镜
混合现实
协作平台
XBOX
游戏生态
16
自然语言是指人类日常使用的语言,比如:中文、英语、日语等。自然语言灵活多变,是人类社会的重要组成部分,但它却不能被计算机很好地理解。为了实现用自然语言在人与计算机之间进行沟通,自然语言处理诞生了。自然语言处理(Natural Language Processing, NLP)是一个融合了语言学、计算机科学、数学等学科的领域,它不仅研究语言学,更研究如何让计算机处理这些语言。它主要分为两大方向:自然语言理解(Natural language Understanding, NLU)和自然语言生成(Natural language Generation, NLG),前者是听读,后者是说写。
本文将从自然语言处理的历史与发展讲起,进而分析目前深度学习在自然语言处理领域的研究进展,最后讨论自然语言处理的未来发展方向。
1950年,计算机科学之父图灵提出了“图灵测试”,标志着人工智能领域的开端。而此时,正值苏美冷战,美国政府为了更方便地破译苏联相关文件,大力投入机器翻译的研究,自然语言处理从此兴起。从这之后的一段时期内,自然语言处理主要采用基于规则的方法,这种方法依赖于语言学,它通过分析词法、语法等信息,总结这些信息之间的规则,从而达到翻译的效果。这种类似于专家系统的方法,泛化性差、不便于优化,最终进展缓慢,未能达到预期效果。
到了20世纪80、90年代,互联网飞速发展,计算机硬件也有了显著提升。同时,自然语言处理引入了统计机器学习算法,基于规则的方法逐渐被基于统计的方法所取代。在这一阶段,自然语言处理取得了实质性突破,并走向了实际应用。
而从2008年左右开始,随着深度学习神经网络在图像处理、语音识别等领域取得了显著的成果,它也开始被应用到自然语言处理领域。从最开始的词嵌入、word2vec,到RNN、GRU、LSTM等神经网络模型,再到最近的注意力机制、预训练语言模型等等。伴随着深度学习的加持,自然语言处理也迎来了突飞猛进。
接下来,我将介绍自然语言处理与深度学习结合后的相关进展。
在自然语言中,词是最基本的单元。为了让计算机理解并处理自然语言,我们首先就要对词进行编码。由于自然语言中词的数量是有限的,那就可以对每个词指定一个唯一序号,比如:英文单词word的序号可以是1156。而为了方便计算,通常会将序号转换成统一的向量。简单做法是对单词序号进行one-hot编码,每个单词都对应一个长度为N(单词总数)的向量(一维数组),向量中只有该单词序号对应位置的元素值为1,其它都为0。
虽然使用one-hot编码构造词向量十分容易,但并不是一个较好的方法。主要原因是无法很好地表示词的语义,比如苹果和橘子是相似单词(都是水果),但one-hot向量就无法体现这种相似关系。
为了解决上述问题,Google的Mikolov等人于2013年发表了两篇与word2vec相关的原始论文[1][2]。word2vec将词表示成一个定长的向量,并通过上下文学习词的语义信息,使得这些向量能表达词特征、词之间关系等语义信息。word2vec包含两个模型:跳字模型(Skip-gram)[1] 和连续词袋模型(continuous bag of words,CBOW)[2],它们的作用分别是:通过某个中心词预测上下文、通过上下文预测某个中心词。比如,有一句话"I drink apple juice",Skip-gram模型是用apple预测其它词,CBOW模型则是用其它词预测出apple。
首先介绍CBOW模型,它是一个三层神经网络,通过上下文预测中心词。以某个训练数据"I drink apple juice"为例,可以把apple作为标签值先剔除,将"I drink juice"作为输入,apple作为待预测的中心词。
Skip-gram模型与CBOW类似,也是一个三层神经网络模型。不同在于,它是通过中心词预测上下文,即通过"apple"预测出"I drink juice"。接下来简单介绍Skip-gram模型中各层:
两种模型训练结束后,会取 作为词向量矩阵,第i行就代表词库中第i个词的词向量。词向量可用来计算词之间的相似度(词向量点乘)。比如,输入 I drink _ juice 上下文,预测出中心词为apple、orange的概率可能都很高,原因就是在 中apple和orange对应的词向量十分相似,即相似度高。词向量还可以用于机器翻译、命名实体识别、关系抽取等等。
其实这两种模型的原型在2003年就已出现[3],而Mikolov在13年的论文中主要是简化了模型,且提出了负采样与层序softmax方法,使得训练更加高效。
词向量提出的同时,深度学习RNN框架也被应用到NLP中,并结合词向量取得了巨大成效。但是,RNN网络也存在一些问题,比如:难以并行化、难以建立长距离和层级化的依赖关系。而这些问题都在2017年发表的论文《Attention Is All You Need》[4]中得到有效解决。正是在这篇论文中,提出了Transformer模型。Transformer中抛弃了传统的复杂的CNN和RNN,整个网络结构完全由注意力机制组成。
Transformer最核心的内容是自注意力机制(Self-Attention),它是注意力机制(Attention)的变体。注意力的作用是从大量信息中筛选出少量重要信息,并聚焦在这些信息上,比如:人在看一幅图像时,会重点关注较为吸引的部分,而忽略其它信息,这就是注意力的体现。但注意力机制会关注全局信息,即关注输入数据与输出数据以及中间产物的相关性。而自注意力机制则减少了对外部其它数据的关注,只关注输入数据本身,更擅长捕捉数据内部的相关性。
自注意力机制的算法过程如下:
自注意力机制不仅建立了输入数据中词与词之间的关系,还能并行地高效地计算出每个词的输出。
Transformer的总体架构如下:
它分为两部分:编码器(Encoder)和解码器(Decoder)。
编码器的输入是词向量加上位置编码(表明这个词是在哪个位置),再通过多头自注意力操作(Multi-Head Attention)、全连接网络(Feed Forward)两部分得到输出。其中,多头自注意力就是输入的每个词对应多组q、k、v,每组之间互不影响,最终每个词产生多个输出b值,组成一个向量。编码器是transformer的核心,它通常会有多层,前一层的输出会作为下一层的输入,最后一层的输出会作为解码器的一部分输入。
解码器包含两个不同的多头自注意力操作(Masked Multi-Head Attention和Multi-Head Attention)、全连接网络(Feed Forward)三部分。解码器会运行多次,每次只输出一个单词,直到输出完整的目标文本。已输出的部分会组合起来,作为下一次解码器的输入。其中,Masked Multi-Head Attention是将输入中未得到的部分遮掩起来,再进行多头自注意力操作。比如原有5个输入,但某次只有2个输入,那么q1和q2只会与k1、k2相乘,。
如果深度学习的应用,让NLP有了第一次飞跃。那预训练模型的出现,让NLP有了第二次的飞跃。预训练通过自监督学习(不需要标注)从大规模语料数据中学习出一个强大的语言模型,再通过微调迁移到具体任务,最终达成显著效果。
预训练模型的优势如下:
预训练模型的关键技术有三个:
关于预训练模型的架构,以Bert为例:输入是词的one-hot编码向量,乘上词向量矩阵后,再经过多层transformer中的Encoder模块,最终得到输出。
本文介绍了NLP领域的流行研究进展,其中transformer和预训练模型的出现,具有划时代的意义。但随着预训练模型越来越庞大,也将触及硬件瓶颈。另外,NLP在一些阅读理解、文本推理等任务上的表示,也差强人意。总而言之,NLP领域依旧存在着巨大的前景与挑战,仍然需要大家的长期努力。
感
谢
观
看
THANKS
同课章节目录