2025新教材技术高考第一轮基础练习--信息技术专题三 数据处理与应用
文档属性
| 名称 | 2025新教材技术高考第一轮基础练习--信息技术专题三 数据处理与应用 |

|
|
| 格式 | docx | ||
| 文件大小 | 2.4MB | ||
| 资源类型 | 试卷 | ||
| 版本资源 | 通用版 | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2024-03-15 00:00:00 | ||
图片预览

文档简介
中小学教育资源及组卷应用平台
2025新教材技术高考第一轮
专题三 数据处理与应用
考点过关练
考点一 常用表格数据的处理
1.(2022诸暨海亮高中期中,16)为了响应全民健身计划,某高中对学生进行了体质健康测评,并用Excel软件进行数据处理,如图a所示。
图a
请回答下列问题:
(1)区域M2:P15 的数据是通过公式计算得到的,在M2单元格中输入公式后,再使用自动填充功能完成该区域的计算,则N3单元格中的公式是“=SUMPRODUCT(( )*($I$3:$I$553=N$1))”。
(提示:M2单元格输入公式=SUMPRODUCT((A1:A100=“2”)*(I1:I100=“优秀”)),表示同时满足A1:A100是2班和I1:I100是优秀这两个条件的情况数量,也就是进行条件计数。)
(2)根据图a中的数据制作的图表如图b所示。创建该图表的数据区域是 。
图b
(3)对图a工作表进行相关数据分析,下列说法正确的是 (多选,填字母)。
A.以“总分等级”为依据进行升序排序,选择的区域是A3:I553
B.选择“A3:I553”按照“总分等级”升序排序后,图 b 的图表不会发生改变
C.现需要选出总分等级为“不及格”的学生,可选择区域A3:I553,以“总分等级”为“不及格”进行筛选并保留结果
D.为了显示男生立定跳远得分最高的3位学生数据,可先对“性别”为“男”进行筛选,再对“立定跳远”进行筛选,选择最大的3项
2.(2023杭州“六县九校”期中,16)小明同学为备战明年的计算机类研究生考试,收集了部分高校的计算机专业复试分数线并进行分析。小明收集到的数据如图a所示。
各院校总分展示图
请帮助小明同学对表格数据进行下列分析:
(1)若想知道这些学校的总分情况,则在F2单元格先输入公式 (要求必须使用函数),然后使用自动填充功能完成单元格F3:F8 的计算。
(2)现要求按照“总分”列进行降序排序,并筛选出总分在290分及以上的院校并显示,最后绘制各个院校总分的垂直柱形图(如图b)。请在程序划线①②③处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['KaiTi','SimHei','FangSong'] #图表中文显示处理
df=pd.read_excel ("score.xlsx")
df1=df[ ① ]
print(df1)#输出筛选数据
df=df. ② ("总分",ascending=False)#按照“总分”列降序排序
print(df)#输出排序好的数据
#------创建图表代码------
plt.title("各院校总分展示图")
plt.xlabel("院校名称")
plt. ③ (df.院校名称,df.总分) #各个院校总分的垂直柱形图
plt.show()
3.(2023杭州S9联盟联考,14)小明收集了当地2023年3月份的天气情况,数据存储在文件“temp.xlsx”中,如图a所示。分析温差最大的日期,并生成反映各类天气情况的天数对比图如图b所示。
(1)在对表格进行数据整理时发现,“日期”可能存在的数据问题是 (单选:A.数据缺失;B.数据异常;C.逻辑错误;D.数据格式不一致)。
(2)程序代码如下所示,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams["font.sans-serif"]=["SimHei"] #设置中文字体
df=pd.read_excel("temp.xlsx")
df["温差"]= ① #新增"温差"列
s=df.sort_values("温差", ascending=False, ignore_index=True)
df_max= ② #获取温差最大的日期,如并列只输出第一个日期
print(df_max)
df_t=s.groupby("天气", as_index=False).count()
df_t=df_t.rename(columns={"日期": "天数"}) #修改列名"日期"为"天数"
x=df_t["天气"]
y=df_t["天数"]
③ (x, y, label="天气情况")
plt.legend()
plt.show()
(3)观察图b,3月份天数最多的天气类型是 。
4.(2023杭州地区重点中学期中,15)某中学高一年级完成一次7选3意向调查,数据存储在“xk73.xlsx”中,如图a所示,其中1代表选择科目,0代表弃选科目。
(1)使用 pandas 编程计算本次选课各门课人数占总人数的比例, 请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#图表显示中文
df=pd.read_excel (" ① ")
a=[" "]*len(df) #存储每个学生的选课组合
dic={"物":0,"化":0,"生":0,"政":0,"历":0,"地":0,"技":0}
for i in df.index:
for j in df.columns[3:]:
if df.at[i,j]==1:
②
a[i]+=j
for i in dic.keys():
dic[i]=round(dic[i]/len(df)*100,2)
(2)按照各科选考人数占比创建如图b所示的图表。
各科选考人数占比
df1=pd.DataFrame({"学科":dic.keys(),"人数占比":dic.values()})
df1= ①
plt.title("各科选考人数占比")
plt.bar( ② , label="人数占比")
plt.legend()
plt.show()
观察图b,横线处应填入的代码为:① ;② (选填字母)。
A.df1.sort_values("人数占比",ascending=True)
B.df1.sort_values("人数占比",ascending=False)
C.df1.学科,df1.人数占比
D.df1.人数占比,df1.学科
(3)小李同学想查询某种七选三组合有多少人。以下程序代码可以为小李同学提供查询功能,程序运行示例如图c所示,请在划线处填入合适的代码。
请输入需要查询的选课组合:物化技
选择物化技组合的同学共有:192人
图c
cx=input("请输入需要查询的选课组合:")
cnt=0
for i in range(len(a)):
if :
cnt=cnt+1
print(f"选择{cx}组合的同学共有: {cnt}人")
5.(2023浙江1月选考,14,9分)小红收集了部分城市2021年全年每天PM2.5、PM10、CO浓度数据,每天的数据分别保存在以8位日期字符串命名的CSV文件中,部分文件如图a所示,每个文件记录了一天24小时的监测数据,示例如图b所示。
为统计分析城市A全年各月份PM2.5的月平均浓度(当月的日平均浓度的平均值),编写Python程序。请回答下列问题:
(1)定义pmday函数,功能为:读取某天的CSV文件,返回城市A当天PM2.5的日平均浓度。函数代码如下,划线处应填入的代码为 (单选,填字母)。
A.df['类型']=='PM2.5'
B.df['类型'=='PM2.5']
C.df[df['类型']]=='PM2.5'
D.df[df['类型']=='PM2.5']
import pandas as pd
def pmday(dayfile):
df=pd.read_csv(dayfile) #读取文件 dayfile 中的数据
df=
return df['城市A'].mean() #返回城市A当天PM2.5的日平均浓度
(2)统计城市A各月份PM2.5的月平均浓度并绘制线形图,部分Python程序如下,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
def tstr(t):
if t<10:
retrun '0'+str(t)
else:
retrun str(t)
pm=[0]*12
mdays=[31,28,31,30,31,30,31,31,30,31,30,31] #2021年每月天数
for m in range(12):
sm=0
mstr=tstr(m+1)
for d in range( ① ):
dstr=tstr(d+1)
dayfile='2021'+ mstr+ dstr+ '.csv'
sd=pmday(dayfile)
②
pm[m]=sm/mdays[m]
x=[1,2,3,4,5,6,7,8,9,10,11,12]
y= ③
plt.plot(x,y) #绘制线形图
#设置绘图参数,显示如图c所示线形图,代码略
(3)城市A 2021年 PM2.5年平均浓度为34.6微克/立方米。由图c可知,城市A 2021年 PM2.5月平均浓度超过年平均浓度的月份共 个。
考点二 大数据处理
1.(2023宁波三锋期中,2)下列关于大数据与大数据处理的说法,不正确的是( )
A.处理大数据时,一般采用分治思想
B.大数据的处理对象是全体数据,而不是抽样数据
C.大数据的特点是数据量大、速度快、数据类型多、价值密度低
D.Hadoop是一个可运行于大规模计算机集群上的分布式系统基础架构,适用于处理实时数据
2.(2023金华十校联考,3)下列有关大数据处理、数据可视化的说法不正确的是( )
A.静态数据是指处理时已收集完成、计算时不会发生改变的数据
B.流数据主要是指不间断地、持续地到达的实时数据
C.图计算是指有关大量图片的计算
D.“各省生产总值占比情况”可以采用饼图或环形图呈现
3.有Python程序段如下所示:
import pandas as pd
import numpy as np
a=np.array([1,2,3,4]).reshape(2,2)
df=pd.DataFrame(a)
print(df.at[1,1])
该程序段运行后输出的结果为( )
A.4 B.3 C.2 D.1
4.小张收集了近阶段要学习的英文单词,存储为“data.txt”文件,格式如图所示。
处理“data.txt”文件中的英文单词的Python程序段如下所示:
file='data.txt'
word_c=[]
n=0
for word in open(file):
if word[0:1]=="c":
word_c.append(word)
print('字母c开头的单词个数为:',n)
(1)划线处的代码为 。
(2)该程序段运行后,列表word_c中的数据为 。
5.请在空格处填写正确的代码,使程序完善。
实现功能:绘制y=x2-2x+1的图象。
#加载numpy模块并取名为np
import numpy as np
#加载matplotlib.pyplot模块并取名为plt
import matplotlib.pyplot as plt
# x在-7到9之间,每隔0.1取一个值
x=np.arange(-7,9,0.1)
① =x**2-2*x+1
plt.plot(x, ② )
plt.title('y=x*x-2*x+1')
plt.xlabel('x')
plt.ylabel('y')
plt. ③
6.在网上搜索朱自清的文章《绿》,如图所示。
(1)搜索信息并保存为txt文件,该过程称为 。
(2)“绿.txt”文件的文本类型是 。(填写字母:A.结构化数据/B.半结构化数据/C.非结构化数据)
(3)制作标签云的代码如下:
import collections
import jieba
import wordcloud as wc
import numpy as np
from PIL import Image
wcg=wc.WordCloud(background_color="white",font_path='assets/msyh.ttf')
text=open('data/绿.txt',encoding='utf-8')
read()
seg_list= ①
f=collections.Counter(seg_list)
wcg.fit_words(f)
wcg.to_file('output/b.png')
划线处①语句是调用jieba对象的cut函数对变量为text的文件进行分词,则该处语句为 。
(4)得到的标签云如图所示。
该图片的文件名是 ,表现该文本特征的是 。(至少写出3个)
专题综合练
题组一
1.(2023十校联盟联考,5)近年来,各地相继出现了一些无人售货超市,其购物流程为:通过微信号/支付宝注册→扫码或扫脸开门→选购商品→结算区显示屏清单确认(智能检测)→开门即走(智能扣款)。整个过程快捷方便,达到无感支付。超市内24小时利用摄像头监控,实行人脸识别防盗监控,发现有小偷将自动抓拍报警并列入黑名单,通过RFID技术+核心软件算法有效识别和定位货损源头,并进行有效处理和防范。此外,超市也会依靠大数据、云计算技术,对各种商品的销售状况进行汇总分析,并智能判断客户的购买习惯进行产品推荐,还能预测销售走势,给商家提供合理的建议。
根据阅读材料,下列说法正确的是( )
A.汇总分析已完成的商品销售状况数据属于流数据
B.无人售货超市依靠大数据处理只需要分析最近几个月的抽样数据
C.根据客户账号的购买习惯进行产品推荐,不需要知道用户购买商品的原因
D.无人售货超市中的每一个数据都来自真实数据,体现了大数据价值密度高的特点
2.(2023舟山高二期末,12)小明用下列Python程序将图a处理成图b所示效果,发现处理后的图像不理想,他要想将图像处理成图c所示效果,则可做的修改是( )
from PIL import Image#第0行
import numpy as np#第1行
import matplotlib.pyplot as plt#第2行
img=np.array(Image.open ('dj.jpg').convert('L'))#第3行
row,cols=img.shape#第4行
for i in range(row):#第5行
for j in range(cols):#第6行
if img[i,j]>188:#第7行
img[i,j]=1 #1表示白色#第8行
else:#第9行
img[i,j]=0 #0 表示黑色
#第10行
plt.figure('dj')#第11行
plt.imshow(img,cmap='gray')
#第12行
plt.axis('off')#第13行
plt.show ()
A.将第7行中的数字188改成138
B.将第7行中的数字188改成250
C.将第7行中的>改成<
D.将第8行的代码与第10行的代码互换
3.(2022杭州重点中学期中,13)小萧从国家统计局网站上收集了近几年国民总收入相关数据,并使用Excel软件进行相关数据处理与分析。部分界面如图a所示,请回答下列问题:
(1)下列关于数据整理的描述,正确的是 (单选)。
A.某些缺失的数据可以自己随意估计一个值进行补充
B.Excel表格中的异常数据可以直接删除或忽略
C.Excel表格中的重复数据可以进行合并或删除
D.Excel中格式不一致的数据,一般只保留一种格式的数据,删除其他格式的数据
(2)图b的图表数据类型为 (选填:柱形图/条形图/折线图)。
图b
(3)根据表格数据呈现,从2017年开始可以计算国民总收入增长比例,方法是在C8单元格输入公式 (计算公式:(当年国民总收入-去年国民总收入)/去年国民总收入),设置百分比格式后自动填充至F8单元格。
(4)除了Excel,可以进行数据分析的软件还有 (多选,填数字)。
①Word ②SPSS ③SAS ④MATLAB
⑤记事本 ⑥Python ⑦录音机
4.(2022杭州八县市区期末,16)某次测试的Excel文件成绩表如图1所示。
图1
(1)已知有200名同学参加了本次测试。小明想把全体同学的信息平均分放在D202单元格,那么在 D202单元格输入的公式为 。
(2)现在要求用Python增加“总分”列数据,然后求每个班总分的平均分(如图2),最后绘制每班总分平均分的垂直柱形图(如图3)。请在程序划线①②处选择合适的代码(填字母)。
图2
图3
import pandas as pd
import matplotlib.pyplot as plt
#图表中文显示处理,代码略
df=pd.read_excel("test.xlsx")
score=[]
for i in df.values:
js= ① #①处请选择(填字母): A.df["信息"]+df["通用"]/B.i[3]+i[4]
score.append(js)
df["总分"]=score
df1=df.groupby("班级".as_index=False)["总分"].mean()
plt.title("期中技术平均分")
plt. ② (df1["班级"],df1["总分"],width=0.5)#②处请选择(填字母):
A.plot/B.bar/C.scatter
5.(2022丽水期末,13)小明收集了本周信息技术学科学习评价的数据,如图所示。
(1)观察上表小明做了如下操作,其中属于数据整理的是 (多选,填字母)。
A.删除重复行第五行
B.验证并修改D2单元格数据
C.通过公式计算全班平均分
D.重新设置C3单元格格式
(2)为了分析每个组的平均分,设计了如下Python程序。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("成绩表.xlsx")
print(df1)
划线处的代码应为 (单选,填字母)。
A.df1=df.groupby("平均分").mean()
B.df1=df.mean()
C.df1=df.groupby("小组").mean()
D.df1=df["小组"].mean()
(3)利用Python程序绘制各小题得分率图表,如图所示。
请在划线处填写合适的代码。
num=int(input("请输入小组:"))
plt.figure(figsize=(10,5))
list=[]
for i in range(12):
s="题"+str(i+1)
list.append(df1.at[num,s]*50)
plt.bar(range(1,13),list)
plt.title(str(num)+" ")
plt.xlabel("question number")
plt.ylabel("correct rate")
plt.show()
6.(2024届A9协作体返校考,14)张三同学收集了一个地区8月各类共享单车的骑行数据记录,每天的用户数据存储于“shared bikes. xlsx”文件中,不考虑跨天数据。数据格式如图a所示,请回答下列问题:
(1) cal函数功能为:读取骑行时间的小时和分钟部分,转换为分钟格式并返回,如“2022/8/20 6:57”获取“6:57”转换为417 (6*60+57=417), 代码如下。请在划线处填入合适的代码。
def cal(s):
n=len(s)
for i in range(n):
if s[i]==" ": #如果为空格字符
p=i
if s[i]==":":
q=i
t= + int(s[q+1:])
return t
(2)统计本月各类型单车的每天平均骑行时长,并绘制柱形图,代码如下,绘制的图表如图b所示,请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel ("shared bikes.xlsx")
bike=["哈罗单车","摩拜单车","美团单车","青桔单车"]
sm=[0]*4
avg=[0]*4
days=31
for i in ① :
t=cal(df.at[i, "结束时间"]) - cal (df. at[i, "开始时间"])
for j in range(4):
if df.at[i,"App 类型”]==bike[j]:
②
break
for i in range(4):
avg[i]=sm[i]/ days
plt.figure(figsize=(12, 4))
x=bike
y= ③
plt.bar(x, y)
plt.show()
(3)统计本月各类型单车的骑行次数,加框处代码有错,可以改正为 (选填字母:A.max()/B.min()/C.mean()/D.count())。
n=df. groupby("App类型",as_ index=True).用户编号.sum ()
7.(2024届绍兴诊断性测试,14)学校暑期开展“青春迎亚运”活动,邀请高二学生每日参加运动锻炼并进行线上打卡。每周收集一次相关数据,分别保存在相应的xlsx文件中,部分文件如图a所示。每个文件记录了一周7天的打卡数据,示例如图b所示,其中运动时长单位为分钟。
为统计分析学生锻炼情况,给出周报数据,编写Python程序,请回答以下问题:
(1)定义px函数,功能为:读取某一周的打卡数据,将其按班级进行排序操作并返回结果。
函数代码如下,将划线处代码补充完整。
import pandas as pd
def px(file_week):
df=pd.read_excel(file_week)
df=df.sort_values( ,ignore_index=True)
#按班级升序排序,参数ignore_index=True表示更新索引
return df
(2)统计某一周各运动项目的参与人次,并绘制柱形图,如图c所示,部分Python代码如下:
import matplotlib.pyplot as plt
s=input("请输入文件名: ")
df=px(s)
df1=df.groupby("运动项目".as_index=False). ① #统计各运动项目参与人次
df1.rename(columns={"学号":"参与人次"},inplace=True) #更改列标题
plt.bar( ② )
plt.xlabel("运动项目")
plt.ylabel("参与人次")
plt.show()
划线处应填入的代码为 (单选,填字母)。
A.①count() ②df1["参与人次"], df1["运动项目"]
B.①sum() ②df1["参与人次"], df1["运动项目"]
C.①sum() ②df1.运动项目, df1.参与人次
D.①count() ②df1.运动项目, df1.参与人次
(3)统计某一周每班各学生的总运动时长后,比较得出该周每班最高的两位时长,部分Python程序代码如下,请在划线处填入合适的代码。
qp=[[0 for i in range(m)]for j in range(n)]
'''
定义数组qp记录每班各学生一周运动总时长,n为班级数,m为每班人数。其中qp[0][0]~qp[0][m-1]存储1班1号~m号同学的每周运动总时长,依次类推,qp[n-1][0]~qp[n-1][m-1]存储n班1号~m号同学的每周运动总时长。
'''
print("本周每班最高的两位时长分别为: ")
i=0
while i num=df["学号"][i]
cla=df["班级"][i]
①
if i!=0 and df["班级"][i]!=df["班级"][i-1] or ② :
cla=df["班级"][i-1]
k1=0;k2=0
for j in range(1,len(qp[cla-1])):
if qp[cla-1][j]>qp[cla-1][k1]:
③
k1=j
elif qp[cla-1][j]>qp[cla-1][k2]:
k2=j
print(cla,"班",qp[cla-1][k1].qp[cla-1][k2])
i=i+1
(4)统计某一周各运动项目的参与人次后绘制柱形图如图c所示,由图可知,该周参与人气最高的运动项目为 。
8.(2024届宁波模拟,13)已知某年级有6个班级,所有学生名单存储在文件“name.csv”中(如图1),学校举行某趣味活动项目中,需要每个班抽3名代表参加比赛,请编写一个随机抽取程序,执行效果如图2。请回答以下问题:
(1)加框处代码的作用是 。
(2)实现上述功能的部分Python程序如下,请在划线处填写合适的代码。
import csv
import random #数据读入
f=open("name.csv","r")
flines=csv.reader(f)
name_list=[]
m=6 #班级总数
total=18 #参赛总人数
for line in flines:
if line[0]=="班级":
continue #跳过当前循环的剩余语句,继续进行下一次循环
name_list.append(line)
①
flag=[False]*n
grade=[3]*m
i=0
while i p=random.randint( ② , ③ )
bj=int(name_list[p][0])
if flag[p]==False:
if grade[bj-1]>0:
flag[p]=True
④
i+=1
print("抽取名单为: ")
print("班级","姓名")
for i in range(n):
if flag[i]:
print(name_list[i][0],name_list[i][1])
f.close()
9.(2023杭州地区重点中学联考,14)小明利用“在线社团报名系统”收集了全校学生的社团报名信息,并将报名数据导出到“社团报名.xlsx”中,如图1所示。然后编写Python程序对报名数据进行处理,生成分别以班级名和社团名为文件名的 Excel 文件,以便分发给相应的社团指导老师和班主任。
(1)在对表格进行数据整理时发现,关于“Jacky.Y” 同学的记录可能存在的数据问题是 (选填:A.数据缺失 B.数据异常 C.逻辑错误 D.数据格式不一致)。
(2)其中生成每个社团名单文件的过程是:先对报名数据按社团名称进行分类,并对选报同一社团的学生按班级进行升序排序,然后生成各个社团名单文件,如图 2所示。对应的程序代码如下,请在划线处填写合适的代码。
import pandas as pd
def read_file(filename):
#读入报名数据的原始文件,并将表中的数据转换成列表,代码略
def save_file(a): #保存名单到相应社团的Excel电子表格文件
df=pd.DataFrame(a,columns=["班级","姓名","选报社团"])
df.to_excel( ① )+".xlsx",index=False)
a=read_file("社团报名.xlsx")
n=len(a)
#按社团名(参照拼音的字母顺序)进行升序排序,代码略
#统计各社团人数,存在列表 rs 中,rs=[["滑板社",36],…],代码略
s=0
for i in range(len(rs)):
②
left,right=s, s+num-1
while left < right:
imin=imax=left
for k in range(left+1,right+1):
if a[k][0] < a[imin][0]:
imin=k
elif a[k][0] > a[imax][0]:
imax=k
if imin !=left:
a[imin],a[left]=a[left],a[imin]
if imax==left:
③
if imax !=right:
a[imax],a[right]=a[right],a[imax]
left=left+1; right=right-1
④
s+=num
题组二
1.(2022诸暨期末,4)使用pandas编程处理数据DF1,下列选项能实现行列转置操作的是( )
A.DF1.T B.DF1.columns
C.DF1.values D.DF1.index
2.(2022宁波奉化期末,9) 有如下Python程序段:
import pandas as pd
s=pd.Series(range(5,11,3))
s[1]=15
print(s)
该程序执行后,输出的结果是( )
1 15 2 8 dtype: int64 0 5 1 15 dtype: int64 1 15 2 8 3 11 dtype: int64 0 5 1 15 2 11 dtype: int64
A. B. C. D.
3.(2022宁波咸祥中学期中,16)小明收集了某超市饮料销售情况相关数据,并使用Excel软件进行处理,如图a所示。
请回答下列问题:
(1) 区域 I3:I15 的数据是通过公式计算得到的。在I3单元格输入公式后, 用自动填充功能完成 I4:I15 的计算,则I3单元格中的公式是 。 (占销售总额百分比=销售额(元)/销售总额(元))
(2)若因误操作将 I16 单元格删除,则 I3 单元格会显示 (选填字母:A.#VALUE B.#DIV/0! C.###### D.#REF! )。
(3)要将类别为“可乐”的饮料以“毛利润(元)”为主要关键字降序排序, 则选择排序的区域为 。
(4)小王根据图 a 中的数据,制作了一张反映橙汁类饮料销售额和毛利润对比的图表,如图b 所示,则建立该图表的数据区域是 。将E8单元格数值修改成6.00,是否会影响该图表 (选填:是/否)
图b
4.(2022台州启超中学期中,16)APP活跃人数数据存储在“app.xlsx”文件中,如图所示,现要编程统计结果,请回答下列问题:
若要把“app.xlsx”第1张工作表中的信息导入到book1对象中,并进行统计,实现这个功能的Python代码如下,在程序划线处填入合适的代码。
import pandas as pd
book1= (1) #读取app.xlsx文件数据,并存储在book1对象中
book1_sum= (2)
#计算10月人数之和
book1_aver= (3)
#计算11月人数平均值
book1_g= (4)
#按应用领域分组统计
book1_sort= (5)
#按11月人数值,降序排序
print("10月人数之和:",book1_sum)
print("11月人数平均值:",book1_aver)
5.(2022宁波奉化期末,14)小孙收集了2016年到2020年的各地区粮食生产总量并存储在“lscl.xlsx”文件中,如图a所示,现使用Python对其进行数据处理,并实现数据可视化,绘制的图表如图b所示。
实现如上功能的代码如下,请回答以下问题。
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family': 'SimHei'})
#设置中文字体
df=pd.read_excel("lscl.xlsx")
df. ① ("2020年",ascending=False,inplace=True)
df1=df.head(10)
x= ②
y=df1["2020年"]
plt.figure(figsize=(8,6))
plt. ③ ("2020年粮食产量TOP10")
plt.bar(x,y,label="2020年")
plt.xlabel("地区")
plt.legend()
④
(1)请在划线处填入合适的代码语句,以实现以上功能。
(2)代码语句“plt.bar(x,y,label="2020年")”的功能为绘制如图b所示的图像,能够实现相同功能的语句是 (多选题,少选得1分,多选不得分)。
A.df.head(10).plot("地区","2020年")
B.df[:10:].plot("地区","2020年",kind="bar")
C.plt.plot(x,y,label="2020年",kind="bar")
D.plt.bar("地区","2020年",label="2020年")
E.df1.plot("地区","2020年",kind="bar")
6.(2022杭州场口中学、桐庐富春中学检测,16)在月考之后,学校教务员拿到了高一年级月考的基础成绩并用Excel软件进行数据处理,如图1所示。请回答下列问题:
图1
(1)区域M2:M645的数据是通过在M2单元格输入公式并自动填充得到的,则M645单元格中的公式是 。
(2)为了分析各班级的数学平均分,设计了如下Python程序,利用其绘制各班数学平均分图表,如图2所示:
结合上图的效果,请在程序划线处填写合适的代码。
import matplotlib.pyplot as plt
import pandas as pd
df=pd.read_excel('高一月考成绩.xlsx')
df1=df.groupby("班级"). ①
plt.bar(df1.index, ② )
plt.title("高一各班数学平均分")
plt.ylim(40,100)
plt.xlabel( ③ )
plt.ylabel("分数")
plt.show()
7.(2023 三月百校联考,14)李明收集了梅西2004年至2022年俱乐部比赛数据,保存在“梅西俱乐部详细比赛数据.xlsx”文件中,部分数据如图a所示,现在利用pandas模块处理数据。
(1)梅西2004年10月—2021年7月效力于巴塞罗那俱乐部,2021年8月转会至巴黎圣日耳曼俱乐部,现在李明想知道梅西每个赛季的胜率,实现上述功能的Python程序如下,请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("梅西俱乐部详细比赛数据.xlsx")
df['年']=pd.to_datetime(df["时间"]).dt.strftime('%Y').astype(int)
df['月']=pd.to_datetime(df["时间"]).dt.strftime('%m').astype(int)
df['胜负情况']=" "
for i in range(len(df)):
f=True;z=0;k=0
for c in df["比分"][i]:
if ① :
if f:
z=z*10+int(c)
else:
k=k*10+int(c)
else:
f=not f
jlb="巴塞罗那"
if df["年"][i]*100+df["月"][i]>=202108:
②
if (df["主队"][i]==jlb and z>k) or (df["客队"][i]==jlb and z df['胜负情况'][i]="胜"
elif z==k:
df['胜负情况'][i]="平"
else:
df['胜负情况'][i]="负"
g=df.groupby(df["年"],as_index=True).count()
③
g1=df1.groupby(df1["年"],as_index=True).count()
g["胜率"]=g1["胜负情况"]/g["胜负情况"]*100
(2)图b为2004—2022年梅西俱乐部比赛胜率统计图。
2004-2022年梅西俱乐部比赛胜率统计
plt.plot( , marker='^')
plt.title("2004-2022年梅西俱乐部比赛胜率统计")
plt.show()
方框处代码为 (多选:填字母)。
A.g["年"],g["胜率"] B.g["年"],g.胜率
C.g.index,g["胜率"] D.g.index,g.胜率
8.(2022湖州三贤联盟期中,14)小张同学为了更好地了解冬奥会,从网上收集了历届冬奥会各个项目比赛信息,收集到的部分数据如图1所示。
图1
图2
为分析数据,小张编写了如下程序:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
df=pd.read_csv("dongao.csv")
#删除所有未获得奖牌的记录,并将奖牌列中的"G"修改为"金牌","S"修改为"银牌","B"修改为"铜牌"
jp={'G':'金牌','S':'银牌','B':'铜牌'}
for i in df.index:
if ① :
df=df.drop(i)
else:
df.at[i,'奖牌']=jp[df.at[i,'奖牌']]
#对输入国家每届的奖牌数进行统计,并制作相应图表,如图2所示
nt=input("请输入国家名称:")
df1=df[df['国家']==nt]
df3=pd.DataFrame(df2) #将分组后数据生成新的二维结构,索引为“届次”,列标题为“奖牌”
x=df3.index
y= ②
plt.title(nt+"历届冬奥会奖牌趋势图")
plt. ③ (x,y)
plt.show()
(1)在划线处填上合适的代码。
(2)为了能显示某国历届冬奥会奖牌变化,需在加框处添加的语句为 (多选)。
A.df2=df1.groupby('奖牌')
df2=df1.届次.count()
B.df2=df1.groupby('届次')
df2=df2['奖牌'].count()
C.df2=df1.groupby('奖牌')['届次'].count()
D.df2=df1.groupby('届次').奖牌.count()
9.(2023十校联盟联考,14)小明从网上下载了豆瓣图书1900—2017年间出版的图书数据,存储在Excel文件中,如图a所示,数据表已按出版年份升序排好,包含书名、作者、出版社、出版年份、价格、评分以及评论数量。他要编写一个Python程序快速对图书数据进行分析。
(1)为了求评论数量累计最高的作者及其出版的图书平均评分,小明需要对图a所示的表中数据进行整理,则下列说法正确的是 (多选,填字母)。
A.第3行和第4行数据重复,删除其中一行即可
B.通过检测发现F56168单元格的数据存在错误,应进行修正
C.删除“出版社”和“出版年份”两列数据,不影响分析结果
D.“评分”及“评论数量”为0的数据没有任何价值,可以直接删除
(2)小明利用整理好的数据,编写并运行程序,结果如图b所示。
作者 评论数量
0 [日]村上春树 679101.0
1 [日]东野主吾 664106.0
2 韩寒 623116.0
3 郭敬明 620571.0
4 [英]J.K.罗琳 462476.0
评论数量累计最多的作者是:[日]村上春树 共出版了34部作品,平均评分为8.01
图b
实现上述结果的Python程序如下:
import pandas as pd
df=pd.read_excel("books.xlsx")
df1=df.groupby("作者", as_index=False)
df2=df1.评论数量.sum()
dfsort=df2.sort_values("评论数量" ,ascending=False,ignore_index=True)
print(dfsort.head(5))
#输出评论数量累计前五名作者
top= ①
dfbk=df[df.作者==top]
#根据作者检索出相应的作品
avg=dfbk.评分.mean()
print("评论数量累计最多的作者是:", top)
print("共出版了", ② ,"部作品,平均评分为" , round(avg,2))
则程序中划线①②处应填入的代码为:
① ;
② 。
10.(2024浙江1月选考,14,7分)某学院举行运动会,比赛设跳高、100米等项目,每个项目分男子组和女子组。现要进行报名数据处理和比赛成绩分析。请回答下列问题:
(1)运动会报名规则为:对于每个项目的男子组和女子组,每个专业最多各报5人(如“软件工程”专业在男子跳高项目中最多报5人)。软件工程专业的报名数据保存在DataFrame对象df中,如图a所示。若要编写Python 程序检查该专业男子跳高项目报名是否符合规则,下列方法中, 正确的是 (单选,填字母)。
A.从df中筛选出性别为“男”的数据dfs, 再从dfs中筛选出项目为“跳高”的数据,判断筛选出的数据行是否超过5行
B.对df中数据按性别排序并保存到dfs中,再从dfs中筛选出项目为“跳高”的数据,判断筛选出的数据行是否超过5行
C.从df中筛选出项目为“跳高”的数据dfs,判断dfs中是否有连续5行以上的男生数据
(2)运动员比赛成绩的部分数据如图b所示。根据已有名次计算得分,第1名至8名分别计9,7,6,5,4,3,2,1分,第8名之后计0分。实现上述功能的部分Python程序如下,请在程序中划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
#读取如图b 所示数据,保存到DataFrame对象df1中,代码略
f=[9,7,6,5,4,3,2,1]
for i in range(0,len(df1)):
rank=df1.at[i,"名次"] #通过行、列标签取单个值
score=0
if rank<=8:
df1.at[i,"得分"]=score
(3)根据上述df1中的得分数据,统计各专业总分,绘制如图c所示的柱形图,实现该功能的部分Python程序如下:
df2=df1.groupby(" ",as_index=False).sum() #分组求和
#设置绘图参数,代码略
plt.bar(x,y) #绘制柱形图
①请在程序中划线处填入合适的代码。
②程序的方框中应填入的正确代码为 (单选,填字母)。
A.x=df1["专业"]
y=df1["总分"]
B.x=df2["专业"]
y=df2["得分"]
C.df1["专业"]="专业"
df1["总分"]="总分"
D.df2["专业"]="专业"
df2["得分"]="得分"
专题三 数据处理与应用
考点过关练
考点一 常用表格数据的处理
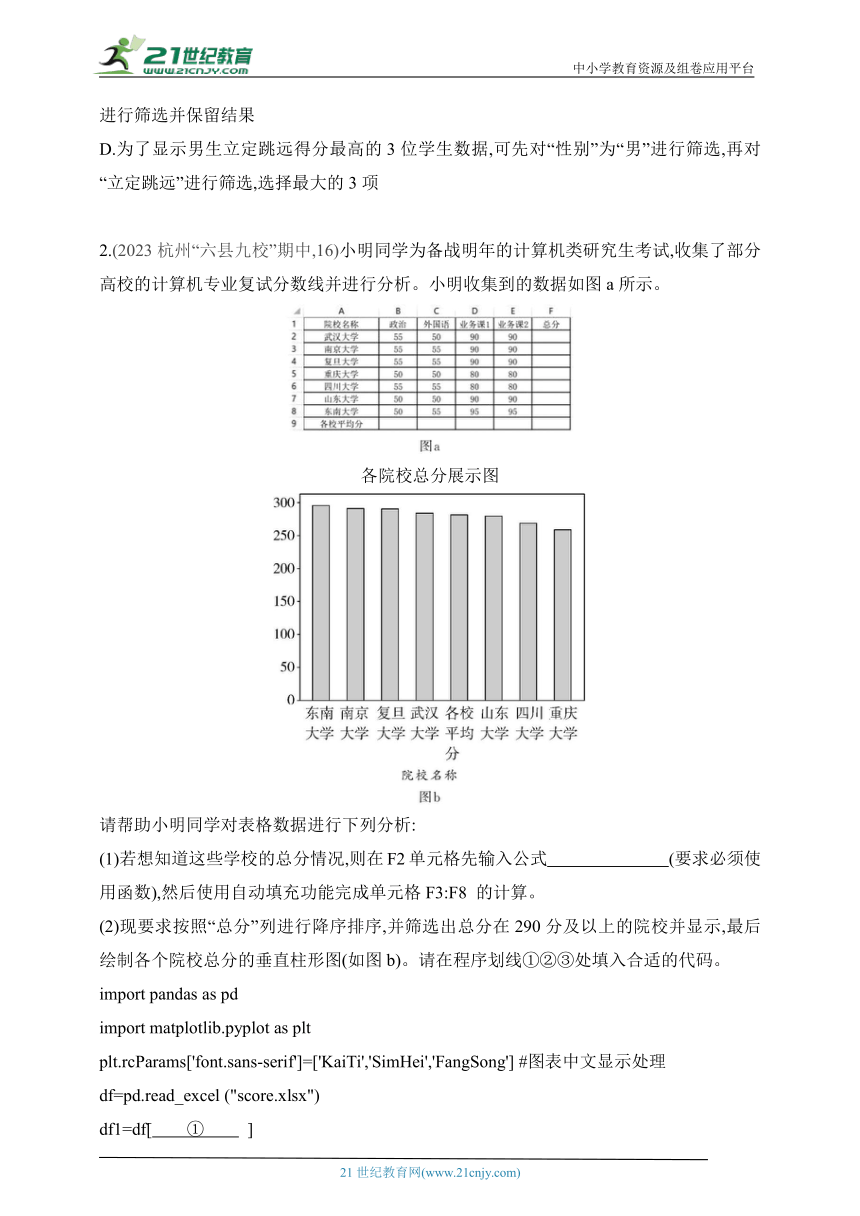
1.(2022诸暨海亮高中期中,16)为了响应全民健身计划,某高中对学生进行了体质健康测评,并用Excel软件进行数据处理,如图a所示。
图a
请回答下列问题:
(1)区域M2:P15 的数据是通过公式计算得到的,在M2单元格中输入公式后,再使用自动填充功能完成该区域的计算,则N3单元格中的公式是“=SUMPRODUCT(( )*($I$3:$I$553=N$1))”。
(提示:M2单元格输入公式=SUMPRODUCT((A1:A100=“2”)*(I1:I100=“优秀”)),表示同时满足A1:A100是2班和I1:I100是优秀这两个条件的情况数量,也就是进行条件计数。)
(2)根据图a中的数据制作的图表如图b所示。创建该图表的数据区域是 。
图b
(3)对图a工作表进行相关数据分析,下列说法正确的是 (多选,填字母)。
A.以“总分等级”为依据进行升序排序,选择的区域是A3:I553
B.选择“A3:I553”按照“总分等级”升序排序后,图 b 的图表不会发生改变
C.现需要选出总分等级为“不及格”的学生,可选择区域A3:I553,以“总分等级”为“不及格”进行筛选并保留结果
D.为了显示男生立定跳远得分最高的3位学生数据,可先对“性别”为“男”进行筛选,再对“立定跳远”进行筛选,选择最大的3项
答案 (1)$A$3:$A$553=$K3 (2)M1:P1,M16:P16
(3)ABC
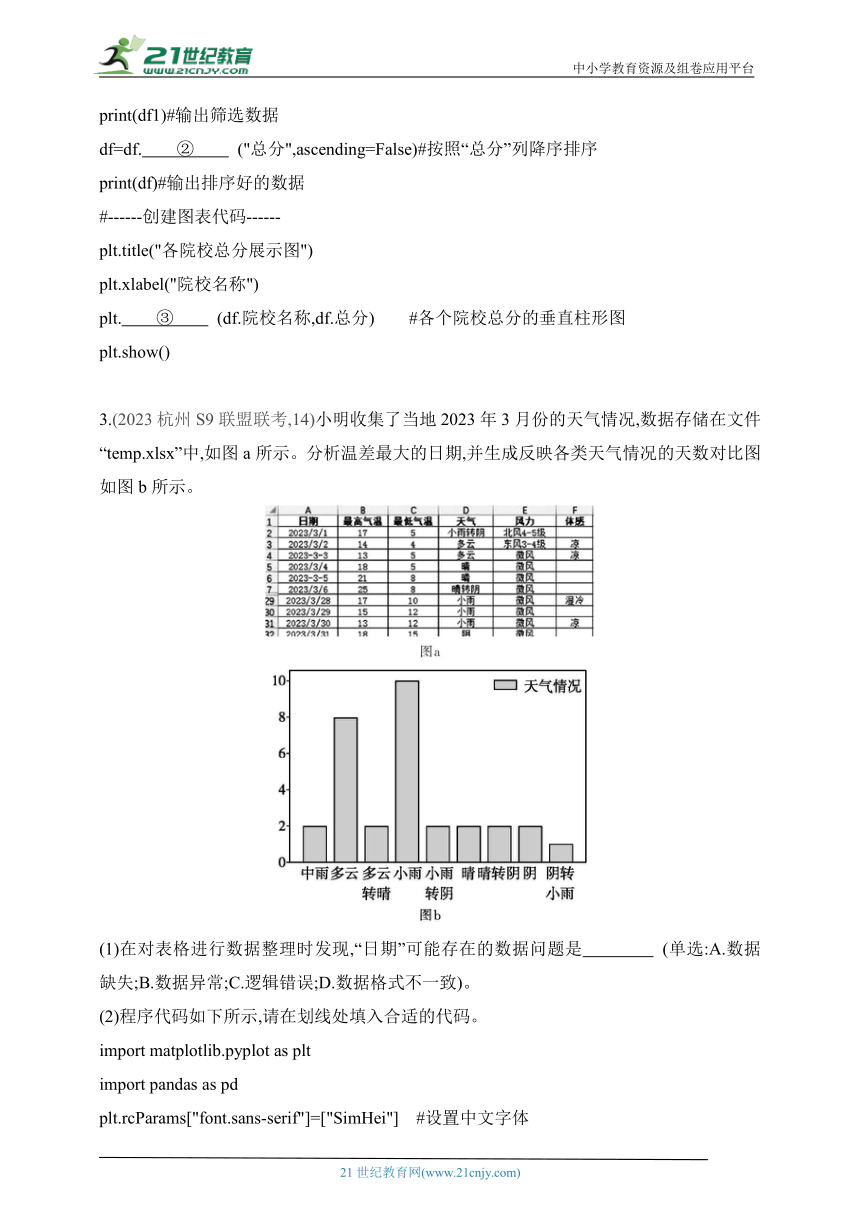
2.(2023杭州“六县九校”期中,16)小明同学为备战明年的计算机类研究生考试,收集了部分高校的计算机专业复试分数线并进行分析。小明收集到的数据如图a所示。
各院校总分展示图
请帮助小明同学对表格数据进行下列分析:
(1)若想知道这些学校的总分情况,则在F2单元格先输入公式 (要求必须使用函数),然后使用自动填充功能完成单元格F3:F8 的计算。
(2)现要求按照“总分”列进行降序排序,并筛选出总分在290分及以上的院校并显示,最后绘制各个院校总分的垂直柱形图(如图b)。请在程序划线①②③处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['KaiTi','SimHei','FangSong'] #图表中文显示处理
df=pd.read_excel ("score.xlsx")
df1=df[ ① ]
print(df1)#输出筛选数据
df=df. ② ("总分",ascending=False)#按照“总分”列降序排序
print(df)#输出排序好的数据
#------创建图表代码------
plt.title("各院校总分展示图")
plt.xlabel("院校名称")
plt. ③ (df.院校名称,df.总分) #各个院校总分的垂直柱形图
plt.show()
答案 (1)=SUM (B2:E2) (2)①df.总分>=290或者df["总分"]>=290 ②sort_values ③bar
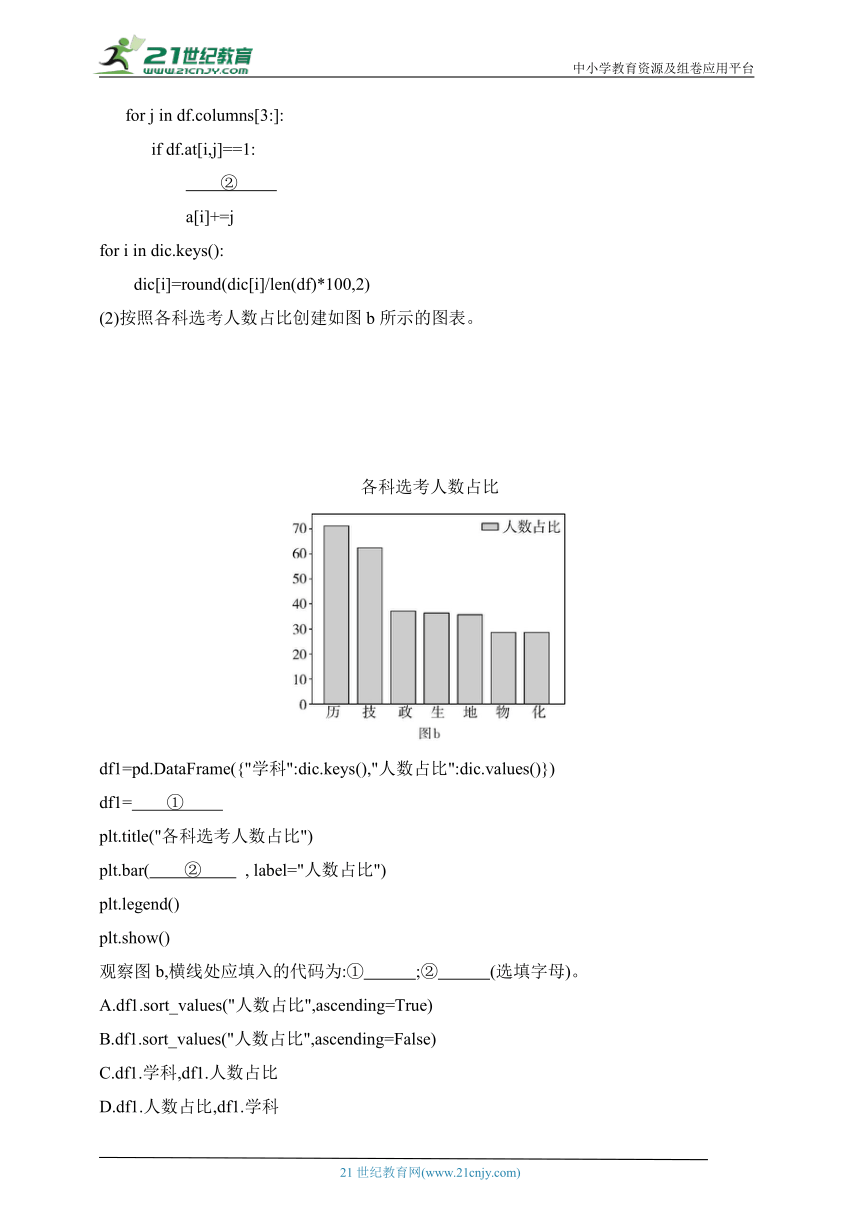
3.(2023杭州S9联盟联考,14)小明收集了当地2023年3月份的天气情况,数据存储在文件“temp.xlsx”中,如图a所示。分析温差最大的日期,并生成反映各类天气情况的天数对比图如图b所示。
(1)在对表格进行数据整理时发现,“日期”可能存在的数据问题是 (单选:A.数据缺失;B.数据异常;C.逻辑错误;D.数据格式不一致)。
(2)程序代码如下所示,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams["font.sans-serif"]=["SimHei"] #设置中文字体
df=pd.read_excel("temp.xlsx")
df["温差"]= ① #新增"温差"列
s=df.sort_values("温差", ascending=False, ignore_index=True)
df_max= ② #获取温差最大的日期,如并列只输出第一个日期
print(df_max)
df_t=s.groupby("天气", as_index=False).count()
df_t=df_t.rename(columns={"日期": "天数"}) #修改列名"日期"为"天数"
x=df_t["天气"]
y=df_t["天数"]
③ (x, y, label="天气情况")
plt.legend()
plt.show()
(3)观察图b,3月份天数最多的天气类型是 。
答案 (1)D (2)①df["最高气温"]-df["最低气温"]
②s["日期"][0]或 s.at[0,"日期"] ③plt.bar (3)小雨
4.(2023杭州地区重点中学期中,15)某中学高一年级完成一次7选3意向调查,数据存储在“xk73.xlsx”中,如图a所示,其中1代表选择科目,0代表弃选科目。
(1)使用 pandas 编程计算本次选课各门课人数占总人数的比例, 请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#图表显示中文
df=pd.read_excel (" ① ")
a=[" "]*len(df) #存储每个学生的选课组合
dic={"物":0,"化":0,"生":0,"政":0,"历":0,"地":0,"技":0}
for i in df.index:
for j in df.columns[3:]:
if df.at[i,j]==1:
②
a[i]+=j
for i in dic.keys():
dic[i]=round(dic[i]/len(df)*100,2)
(2)按照各科选考人数占比创建如图b所示的图表。
各科选考人数占比
df1=pd.DataFrame({"学科":dic.keys(),"人数占比":dic.values()})
df1= ①
plt.title("各科选考人数占比")
plt.bar( ② , label="人数占比")
plt.legend()
plt.show()
观察图b,横线处应填入的代码为:① ;② (选填字母)。
A.df1.sort_values("人数占比",ascending=True)
B.df1.sort_values("人数占比",ascending=False)
C.df1.学科,df1.人数占比
D.df1.人数占比,df1.学科
(3)小李同学想查询某种七选三组合有多少人。以下程序代码可以为小李同学提供查询功能,程序运行示例如图c所示,请在划线处填入合适的代码。
请输入需要查询的选课组合:物化技
选择物化技组合的同学共有:192人
图c
cx=input("请输入需要查询的选课组合:")
cnt=0
for i in range(len(a)):
if :
cnt=cnt+1
print(f"选择{cx}组合的同学共有: {cnt}人")
答案 (1)①xk73.xlsx ②dic[j]+=1 (2)①B ②C (3)a[i]==cx或其他等价表达式
5.(2023浙江1月选考,14,9分)小红收集了部分城市2021年全年每天PM2.5、PM10、CO浓度数据,每天的数据分别保存在以8位日期字符串命名的CSV文件中,部分文件如图a所示,每个文件记录了一天24小时的监测数据,示例如图b所示。
为统计分析城市A全年各月份PM2.5的月平均浓度(当月的日平均浓度的平均值),编写Python程序。请回答下列问题:
(1)定义pmday函数,功能为:读取某天的CSV文件,返回城市A当天PM2.5的日平均浓度。函数代码如下,划线处应填入的代码为 (单选,填字母)。
A.df['类型']=='PM2.5'
B.df['类型'=='PM2.5']
C.df[df['类型']]=='PM2.5'
D.df[df['类型']=='PM2.5']
import pandas as pd
def pmday(dayfile):
df=pd.read_csv(dayfile) #读取文件 dayfile 中的数据
df=
return df['城市A'].mean() #返回城市A当天PM2.5的日平均浓度
(2)统计城市A各月份PM2.5的月平均浓度并绘制线形图,部分Python程序如下,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
def tstr(t):
if t<10:
retrun '0'+str(t)
else:
retrun str(t)
pm=[0]*12
mdays=[31,28,31,30,31,30,31,31,30,31,30,31] #2021年每月天数
for m in range(12):
sm=0
mstr=tstr(m+1)
for d in range( ① ):
dstr=tstr(d+1)
dayfile='2021'+ mstr+ dstr+ '.csv'
sd=pmday(dayfile)
②
pm[m]=sm/mdays[m]
x=[1,2,3,4,5,6,7,8,9,10,11,12]
y= ③
plt.plot(x,y) #绘制线形图
#设置绘图参数,显示如图c所示线形图,代码略
(3)城市A 2021年 PM2.5年平均浓度为34.6微克/立方米。由图c可知,城市A 2021年 PM2.5月平均浓度超过年平均浓度的月份共 个。
答案 (1)D (2)①mdays[m] ②sm+=sd ③pm (3)5
考点二 大数据处理
1.(2023宁波三锋期中,2)下列关于大数据与大数据处理的说法,不正确的是( )
A.处理大数据时,一般采用分治思想
B.大数据的处理对象是全体数据,而不是抽样数据
C.大数据的特点是数据量大、速度快、数据类型多、价值密度低
D.Hadoop是一个可运行于大规模计算机集群上的分布式系统基础架构,适用于处理实时数据
答案 D
2.(2023金华十校联考,3)下列有关大数据处理、数据可视化的说法不正确的是( )
A.静态数据是指处理时已收集完成、计算时不会发生改变的数据
B.流数据主要是指不间断地、持续地到达的实时数据
C.图计算是指有关大量图片的计算
D.“各省生产总值占比情况”可以采用饼图或环形图呈现
答案 C
3.有Python程序段如下所示:
import pandas as pd
import numpy as np
a=np.array([1,2,3,4]).reshape(2,2)
df=pd.DataFrame(a)
print(df.at[1,1])
该程序段运行后输出的结果为( )
A.4 B.3 C.2 D.1
答案 A
4.小张收集了近阶段要学习的英文单词,存储为“data.txt”文件,格式如图所示。
处理“data.txt”文件中的英文单词的Python程序段如下所示:
file='data.txt'
word_c=[]
n=0
for word in open(file):
if word[0:1]=="c":
word_c.append(word)
print('字母c开头的单词个数为:',n)
(1)划线处的代码为 。
(2)该程序段运行后,列表word_c中的数据为 。
答案 (1)n=n+1或n+=1 (2)data.txt中所有以小写字母"c"开头的单词
5.请在空格处填写正确的代码,使程序完善。
实现功能:绘制y=x2-2x+1的图象。
#加载numpy模块并取名为np
import numpy as np
#加载matplotlib.pyplot模块并取名为plt
import matplotlib.pyplot as plt
# x在-7到9之间,每隔0.1取一个值
x=np.arange(-7,9,0.1)
① =x**2-2*x+1
plt.plot(x, ② )
plt.title('y=x*x-2*x+1')
plt.xlabel('x')
plt.ylabel('y')
plt. ③
答案 ①y ②y ③show()
6.在网上搜索朱自清的文章《绿》,如图所示。
(1)搜索信息并保存为txt文件,该过程称为 。
(2)“绿.txt”文件的文本类型是 。(填写字母:A.结构化数据/B.半结构化数据/C.非结构化数据)
(3)制作标签云的代码如下:
import collections
import jieba
import wordcloud as wc
import numpy as np
from PIL import Image
wcg=wc.WordCloud(background_color="white",font_path='assets/msyh.ttf')
text=open('data/绿.txt',encoding='utf-8')
read()
seg_list= ①
f=collections.Counter(seg_list)
wcg.fit_words(f)
wcg.to_file('output/b.png')
划线处①语句是调用jieba对象的cut函数对变量为text的文件进行分词,则该处语句为 。
(4)得到的标签云如图所示。
该图片的文件名是 ,表现该文本特征的是 。(至少写出3个)
答案 (1)采集信息 (2)C (3)jieba.cut(text)
(4)b.png;我、的、着、了、绿、你
专题综合练
题组一
1.(2023十校联盟联考,5)近年来,各地相继出现了一些无人售货超市,其购物流程为:通过微信号/支付宝注册→扫码或扫脸开门→选购商品→结算区显示屏清单确认(智能检测)→开门即走(智能扣款)。整个过程快捷方便,达到无感支付。超市内24小时利用摄像头监控,实行人脸识别防盗监控,发现有小偷将自动抓拍报警并列入黑名单,通过RFID技术+核心软件算法有效识别和定位货损源头,并进行有效处理和防范。此外,超市也会依靠大数据、云计算技术,对各种商品的销售状况进行汇总分析,并智能判断客户的购买习惯进行产品推荐,还能预测销售走势,给商家提供合理的建议。
根据阅读材料,下列说法正确的是( )
A.汇总分析已完成的商品销售状况数据属于流数据
B.无人售货超市依靠大数据处理只需要分析最近几个月的抽样数据
C.根据客户账号的购买习惯进行产品推荐,不需要知道用户购买商品的原因
D.无人售货超市中的每一个数据都来自真实数据,体现了大数据价值密度高的特点
答案 C
2.(2023舟山高二期末,12)小明用下列Python程序将图a处理成图b所示效果,发现处理后的图像不理想,他要想将图像处理成图c所示效果,则可做的修改是( )
from PIL import Image#第0行
import numpy as np#第1行
import matplotlib.pyplot as plt#第2行
img=np.array(Image.open ('dj.jpg').convert('L'))#第3行
row,cols=img.shape#第4行
for i in range(row):#第5行
for j in range(cols):#第6行
if img[i,j]>188:#第7行
img[i,j]=1 #1表示白色#第8行
else:#第9行
img[i,j]=0 #0 表示黑色
#第10行
plt.figure('dj')#第11行
plt.imshow(img,cmap='gray')
#第12行
plt.axis('off')#第13行
plt.show ()
A.将第7行中的数字188改成138
B.将第7行中的数字188改成250
C.将第7行中的>改成<
D.将第8行的代码与第10行的代码互换
答案 A
3.(2022杭州重点中学期中,13)小萧从国家统计局网站上收集了近几年国民总收入相关数据,并使用Excel软件进行相关数据处理与分析。部分界面如图a所示,请回答下列问题:
(1)下列关于数据整理的描述,正确的是 (单选)。
A.某些缺失的数据可以自己随意估计一个值进行补充
B.Excel表格中的异常数据可以直接删除或忽略
C.Excel表格中的重复数据可以进行合并或删除
D.Excel中格式不一致的数据,一般只保留一种格式的数据,删除其他格式的数据
(2)图b的图表数据类型为 (选填:柱形图/条形图/折线图)。
图b
(3)根据表格数据呈现,从2017年开始可以计算国民总收入增长比例,方法是在C8单元格输入公式 (计算公式:(当年国民总收入-去年国民总收入)/去年国民总收入),设置百分比格式后自动填充至F8单元格。
(4)除了Excel,可以进行数据分析的软件还有 (多选,填数字)。
①Word ②SPSS ③SAS ④MATLAB
⑤记事本 ⑥Python ⑦录音机
答案 (1)C (2)柱形图 (3)=(C2-B2)/B2
(4)②③④⑥
4.(2022杭州八县市区期末,16)某次测试的Excel文件成绩表如图1所示。
图1
(1)已知有200名同学参加了本次测试。小明想把全体同学的信息平均分放在D202单元格,那么在 D202单元格输入的公式为 。
(2)现在要求用Python增加“总分”列数据,然后求每个班总分的平均分(如图2),最后绘制每班总分平均分的垂直柱形图(如图3)。请在程序划线①②处选择合适的代码(填字母)。
图2
图3
import pandas as pd
import matplotlib.pyplot as plt
#图表中文显示处理,代码略
df=pd.read_excel("test.xlsx")
score=[]
for i in df.values:
js= ① #①处请选择(填字母): A.df["信息"]+df["通用"]/B.i[3]+i[4]
score.append(js)
df["总分"]=score
df1=df.groupby("班级".as_index=False)["总分"].mean()
plt.title("期中技术平均分")
plt. ② (df1["班级"],df1["总分"],width=0.5)#②处请选择(填字母):
A.plot/B.bar/C.scatter
答案 (1)=AVERAGE(D2:D201) (2)①B ②B
5.(2022丽水期末,13)小明收集了本周信息技术学科学习评价的数据,如图所示。
(1)观察上表小明做了如下操作,其中属于数据整理的是 (多选,填字母)。
A.删除重复行第五行
B.验证并修改D2单元格数据
C.通过公式计算全班平均分
D.重新设置C3单元格格式
(2)为了分析每个组的平均分,设计了如下Python程序。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("成绩表.xlsx")
print(df1)
划线处的代码应为 (单选,填字母)。
A.df1=df.groupby("平均分").mean()
B.df1=df.mean()
C.df1=df.groupby("小组").mean()
D.df1=df["小组"].mean()
(3)利用Python程序绘制各小题得分率图表,如图所示。
请在划线处填写合适的代码。
num=int(input("请输入小组:"))
plt.figure(figsize=(10,5))
list=[]
for i in range(12):
s="题"+str(i+1)
list.append(df1.at[num,s]*50)
plt.bar(range(1,13),list)
plt.title(str(num)+" ")
plt.xlabel("question number")
plt.ylabel("correct rate")
plt.show()
答案 (1)ABD (2)C (3)group
6.(2024届A9协作体返校考,14)张三同学收集了一个地区8月各类共享单车的骑行数据记录,每天的用户数据存储于“shared bikes. xlsx”文件中,不考虑跨天数据。数据格式如图a所示,请回答下列问题:
(1) cal函数功能为:读取骑行时间的小时和分钟部分,转换为分钟格式并返回,如“2022/8/20 6:57”获取“6:57”转换为417 (6*60+57=417), 代码如下。请在划线处填入合适的代码。
def cal(s):
n=len(s)
for i in range(n):
if s[i]==" ": #如果为空格字符
p=i
if s[i]==":":
q=i
t= + int(s[q+1:])
return t
(2)统计本月各类型单车的每天平均骑行时长,并绘制柱形图,代码如下,绘制的图表如图b所示,请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel ("shared bikes.xlsx")
bike=["哈罗单车","摩拜单车","美团单车","青桔单车"]
sm=[0]*4
avg=[0]*4
days=31
for i in ① :
t=cal(df.at[i, "结束时间"]) - cal (df. at[i, "开始时间"])
for j in range(4):
if df.at[i,"App 类型”]==bike[j]:
②
break
for i in range(4):
avg[i]=sm[i]/ days
plt.figure(figsize=(12, 4))
x=bike
y= ③
plt.bar(x, y)
plt.show()
(3)统计本月各类型单车的骑行次数,加框处代码有错,可以改正为 (选填字母:A.max()/B.min()/C.mean()/D.count())。
n=df. groupby("App类型",as_ index=True).用户编号.sum ()
答案 (1)int(s[p+1:q])*60 (2)①df.index或range(len(df)) ②sm[j]+=t ③avg (3)D
7.(2024届绍兴诊断性测试,14)学校暑期开展“青春迎亚运”活动,邀请高二学生每日参加运动锻炼并进行线上打卡。每周收集一次相关数据,分别保存在相应的xlsx文件中,部分文件如图a所示。每个文件记录了一周7天的打卡数据,示例如图b所示,其中运动时长单位为分钟。
为统计分析学生锻炼情况,给出周报数据,编写Python程序,请回答以下问题:
(1)定义px函数,功能为:读取某一周的打卡数据,将其按班级进行排序操作并返回结果。
函数代码如下,将划线处代码补充完整。
import pandas as pd
def px(file_week):
df=pd.read_excel(file_week)
df=df.sort_values( ,ignore_index=True)
#按班级升序排序,参数ignore_index=True表示更新索引
return df
(2)统计某一周各运动项目的参与人次,并绘制柱形图,如图c所示,部分Python代码如下:
import matplotlib.pyplot as plt
s=input("请输入文件名: ")
df=px(s)
df1=df.groupby("运动项目".as_index=False). ① #统计各运动项目参与人次
df1.rename(columns={"学号":"参与人次"},inplace=True) #更改列标题
plt.bar( ② )
plt.xlabel("运动项目")
plt.ylabel("参与人次")
plt.show()
划线处应填入的代码为 (单选,填字母)。
A.①count() ②df1["参与人次"], df1["运动项目"]
B.①sum() ②df1["参与人次"], df1["运动项目"]
C.①sum() ②df1.运动项目, df1.参与人次
D.①count() ②df1.运动项目, df1.参与人次
(3)统计某一周每班各学生的总运动时长后,比较得出该周每班最高的两位时长,部分Python程序代码如下,请在划线处填入合适的代码。
qp=[[0 for i in range(m)]for j in range(n)]
'''
定义数组qp记录每班各学生一周运动总时长,n为班级数,m为每班人数。其中qp[0][0]~qp[0][m-1]存储1班1号~m号同学的每周运动总时长,依次类推,qp[n-1][0]~qp[n-1][m-1]存储n班1号~m号同学的每周运动总时长。
'''
print("本周每班最高的两位时长分别为: ")
i=0
while i num=df["学号"][i]
cla=df["班级"][i]
①
if i!=0 and df["班级"][i]!=df["班级"][i-1] or ② :
cla=df["班级"][i-1]
k1=0;k2=0
for j in range(1,len(qp[cla-1])):
if qp[cla-1][j]>qp[cla-1][k1]:
③
k1=j
elif qp[cla-1][j]>qp[cla-1][k2]:
k2=j
print(cla,"班",qp[cla-1][k1].qp[cla-1][k2])
i=i+1
(4)统计某一周各运动项目的参与人次后绘制柱形图如图c所示,由图可知,该周参与人气最高的运动项目为 。
答案 (1)"班级" (2)D (3)①qp[cla-1][num-1]+=df["运动时长"][i] ②i==len(df)-1 ③k2=k1
(4)跑步
8.(2024届宁波模拟,13)已知某年级有6个班级,所有学生名单存储在文件“name.csv”中(如图1),学校举行某趣味活动项目中,需要每个班抽3名代表参加比赛,请编写一个随机抽取程序,执行效果如图2。请回答以下问题:
(1)加框处代码的作用是 。
(2)实现上述功能的部分Python程序如下,请在划线处填写合适的代码。
import csv
import random #数据读入
f=open("name.csv","r")
flines=csv.reader(f)
name_list=[]
m=6 #班级总数
total=18 #参赛总人数
for line in flines:
if line[0]=="班级":
continue #跳过当前循环的剩余语句,继续进行下一次循环
name_list.append(line)
①
flag=[False]*n
grade=[3]*m
i=0
while i p=random.randint( ② , ③ )
bj=int(name_list[p][0])
if flag[p]==False:
if grade[bj-1]>0:
flag[p]=True
④
i+=1
print("抽取名单为: ")
print("班级","姓名")
for i in range(n):
if flag[i]:
print(name_list[i][0],name_list[i][1])
f.close()
答案 (1)列表name_list中的数据不包括标题行
(2)①n=len(name_list) ②0 ③n-1 ④grade[bj-1]-=1
9.(2023杭州地区重点中学联考,14)小明利用“在线社团报名系统”收集了全校学生的社团报名信息,并将报名数据导出到“社团报名.xlsx”中,如图1所示。然后编写Python程序对报名数据进行处理,生成分别以班级名和社团名为文件名的 Excel 文件,以便分发给相应的社团指导老师和班主任。
(1)在对表格进行数据整理时发现,关于“Jacky.Y” 同学的记录可能存在的数据问题是 (选填:A.数据缺失 B.数据异常 C.逻辑错误 D.数据格式不一致)。
(2)其中生成每个社团名单文件的过程是:先对报名数据按社团名称进行分类,并对选报同一社团的学生按班级进行升序排序,然后生成各个社团名单文件,如图 2所示。对应的程序代码如下,请在划线处填写合适的代码。
import pandas as pd
def read_file(filename):
#读入报名数据的原始文件,并将表中的数据转换成列表,代码略
def save_file(a): #保存名单到相应社团的Excel电子表格文件
df=pd.DataFrame(a,columns=["班级","姓名","选报社团"])
df.to_excel( ① )+".xlsx",index=False)
a=read_file("社团报名.xlsx")
n=len(a)
#按社团名(参照拼音的字母顺序)进行升序排序,代码略
#统计各社团人数,存在列表 rs 中,rs=[["滑板社",36],…],代码略
s=0
for i in range(len(rs)):
②
left,right=s, s+num-1
while left < right:
imin=imax=left
for k in range(left+1,right+1):
if a[k][0] < a[imin][0]:
imin=k
elif a[k][0] > a[imax][0]:
imax=k
if imin !=left:
a[imin],a[left]=a[left],a[imin]
if imax==left:
③
if imax !=right:
a[imax],a[right]=a[right],a[imax]
left=left+1; right=right-1
④
s+=num
答案 (1)B (2)①a[0][2]或df.at[0,"选报社团"] 或 df["选报社团"][0] ②num=rs[i][1] ③imax=imin
④save_file(a[s:s+num])
题组二
1.(2022诸暨期末,4)使用pandas编程处理数据DF1,下列选项能实现行列转置操作的是( )
A.DF1.T B.DF1.columns
C.DF1.values D.DF1.index
答案 A
2.(2022宁波奉化期末,9) 有如下Python程序段:
import pandas as pd
s=pd.Series(range(5,11,3))
s[1]=15
print(s)
该程序执行后,输出的结果是( )
1 15 2 8 dtype: int64 0 5 1 15 dtype: int64 1 15 2 8 3 11 dtype: int64 0 5 1 15 2 11 dtype: int64
A. B. C. D.
答案 B
3.(2022宁波咸祥中学期中,16)小明收集了某超市饮料销售情况相关数据,并使用Excel软件进行处理,如图a所示。
请回答下列问题:
(1) 区域 I3:I15 的数据是通过公式计算得到的。在I3单元格输入公式后, 用自动填充功能完成 I4:I15 的计算,则I3单元格中的公式是 。 (占销售总额百分比=销售额(元)/销售总额(元))
(2)若因误操作将 I16 单元格删除,则 I3 单元格会显示 (选填字母:A.#VALUE B.#DIV/0! C.###### D.#REF! )。
(3)要将类别为“可乐”的饮料以“毛利润(元)”为主要关键字降序排序, 则选择排序的区域为 。
(4)小王根据图 a 中的数据,制作了一张反映橙汁类饮料销售额和毛利润对比的图表,如图b 所示,则建立该图表的数据区域是 。将E8单元格数值修改成6.00,是否会影响该图表 (选填:是/否)
图b
答案 (1)=G3/$I$16或=G3/I$16 (2)B (3)B8:I11
(4)B2,G2:H2,B5:B7,G5:H7;否
4.(2022台州启超中学期中,16)APP活跃人数数据存储在“app.xlsx”文件中,如图所示,现要编程统计结果,请回答下列问题:
若要把“app.xlsx”第1张工作表中的信息导入到book1对象中,并进行统计,实现这个功能的Python代码如下,在程序划线处填入合适的代码。
import pandas as pd
book1= (1) #读取app.xlsx文件数据,并存储在book1对象中
book1_sum= (2)
#计算10月人数之和
book1_aver= (3)
#计算11月人数平均值
book1_g= (4)
#按应用领域分组统计
book1_sort= (5)
#按11月人数值,降序排序
print("10月人数之和:",book1_sum)
print("11月人数平均值:",book1_aver)
答案 (1)pd.read_excel("app.xlsx") (2)book1["10月人数"].sum() (3)book1["11月人数"].mean()
(4)book1.groupby("应用领域")
(5)book1.sort_values("11月人数",ascending=False)
5.(2022宁波奉化期末,14)小孙收集了2016年到2020年的各地区粮食生产总量并存储在“lscl.xlsx”文件中,如图a所示,现使用Python对其进行数据处理,并实现数据可视化,绘制的图表如图b所示。
实现如上功能的代码如下,请回答以下问题。
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family': 'SimHei'})
#设置中文字体
df=pd.read_excel("lscl.xlsx")
df. ① ("2020年",ascending=False,inplace=True)
df1=df.head(10)
x= ②
y=df1["2020年"]
plt.figure(figsize=(8,6))
plt. ③ ("2020年粮食产量TOP10")
plt.bar(x,y,label="2020年")
plt.xlabel("地区")
plt.legend()
④
(1)请在划线处填入合适的代码语句,以实现以上功能。
(2)代码语句“plt.bar(x,y,label="2020年")”的功能为绘制如图b所示的图像,能够实现相同功能的语句是 (多选题,少选得1分,多选不得分)。
A.df.head(10).plot("地区","2020年")
B.df[:10:].plot("地区","2020年",kind="bar")
C.plt.plot(x,y,label="2020年",kind="bar")
D.plt.bar("地区","2020年",label="2020年")
E.df1.plot("地区","2020年",kind="bar")
答案 (1)①sort_values ②df1["地区"] 或 df1.地区
③title ④plt.show() (2)BE
6.(2022杭州场口中学、桐庐富春中学检测,16)在月考之后,学校教务员拿到了高一年级月考的基础成绩并用Excel软件进行数据处理,如图1所示。请回答下列问题:
图1
(1)区域M2:M645的数据是通过在M2单元格输入公式并自动填充得到的,则M645单元格中的公式是 。
(2)为了分析各班级的数学平均分,设计了如下Python程序,利用其绘制各班数学平均分图表,如图2所示:
结合上图的效果,请在程序划线处填写合适的代码。
import matplotlib.pyplot as plt
import pandas as pd
df=pd.read_excel('高一月考成绩.xlsx')
df1=df.groupby("班级"). ①
plt.bar(df1.index, ② )
plt.title("高一各班数学平均分")
plt.ylim(40,100)
plt.xlabel( ③ )
plt.ylabel("分数")
plt.show()
答案 (1)=SUM(D645:L645) (2)①mean() ②df1.数学 ③"班级"
7.(2023 三月百校联考,14)李明收集了梅西2004年至2022年俱乐部比赛数据,保存在“梅西俱乐部详细比赛数据.xlsx”文件中,部分数据如图a所示,现在利用pandas模块处理数据。
(1)梅西2004年10月—2021年7月效力于巴塞罗那俱乐部,2021年8月转会至巴黎圣日耳曼俱乐部,现在李明想知道梅西每个赛季的胜率,实现上述功能的Python程序如下,请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("梅西俱乐部详细比赛数据.xlsx")
df['年']=pd.to_datetime(df["时间"]).dt.strftime('%Y').astype(int)
df['月']=pd.to_datetime(df["时间"]).dt.strftime('%m').astype(int)
df['胜负情况']=" "
for i in range(len(df)):
f=True;z=0;k=0
for c in df["比分"][i]:
if ① :
if f:
z=z*10+int(c)
else:
k=k*10+int(c)
else:
f=not f
jlb="巴塞罗那"
if df["年"][i]*100+df["月"][i]>=202108:
②
if (df["主队"][i]==jlb and z>k) or (df["客队"][i]==jlb and z df['胜负情况'][i]="胜"
elif z==k:
df['胜负情况'][i]="平"
else:
df['胜负情况'][i]="负"
g=df.groupby(df["年"],as_index=True).count()
③
g1=df1.groupby(df1["年"],as_index=True).count()
g["胜率"]=g1["胜负情况"]/g["胜负情况"]*100
(2)图b为2004—2022年梅西俱乐部比赛胜率统计图。
2004-2022年梅西俱乐部比赛胜率统计
plt.plot( , marker='^')
plt.title("2004-2022年梅西俱乐部比赛胜率统计")
plt.show()
方框处代码为 (多选:填字母)。
A.g["年"],g["胜率"] B.g["年"],g.胜率
C.g.index,g["胜率"] D.g.index,g.胜率
答案 (1)①c!="-" 或c>="0" and c<="9" ②jlb="巴黎圣日耳曼" ③df1=df[df['胜负情况']=="胜"] (2)CD
8.(2022湖州三贤联盟期中,14)小张同学为了更好地了解冬奥会,从网上收集了历届冬奥会各个项目比赛信息,收集到的部分数据如图1所示。
图1
图2
为分析数据,小张编写了如下程序:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
df=pd.read_csv("dongao.csv")
#删除所有未获得奖牌的记录,并将奖牌列中的"G"修改为"金牌","S"修改为"银牌","B"修改为"铜牌"
jp={'G':'金牌','S':'银牌','B':'铜牌'}
for i in df.index:
if ① :
df=df.drop(i)
else:
df.at[i,'奖牌']=jp[df.at[i,'奖牌']]
#对输入国家每届的奖牌数进行统计,并制作相应图表,如图2所示
nt=input("请输入国家名称:")
df1=df[df['国家']==nt]
df3=pd.DataFrame(df2) #将分组后数据生成新的二维结构,索引为“届次”,列标题为“奖牌”
x=df3.index
y= ②
plt.title(nt+"历届冬奥会奖牌趋势图")
plt. ③ (x,y)
plt.show()
(1)在划线处填上合适的代码。
(2)为了能显示某国历届冬奥会奖牌变化,需在加框处添加的语句为 (多选)。
A.df2=df1.groupby('奖牌')
df2=df1.届次.count()
B.df2=df1.groupby('届次')
df2=df2['奖牌'].count()
C.df2=df1.groupby('奖牌')['届次'].count()
D.df2=df1.groupby('届次').奖牌.count()
答案 (1)①df.at[i,'奖牌']=='0'或 df.奖牌[i]=='0'或 df['奖牌'][i]=='0' ②df3["奖牌"]或 df3.奖牌 ③plot (2)BD
9.(2023十校联盟联考,14)小明从网上下载了豆瓣图书1900—2017年间出版的图书数据,存储在Excel文件中,如图a所示,数据表已按出版年份升序排好,包含书名、作者、出版社、出版年份、价格、评分以及评论数量。他要编写一个Python程序快速对图书数据进行分析。
(1)为了求评论数量累计最高的作者及其出版的图书平均评分,小明需要对图a所示的表中数据进行整理,则下列说法正确的是 (多选,填字母)。
A.第3行和第4行数据重复,删除其中一行即可
B.通过检测发现F56168单元格的数据存在错误,应进行修正
C.删除“出版社”和“出版年份”两列数据,不影响分析结果
D.“评分”及“评论数量”为0的数据没有任何价值,可以直接删除
(2)小明利用整理好的数据,编写并运行程序,结果如图b所示。
作者 评论数量
0 [日]村上春树 679101.0
1 [日]东野主吾 664106.0
2 韩寒 623116.0
3 郭敬明 620571.0
4 [英]J.K.罗琳 462476.0
评论数量累计最多的作者是:[日]村上春树 共出版了34部作品,平均评分为8.01
图b
实现上述结果的Python程序如下:
import pandas as pd
df=pd.read_excel("books.xlsx")
df1=df.groupby("作者", as_index=False)
df2=df1.评论数量.sum()
dfsort=df2.sort_values("评论数量" ,ascending=False,ignore_index=True)
print(dfsort.head(5))
#输出评论数量累计前五名作者
top= ①
dfbk=df[df.作者==top]
#根据作者检索出相应的作品
avg=dfbk.评分.mean()
print("评论数量累计最多的作者是:", top)
print("共出版了", ② ,"部作品,平均评分为" , round(avg,2))
则程序中划线①②处应填入的代码为:
① ;
② 。
答案 (1)BC (2)①dfsort.at[0,"作者"]或dfsort["作者"][0]或其他等价答案 ②len(dfbk)或dfbk.书名.count()或dfbk["书名"].count()
10.(2024浙江1月选考,14,7分)某学院举行运动会,比赛设跳高、100米等项目,每个项目分男子组和女子组。现要进行报名数据处理和比赛成绩分析。请回答下列问题:
(1)运动会报名规则为:对于每个项目的男子组和女子组,每个专业最多各报5人(如“软件工程”专业在男子跳高项目中最多报5人)。软件工程专业的报名数据保存在DataFrame对象df中,如图a所示。若要编写Python 程序检查该专业男子跳高项目报名是否符合规则,下列方法中, 正确的是 (单选,填字母)。
A.从df中筛选出性别为“男”的数据dfs, 再从dfs中筛选出项目为“跳高”的数据,判断筛选出的数据行是否超过5行
B.对df中数据按性别排序并保存到dfs中,再从dfs中筛选出项目为“跳高”的数据,判断筛选出的数据行是否超过5行
C.从df中筛选出项目为“跳高”的数据dfs,判断dfs中是否有连续5行以上的男生数据
(2)运动员比赛成绩的部分数据如图b所示。根据已有名次计算得分,第1名至8名分别计9,7,6,5,4,3,2,1分,第8名之后计0分。实现上述功能的部分Python程序如下,请在程序中划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
#读取如图b 所示数据,保存到DataFrame对象df1中,代码略
f=[9,7,6,5,4,3,2,1]
for i in range(0,len(df1)):
rank=df1.at[i,"名次"] #通过行、列标签取单个值
score=0
if rank<=8:
df1.at[i,"得分"]=score
(3)根据上述df1中的得分数据,统计各专业总分,绘制如图c所示的柱形图,实现该功能的部分Python程序如下:
df2=df1.groupby(" ",as_index=False).sum() #分组求和
#设置绘图参数,代码略
plt.bar(x,y) #绘制柱形图
①请在程序中划线处填入合适的代码。
②程序的方框中应填入的正确代码为 (单选,填字母)。
A.x=df1["专业"]
y=df1["总分"]
B.x=df2["专业"]
y=df2["得分"]
C.df1["专业"]="专业"
df1["总分"]="总分"
D.df2["专业"]="专业"
df2["得分"]="得分"
答案 (1)A (2)score=f[rank-1]或score=f[int(rank)-1] (3)①专业 ②B
21世纪教育网 www.21cnjy.com 精品试卷·第 2 页 (共 2 页)
21世纪教育网(www.21cnjy.com)
2025新教材技术高考第一轮
专题三 数据处理与应用
考点过关练
考点一 常用表格数据的处理
1.(2022诸暨海亮高中期中,16)为了响应全民健身计划,某高中对学生进行了体质健康测评,并用Excel软件进行数据处理,如图a所示。
图a
请回答下列问题:
(1)区域M2:P15 的数据是通过公式计算得到的,在M2单元格中输入公式后,再使用自动填充功能完成该区域的计算,则N3单元格中的公式是“=SUMPRODUCT(( )*($I$3:$I$553=N$1))”。
(提示:M2单元格输入公式=SUMPRODUCT((A1:A100=“2”)*(I1:I100=“优秀”)),表示同时满足A1:A100是2班和I1:I100是优秀这两个条件的情况数量,也就是进行条件计数。)
(2)根据图a中的数据制作的图表如图b所示。创建该图表的数据区域是 。
图b
(3)对图a工作表进行相关数据分析,下列说法正确的是 (多选,填字母)。
A.以“总分等级”为依据进行升序排序,选择的区域是A3:I553
B.选择“A3:I553”按照“总分等级”升序排序后,图 b 的图表不会发生改变
C.现需要选出总分等级为“不及格”的学生,可选择区域A3:I553,以“总分等级”为“不及格”进行筛选并保留结果
D.为了显示男生立定跳远得分最高的3位学生数据,可先对“性别”为“男”进行筛选,再对“立定跳远”进行筛选,选择最大的3项
2.(2023杭州“六县九校”期中,16)小明同学为备战明年的计算机类研究生考试,收集了部分高校的计算机专业复试分数线并进行分析。小明收集到的数据如图a所示。
各院校总分展示图
请帮助小明同学对表格数据进行下列分析:
(1)若想知道这些学校的总分情况,则在F2单元格先输入公式 (要求必须使用函数),然后使用自动填充功能完成单元格F3:F8 的计算。
(2)现要求按照“总分”列进行降序排序,并筛选出总分在290分及以上的院校并显示,最后绘制各个院校总分的垂直柱形图(如图b)。请在程序划线①②③处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['KaiTi','SimHei','FangSong'] #图表中文显示处理
df=pd.read_excel ("score.xlsx")
df1=df[ ① ]
print(df1)#输出筛选数据
df=df. ② ("总分",ascending=False)#按照“总分”列降序排序
print(df)#输出排序好的数据
#------创建图表代码------
plt.title("各院校总分展示图")
plt.xlabel("院校名称")
plt. ③ (df.院校名称,df.总分) #各个院校总分的垂直柱形图
plt.show()
3.(2023杭州S9联盟联考,14)小明收集了当地2023年3月份的天气情况,数据存储在文件“temp.xlsx”中,如图a所示。分析温差最大的日期,并生成反映各类天气情况的天数对比图如图b所示。
(1)在对表格进行数据整理时发现,“日期”可能存在的数据问题是 (单选:A.数据缺失;B.数据异常;C.逻辑错误;D.数据格式不一致)。
(2)程序代码如下所示,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams["font.sans-serif"]=["SimHei"] #设置中文字体
df=pd.read_excel("temp.xlsx")
df["温差"]= ① #新增"温差"列
s=df.sort_values("温差", ascending=False, ignore_index=True)
df_max= ② #获取温差最大的日期,如并列只输出第一个日期
print(df_max)
df_t=s.groupby("天气", as_index=False).count()
df_t=df_t.rename(columns={"日期": "天数"}) #修改列名"日期"为"天数"
x=df_t["天气"]
y=df_t["天数"]
③ (x, y, label="天气情况")
plt.legend()
plt.show()
(3)观察图b,3月份天数最多的天气类型是 。
4.(2023杭州地区重点中学期中,15)某中学高一年级完成一次7选3意向调查,数据存储在“xk73.xlsx”中,如图a所示,其中1代表选择科目,0代表弃选科目。
(1)使用 pandas 编程计算本次选课各门课人数占总人数的比例, 请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#图表显示中文
df=pd.read_excel (" ① ")
a=[" "]*len(df) #存储每个学生的选课组合
dic={"物":0,"化":0,"生":0,"政":0,"历":0,"地":0,"技":0}
for i in df.index:
for j in df.columns[3:]:
if df.at[i,j]==1:
②
a[i]+=j
for i in dic.keys():
dic[i]=round(dic[i]/len(df)*100,2)
(2)按照各科选考人数占比创建如图b所示的图表。
各科选考人数占比
df1=pd.DataFrame({"学科":dic.keys(),"人数占比":dic.values()})
df1= ①
plt.title("各科选考人数占比")
plt.bar( ② , label="人数占比")
plt.legend()
plt.show()
观察图b,横线处应填入的代码为:① ;② (选填字母)。
A.df1.sort_values("人数占比",ascending=True)
B.df1.sort_values("人数占比",ascending=False)
C.df1.学科,df1.人数占比
D.df1.人数占比,df1.学科
(3)小李同学想查询某种七选三组合有多少人。以下程序代码可以为小李同学提供查询功能,程序运行示例如图c所示,请在划线处填入合适的代码。
请输入需要查询的选课组合:物化技
选择物化技组合的同学共有:192人
图c
cx=input("请输入需要查询的选课组合:")
cnt=0
for i in range(len(a)):
if :
cnt=cnt+1
print(f"选择{cx}组合的同学共有: {cnt}人")
5.(2023浙江1月选考,14,9分)小红收集了部分城市2021年全年每天PM2.5、PM10、CO浓度数据,每天的数据分别保存在以8位日期字符串命名的CSV文件中,部分文件如图a所示,每个文件记录了一天24小时的监测数据,示例如图b所示。
为统计分析城市A全年各月份PM2.5的月平均浓度(当月的日平均浓度的平均值),编写Python程序。请回答下列问题:
(1)定义pmday函数,功能为:读取某天的CSV文件,返回城市A当天PM2.5的日平均浓度。函数代码如下,划线处应填入的代码为 (单选,填字母)。
A.df['类型']=='PM2.5'
B.df['类型'=='PM2.5']
C.df[df['类型']]=='PM2.5'
D.df[df['类型']=='PM2.5']
import pandas as pd
def pmday(dayfile):
df=pd.read_csv(dayfile) #读取文件 dayfile 中的数据
df=
return df['城市A'].mean() #返回城市A当天PM2.5的日平均浓度
(2)统计城市A各月份PM2.5的月平均浓度并绘制线形图,部分Python程序如下,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
def tstr(t):
if t<10:
retrun '0'+str(t)
else:
retrun str(t)
pm=[0]*12
mdays=[31,28,31,30,31,30,31,31,30,31,30,31] #2021年每月天数
for m in range(12):
sm=0
mstr=tstr(m+1)
for d in range( ① ):
dstr=tstr(d+1)
dayfile='2021'+ mstr+ dstr+ '.csv'
sd=pmday(dayfile)
②
pm[m]=sm/mdays[m]
x=[1,2,3,4,5,6,7,8,9,10,11,12]
y= ③
plt.plot(x,y) #绘制线形图
#设置绘图参数,显示如图c所示线形图,代码略
(3)城市A 2021年 PM2.5年平均浓度为34.6微克/立方米。由图c可知,城市A 2021年 PM2.5月平均浓度超过年平均浓度的月份共 个。
考点二 大数据处理
1.(2023宁波三锋期中,2)下列关于大数据与大数据处理的说法,不正确的是( )
A.处理大数据时,一般采用分治思想
B.大数据的处理对象是全体数据,而不是抽样数据
C.大数据的特点是数据量大、速度快、数据类型多、价值密度低
D.Hadoop是一个可运行于大规模计算机集群上的分布式系统基础架构,适用于处理实时数据
2.(2023金华十校联考,3)下列有关大数据处理、数据可视化的说法不正确的是( )
A.静态数据是指处理时已收集完成、计算时不会发生改变的数据
B.流数据主要是指不间断地、持续地到达的实时数据
C.图计算是指有关大量图片的计算
D.“各省生产总值占比情况”可以采用饼图或环形图呈现
3.有Python程序段如下所示:
import pandas as pd
import numpy as np
a=np.array([1,2,3,4]).reshape(2,2)
df=pd.DataFrame(a)
print(df.at[1,1])
该程序段运行后输出的结果为( )
A.4 B.3 C.2 D.1
4.小张收集了近阶段要学习的英文单词,存储为“data.txt”文件,格式如图所示。
处理“data.txt”文件中的英文单词的Python程序段如下所示:
file='data.txt'
word_c=[]
n=0
for word in open(file):
if word[0:1]=="c":
word_c.append(word)
print('字母c开头的单词个数为:',n)
(1)划线处的代码为 。
(2)该程序段运行后,列表word_c中的数据为 。
5.请在空格处填写正确的代码,使程序完善。
实现功能:绘制y=x2-2x+1的图象。
#加载numpy模块并取名为np
import numpy as np
#加载matplotlib.pyplot模块并取名为plt
import matplotlib.pyplot as plt
# x在-7到9之间,每隔0.1取一个值
x=np.arange(-7,9,0.1)
① =x**2-2*x+1
plt.plot(x, ② )
plt.title('y=x*x-2*x+1')
plt.xlabel('x')
plt.ylabel('y')
plt. ③
6.在网上搜索朱自清的文章《绿》,如图所示。
(1)搜索信息并保存为txt文件,该过程称为 。
(2)“绿.txt”文件的文本类型是 。(填写字母:A.结构化数据/B.半结构化数据/C.非结构化数据)
(3)制作标签云的代码如下:
import collections
import jieba
import wordcloud as wc
import numpy as np
from PIL import Image
wcg=wc.WordCloud(background_color="white",font_path='assets/msyh.ttf')
text=open('data/绿.txt',encoding='utf-8')
read()
seg_list= ①
f=collections.Counter(seg_list)
wcg.fit_words(f)
wcg.to_file('output/b.png')
划线处①语句是调用jieba对象的cut函数对变量为text的文件进行分词,则该处语句为 。
(4)得到的标签云如图所示。
该图片的文件名是 ,表现该文本特征的是 。(至少写出3个)
专题综合练
题组一
1.(2023十校联盟联考,5)近年来,各地相继出现了一些无人售货超市,其购物流程为:通过微信号/支付宝注册→扫码或扫脸开门→选购商品→结算区显示屏清单确认(智能检测)→开门即走(智能扣款)。整个过程快捷方便,达到无感支付。超市内24小时利用摄像头监控,实行人脸识别防盗监控,发现有小偷将自动抓拍报警并列入黑名单,通过RFID技术+核心软件算法有效识别和定位货损源头,并进行有效处理和防范。此外,超市也会依靠大数据、云计算技术,对各种商品的销售状况进行汇总分析,并智能判断客户的购买习惯进行产品推荐,还能预测销售走势,给商家提供合理的建议。
根据阅读材料,下列说法正确的是( )
A.汇总分析已完成的商品销售状况数据属于流数据
B.无人售货超市依靠大数据处理只需要分析最近几个月的抽样数据
C.根据客户账号的购买习惯进行产品推荐,不需要知道用户购买商品的原因
D.无人售货超市中的每一个数据都来自真实数据,体现了大数据价值密度高的特点
2.(2023舟山高二期末,12)小明用下列Python程序将图a处理成图b所示效果,发现处理后的图像不理想,他要想将图像处理成图c所示效果,则可做的修改是( )
from PIL import Image#第0行
import numpy as np#第1行
import matplotlib.pyplot as plt#第2行
img=np.array(Image.open ('dj.jpg').convert('L'))#第3行
row,cols=img.shape#第4行
for i in range(row):#第5行
for j in range(cols):#第6行
if img[i,j]>188:#第7行
img[i,j]=1 #1表示白色#第8行
else:#第9行
img[i,j]=0 #0 表示黑色
#第10行
plt.figure('dj')#第11行
plt.imshow(img,cmap='gray')
#第12行
plt.axis('off')#第13行
plt.show ()
A.将第7行中的数字188改成138
B.将第7行中的数字188改成250
C.将第7行中的>改成<
D.将第8行的代码与第10行的代码互换
3.(2022杭州重点中学期中,13)小萧从国家统计局网站上收集了近几年国民总收入相关数据,并使用Excel软件进行相关数据处理与分析。部分界面如图a所示,请回答下列问题:
(1)下列关于数据整理的描述,正确的是 (单选)。
A.某些缺失的数据可以自己随意估计一个值进行补充
B.Excel表格中的异常数据可以直接删除或忽略
C.Excel表格中的重复数据可以进行合并或删除
D.Excel中格式不一致的数据,一般只保留一种格式的数据,删除其他格式的数据
(2)图b的图表数据类型为 (选填:柱形图/条形图/折线图)。
图b
(3)根据表格数据呈现,从2017年开始可以计算国民总收入增长比例,方法是在C8单元格输入公式 (计算公式:(当年国民总收入-去年国民总收入)/去年国民总收入),设置百分比格式后自动填充至F8单元格。
(4)除了Excel,可以进行数据分析的软件还有 (多选,填数字)。
①Word ②SPSS ③SAS ④MATLAB
⑤记事本 ⑥Python ⑦录音机
4.(2022杭州八县市区期末,16)某次测试的Excel文件成绩表如图1所示。
图1
(1)已知有200名同学参加了本次测试。小明想把全体同学的信息平均分放在D202单元格,那么在 D202单元格输入的公式为 。
(2)现在要求用Python增加“总分”列数据,然后求每个班总分的平均分(如图2),最后绘制每班总分平均分的垂直柱形图(如图3)。请在程序划线①②处选择合适的代码(填字母)。
图2
图3
import pandas as pd
import matplotlib.pyplot as plt
#图表中文显示处理,代码略
df=pd.read_excel("test.xlsx")
score=[]
for i in df.values:
js= ① #①处请选择(填字母): A.df["信息"]+df["通用"]/B.i[3]+i[4]
score.append(js)
df["总分"]=score
df1=df.groupby("班级".as_index=False)["总分"].mean()
plt.title("期中技术平均分")
plt. ② (df1["班级"],df1["总分"],width=0.5)#②处请选择(填字母):
A.plot/B.bar/C.scatter
5.(2022丽水期末,13)小明收集了本周信息技术学科学习评价的数据,如图所示。
(1)观察上表小明做了如下操作,其中属于数据整理的是 (多选,填字母)。
A.删除重复行第五行
B.验证并修改D2单元格数据
C.通过公式计算全班平均分
D.重新设置C3单元格格式
(2)为了分析每个组的平均分,设计了如下Python程序。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("成绩表.xlsx")
print(df1)
划线处的代码应为 (单选,填字母)。
A.df1=df.groupby("平均分").mean()
B.df1=df.mean()
C.df1=df.groupby("小组").mean()
D.df1=df["小组"].mean()
(3)利用Python程序绘制各小题得分率图表,如图所示。
请在划线处填写合适的代码。
num=int(input("请输入小组:"))
plt.figure(figsize=(10,5))
list=[]
for i in range(12):
s="题"+str(i+1)
list.append(df1.at[num,s]*50)
plt.bar(range(1,13),list)
plt.title(str(num)+" ")
plt.xlabel("question number")
plt.ylabel("correct rate")
plt.show()
6.(2024届A9协作体返校考,14)张三同学收集了一个地区8月各类共享单车的骑行数据记录,每天的用户数据存储于“shared bikes. xlsx”文件中,不考虑跨天数据。数据格式如图a所示,请回答下列问题:
(1) cal函数功能为:读取骑行时间的小时和分钟部分,转换为分钟格式并返回,如“2022/8/20 6:57”获取“6:57”转换为417 (6*60+57=417), 代码如下。请在划线处填入合适的代码。
def cal(s):
n=len(s)
for i in range(n):
if s[i]==" ": #如果为空格字符
p=i
if s[i]==":":
q=i
t= + int(s[q+1:])
return t
(2)统计本月各类型单车的每天平均骑行时长,并绘制柱形图,代码如下,绘制的图表如图b所示,请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel ("shared bikes.xlsx")
bike=["哈罗单车","摩拜单车","美团单车","青桔单车"]
sm=[0]*4
avg=[0]*4
days=31
for i in ① :
t=cal(df.at[i, "结束时间"]) - cal (df. at[i, "开始时间"])
for j in range(4):
if df.at[i,"App 类型”]==bike[j]:
②
break
for i in range(4):
avg[i]=sm[i]/ days
plt.figure(figsize=(12, 4))
x=bike
y= ③
plt.bar(x, y)
plt.show()
(3)统计本月各类型单车的骑行次数,加框处代码有错,可以改正为 (选填字母:A.max()/B.min()/C.mean()/D.count())。
n=df. groupby("App类型",as_ index=True).用户编号.sum ()
7.(2024届绍兴诊断性测试,14)学校暑期开展“青春迎亚运”活动,邀请高二学生每日参加运动锻炼并进行线上打卡。每周收集一次相关数据,分别保存在相应的xlsx文件中,部分文件如图a所示。每个文件记录了一周7天的打卡数据,示例如图b所示,其中运动时长单位为分钟。
为统计分析学生锻炼情况,给出周报数据,编写Python程序,请回答以下问题:
(1)定义px函数,功能为:读取某一周的打卡数据,将其按班级进行排序操作并返回结果。
函数代码如下,将划线处代码补充完整。
import pandas as pd
def px(file_week):
df=pd.read_excel(file_week)
df=df.sort_values( ,ignore_index=True)
#按班级升序排序,参数ignore_index=True表示更新索引
return df
(2)统计某一周各运动项目的参与人次,并绘制柱形图,如图c所示,部分Python代码如下:
import matplotlib.pyplot as plt
s=input("请输入文件名: ")
df=px(s)
df1=df.groupby("运动项目".as_index=False). ① #统计各运动项目参与人次
df1.rename(columns={"学号":"参与人次"},inplace=True) #更改列标题
plt.bar( ② )
plt.xlabel("运动项目")
plt.ylabel("参与人次")
plt.show()
划线处应填入的代码为 (单选,填字母)。
A.①count() ②df1["参与人次"], df1["运动项目"]
B.①sum() ②df1["参与人次"], df1["运动项目"]
C.①sum() ②df1.运动项目, df1.参与人次
D.①count() ②df1.运动项目, df1.参与人次
(3)统计某一周每班各学生的总运动时长后,比较得出该周每班最高的两位时长,部分Python程序代码如下,请在划线处填入合适的代码。
qp=[[0 for i in range(m)]for j in range(n)]
'''
定义数组qp记录每班各学生一周运动总时长,n为班级数,m为每班人数。其中qp[0][0]~qp[0][m-1]存储1班1号~m号同学的每周运动总时长,依次类推,qp[n-1][0]~qp[n-1][m-1]存储n班1号~m号同学的每周运动总时长。
'''
print("本周每班最高的两位时长分别为: ")
i=0
while i
cla=df["班级"][i]
①
if i!=0 and df["班级"][i]!=df["班级"][i-1] or ② :
cla=df["班级"][i-1]
k1=0;k2=0
for j in range(1,len(qp[cla-1])):
if qp[cla-1][j]>qp[cla-1][k1]:
③
k1=j
elif qp[cla-1][j]>qp[cla-1][k2]:
k2=j
print(cla,"班",qp[cla-1][k1].qp[cla-1][k2])
i=i+1
(4)统计某一周各运动项目的参与人次后绘制柱形图如图c所示,由图可知,该周参与人气最高的运动项目为 。
8.(2024届宁波模拟,13)已知某年级有6个班级,所有学生名单存储在文件“name.csv”中(如图1),学校举行某趣味活动项目中,需要每个班抽3名代表参加比赛,请编写一个随机抽取程序,执行效果如图2。请回答以下问题:
(1)加框处代码的作用是 。
(2)实现上述功能的部分Python程序如下,请在划线处填写合适的代码。
import csv
import random #数据读入
f=open("name.csv","r")
flines=csv.reader(f)
name_list=[]
m=6 #班级总数
total=18 #参赛总人数
for line in flines:
if line[0]=="班级":
continue #跳过当前循环的剩余语句,继续进行下一次循环
name_list.append(line)
①
flag=[False]*n
grade=[3]*m
i=0
while i
bj=int(name_list[p][0])
if flag[p]==False:
if grade[bj-1]>0:
flag[p]=True
④
i+=1
print("抽取名单为: ")
print("班级","姓名")
for i in range(n):
if flag[i]:
print(name_list[i][0],name_list[i][1])
f.close()
9.(2023杭州地区重点中学联考,14)小明利用“在线社团报名系统”收集了全校学生的社团报名信息,并将报名数据导出到“社团报名.xlsx”中,如图1所示。然后编写Python程序对报名数据进行处理,生成分别以班级名和社团名为文件名的 Excel 文件,以便分发给相应的社团指导老师和班主任。
(1)在对表格进行数据整理时发现,关于“Jacky.Y” 同学的记录可能存在的数据问题是 (选填:A.数据缺失 B.数据异常 C.逻辑错误 D.数据格式不一致)。
(2)其中生成每个社团名单文件的过程是:先对报名数据按社团名称进行分类,并对选报同一社团的学生按班级进行升序排序,然后生成各个社团名单文件,如图 2所示。对应的程序代码如下,请在划线处填写合适的代码。
import pandas as pd
def read_file(filename):
#读入报名数据的原始文件,并将表中的数据转换成列表,代码略
def save_file(a): #保存名单到相应社团的Excel电子表格文件
df=pd.DataFrame(a,columns=["班级","姓名","选报社团"])
df.to_excel( ① )+".xlsx",index=False)
a=read_file("社团报名.xlsx")
n=len(a)
#按社团名(参照拼音的字母顺序)进行升序排序,代码略
#统计各社团人数,存在列表 rs 中,rs=[["滑板社",36],…],代码略
s=0
for i in range(len(rs)):
②
left,right=s, s+num-1
while left < right:
imin=imax=left
for k in range(left+1,right+1):
if a[k][0] < a[imin][0]:
imin=k
elif a[k][0] > a[imax][0]:
imax=k
if imin !=left:
a[imin],a[left]=a[left],a[imin]
if imax==left:
③
if imax !=right:
a[imax],a[right]=a[right],a[imax]
left=left+1; right=right-1
④
s+=num
题组二
1.(2022诸暨期末,4)使用pandas编程处理数据DF1,下列选项能实现行列转置操作的是( )
A.DF1.T B.DF1.columns
C.DF1.values D.DF1.index
2.(2022宁波奉化期末,9) 有如下Python程序段:
import pandas as pd
s=pd.Series(range(5,11,3))
s[1]=15
print(s)
该程序执行后,输出的结果是( )
1 15 2 8 dtype: int64 0 5 1 15 dtype: int64 1 15 2 8 3 11 dtype: int64 0 5 1 15 2 11 dtype: int64
A. B. C. D.
3.(2022宁波咸祥中学期中,16)小明收集了某超市饮料销售情况相关数据,并使用Excel软件进行处理,如图a所示。
请回答下列问题:
(1) 区域 I3:I15 的数据是通过公式计算得到的。在I3单元格输入公式后, 用自动填充功能完成 I4:I15 的计算,则I3单元格中的公式是 。 (占销售总额百分比=销售额(元)/销售总额(元))
(2)若因误操作将 I16 单元格删除,则 I3 单元格会显示 (选填字母:A.#VALUE B.#DIV/0! C.###### D.#REF! )。
(3)要将类别为“可乐”的饮料以“毛利润(元)”为主要关键字降序排序, 则选择排序的区域为 。
(4)小王根据图 a 中的数据,制作了一张反映橙汁类饮料销售额和毛利润对比的图表,如图b 所示,则建立该图表的数据区域是 。将E8单元格数值修改成6.00,是否会影响该图表 (选填:是/否)
图b
4.(2022台州启超中学期中,16)APP活跃人数数据存储在“app.xlsx”文件中,如图所示,现要编程统计结果,请回答下列问题:
若要把“app.xlsx”第1张工作表中的信息导入到book1对象中,并进行统计,实现这个功能的Python代码如下,在程序划线处填入合适的代码。
import pandas as pd
book1= (1) #读取app.xlsx文件数据,并存储在book1对象中
book1_sum= (2)
#计算10月人数之和
book1_aver= (3)
#计算11月人数平均值
book1_g= (4)
#按应用领域分组统计
book1_sort= (5)
#按11月人数值,降序排序
print("10月人数之和:",book1_sum)
print("11月人数平均值:",book1_aver)
5.(2022宁波奉化期末,14)小孙收集了2016年到2020年的各地区粮食生产总量并存储在“lscl.xlsx”文件中,如图a所示,现使用Python对其进行数据处理,并实现数据可视化,绘制的图表如图b所示。
实现如上功能的代码如下,请回答以下问题。
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family': 'SimHei'})
#设置中文字体
df=pd.read_excel("lscl.xlsx")
df. ① ("2020年",ascending=False,inplace=True)
df1=df.head(10)
x= ②
y=df1["2020年"]
plt.figure(figsize=(8,6))
plt. ③ ("2020年粮食产量TOP10")
plt.bar(x,y,label="2020年")
plt.xlabel("地区")
plt.legend()
④
(1)请在划线处填入合适的代码语句,以实现以上功能。
(2)代码语句“plt.bar(x,y,label="2020年")”的功能为绘制如图b所示的图像,能够实现相同功能的语句是 (多选题,少选得1分,多选不得分)。
A.df.head(10).plot("地区","2020年")
B.df[:10:].plot("地区","2020年",kind="bar")
C.plt.plot(x,y,label="2020年",kind="bar")
D.plt.bar("地区","2020年",label="2020年")
E.df1.plot("地区","2020年",kind="bar")
6.(2022杭州场口中学、桐庐富春中学检测,16)在月考之后,学校教务员拿到了高一年级月考的基础成绩并用Excel软件进行数据处理,如图1所示。请回答下列问题:
图1
(1)区域M2:M645的数据是通过在M2单元格输入公式并自动填充得到的,则M645单元格中的公式是 。
(2)为了分析各班级的数学平均分,设计了如下Python程序,利用其绘制各班数学平均分图表,如图2所示:
结合上图的效果,请在程序划线处填写合适的代码。
import matplotlib.pyplot as plt
import pandas as pd
df=pd.read_excel('高一月考成绩.xlsx')
df1=df.groupby("班级"). ①
plt.bar(df1.index, ② )
plt.title("高一各班数学平均分")
plt.ylim(40,100)
plt.xlabel( ③ )
plt.ylabel("分数")
plt.show()
7.(2023 三月百校联考,14)李明收集了梅西2004年至2022年俱乐部比赛数据,保存在“梅西俱乐部详细比赛数据.xlsx”文件中,部分数据如图a所示,现在利用pandas模块处理数据。
(1)梅西2004年10月—2021年7月效力于巴塞罗那俱乐部,2021年8月转会至巴黎圣日耳曼俱乐部,现在李明想知道梅西每个赛季的胜率,实现上述功能的Python程序如下,请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("梅西俱乐部详细比赛数据.xlsx")
df['年']=pd.to_datetime(df["时间"]).dt.strftime('%Y').astype(int)
df['月']=pd.to_datetime(df["时间"]).dt.strftime('%m').astype(int)
df['胜负情况']=" "
for i in range(len(df)):
f=True;z=0;k=0
for c in df["比分"][i]:
if ① :
if f:
z=z*10+int(c)
else:
k=k*10+int(c)
else:
f=not f
jlb="巴塞罗那"
if df["年"][i]*100+df["月"][i]>=202108:
②
if (df["主队"][i]==jlb and z>k) or (df["客队"][i]==jlb and z
elif z==k:
df['胜负情况'][i]="平"
else:
df['胜负情况'][i]="负"
g=df.groupby(df["年"],as_index=True).count()
③
g1=df1.groupby(df1["年"],as_index=True).count()
g["胜率"]=g1["胜负情况"]/g["胜负情况"]*100
(2)图b为2004—2022年梅西俱乐部比赛胜率统计图。
2004-2022年梅西俱乐部比赛胜率统计
plt.plot( , marker='^')
plt.title("2004-2022年梅西俱乐部比赛胜率统计")
plt.show()
方框处代码为 (多选:填字母)。
A.g["年"],g["胜率"] B.g["年"],g.胜率
C.g.index,g["胜率"] D.g.index,g.胜率
8.(2022湖州三贤联盟期中,14)小张同学为了更好地了解冬奥会,从网上收集了历届冬奥会各个项目比赛信息,收集到的部分数据如图1所示。
图1
图2
为分析数据,小张编写了如下程序:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
df=pd.read_csv("dongao.csv")
#删除所有未获得奖牌的记录,并将奖牌列中的"G"修改为"金牌","S"修改为"银牌","B"修改为"铜牌"
jp={'G':'金牌','S':'银牌','B':'铜牌'}
for i in df.index:
if ① :
df=df.drop(i)
else:
df.at[i,'奖牌']=jp[df.at[i,'奖牌']]
#对输入国家每届的奖牌数进行统计,并制作相应图表,如图2所示
nt=input("请输入国家名称:")
df1=df[df['国家']==nt]
df3=pd.DataFrame(df2) #将分组后数据生成新的二维结构,索引为“届次”,列标题为“奖牌”
x=df3.index
y= ②
plt.title(nt+"历届冬奥会奖牌趋势图")
plt. ③ (x,y)
plt.show()
(1)在划线处填上合适的代码。
(2)为了能显示某国历届冬奥会奖牌变化,需在加框处添加的语句为 (多选)。
A.df2=df1.groupby('奖牌')
df2=df1.届次.count()
B.df2=df1.groupby('届次')
df2=df2['奖牌'].count()
C.df2=df1.groupby('奖牌')['届次'].count()
D.df2=df1.groupby('届次').奖牌.count()
9.(2023十校联盟联考,14)小明从网上下载了豆瓣图书1900—2017年间出版的图书数据,存储在Excel文件中,如图a所示,数据表已按出版年份升序排好,包含书名、作者、出版社、出版年份、价格、评分以及评论数量。他要编写一个Python程序快速对图书数据进行分析。
(1)为了求评论数量累计最高的作者及其出版的图书平均评分,小明需要对图a所示的表中数据进行整理,则下列说法正确的是 (多选,填字母)。
A.第3行和第4行数据重复,删除其中一行即可
B.通过检测发现F56168单元格的数据存在错误,应进行修正
C.删除“出版社”和“出版年份”两列数据,不影响分析结果
D.“评分”及“评论数量”为0的数据没有任何价值,可以直接删除
(2)小明利用整理好的数据,编写并运行程序,结果如图b所示。
作者 评论数量
0 [日]村上春树 679101.0
1 [日]东野主吾 664106.0
2 韩寒 623116.0
3 郭敬明 620571.0
4 [英]J.K.罗琳 462476.0
评论数量累计最多的作者是:[日]村上春树 共出版了34部作品,平均评分为8.01
图b
实现上述结果的Python程序如下:
import pandas as pd
df=pd.read_excel("books.xlsx")
df1=df.groupby("作者", as_index=False)
df2=df1.评论数量.sum()
dfsort=df2.sort_values("评论数量" ,ascending=False,ignore_index=True)
print(dfsort.head(5))
#输出评论数量累计前五名作者
top= ①
dfbk=df[df.作者==top]
#根据作者检索出相应的作品
avg=dfbk.评分.mean()
print("评论数量累计最多的作者是:", top)
print("共出版了", ② ,"部作品,平均评分为" , round(avg,2))
则程序中划线①②处应填入的代码为:
① ;
② 。
10.(2024浙江1月选考,14,7分)某学院举行运动会,比赛设跳高、100米等项目,每个项目分男子组和女子组。现要进行报名数据处理和比赛成绩分析。请回答下列问题:
(1)运动会报名规则为:对于每个项目的男子组和女子组,每个专业最多各报5人(如“软件工程”专业在男子跳高项目中最多报5人)。软件工程专业的报名数据保存在DataFrame对象df中,如图a所示。若要编写Python 程序检查该专业男子跳高项目报名是否符合规则,下列方法中, 正确的是 (单选,填字母)。
A.从df中筛选出性别为“男”的数据dfs, 再从dfs中筛选出项目为“跳高”的数据,判断筛选出的数据行是否超过5行
B.对df中数据按性别排序并保存到dfs中,再从dfs中筛选出项目为“跳高”的数据,判断筛选出的数据行是否超过5行
C.从df中筛选出项目为“跳高”的数据dfs,判断dfs中是否有连续5行以上的男生数据
(2)运动员比赛成绩的部分数据如图b所示。根据已有名次计算得分,第1名至8名分别计9,7,6,5,4,3,2,1分,第8名之后计0分。实现上述功能的部分Python程序如下,请在程序中划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
#读取如图b 所示数据,保存到DataFrame对象df1中,代码略
f=[9,7,6,5,4,3,2,1]
for i in range(0,len(df1)):
rank=df1.at[i,"名次"] #通过行、列标签取单个值
score=0
if rank<=8:
df1.at[i,"得分"]=score
(3)根据上述df1中的得分数据,统计各专业总分,绘制如图c所示的柱形图,实现该功能的部分Python程序如下:
df2=df1.groupby(" ",as_index=False).sum() #分组求和
#设置绘图参数,代码略
plt.bar(x,y) #绘制柱形图
①请在程序中划线处填入合适的代码。
②程序的方框中应填入的正确代码为 (单选,填字母)。
A.x=df1["专业"]
y=df1["总分"]
B.x=df2["专业"]
y=df2["得分"]
C.df1["专业"]="专业"
df1["总分"]="总分"
D.df2["专业"]="专业"
df2["得分"]="得分"
专题三 数据处理与应用
考点过关练
考点一 常用表格数据的处理
1.(2022诸暨海亮高中期中,16)为了响应全民健身计划,某高中对学生进行了体质健康测评,并用Excel软件进行数据处理,如图a所示。
图a
请回答下列问题:
(1)区域M2:P15 的数据是通过公式计算得到的,在M2单元格中输入公式后,再使用自动填充功能完成该区域的计算,则N3单元格中的公式是“=SUMPRODUCT(( )*($I$3:$I$553=N$1))”。
(提示:M2单元格输入公式=SUMPRODUCT((A1:A100=“2”)*(I1:I100=“优秀”)),表示同时满足A1:A100是2班和I1:I100是优秀这两个条件的情况数量,也就是进行条件计数。)
(2)根据图a中的数据制作的图表如图b所示。创建该图表的数据区域是 。
图b
(3)对图a工作表进行相关数据分析,下列说法正确的是 (多选,填字母)。
A.以“总分等级”为依据进行升序排序,选择的区域是A3:I553
B.选择“A3:I553”按照“总分等级”升序排序后,图 b 的图表不会发生改变
C.现需要选出总分等级为“不及格”的学生,可选择区域A3:I553,以“总分等级”为“不及格”进行筛选并保留结果
D.为了显示男生立定跳远得分最高的3位学生数据,可先对“性别”为“男”进行筛选,再对“立定跳远”进行筛选,选择最大的3项
答案 (1)$A$3:$A$553=$K3 (2)M1:P1,M16:P16
(3)ABC
2.(2023杭州“六县九校”期中,16)小明同学为备战明年的计算机类研究生考试,收集了部分高校的计算机专业复试分数线并进行分析。小明收集到的数据如图a所示。
各院校总分展示图
请帮助小明同学对表格数据进行下列分析:
(1)若想知道这些学校的总分情况,则在F2单元格先输入公式 (要求必须使用函数),然后使用自动填充功能完成单元格F3:F8 的计算。
(2)现要求按照“总分”列进行降序排序,并筛选出总分在290分及以上的院校并显示,最后绘制各个院校总分的垂直柱形图(如图b)。请在程序划线①②③处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['KaiTi','SimHei','FangSong'] #图表中文显示处理
df=pd.read_excel ("score.xlsx")
df1=df[ ① ]
print(df1)#输出筛选数据
df=df. ② ("总分",ascending=False)#按照“总分”列降序排序
print(df)#输出排序好的数据
#------创建图表代码------
plt.title("各院校总分展示图")
plt.xlabel("院校名称")
plt. ③ (df.院校名称,df.总分) #各个院校总分的垂直柱形图
plt.show()
答案 (1)=SUM (B2:E2) (2)①df.总分>=290或者df["总分"]>=290 ②sort_values ③bar
3.(2023杭州S9联盟联考,14)小明收集了当地2023年3月份的天气情况,数据存储在文件“temp.xlsx”中,如图a所示。分析温差最大的日期,并生成反映各类天气情况的天数对比图如图b所示。
(1)在对表格进行数据整理时发现,“日期”可能存在的数据问题是 (单选:A.数据缺失;B.数据异常;C.逻辑错误;D.数据格式不一致)。
(2)程序代码如下所示,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams["font.sans-serif"]=["SimHei"] #设置中文字体
df=pd.read_excel("temp.xlsx")
df["温差"]= ① #新增"温差"列
s=df.sort_values("温差", ascending=False, ignore_index=True)
df_max= ② #获取温差最大的日期,如并列只输出第一个日期
print(df_max)
df_t=s.groupby("天气", as_index=False).count()
df_t=df_t.rename(columns={"日期": "天数"}) #修改列名"日期"为"天数"
x=df_t["天气"]
y=df_t["天数"]
③ (x, y, label="天气情况")
plt.legend()
plt.show()
(3)观察图b,3月份天数最多的天气类型是 。
答案 (1)D (2)①df["最高气温"]-df["最低气温"]
②s["日期"][0]或 s.at[0,"日期"] ③plt.bar (3)小雨
4.(2023杭州地区重点中学期中,15)某中学高一年级完成一次7选3意向调查,数据存储在“xk73.xlsx”中,如图a所示,其中1代表选择科目,0代表弃选科目。
(1)使用 pandas 编程计算本次选课各门课人数占总人数的比例, 请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#图表显示中文
df=pd.read_excel (" ① ")
a=[" "]*len(df) #存储每个学生的选课组合
dic={"物":0,"化":0,"生":0,"政":0,"历":0,"地":0,"技":0}
for i in df.index:
for j in df.columns[3:]:
if df.at[i,j]==1:
②
a[i]+=j
for i in dic.keys():
dic[i]=round(dic[i]/len(df)*100,2)
(2)按照各科选考人数占比创建如图b所示的图表。
各科选考人数占比
df1=pd.DataFrame({"学科":dic.keys(),"人数占比":dic.values()})
df1= ①
plt.title("各科选考人数占比")
plt.bar( ② , label="人数占比")
plt.legend()
plt.show()
观察图b,横线处应填入的代码为:① ;② (选填字母)。
A.df1.sort_values("人数占比",ascending=True)
B.df1.sort_values("人数占比",ascending=False)
C.df1.学科,df1.人数占比
D.df1.人数占比,df1.学科
(3)小李同学想查询某种七选三组合有多少人。以下程序代码可以为小李同学提供查询功能,程序运行示例如图c所示,请在划线处填入合适的代码。
请输入需要查询的选课组合:物化技
选择物化技组合的同学共有:192人
图c
cx=input("请输入需要查询的选课组合:")
cnt=0
for i in range(len(a)):
if :
cnt=cnt+1
print(f"选择{cx}组合的同学共有: {cnt}人")
答案 (1)①xk73.xlsx ②dic[j]+=1 (2)①B ②C (3)a[i]==cx或其他等价表达式
5.(2023浙江1月选考,14,9分)小红收集了部分城市2021年全年每天PM2.5、PM10、CO浓度数据,每天的数据分别保存在以8位日期字符串命名的CSV文件中,部分文件如图a所示,每个文件记录了一天24小时的监测数据,示例如图b所示。
为统计分析城市A全年各月份PM2.5的月平均浓度(当月的日平均浓度的平均值),编写Python程序。请回答下列问题:
(1)定义pmday函数,功能为:读取某天的CSV文件,返回城市A当天PM2.5的日平均浓度。函数代码如下,划线处应填入的代码为 (单选,填字母)。
A.df['类型']=='PM2.5'
B.df['类型'=='PM2.5']
C.df[df['类型']]=='PM2.5'
D.df[df['类型']=='PM2.5']
import pandas as pd
def pmday(dayfile):
df=pd.read_csv(dayfile) #读取文件 dayfile 中的数据
df=
return df['城市A'].mean() #返回城市A当天PM2.5的日平均浓度
(2)统计城市A各月份PM2.5的月平均浓度并绘制线形图,部分Python程序如下,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
def tstr(t):
if t<10:
retrun '0'+str(t)
else:
retrun str(t)
pm=[0]*12
mdays=[31,28,31,30,31,30,31,31,30,31,30,31] #2021年每月天数
for m in range(12):
sm=0
mstr=tstr(m+1)
for d in range( ① ):
dstr=tstr(d+1)
dayfile='2021'+ mstr+ dstr+ '.csv'
sd=pmday(dayfile)
②
pm[m]=sm/mdays[m]
x=[1,2,3,4,5,6,7,8,9,10,11,12]
y= ③
plt.plot(x,y) #绘制线形图
#设置绘图参数,显示如图c所示线形图,代码略
(3)城市A 2021年 PM2.5年平均浓度为34.6微克/立方米。由图c可知,城市A 2021年 PM2.5月平均浓度超过年平均浓度的月份共 个。
答案 (1)D (2)①mdays[m] ②sm+=sd ③pm (3)5
考点二 大数据处理
1.(2023宁波三锋期中,2)下列关于大数据与大数据处理的说法,不正确的是( )
A.处理大数据时,一般采用分治思想
B.大数据的处理对象是全体数据,而不是抽样数据
C.大数据的特点是数据量大、速度快、数据类型多、价值密度低
D.Hadoop是一个可运行于大规模计算机集群上的分布式系统基础架构,适用于处理实时数据
答案 D
2.(2023金华十校联考,3)下列有关大数据处理、数据可视化的说法不正确的是( )
A.静态数据是指处理时已收集完成、计算时不会发生改变的数据
B.流数据主要是指不间断地、持续地到达的实时数据
C.图计算是指有关大量图片的计算
D.“各省生产总值占比情况”可以采用饼图或环形图呈现
答案 C
3.有Python程序段如下所示:
import pandas as pd
import numpy as np
a=np.array([1,2,3,4]).reshape(2,2)
df=pd.DataFrame(a)
print(df.at[1,1])
该程序段运行后输出的结果为( )
A.4 B.3 C.2 D.1
答案 A
4.小张收集了近阶段要学习的英文单词,存储为“data.txt”文件,格式如图所示。
处理“data.txt”文件中的英文单词的Python程序段如下所示:
file='data.txt'
word_c=[]
n=0
for word in open(file):
if word[0:1]=="c":
word_c.append(word)
print('字母c开头的单词个数为:',n)
(1)划线处的代码为 。
(2)该程序段运行后,列表word_c中的数据为 。
答案 (1)n=n+1或n+=1 (2)data.txt中所有以小写字母"c"开头的单词
5.请在空格处填写正确的代码,使程序完善。
实现功能:绘制y=x2-2x+1的图象。
#加载numpy模块并取名为np
import numpy as np
#加载matplotlib.pyplot模块并取名为plt
import matplotlib.pyplot as plt
# x在-7到9之间,每隔0.1取一个值
x=np.arange(-7,9,0.1)
① =x**2-2*x+1
plt.plot(x, ② )
plt.title('y=x*x-2*x+1')
plt.xlabel('x')
plt.ylabel('y')
plt. ③
答案 ①y ②y ③show()
6.在网上搜索朱自清的文章《绿》,如图所示。
(1)搜索信息并保存为txt文件,该过程称为 。
(2)“绿.txt”文件的文本类型是 。(填写字母:A.结构化数据/B.半结构化数据/C.非结构化数据)
(3)制作标签云的代码如下:
import collections
import jieba
import wordcloud as wc
import numpy as np
from PIL import Image
wcg=wc.WordCloud(background_color="white",font_path='assets/msyh.ttf')
text=open('data/绿.txt',encoding='utf-8')
read()
seg_list= ①
f=collections.Counter(seg_list)
wcg.fit_words(f)
wcg.to_file('output/b.png')
划线处①语句是调用jieba对象的cut函数对变量为text的文件进行分词,则该处语句为 。
(4)得到的标签云如图所示。
该图片的文件名是 ,表现该文本特征的是 。(至少写出3个)
答案 (1)采集信息 (2)C (3)jieba.cut(text)
(4)b.png;我、的、着、了、绿、你
专题综合练
题组一
1.(2023十校联盟联考,5)近年来,各地相继出现了一些无人售货超市,其购物流程为:通过微信号/支付宝注册→扫码或扫脸开门→选购商品→结算区显示屏清单确认(智能检测)→开门即走(智能扣款)。整个过程快捷方便,达到无感支付。超市内24小时利用摄像头监控,实行人脸识别防盗监控,发现有小偷将自动抓拍报警并列入黑名单,通过RFID技术+核心软件算法有效识别和定位货损源头,并进行有效处理和防范。此外,超市也会依靠大数据、云计算技术,对各种商品的销售状况进行汇总分析,并智能判断客户的购买习惯进行产品推荐,还能预测销售走势,给商家提供合理的建议。
根据阅读材料,下列说法正确的是( )
A.汇总分析已完成的商品销售状况数据属于流数据
B.无人售货超市依靠大数据处理只需要分析最近几个月的抽样数据
C.根据客户账号的购买习惯进行产品推荐,不需要知道用户购买商品的原因
D.无人售货超市中的每一个数据都来自真实数据,体现了大数据价值密度高的特点
答案 C
2.(2023舟山高二期末,12)小明用下列Python程序将图a处理成图b所示效果,发现处理后的图像不理想,他要想将图像处理成图c所示效果,则可做的修改是( )
from PIL import Image#第0行
import numpy as np#第1行
import matplotlib.pyplot as plt#第2行
img=np.array(Image.open ('dj.jpg').convert('L'))#第3行
row,cols=img.shape#第4行
for i in range(row):#第5行
for j in range(cols):#第6行
if img[i,j]>188:#第7行
img[i,j]=1 #1表示白色#第8行
else:#第9行
img[i,j]=0 #0 表示黑色
#第10行
plt.figure('dj')#第11行
plt.imshow(img,cmap='gray')
#第12行
plt.axis('off')#第13行
plt.show ()
A.将第7行中的数字188改成138
B.将第7行中的数字188改成250
C.将第7行中的>改成<
D.将第8行的代码与第10行的代码互换
答案 A
3.(2022杭州重点中学期中,13)小萧从国家统计局网站上收集了近几年国民总收入相关数据,并使用Excel软件进行相关数据处理与分析。部分界面如图a所示,请回答下列问题:
(1)下列关于数据整理的描述,正确的是 (单选)。
A.某些缺失的数据可以自己随意估计一个值进行补充
B.Excel表格中的异常数据可以直接删除或忽略
C.Excel表格中的重复数据可以进行合并或删除
D.Excel中格式不一致的数据,一般只保留一种格式的数据,删除其他格式的数据
(2)图b的图表数据类型为 (选填:柱形图/条形图/折线图)。
图b
(3)根据表格数据呈现,从2017年开始可以计算国民总收入增长比例,方法是在C8单元格输入公式 (计算公式:(当年国民总收入-去年国民总收入)/去年国民总收入),设置百分比格式后自动填充至F8单元格。
(4)除了Excel,可以进行数据分析的软件还有 (多选,填数字)。
①Word ②SPSS ③SAS ④MATLAB
⑤记事本 ⑥Python ⑦录音机
答案 (1)C (2)柱形图 (3)=(C2-B2)/B2
(4)②③④⑥
4.(2022杭州八县市区期末,16)某次测试的Excel文件成绩表如图1所示。
图1
(1)已知有200名同学参加了本次测试。小明想把全体同学的信息平均分放在D202单元格,那么在 D202单元格输入的公式为 。
(2)现在要求用Python增加“总分”列数据,然后求每个班总分的平均分(如图2),最后绘制每班总分平均分的垂直柱形图(如图3)。请在程序划线①②处选择合适的代码(填字母)。
图2
图3
import pandas as pd
import matplotlib.pyplot as plt
#图表中文显示处理,代码略
df=pd.read_excel("test.xlsx")
score=[]
for i in df.values:
js= ① #①处请选择(填字母): A.df["信息"]+df["通用"]/B.i[3]+i[4]
score.append(js)
df["总分"]=score
df1=df.groupby("班级".as_index=False)["总分"].mean()
plt.title("期中技术平均分")
plt. ② (df1["班级"],df1["总分"],width=0.5)#②处请选择(填字母):
A.plot/B.bar/C.scatter
答案 (1)=AVERAGE(D2:D201) (2)①B ②B
5.(2022丽水期末,13)小明收集了本周信息技术学科学习评价的数据,如图所示。
(1)观察上表小明做了如下操作,其中属于数据整理的是 (多选,填字母)。
A.删除重复行第五行
B.验证并修改D2单元格数据
C.通过公式计算全班平均分
D.重新设置C3单元格格式
(2)为了分析每个组的平均分,设计了如下Python程序。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("成绩表.xlsx")
print(df1)
划线处的代码应为 (单选,填字母)。
A.df1=df.groupby("平均分").mean()
B.df1=df.mean()
C.df1=df.groupby("小组").mean()
D.df1=df["小组"].mean()
(3)利用Python程序绘制各小题得分率图表,如图所示。
请在划线处填写合适的代码。
num=int(input("请输入小组:"))
plt.figure(figsize=(10,5))
list=[]
for i in range(12):
s="题"+str(i+1)
list.append(df1.at[num,s]*50)
plt.bar(range(1,13),list)
plt.title(str(num)+" ")
plt.xlabel("question number")
plt.ylabel("correct rate")
plt.show()
答案 (1)ABD (2)C (3)group
6.(2024届A9协作体返校考,14)张三同学收集了一个地区8月各类共享单车的骑行数据记录,每天的用户数据存储于“shared bikes. xlsx”文件中,不考虑跨天数据。数据格式如图a所示,请回答下列问题:
(1) cal函数功能为:读取骑行时间的小时和分钟部分,转换为分钟格式并返回,如“2022/8/20 6:57”获取“6:57”转换为417 (6*60+57=417), 代码如下。请在划线处填入合适的代码。
def cal(s):
n=len(s)
for i in range(n):
if s[i]==" ": #如果为空格字符
p=i
if s[i]==":":
q=i
t= + int(s[q+1:])
return t
(2)统计本月各类型单车的每天平均骑行时长,并绘制柱形图,代码如下,绘制的图表如图b所示,请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel ("shared bikes.xlsx")
bike=["哈罗单车","摩拜单车","美团单车","青桔单车"]
sm=[0]*4
avg=[0]*4
days=31
for i in ① :
t=cal(df.at[i, "结束时间"]) - cal (df. at[i, "开始时间"])
for j in range(4):
if df.at[i,"App 类型”]==bike[j]:
②
break
for i in range(4):
avg[i]=sm[i]/ days
plt.figure(figsize=(12, 4))
x=bike
y= ③
plt.bar(x, y)
plt.show()
(3)统计本月各类型单车的骑行次数,加框处代码有错,可以改正为 (选填字母:A.max()/B.min()/C.mean()/D.count())。
n=df. groupby("App类型",as_ index=True).用户编号.sum ()
答案 (1)int(s[p+1:q])*60 (2)①df.index或range(len(df)) ②sm[j]+=t ③avg (3)D
7.(2024届绍兴诊断性测试,14)学校暑期开展“青春迎亚运”活动,邀请高二学生每日参加运动锻炼并进行线上打卡。每周收集一次相关数据,分别保存在相应的xlsx文件中,部分文件如图a所示。每个文件记录了一周7天的打卡数据,示例如图b所示,其中运动时长单位为分钟。
为统计分析学生锻炼情况,给出周报数据,编写Python程序,请回答以下问题:
(1)定义px函数,功能为:读取某一周的打卡数据,将其按班级进行排序操作并返回结果。
函数代码如下,将划线处代码补充完整。
import pandas as pd
def px(file_week):
df=pd.read_excel(file_week)
df=df.sort_values( ,ignore_index=True)
#按班级升序排序,参数ignore_index=True表示更新索引
return df
(2)统计某一周各运动项目的参与人次,并绘制柱形图,如图c所示,部分Python代码如下:
import matplotlib.pyplot as plt
s=input("请输入文件名: ")
df=px(s)
df1=df.groupby("运动项目".as_index=False). ① #统计各运动项目参与人次
df1.rename(columns={"学号":"参与人次"},inplace=True) #更改列标题
plt.bar( ② )
plt.xlabel("运动项目")
plt.ylabel("参与人次")
plt.show()
划线处应填入的代码为 (单选,填字母)。
A.①count() ②df1["参与人次"], df1["运动项目"]
B.①sum() ②df1["参与人次"], df1["运动项目"]
C.①sum() ②df1.运动项目, df1.参与人次
D.①count() ②df1.运动项目, df1.参与人次
(3)统计某一周每班各学生的总运动时长后,比较得出该周每班最高的两位时长,部分Python程序代码如下,请在划线处填入合适的代码。
qp=[[0 for i in range(m)]for j in range(n)]
'''
定义数组qp记录每班各学生一周运动总时长,n为班级数,m为每班人数。其中qp[0][0]~qp[0][m-1]存储1班1号~m号同学的每周运动总时长,依次类推,qp[n-1][0]~qp[n-1][m-1]存储n班1号~m号同学的每周运动总时长。
'''
print("本周每班最高的两位时长分别为: ")
i=0
while i
cla=df["班级"][i]
①
if i!=0 and df["班级"][i]!=df["班级"][i-1] or ② :
cla=df["班级"][i-1]
k1=0;k2=0
for j in range(1,len(qp[cla-1])):
if qp[cla-1][j]>qp[cla-1][k1]:
③
k1=j
elif qp[cla-1][j]>qp[cla-1][k2]:
k2=j
print(cla,"班",qp[cla-1][k1].qp[cla-1][k2])
i=i+1
(4)统计某一周各运动项目的参与人次后绘制柱形图如图c所示,由图可知,该周参与人气最高的运动项目为 。
答案 (1)"班级" (2)D (3)①qp[cla-1][num-1]+=df["运动时长"][i] ②i==len(df)-1 ③k2=k1
(4)跑步
8.(2024届宁波模拟,13)已知某年级有6个班级,所有学生名单存储在文件“name.csv”中(如图1),学校举行某趣味活动项目中,需要每个班抽3名代表参加比赛,请编写一个随机抽取程序,执行效果如图2。请回答以下问题:
(1)加框处代码的作用是 。
(2)实现上述功能的部分Python程序如下,请在划线处填写合适的代码。
import csv
import random #数据读入
f=open("name.csv","r")
flines=csv.reader(f)
name_list=[]
m=6 #班级总数
total=18 #参赛总人数
for line in flines:
if line[0]=="班级":
continue #跳过当前循环的剩余语句,继续进行下一次循环
name_list.append(line)
①
flag=[False]*n
grade=[3]*m
i=0
while i
bj=int(name_list[p][0])
if flag[p]==False:
if grade[bj-1]>0:
flag[p]=True
④
i+=1
print("抽取名单为: ")
print("班级","姓名")
for i in range(n):
if flag[i]:
print(name_list[i][0],name_list[i][1])
f.close()
答案 (1)列表name_list中的数据不包括标题行
(2)①n=len(name_list) ②0 ③n-1 ④grade[bj-1]-=1
9.(2023杭州地区重点中学联考,14)小明利用“在线社团报名系统”收集了全校学生的社团报名信息,并将报名数据导出到“社团报名.xlsx”中,如图1所示。然后编写Python程序对报名数据进行处理,生成分别以班级名和社团名为文件名的 Excel 文件,以便分发给相应的社团指导老师和班主任。
(1)在对表格进行数据整理时发现,关于“Jacky.Y” 同学的记录可能存在的数据问题是 (选填:A.数据缺失 B.数据异常 C.逻辑错误 D.数据格式不一致)。
(2)其中生成每个社团名单文件的过程是:先对报名数据按社团名称进行分类,并对选报同一社团的学生按班级进行升序排序,然后生成各个社团名单文件,如图 2所示。对应的程序代码如下,请在划线处填写合适的代码。
import pandas as pd
def read_file(filename):
#读入报名数据的原始文件,并将表中的数据转换成列表,代码略
def save_file(a): #保存名单到相应社团的Excel电子表格文件
df=pd.DataFrame(a,columns=["班级","姓名","选报社团"])
df.to_excel( ① )+".xlsx",index=False)
a=read_file("社团报名.xlsx")
n=len(a)
#按社团名(参照拼音的字母顺序)进行升序排序,代码略
#统计各社团人数,存在列表 rs 中,rs=[["滑板社",36],…],代码略
s=0
for i in range(len(rs)):
②
left,right=s, s+num-1
while left < right:
imin=imax=left
for k in range(left+1,right+1):
if a[k][0] < a[imin][0]:
imin=k
elif a[k][0] > a[imax][0]:
imax=k
if imin !=left:
a[imin],a[left]=a[left],a[imin]
if imax==left:
③
if imax !=right:
a[imax],a[right]=a[right],a[imax]
left=left+1; right=right-1
④
s+=num
答案 (1)B (2)①a[0][2]或df.at[0,"选报社团"] 或 df["选报社团"][0] ②num=rs[i][1] ③imax=imin
④save_file(a[s:s+num])
题组二
1.(2022诸暨期末,4)使用pandas编程处理数据DF1,下列选项能实现行列转置操作的是( )
A.DF1.T B.DF1.columns
C.DF1.values D.DF1.index
答案 A
2.(2022宁波奉化期末,9) 有如下Python程序段:
import pandas as pd
s=pd.Series(range(5,11,3))
s[1]=15
print(s)
该程序执行后,输出的结果是( )
1 15 2 8 dtype: int64 0 5 1 15 dtype: int64 1 15 2 8 3 11 dtype: int64 0 5 1 15 2 11 dtype: int64
A. B. C. D.
答案 B
3.(2022宁波咸祥中学期中,16)小明收集了某超市饮料销售情况相关数据,并使用Excel软件进行处理,如图a所示。
请回答下列问题:
(1) 区域 I3:I15 的数据是通过公式计算得到的。在I3单元格输入公式后, 用自动填充功能完成 I4:I15 的计算,则I3单元格中的公式是 。 (占销售总额百分比=销售额(元)/销售总额(元))
(2)若因误操作将 I16 单元格删除,则 I3 单元格会显示 (选填字母:A.#VALUE B.#DIV/0! C.###### D.#REF! )。
(3)要将类别为“可乐”的饮料以“毛利润(元)”为主要关键字降序排序, 则选择排序的区域为 。
(4)小王根据图 a 中的数据,制作了一张反映橙汁类饮料销售额和毛利润对比的图表,如图b 所示,则建立该图表的数据区域是 。将E8单元格数值修改成6.00,是否会影响该图表 (选填:是/否)
图b
答案 (1)=G3/$I$16或=G3/I$16 (2)B (3)B8:I11
(4)B2,G2:H2,B5:B7,G5:H7;否
4.(2022台州启超中学期中,16)APP活跃人数数据存储在“app.xlsx”文件中,如图所示,现要编程统计结果,请回答下列问题:
若要把“app.xlsx”第1张工作表中的信息导入到book1对象中,并进行统计,实现这个功能的Python代码如下,在程序划线处填入合适的代码。
import pandas as pd
book1= (1) #读取app.xlsx文件数据,并存储在book1对象中
book1_sum= (2)
#计算10月人数之和
book1_aver= (3)
#计算11月人数平均值
book1_g= (4)
#按应用领域分组统计
book1_sort= (5)
#按11月人数值,降序排序
print("10月人数之和:",book1_sum)
print("11月人数平均值:",book1_aver)
答案 (1)pd.read_excel("app.xlsx") (2)book1["10月人数"].sum() (3)book1["11月人数"].mean()
(4)book1.groupby("应用领域")
(5)book1.sort_values("11月人数",ascending=False)
5.(2022宁波奉化期末,14)小孙收集了2016年到2020年的各地区粮食生产总量并存储在“lscl.xlsx”文件中,如图a所示,现使用Python对其进行数据处理,并实现数据可视化,绘制的图表如图b所示。
实现如上功能的代码如下,请回答以下问题。
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family': 'SimHei'})
#设置中文字体
df=pd.read_excel("lscl.xlsx")
df. ① ("2020年",ascending=False,inplace=True)
df1=df.head(10)
x= ②
y=df1["2020年"]
plt.figure(figsize=(8,6))
plt. ③ ("2020年粮食产量TOP10")
plt.bar(x,y,label="2020年")
plt.xlabel("地区")
plt.legend()
④
(1)请在划线处填入合适的代码语句,以实现以上功能。
(2)代码语句“plt.bar(x,y,label="2020年")”的功能为绘制如图b所示的图像,能够实现相同功能的语句是 (多选题,少选得1分,多选不得分)。
A.df.head(10).plot("地区","2020年")
B.df[:10:].plot("地区","2020年",kind="bar")
C.plt.plot(x,y,label="2020年",kind="bar")
D.plt.bar("地区","2020年",label="2020年")
E.df1.plot("地区","2020年",kind="bar")
答案 (1)①sort_values ②df1["地区"] 或 df1.地区
③title ④plt.show() (2)BE
6.(2022杭州场口中学、桐庐富春中学检测,16)在月考之后,学校教务员拿到了高一年级月考的基础成绩并用Excel软件进行数据处理,如图1所示。请回答下列问题:
图1
(1)区域M2:M645的数据是通过在M2单元格输入公式并自动填充得到的,则M645单元格中的公式是 。
(2)为了分析各班级的数学平均分,设计了如下Python程序,利用其绘制各班数学平均分图表,如图2所示:
结合上图的效果,请在程序划线处填写合适的代码。
import matplotlib.pyplot as plt
import pandas as pd
df=pd.read_excel('高一月考成绩.xlsx')
df1=df.groupby("班级"). ①
plt.bar(df1.index, ② )
plt.title("高一各班数学平均分")
plt.ylim(40,100)
plt.xlabel( ③ )
plt.ylabel("分数")
plt.show()
答案 (1)=SUM(D645:L645) (2)①mean() ②df1.数学 ③"班级"
7.(2023 三月百校联考,14)李明收集了梅西2004年至2022年俱乐部比赛数据,保存在“梅西俱乐部详细比赛数据.xlsx”文件中,部分数据如图a所示,现在利用pandas模块处理数据。
(1)梅西2004年10月—2021年7月效力于巴塞罗那俱乐部,2021年8月转会至巴黎圣日耳曼俱乐部,现在李明想知道梅西每个赛季的胜率,实现上述功能的Python程序如下,请在划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("梅西俱乐部详细比赛数据.xlsx")
df['年']=pd.to_datetime(df["时间"]).dt.strftime('%Y').astype(int)
df['月']=pd.to_datetime(df["时间"]).dt.strftime('%m').astype(int)
df['胜负情况']=" "
for i in range(len(df)):
f=True;z=0;k=0
for c in df["比分"][i]:
if ① :
if f:
z=z*10+int(c)
else:
k=k*10+int(c)
else:
f=not f
jlb="巴塞罗那"
if df["年"][i]*100+df["月"][i]>=202108:
②
if (df["主队"][i]==jlb and z>k) or (df["客队"][i]==jlb and z
elif z==k:
df['胜负情况'][i]="平"
else:
df['胜负情况'][i]="负"
g=df.groupby(df["年"],as_index=True).count()
③
g1=df1.groupby(df1["年"],as_index=True).count()
g["胜率"]=g1["胜负情况"]/g["胜负情况"]*100
(2)图b为2004—2022年梅西俱乐部比赛胜率统计图。
2004-2022年梅西俱乐部比赛胜率统计
plt.plot( , marker='^')
plt.title("2004-2022年梅西俱乐部比赛胜率统计")
plt.show()
方框处代码为 (多选:填字母)。
A.g["年"],g["胜率"] B.g["年"],g.胜率
C.g.index,g["胜率"] D.g.index,g.胜率
答案 (1)①c!="-" 或c>="0" and c<="9" ②jlb="巴黎圣日耳曼" ③df1=df[df['胜负情况']=="胜"] (2)CD
8.(2022湖州三贤联盟期中,14)小张同学为了更好地了解冬奥会,从网上收集了历届冬奥会各个项目比赛信息,收集到的部分数据如图1所示。
图1
图2
为分析数据,小张编写了如下程序:
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
df=pd.read_csv("dongao.csv")
#删除所有未获得奖牌的记录,并将奖牌列中的"G"修改为"金牌","S"修改为"银牌","B"修改为"铜牌"
jp={'G':'金牌','S':'银牌','B':'铜牌'}
for i in df.index:
if ① :
df=df.drop(i)
else:
df.at[i,'奖牌']=jp[df.at[i,'奖牌']]
#对输入国家每届的奖牌数进行统计,并制作相应图表,如图2所示
nt=input("请输入国家名称:")
df1=df[df['国家']==nt]
df3=pd.DataFrame(df2) #将分组后数据生成新的二维结构,索引为“届次”,列标题为“奖牌”
x=df3.index
y= ②
plt.title(nt+"历届冬奥会奖牌趋势图")
plt. ③ (x,y)
plt.show()
(1)在划线处填上合适的代码。
(2)为了能显示某国历届冬奥会奖牌变化,需在加框处添加的语句为 (多选)。
A.df2=df1.groupby('奖牌')
df2=df1.届次.count()
B.df2=df1.groupby('届次')
df2=df2['奖牌'].count()
C.df2=df1.groupby('奖牌')['届次'].count()
D.df2=df1.groupby('届次').奖牌.count()
答案 (1)①df.at[i,'奖牌']=='0'或 df.奖牌[i]=='0'或 df['奖牌'][i]=='0' ②df3["奖牌"]或 df3.奖牌 ③plot (2)BD
9.(2023十校联盟联考,14)小明从网上下载了豆瓣图书1900—2017年间出版的图书数据,存储在Excel文件中,如图a所示,数据表已按出版年份升序排好,包含书名、作者、出版社、出版年份、价格、评分以及评论数量。他要编写一个Python程序快速对图书数据进行分析。
(1)为了求评论数量累计最高的作者及其出版的图书平均评分,小明需要对图a所示的表中数据进行整理,则下列说法正确的是 (多选,填字母)。
A.第3行和第4行数据重复,删除其中一行即可
B.通过检测发现F56168单元格的数据存在错误,应进行修正
C.删除“出版社”和“出版年份”两列数据,不影响分析结果
D.“评分”及“评论数量”为0的数据没有任何价值,可以直接删除
(2)小明利用整理好的数据,编写并运行程序,结果如图b所示。
作者 评论数量
0 [日]村上春树 679101.0
1 [日]东野主吾 664106.0
2 韩寒 623116.0
3 郭敬明 620571.0
4 [英]J.K.罗琳 462476.0
评论数量累计最多的作者是:[日]村上春树 共出版了34部作品,平均评分为8.01
图b
实现上述结果的Python程序如下:
import pandas as pd
df=pd.read_excel("books.xlsx")
df1=df.groupby("作者", as_index=False)
df2=df1.评论数量.sum()
dfsort=df2.sort_values("评论数量" ,ascending=False,ignore_index=True)
print(dfsort.head(5))
#输出评论数量累计前五名作者
top= ①
dfbk=df[df.作者==top]
#根据作者检索出相应的作品
avg=dfbk.评分.mean()
print("评论数量累计最多的作者是:", top)
print("共出版了", ② ,"部作品,平均评分为" , round(avg,2))
则程序中划线①②处应填入的代码为:
① ;
② 。
答案 (1)BC (2)①dfsort.at[0,"作者"]或dfsort["作者"][0]或其他等价答案 ②len(dfbk)或dfbk.书名.count()或dfbk["书名"].count()
10.(2024浙江1月选考,14,7分)某学院举行运动会,比赛设跳高、100米等项目,每个项目分男子组和女子组。现要进行报名数据处理和比赛成绩分析。请回答下列问题:
(1)运动会报名规则为:对于每个项目的男子组和女子组,每个专业最多各报5人(如“软件工程”专业在男子跳高项目中最多报5人)。软件工程专业的报名数据保存在DataFrame对象df中,如图a所示。若要编写Python 程序检查该专业男子跳高项目报名是否符合规则,下列方法中, 正确的是 (单选,填字母)。
A.从df中筛选出性别为“男”的数据dfs, 再从dfs中筛选出项目为“跳高”的数据,判断筛选出的数据行是否超过5行
B.对df中数据按性别排序并保存到dfs中,再从dfs中筛选出项目为“跳高”的数据,判断筛选出的数据行是否超过5行
C.从df中筛选出项目为“跳高”的数据dfs,判断dfs中是否有连续5行以上的男生数据
(2)运动员比赛成绩的部分数据如图b所示。根据已有名次计算得分,第1名至8名分别计9,7,6,5,4,3,2,1分,第8名之后计0分。实现上述功能的部分Python程序如下,请在程序中划线处填入合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
#读取如图b 所示数据,保存到DataFrame对象df1中,代码略
f=[9,7,6,5,4,3,2,1]
for i in range(0,len(df1)):
rank=df1.at[i,"名次"] #通过行、列标签取单个值
score=0
if rank<=8:
df1.at[i,"得分"]=score
(3)根据上述df1中的得分数据,统计各专业总分,绘制如图c所示的柱形图,实现该功能的部分Python程序如下:
df2=df1.groupby(" ",as_index=False).sum() #分组求和
#设置绘图参数,代码略
plt.bar(x,y) #绘制柱形图
①请在程序中划线处填入合适的代码。
②程序的方框中应填入的正确代码为 (单选,填字母)。
A.x=df1["专业"]
y=df1["总分"]
B.x=df2["专业"]
y=df2["得分"]
C.df1["专业"]="专业"
df1["总分"]="总分"
D.df2["专业"]="专业"
df2["得分"]="得分"
答案 (1)A (2)score=f[rank-1]或score=f[int(rank)-1] (3)①专业 ②B
21世纪教育网 www.21cnjy.com 精品试卷·第 2 页 (共 2 页)
21世纪教育网(www.21cnjy.com)
同课章节目录