对c语言的深入讨论
图片预览











文档简介
(共52张PPT)
12.1 对函数的深入讨论
12.2 编译预处理
12.3 标识符的作用域
12.4 函数的存储分类
12.5 动态存储分配
12.6 定义用户类型
12.7 对C语言的一些说明
第十二章 对C语言的深入讨论
12.1.1 main函数的参数
12.1.2 函数指针
12.1.3 函数的递归调用
12.1 对函数的深入讨论
12.1.1 main函数的参数
main函数是C程序中的主函数,是整个程序的入口,每个C程序有且只有一个main函数。
带参数的main函数
main函数通常有两个参数,其定义形式如下:
main(int argc,char *argv[])
{ …… }
argc和argv是main函数的两个参数,名称可改变,但参数类型是C规定好的,不可改变。
第一个参数必须是整型,第二个参数必须是字符串的指针,也就是char类型的二维指针。第二个参数也可定义为char **argv。
main函数参数的作用:
argc传入命令参数的个数。
argv传入命令参数的各个字符串。
例:如果我们把一个C语言源程序保存为my.c,经过编译、链接后会产生一个my.exe的可执行程序,这样我们就可以离开C语言的开发环境,直接运行该程序了,例如在DOS环境中输入如下程序:
my a command line (CR代表回车)
在上面的命令中,my是可执行程序,后面的a、command和line是my命令的参数。这些参数就是通过main函数的参数传递给程序的。my也被当作一个命令参数被传入。
在上面命令中,argc的值为4,表示有4个命令参数,argv指向一个指针数组,该数组有4个字符串数组元素,分别指向4个命令参数my、a、command和line,如下图所示:
argv[3]
argv[2]
argv[1]
argv[0]
argv
line
command
a
my
命令行各参数间以空格或Tab键隔开,如果参数包含空格,必须把参数放在一对双引号内,例如:
my “a command” line (CR代表回车键)
则a command被当成一个参数.
12.1.2 函数指针
在C语言中,函数名代表一个函数的入口地址,因此可以定义一个指针指向该入口地址,即指向函数的指针。
指向函数的指针变量定义格式如下:
函数返回值类型 (*指针名)(函数参数列表);
例 以下程序使用函数指针调用函数
int fun(int a,int *b)
{ …… }
main()
{ int (*pfun)(int,int*),a,b,s;
pfun=fun;
……
s=(*pfun)(a,&b);
……
}
/*此处定义了pfun这个函数指针*/
/*将函数名fun赋给指针pfun,即让pfun指向fun*/
/*此处通过pfun指针来调用fun函数,相当于调用s=fun(a,&b)*/
12.1.3 函数的递归调用
定义:函数直接或间接的调用自身叫函数的递归调用。
说明:
若要采用递归的方法解决问题,可以把要解决的问题转化为一个新的问题,而这个新的问题的解决仍与原来的解决方法相同,只是处理的对象有规律的递增或递减,从而应用这个转化过程使问题得到解决。
C编译系统对递归函数的自调用次数没有限制。
每调用函数一次,在内存堆栈区分配空间,用于存放函数变量、返回值等信息,所以递归次数过多,可能引起堆栈溢出。
必须有一个明确的结束递归的条件。
例 以下程序运行后的输出结果是:
fun(int x)
{ if(x/2>0) fun(x/2);
printf(“%d”,x);
}
main()
{ fun(6); }
输出结果:136
main()
fun(6)
fun(3)
fun(1)
x为6
输出6
x为3
输出3
x为1
输出1
12.2.0 概述
12.2.1 宏
12.2.2 文件包含
12.2 编译预处理
在C中,凡是以”#”开头的行,都称为“编译预处理”命令行,编译预处理命令行并不是C语言本身的组成部分,不能直接对它们编译,而是由预处理程序在编译前作出相应的处理。
作用:对源程序编译之前做一些处理,生成扩展C源程序
种类
宏定义 #define
文件包含 #include
格式:
“#”开头
占单独书写行
语句尾不加分号
12.2.0 概述
如 if(x==YES) printf(“correct!\n”);
else if (x==NO) printf(“error!\n”);
展开后: if(x==1) printf(“correct!\n”);
else if (x==0) printf(“error!\n”);
12.2.1 宏
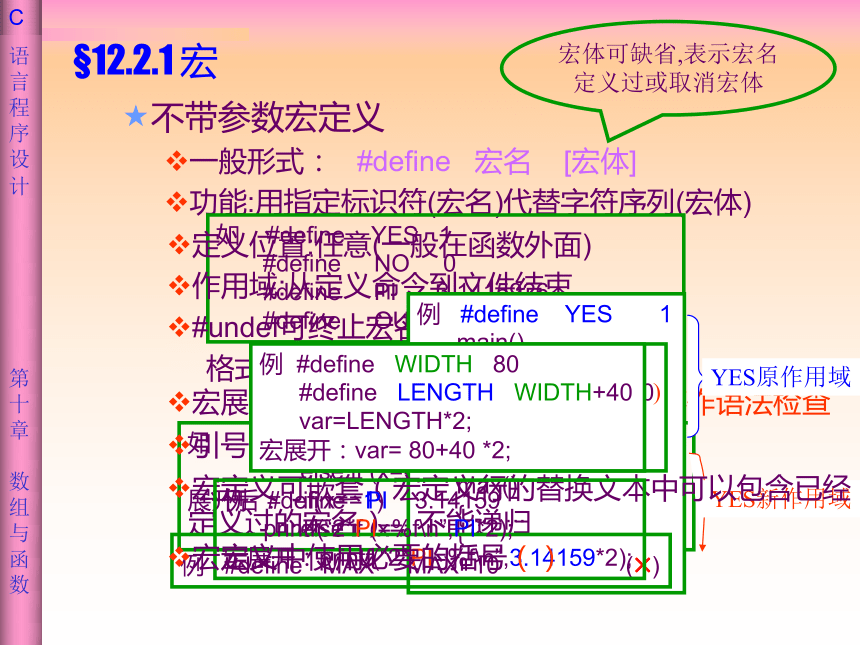
不带参数宏定义
一般形式: #define 宏名 [宏体]
功能:用指定标识符(宏名)代替字符序列(宏体)
宏展开:预编译时,用宏体替换宏名---不作语法检查
如 #define YES 1
#define NO 0
#define PI 3.1415926
#define OUT printf(“Hello,World”);
宏体可缺省,表示宏名
定义过或取消宏体
定义位置:任意(一般在函数外面)
作用域:从定义命令到文件结束
#undef可终止宏名作用域
格式: #undef 宏名
例 #define YES 1
main()
{ ……..
}
#undef YES
#define YES 0
max()
{……..
}
YES原作用域
YES新作用域
宏定义可嵌套(宏定义行的替换文本中可以包含已经定义过的宏名),不能递归
例 #define MAX MAX+10 ( )
引号中的内容与宏名相同也不置换
例 #define PI 3.14159
printf(“2*PI=%f\n”,PI*2);
宏展开:printf(“2*PI=%f\n”,3.14159*2);
宏定义中使用必要的括号()
例 #define WIDTH 80
#define LENGTH WIDTH+40
var=LENGTH*2;
宏展开:var= 80+40 *2;
( )
( )
例 #define WIDTH 80
#define LENGTH WIDTH+40
var=LENGTH*2;
宏展开:var= 80+40 *2;
说明:
宏名一般用大写字母。这不是语法规定,只是一种习惯
可以使用宏名代替一个字符串
当宏定义在一行中写不下,需要在下一行继续时,只需在最后一个字符后紧接一个反斜线“\”。例如:
#define LEAP_YEAR year % 4==0\
&& year %100!=0 || year % 400==0
注意在第二行开始不要有空格,否则空格会一起被替换
宏名的有效范围为定义命令之后到本源文件结束,除非用#undef命令终止宏名的作用域
对程序中用双引号括起来的字符串内的子串和用户标识符中的成分不做替换
同一个宏名不能重复定义,除非两个宏定义命令行完全一致
带参数宏定义
功能:将一个带参数的表达式定义为一个带参数的宏。
一般形式: #define 宏名(参数表) 宏体
例 #define S (r) PI*r*r
相当于定义了不带参宏S,代表字符串“(r) PI*r*r”
宏展开:形参用实参换,其它字符保留
宏体及各形参外一般应加括号()
例 #define S(a,b) a*b
………..
area=S(3,2);
宏展开: area=3*2;
不能加空格
例 #define POWER(x) x*x
x=4; y=6;
z=POWER(x+y);
宏展开:z=x+y*x+y;
一般写成: #define POWER(x) ((x)*(x))
宏展开: z=((x+y)*(x+y));
说明:
在替换带参数的宏名时,一对圆括号不能少,圆括号中实参的个数应该与形参个数相同,若有多个参数,各参数用逗号隔开
与不带参数的宏相同,同一个宏名不能重复定义,除非两个宏定义命令行完全一致
#define MAX(x,y) (x)>(y) (x):(y)
…….
main()
{ int a,b,c,d,t;
…….
t=MAX(a+b,c+d);
……
}
宏展开:t=(a+b)>(c+d) (a+b):(c+d);
int max(int x,int y)
{ return(x>y x:y);
}
main()
{ int a,b,c,d,t;
…….
t=max(a+b,c+d);
………
}
例 用宏定义和函数实现同样的功能
带参的宏与函数区别
带参宏
函数
处理过程
不分配内存
简单的字符置换
分配内存
先求实参值,再代入形参
处理时间
编译时
程序运行时
参数类型
无类型问题
定义实参,形参类型
程序长度
变长
不变
运行速度
不占运行时间
调用和返回占时间
12.2.2 文件包含
功能:一个源文件可将另一个源文件的内容全部包含进来
一般形式: #include “文件名”
或 #include <文件名>
#include “file2.c”
file1.c
file2.c
file1.c
file2.c
A
B
A
处理过程:预编译时,用被包含文件的内容取代该预处理命令,再对“包含”后的文件作一个源文件编译
<> 直接按标准目录搜索
“” 先在当前目录搜索,再搜索标准目录
可指定路径
被包含文件内容
源文件(*.c)
头文件(*.h)
宏定义
数据结构定义
函数说明等
文件包含可嵌套
#include “file2.c”
file1.c
A
file3.c
C
#include “file3.c”
file2.c
B
file1.c
A
file3.c
file2.c
说明:
#include命令行通常书写在文件的开头,故有时也把包含文件称作“头文件”。头文件名可以由用户指定,其后缀不一定用“.h”。
包含文件中,一般包含一些公用的#define命令行、外部说明或函数的原型说明。例如stdio.h就是这样的头文件。
当包含文件修改后,对包含该文件的源程序必须重新进行编译连接。
在一个程序中,允许有任意多个#include命令行。
在包含文件中还可以包含其他文件。
例 文件包含举例
/*14.h*/
#define N 10
#define f2(x) (x*N)
/*14.c*/
#include
#define M 8
#define f(x) ((x)*M)
#include “14.h”
main()
{ int i,j;
i=f(1+1); j=f2(1+1);
printf(“%d %d“,i,j);
}
运行结果:16 11
12.3.0 概述
12.3.1 存储分类
12.3.2 局部变量
12.3.3 全局变量
12.3 标识符的作用域
12.3.0 概述
标识符必须先定义后使用,用户定义的标识符都有一个有效的作用域,所谓变量的作用域,指的是程序中的某一部分。只有在这一部分,该变量才是有效的,才可以被C编译和连接程序所识别。
变量是对程序中数据的存储空间的抽象
内存
…….
main()
{ int a;
a=10;
printf(“%d”,a);
}
编译或函数调用时为其分配内存单元
10
2000
2001
程序中使用变量名对内存操作
12.3.1 存储分类
变量的分类
生存期:变量在某一时刻存在-------静态变量与动态变量
作用域:变量在某区域内有效-------局部变量与全局变量
变量的存储类型
auto -----自动型
register-----寄存器型
static ------静态型
extern -----外部型
变量定义格式: 存储类型 数据类型 变量列表;
或 数据类型 存储类型 变量列表;
变量的存储类型可放在类型名的左边,也可放在类型名的右边.
如: int sum;
auto int a,b,c;
register int i;
static float x,y;
或: int anto a,b,c;
int register i;
float static x,y;
12.3.2 局部变量
局部变量有3种类型:anto、register和static。
anto变量
在定义局部变量时,如果没有指定相应的存储类,则系统默认为anto类型。
anto类型的变量只能在定义它的函数或复合语句内有效。当程序进入定义该变量的函数或复合语句时,系统为这些变量临时分配内存单元。当程序离开这个函数或复合语句时,系统将销毁这些内存单元,使其数据不再有效。
例 int sum;
等价于:
anto int a;
或 int anto a;
例 main()
{ int i=1,i_sum;
{ float f, f_sum;
int i;
i=10;
printf(“(1) i=%d\n”,i);
}
printf(“(2) i=%d\n”,i);
}
输出结果:
(1) i=10
(2) i=1
register变量
register变量(寄存器变量)与anto变量一样,是自动类变量,其作用域和生存期与anto变量一样。
与anto变量唯一区别是anto变量在内存中分配存储空间,而register变量在CPU的寄存器分配。
说明:
寄存器变量的运行速度要远远大于其他类型的变量,读者可根据需要在必要的时候使用寄存器变量。
由于PC机中寄存器的数量极其有限,使用过多的寄存器变量可能会影响程序其他部分的运行效率。
由于寄存器的数量有限,系统在分配寄存器变量时有可能分配不成功,这时系统将为register变量分配anto变量。因此register说明只是对编译系统的一种建议,而不是强制性的。
由于register变量分配的是寄存器而不是内存,因此register类型的变量没有地址,不能使用取地址运算符。
例 main()
{ register int i=1;
int s=0;
for(i=0;i<100;i++)
s+=i;
printf(“sum=%d\n”,sum)
}
static变量
在函数内部或复合语句中定义变量时,如果使用static来说明,就构成了静态局部变量。
静态局部变量的作用域与anto和register类型变量一样,但其生存期却完全不同。
静态局部变量在内存的静态存储区占据着永久性的存储单元,即使离开定义该变量的函数(或复合语名),该存储单元也不会被销毁。当下次再进入定义该变量的函数(或复合语句)时,存储单元仍然保存着原来的值。
静态局部变量的初值是在编译时赋予的,在程序被执行时不再赋初值。
对未赋初值的静态局部变量,C语言编译系统自动给它赋初值0。
例 fun(int a)
{ int b=0;static int c=3;
b++;
c++;
return(a+b+c);
}
main()
{ int i, a=5;
for(i=0;i<3;i++)
printf(“ %d %d”,i,fun(a));
printf(“\n”);
}
输出结果:
0 10 1 11 2 12
第几次调用 调用时初值 调用结束时的值
a b c a b c 函数值
第1次调用 5 0 3 5 1 4 10
第2次调用 5 0 4 5 1 5 11
第3次调用 5 0 5 5 1 6 12
12.3.3 全局变量
在函数外部任意的位置定义的变量,称为全局变量。全局变量都是静态变量,其作用域从定义的位置开始,到整个文件结束为止。
例 int sum;
int fun1()
{ sum+=20; }
int a;
int fun2()
{ a=20; sum+=a; }
main()
{ sum=0;
fun1();
a=8;
fun2();
printf(“sum=%d a=%d”,sum,a);
}
int p=1,q=5;
float f1(int a)
{ int b,c;
…….
}
int f3()
{…..
}
char c1,c2;
char f2(int x,int y)
{ int i,j;
……
}
main()
{ int m,n;
…….
}
c1,c2的作用范围
p,q的作用范围
extern char c1,c2;
c1,c2
的作用范围
扩展后
c1,c2
的作用范围
扩展后
extern char c1,c2;
可以使用extern和static来说明全局变量。
在同一编译单位内使用extern来说明全局变量。
当调用全局变量的函数在该全局变量前面时,可使用extern说明全局变量。此时该变量的作用域就从extern说明处开始。
使用extern说明全局变量,并不是对变量进行了重新定义,它仅仅是告诉编译器,该变量已经定义,可使用了。
在整个程序中,对一个全局变量的定义只能出现一处,它要求编译器分配内存单元。在定义时不能出现extern说明符。
在整个程序中,对全局变量的说明可出现在多处,它并不分配存储单元,仅仅告诉编译器,该变量已在别的地方定义了。在对全局变量进行说明时,必须使用extern说明符。
在不同编译单位内使用extern来说明全局变量。
我们知道,C是由函数构成。当C语言的源程序过大时,为了管理上的方便,往往把源程序分别存放在若干个不同的源文件中。这些源文件可以单独进行编译,生成目标文件(obj文件)。然后再使用链接程序将这些目标文件连接成一个可执行文件(exe文件)。通常,人们把每个可以单独编译的源文件称为编译单位。
在不同编译单位内需要使用同一个全局变量时,就必须使用extern来对变量进行说明。
如果在每个编译单位都定义一个相同名称的全局变量,在对每个编译单位进行编译时并不会出现错误,但在编译生成目标文件进行链接时,就会出现“重复定义变量”的错误。可在其中一个编译单位内定义变量,而在其他的编译单位内使用extern来说明变量。
例 /*文件file1.c*/
int a;
void fun()
main()
{ a=10;
printf(“In main a=%d\n”,a);
a=100;
fun();
}
/*文件flie2.c*/
extern int a;
void fun()
{ printf(“In fun a=%d\n”,a); }
使用static说明全局变量。
当使用static说明符来说明全局变量时,则这个全局变量为静态全局变量,静态全局变量只能被本编译单位使用,不能被其他编译单位使用。
例 /*文件file1.c*/
static int a;
void fun()
main()
{ a=10;
printf(“In main a=%d\n”,a);
a=100;
fun();
}
/*文件flie2.c*/
extern int a;
void fun()
{ printf(“In fun a=%d\n”,a); }
12.4.1 用extern说明函数
12.4.2 用static说明函数
12.4 函数的存储分类
函数不可以嵌套定义,也就是在函数内部不可以再定义函数,所以所有函数在本质上都是外部的,可在定义函数时使用static和extern说明符来改变函数的作用域。
12.4.1 用extern说明函数
可在函数返回值类型前面加上extern来说明函数,使用extern说明的函数称为外部函数。
例: extern int fun()
{ …… }
extern可省略,我们以前定义的函数都属于外部函数。
外部函数可以被其他编译单位内的函数调用,如果在其他编译单位需要调用该函数,必须在调用前使用extern对所调用的函数进行说明。
12.4.2 用static说明函数
使用static进行说明的函数称为静态函数,也叫内部函数。静态函数只能被本编译单位内的函数调用,不能被其他编译单位内的函数调用。
12.5.1 malloc函数
12.5.2 free函数
12.5.3 calloc函数
12.5 动态存储分配
12.5.1 malloc函数
C语言提供了4个函数用于内存空间的动态分配与释放,它们分别是malloc、calloc、realloc和free。
malloc函数
作用:动态分配内存单元。
调用形式:malloc(size)
返回值类型:void *
如果系统有足够的内存可供分配,函数返回一个指向有size个字节的存储区首地址,该首地址的基类型为void类型
若没有足够的存储空间,函数返回空值(NULL)
unsigned int类型,表示需要分配的字节数
例 malloc函数应用举例
int *p;
float *q;
……
p=(int*)malloc(2);
q=(float*)malloc(4);
……
在本例中p、q被定义成了两个指针变量,基类型分别为int类型和float类型。通过malloc函数为这两个指针变量分配内存单元。在调用malloc函数时,传入需要分配的字节数,int类型占用两个字节,float类型占用4个字节,则在调用malloc函数时分配传入参数2和4。
由于malloc函数返回的是void*类型的指针,与变量p和q的基类型不相符,因此需要将其进行强制类型转换。
若有:
if(p!=NULL) *p=6;
if(q!=NULL) *q=3.8;
赋值后数据的存储情况如下:
p
6
q
3.8
说明:
动态分配得到的内存单元没有名字,只能通过指针变量来引用它。
一旦指针变量的值发生改变,原存储单元及所存数据都无法再引用。
通过malloc函数要配的动态存储单元中没有确定的初值。
在调用malloc进行存储分配时,如果不能确定数据类型所占字节数,可以调用sizeof运算符来求得。如上例可改为:
p=(int*)malloc(sizeof(int));
q=(float*)malloc(sizeof(float));
这是一种常用的方式,由系统来计算指定数据类型的字节数
12.5.2 free函数
free函数
作用:释放动态分配的内存单元。
调用形式:free(p)
返回值:无
说明:
静态存储分配的变量和数组,在生存期过后,或者程序运行结束后,所占用的存储单元会由系统自动释放。
动态分配的内存单元,需手动进行释放。
free函数是将指针p所指向的空间释放,使这部分空间可以由系统得新分配。
指向动态分配函数分配的地址
12.5.3 calloc函数
calloc函数
作用:分配单个数据类型的存储单元或分配多个同一类型的连续的存储空间。
调用形式:calloc(n,size);
返回值:基类型为void的指针。
分配成功,函数返回存储空间的首地址
否则,返回空值
说明:
调用形式中n和size的类型都为unsigned int
calloc函数用来给n个同一类型的数据项分配连续的存储空间,其中每个数据项的长度为size个字节
由calloc分配的存储空间,系统自动置初置0。
使用calloc函数分配的动态存储单元,同样必须用free函数释放。
例: int *pint;
pint=(int*)calloc(10,sizeof(int));
程序调用calloc函数在内存中分配了10个连续的int类型的存储单元,由pint指向存储单元的首地址。每个存储单元可以存放一个int型数据。
释放存储空间:
free(pint);
12.6 定义用户类型
C语言不仅提供了丰富的数据类型,而且还允许由用户自己定义类型说明符,也就是说允许由用户为数据类型取“别名”。类型定义符typedef即可用来完成此功能。 。
C语言提供了typedef关键字,用以说明一种新的数据类型名,说明新类型名的形式为:
typedef 类型名 标识符;
在typedef语句中,“类型名”必须是在此语句之前就已经定义的类型标识符,“标识符”是一个用户自定义标识符,用作新的类型名。
typedef的作用仅仅是用作“标识符”来代表已存在的“类型名”,并未产生新的数据类型。原有的类型名依然有效。
例12.16 typedef int MYINT;
本例中,把MYINT标识符说明成了一个int类型的类型名。在此说明后,可以用标识符MYINT来定义整型变量,如:
MYINT i,j; int i,j;
由此可以看出,MYINT标识符也就是关键字int的一个别名。
对typedef的几点说明如下:
(1)习惯上将用typedef说明的新类型名用大写字母表示,以便与程序中其他标准类型标识符相区别。
(2)用typedef只是对已经存在的类型用一个用户命名的标识符来代替,并不是另外设置的一个新的类型。
(3)typedef还可以用于以下形式:
typedef char *CHARP;
CHARP p,a[10]; char *p,*a[10];
(4)typedef还可以用于说明在下一章学到的结构体类型以及共用体类型,对简化程序的书写有极大的好处。
12.7 对C语言的一些说明
C语言是一种高级语言,它可以使用接近英语国家的自然语言和数字语言作为语言的表达形式。
C语言是一种用的最广泛的语言。由于它可以直接控制计算机硬件,因此其编写的程序运行效率较高。
许多系统软件均由C语言编写,如Linux,Unix等操作系统都是由C语言编写而成的。
用C语言编写的程序,我们把它称为C语言源程序。
C语言源程序不能直接执行,它必须通过相关编译、链接程序编译并链接成可执行程序,才能在计算机上执行。
C语言源程序一般保存在一个以扩展名为.c的文本文件中,这个文件能够被我们理解,但是不能被计算机理解。我们需要通过编译程序将源文件编译成目标文件,目标文件保存在一个扩展名为.obj的文件中。
C语言的每一条指令都最终要转换成二进制的机器指令。
目标文件虽然保存了计算机能够理解的机器指令,但是它不能别计算机执行。
为了得到计算机能够理解的可执行文件,必须使用链接链接程序把这些目标文件链接成一个可执行文件。这个可执行文件的扩展名为.exe。
总之,把C语言源程序变为可执行文件,必须经过编译和链接两个步骤。
无论C语言源程序由多少个文件组成,main函数有且仅有一个。
注意:
在C语言的基本数据类型中没有专门的逻辑类型。C语言使用整数来表示逻辑值,其中0表示假,非0表示真。
为了处理数据方便,C语言提供了构造类型。例如,数组、结构体、共用体都是构造类型。构造类型又称为集合类型。
C语言由三种基本结构组成:顺序结构、选择结构和循环结构。这三种结构可以完成任何符合结构化的任务。
使用C语言可以很方便的实现算法。
算法的几个基本特征:
(1)有穷性:指算法必须在执行有限个步骤后终止。
(2)可行性:针对实际问题设计的算法,应该能够得到满意的结果。
(3)确定性:算法中的每个步骤必须有明确的定义,不允许有模棱两可的解释,也不允许有多义性。
(4)零个或多个输入:作为一个算法,可以有一个或多个输入,也可没有输入。
(5)一个或多个输出:算法的目的是为了求解,“解”就是输出。作为一个算法,至少有一个输出,也可以有多个输出。
12.1 对函数的深入讨论
12.2 编译预处理
12.3 标识符的作用域
12.4 函数的存储分类
12.5 动态存储分配
12.6 定义用户类型
12.7 对C语言的一些说明
第十二章 对C语言的深入讨论
12.1.1 main函数的参数
12.1.2 函数指针
12.1.3 函数的递归调用
12.1 对函数的深入讨论
12.1.1 main函数的参数
main函数是C程序中的主函数,是整个程序的入口,每个C程序有且只有一个main函数。
带参数的main函数
main函数通常有两个参数,其定义形式如下:
main(int argc,char *argv[])
{ …… }
argc和argv是main函数的两个参数,名称可改变,但参数类型是C规定好的,不可改变。
第一个参数必须是整型,第二个参数必须是字符串的指针,也就是char类型的二维指针。第二个参数也可定义为char **argv。
main函数参数的作用:
argc传入命令参数的个数。
argv传入命令参数的各个字符串。
例:如果我们把一个C语言源程序保存为my.c,经过编译、链接后会产生一个my.exe的可执行程序,这样我们就可以离开C语言的开发环境,直接运行该程序了,例如在DOS环境中输入如下程序:
my a command line
在上面的命令中,my是可执行程序,后面的a、command和line是my命令的参数。这些参数就是通过main函数的参数传递给程序的。my也被当作一个命令参数被传入。
在上面命令中,argc的值为4,表示有4个命令参数,argv指向一个指针数组,该数组有4个字符串数组元素,分别指向4个命令参数my、a、command和line,如下图所示:
argv[3]
argv[2]
argv[1]
argv[0]
argv
line
command
a
my
命令行各参数间以空格或Tab键隔开,如果参数包含空格,必须把参数放在一对双引号内,例如:
my “a command” line
则a command被当成一个参数.
12.1.2 函数指针
在C语言中,函数名代表一个函数的入口地址,因此可以定义一个指针指向该入口地址,即指向函数的指针。
指向函数的指针变量定义格式如下:
函数返回值类型 (*指针名)(函数参数列表);
例 以下程序使用函数指针调用函数
int fun(int a,int *b)
{ …… }
main()
{ int (*pfun)(int,int*),a,b,s;
pfun=fun;
……
s=(*pfun)(a,&b);
……
}
/*此处定义了pfun这个函数指针*/
/*将函数名fun赋给指针pfun,即让pfun指向fun*/
/*此处通过pfun指针来调用fun函数,相当于调用s=fun(a,&b)*/
12.1.3 函数的递归调用
定义:函数直接或间接的调用自身叫函数的递归调用。
说明:
若要采用递归的方法解决问题,可以把要解决的问题转化为一个新的问题,而这个新的问题的解决仍与原来的解决方法相同,只是处理的对象有规律的递增或递减,从而应用这个转化过程使问题得到解决。
C编译系统对递归函数的自调用次数没有限制。
每调用函数一次,在内存堆栈区分配空间,用于存放函数变量、返回值等信息,所以递归次数过多,可能引起堆栈溢出。
必须有一个明确的结束递归的条件。
例 以下程序运行后的输出结果是:
fun(int x)
{ if(x/2>0) fun(x/2);
printf(“%d”,x);
}
main()
{ fun(6); }
输出结果:136
main()
fun(6)
fun(3)
fun(1)
x为6
输出6
x为3
输出3
x为1
输出1
12.2.0 概述
12.2.1 宏
12.2.2 文件包含
12.2 编译预处理
在C中,凡是以”#”开头的行,都称为“编译预处理”命令行,编译预处理命令行并不是C语言本身的组成部分,不能直接对它们编译,而是由预处理程序在编译前作出相应的处理。
作用:对源程序编译之前做一些处理,生成扩展C源程序
种类
宏定义 #define
文件包含 #include
格式:
“#”开头
占单独书写行
语句尾不加分号
12.2.0 概述
如 if(x==YES) printf(“correct!\n”);
else if (x==NO) printf(“error!\n”);
展开后: if(x==1) printf(“correct!\n”);
else if (x==0) printf(“error!\n”);
12.2.1 宏
不带参数宏定义
一般形式: #define 宏名 [宏体]
功能:用指定标识符(宏名)代替字符序列(宏体)
宏展开:预编译时,用宏体替换宏名---不作语法检查
如 #define YES 1
#define NO 0
#define PI 3.1415926
#define OUT printf(“Hello,World”);
宏体可缺省,表示宏名
定义过或取消宏体
定义位置:任意(一般在函数外面)
作用域:从定义命令到文件结束
#undef可终止宏名作用域
格式: #undef 宏名
例 #define YES 1
main()
{ ……..
}
#undef YES
#define YES 0
max()
{……..
}
YES原作用域
YES新作用域
宏定义可嵌套(宏定义行的替换文本中可以包含已经定义过的宏名),不能递归
例 #define MAX MAX+10 ( )
引号中的内容与宏名相同也不置换
例 #define PI 3.14159
printf(“2*PI=%f\n”,PI*2);
宏展开:printf(“2*PI=%f\n”,3.14159*2);
宏定义中使用必要的括号()
例 #define WIDTH 80
#define LENGTH WIDTH+40
var=LENGTH*2;
宏展开:var= 80+40 *2;
( )
( )
例 #define WIDTH 80
#define LENGTH WIDTH+40
var=LENGTH*2;
宏展开:var= 80+40 *2;
说明:
宏名一般用大写字母。这不是语法规定,只是一种习惯
可以使用宏名代替一个字符串
当宏定义在一行中写不下,需要在下一行继续时,只需在最后一个字符后紧接一个反斜线“\”。例如:
#define LEAP_YEAR year % 4==0\
&& year %100!=0 || year % 400==0
注意在第二行开始不要有空格,否则空格会一起被替换
宏名的有效范围为定义命令之后到本源文件结束,除非用#undef命令终止宏名的作用域
对程序中用双引号括起来的字符串内的子串和用户标识符中的成分不做替换
同一个宏名不能重复定义,除非两个宏定义命令行完全一致
带参数宏定义
功能:将一个带参数的表达式定义为一个带参数的宏。
一般形式: #define 宏名(参数表) 宏体
例 #define S (r) PI*r*r
相当于定义了不带参宏S,代表字符串“(r) PI*r*r”
宏展开:形参用实参换,其它字符保留
宏体及各形参外一般应加括号()
例 #define S(a,b) a*b
………..
area=S(3,2);
宏展开: area=3*2;
不能加空格
例 #define POWER(x) x*x
x=4; y=6;
z=POWER(x+y);
宏展开:z=x+y*x+y;
一般写成: #define POWER(x) ((x)*(x))
宏展开: z=((x+y)*(x+y));
说明:
在替换带参数的宏名时,一对圆括号不能少,圆括号中实参的个数应该与形参个数相同,若有多个参数,各参数用逗号隔开
与不带参数的宏相同,同一个宏名不能重复定义,除非两个宏定义命令行完全一致
#define MAX(x,y) (x)>(y) (x):(y)
…….
main()
{ int a,b,c,d,t;
…….
t=MAX(a+b,c+d);
……
}
宏展开:t=(a+b)>(c+d) (a+b):(c+d);
int max(int x,int y)
{ return(x>y x:y);
}
main()
{ int a,b,c,d,t;
…….
t=max(a+b,c+d);
………
}
例 用宏定义和函数实现同样的功能
带参的宏与函数区别
带参宏
函数
处理过程
不分配内存
简单的字符置换
分配内存
先求实参值,再代入形参
处理时间
编译时
程序运行时
参数类型
无类型问题
定义实参,形参类型
程序长度
变长
不变
运行速度
不占运行时间
调用和返回占时间
12.2.2 文件包含
功能:一个源文件可将另一个源文件的内容全部包含进来
一般形式: #include “文件名”
或 #include <文件名>
#include “file2.c”
file1.c
file2.c
file1.c
file2.c
A
B
A
处理过程:预编译时,用被包含文件的内容取代该预处理命令,再对“包含”后的文件作一个源文件编译
<> 直接按标准目录搜索
“” 先在当前目录搜索,再搜索标准目录
可指定路径
被包含文件内容
源文件(*.c)
头文件(*.h)
宏定义
数据结构定义
函数说明等
文件包含可嵌套
#include “file2.c”
file1.c
A
file3.c
C
#include “file3.c”
file2.c
B
file1.c
A
file3.c
file2.c
说明:
#include命令行通常书写在文件的开头,故有时也把包含文件称作“头文件”。头文件名可以由用户指定,其后缀不一定用“.h”。
包含文件中,一般包含一些公用的#define命令行、外部说明或函数的原型说明。例如stdio.h就是这样的头文件。
当包含文件修改后,对包含该文件的源程序必须重新进行编译连接。
在一个程序中,允许有任意多个#include命令行。
在包含文件中还可以包含其他文件。
例 文件包含举例
/*14.h*/
#define N 10
#define f2(x) (x*N)
/*14.c*/
#include
#define M 8
#define f(x) ((x)*M)
#include “14.h”
main()
{ int i,j;
i=f(1+1); j=f2(1+1);
printf(“%d %d“,i,j);
}
运行结果:16 11
12.3.0 概述
12.3.1 存储分类
12.3.2 局部变量
12.3.3 全局变量
12.3 标识符的作用域
12.3.0 概述
标识符必须先定义后使用,用户定义的标识符都有一个有效的作用域,所谓变量的作用域,指的是程序中的某一部分。只有在这一部分,该变量才是有效的,才可以被C编译和连接程序所识别。
变量是对程序中数据的存储空间的抽象
内存
…….
main()
{ int a;
a=10;
printf(“%d”,a);
}
编译或函数调用时为其分配内存单元
10
2000
2001
程序中使用变量名对内存操作
12.3.1 存储分类
变量的分类
生存期:变量在某一时刻存在-------静态变量与动态变量
作用域:变量在某区域内有效-------局部变量与全局变量
变量的存储类型
auto -----自动型
register-----寄存器型
static ------静态型
extern -----外部型
变量定义格式: 存储类型 数据类型 变量列表;
或 数据类型 存储类型 变量列表;
变量的存储类型可放在类型名的左边,也可放在类型名的右边.
如: int sum;
auto int a,b,c;
register int i;
static float x,y;
或: int anto a,b,c;
int register i;
float static x,y;
12.3.2 局部变量
局部变量有3种类型:anto、register和static。
anto变量
在定义局部变量时,如果没有指定相应的存储类,则系统默认为anto类型。
anto类型的变量只能在定义它的函数或复合语句内有效。当程序进入定义该变量的函数或复合语句时,系统为这些变量临时分配内存单元。当程序离开这个函数或复合语句时,系统将销毁这些内存单元,使其数据不再有效。
例 int sum;
等价于:
anto int a;
或 int anto a;
例 main()
{ int i=1,i_sum;
{ float f, f_sum;
int i;
i=10;
printf(“(1) i=%d\n”,i);
}
printf(“(2) i=%d\n”,i);
}
输出结果:
(1) i=10
(2) i=1
register变量
register变量(寄存器变量)与anto变量一样,是自动类变量,其作用域和生存期与anto变量一样。
与anto变量唯一区别是anto变量在内存中分配存储空间,而register变量在CPU的寄存器分配。
说明:
寄存器变量的运行速度要远远大于其他类型的变量,读者可根据需要在必要的时候使用寄存器变量。
由于PC机中寄存器的数量极其有限,使用过多的寄存器变量可能会影响程序其他部分的运行效率。
由于寄存器的数量有限,系统在分配寄存器变量时有可能分配不成功,这时系统将为register变量分配anto变量。因此register说明只是对编译系统的一种建议,而不是强制性的。
由于register变量分配的是寄存器而不是内存,因此register类型的变量没有地址,不能使用取地址运算符。
例 main()
{ register int i=1;
int s=0;
for(i=0;i<100;i++)
s+=i;
printf(“sum=%d\n”,sum)
}
static变量
在函数内部或复合语句中定义变量时,如果使用static来说明,就构成了静态局部变量。
静态局部变量的作用域与anto和register类型变量一样,但其生存期却完全不同。
静态局部变量在内存的静态存储区占据着永久性的存储单元,即使离开定义该变量的函数(或复合语名),该存储单元也不会被销毁。当下次再进入定义该变量的函数(或复合语句)时,存储单元仍然保存着原来的值。
静态局部变量的初值是在编译时赋予的,在程序被执行时不再赋初值。
对未赋初值的静态局部变量,C语言编译系统自动给它赋初值0。
例 fun(int a)
{ int b=0;static int c=3;
b++;
c++;
return(a+b+c);
}
main()
{ int i, a=5;
for(i=0;i<3;i++)
printf(“ %d %d”,i,fun(a));
printf(“\n”);
}
输出结果:
0 10 1 11 2 12
第几次调用 调用时初值 调用结束时的值
a b c a b c 函数值
第1次调用 5 0 3 5 1 4 10
第2次调用 5 0 4 5 1 5 11
第3次调用 5 0 5 5 1 6 12
12.3.3 全局变量
在函数外部任意的位置定义的变量,称为全局变量。全局变量都是静态变量,其作用域从定义的位置开始,到整个文件结束为止。
例 int sum;
int fun1()
{ sum+=20; }
int a;
int fun2()
{ a=20; sum+=a; }
main()
{ sum=0;
fun1();
a=8;
fun2();
printf(“sum=%d a=%d”,sum,a);
}
int p=1,q=5;
float f1(int a)
{ int b,c;
…….
}
int f3()
{…..
}
char c1,c2;
char f2(int x,int y)
{ int i,j;
……
}
main()
{ int m,n;
…….
}
c1,c2的作用范围
p,q的作用范围
extern char c1,c2;
c1,c2
的作用范围
扩展后
c1,c2
的作用范围
扩展后
extern char c1,c2;
可以使用extern和static来说明全局变量。
在同一编译单位内使用extern来说明全局变量。
当调用全局变量的函数在该全局变量前面时,可使用extern说明全局变量。此时该变量的作用域就从extern说明处开始。
使用extern说明全局变量,并不是对变量进行了重新定义,它仅仅是告诉编译器,该变量已经定义,可使用了。
在整个程序中,对一个全局变量的定义只能出现一处,它要求编译器分配内存单元。在定义时不能出现extern说明符。
在整个程序中,对全局变量的说明可出现在多处,它并不分配存储单元,仅仅告诉编译器,该变量已在别的地方定义了。在对全局变量进行说明时,必须使用extern说明符。
在不同编译单位内使用extern来说明全局变量。
我们知道,C是由函数构成。当C语言的源程序过大时,为了管理上的方便,往往把源程序分别存放在若干个不同的源文件中。这些源文件可以单独进行编译,生成目标文件(obj文件)。然后再使用链接程序将这些目标文件连接成一个可执行文件(exe文件)。通常,人们把每个可以单独编译的源文件称为编译单位。
在不同编译单位内需要使用同一个全局变量时,就必须使用extern来对变量进行说明。
如果在每个编译单位都定义一个相同名称的全局变量,在对每个编译单位进行编译时并不会出现错误,但在编译生成目标文件进行链接时,就会出现“重复定义变量”的错误。可在其中一个编译单位内定义变量,而在其他的编译单位内使用extern来说明变量。
例 /*文件file1.c*/
int a;
void fun()
main()
{ a=10;
printf(“In main a=%d\n”,a);
a=100;
fun();
}
/*文件flie2.c*/
extern int a;
void fun()
{ printf(“In fun a=%d\n”,a); }
使用static说明全局变量。
当使用static说明符来说明全局变量时,则这个全局变量为静态全局变量,静态全局变量只能被本编译单位使用,不能被其他编译单位使用。
例 /*文件file1.c*/
static int a;
void fun()
main()
{ a=10;
printf(“In main a=%d\n”,a);
a=100;
fun();
}
/*文件flie2.c*/
extern int a;
void fun()
{ printf(“In fun a=%d\n”,a); }
12.4.1 用extern说明函数
12.4.2 用static说明函数
12.4 函数的存储分类
函数不可以嵌套定义,也就是在函数内部不可以再定义函数,所以所有函数在本质上都是外部的,可在定义函数时使用static和extern说明符来改变函数的作用域。
12.4.1 用extern说明函数
可在函数返回值类型前面加上extern来说明函数,使用extern说明的函数称为外部函数。
例: extern int fun()
{ …… }
extern可省略,我们以前定义的函数都属于外部函数。
外部函数可以被其他编译单位内的函数调用,如果在其他编译单位需要调用该函数,必须在调用前使用extern对所调用的函数进行说明。
12.4.2 用static说明函数
使用static进行说明的函数称为静态函数,也叫内部函数。静态函数只能被本编译单位内的函数调用,不能被其他编译单位内的函数调用。
12.5.1 malloc函数
12.5.2 free函数
12.5.3 calloc函数
12.5 动态存储分配
12.5.1 malloc函数
C语言提供了4个函数用于内存空间的动态分配与释放,它们分别是malloc、calloc、realloc和free。
malloc函数
作用:动态分配内存单元。
调用形式:malloc(size)
返回值类型:void *
如果系统有足够的内存可供分配,函数返回一个指向有size个字节的存储区首地址,该首地址的基类型为void类型
若没有足够的存储空间,函数返回空值(NULL)
unsigned int类型,表示需要分配的字节数
例 malloc函数应用举例
int *p;
float *q;
……
p=(int*)malloc(2);
q=(float*)malloc(4);
……
在本例中p、q被定义成了两个指针变量,基类型分别为int类型和float类型。通过malloc函数为这两个指针变量分配内存单元。在调用malloc函数时,传入需要分配的字节数,int类型占用两个字节,float类型占用4个字节,则在调用malloc函数时分配传入参数2和4。
由于malloc函数返回的是void*类型的指针,与变量p和q的基类型不相符,因此需要将其进行强制类型转换。
若有:
if(p!=NULL) *p=6;
if(q!=NULL) *q=3.8;
赋值后数据的存储情况如下:
p
6
q
3.8
说明:
动态分配得到的内存单元没有名字,只能通过指针变量来引用它。
一旦指针变量的值发生改变,原存储单元及所存数据都无法再引用。
通过malloc函数要配的动态存储单元中没有确定的初值。
在调用malloc进行存储分配时,如果不能确定数据类型所占字节数,可以调用sizeof运算符来求得。如上例可改为:
p=(int*)malloc(sizeof(int));
q=(float*)malloc(sizeof(float));
这是一种常用的方式,由系统来计算指定数据类型的字节数
12.5.2 free函数
free函数
作用:释放动态分配的内存单元。
调用形式:free(p)
返回值:无
说明:
静态存储分配的变量和数组,在生存期过后,或者程序运行结束后,所占用的存储单元会由系统自动释放。
动态分配的内存单元,需手动进行释放。
free函数是将指针p所指向的空间释放,使这部分空间可以由系统得新分配。
指向动态分配函数分配的地址
12.5.3 calloc函数
calloc函数
作用:分配单个数据类型的存储单元或分配多个同一类型的连续的存储空间。
调用形式:calloc(n,size);
返回值:基类型为void的指针。
分配成功,函数返回存储空间的首地址
否则,返回空值
说明:
调用形式中n和size的类型都为unsigned int
calloc函数用来给n个同一类型的数据项分配连续的存储空间,其中每个数据项的长度为size个字节
由calloc分配的存储空间,系统自动置初置0。
使用calloc函数分配的动态存储单元,同样必须用free函数释放。
例: int *pint;
pint=(int*)calloc(10,sizeof(int));
程序调用calloc函数在内存中分配了10个连续的int类型的存储单元,由pint指向存储单元的首地址。每个存储单元可以存放一个int型数据。
释放存储空间:
free(pint);
12.6 定义用户类型
C语言不仅提供了丰富的数据类型,而且还允许由用户自己定义类型说明符,也就是说允许由用户为数据类型取“别名”。类型定义符typedef即可用来完成此功能。 。
C语言提供了typedef关键字,用以说明一种新的数据类型名,说明新类型名的形式为:
typedef 类型名 标识符;
在typedef语句中,“类型名”必须是在此语句之前就已经定义的类型标识符,“标识符”是一个用户自定义标识符,用作新的类型名。
typedef的作用仅仅是用作“标识符”来代表已存在的“类型名”,并未产生新的数据类型。原有的类型名依然有效。
例12.16 typedef int MYINT;
本例中,把MYINT标识符说明成了一个int类型的类型名。在此说明后,可以用标识符MYINT来定义整型变量,如:
MYINT i,j; int i,j;
由此可以看出,MYINT标识符也就是关键字int的一个别名。
对typedef的几点说明如下:
(1)习惯上将用typedef说明的新类型名用大写字母表示,以便与程序中其他标准类型标识符相区别。
(2)用typedef只是对已经存在的类型用一个用户命名的标识符来代替,并不是另外设置的一个新的类型。
(3)typedef还可以用于以下形式:
typedef char *CHARP;
CHARP p,a[10]; char *p,*a[10];
(4)typedef还可以用于说明在下一章学到的结构体类型以及共用体类型,对简化程序的书写有极大的好处。
12.7 对C语言的一些说明
C语言是一种高级语言,它可以使用接近英语国家的自然语言和数字语言作为语言的表达形式。
C语言是一种用的最广泛的语言。由于它可以直接控制计算机硬件,因此其编写的程序运行效率较高。
许多系统软件均由C语言编写,如Linux,Unix等操作系统都是由C语言编写而成的。
用C语言编写的程序,我们把它称为C语言源程序。
C语言源程序不能直接执行,它必须通过相关编译、链接程序编译并链接成可执行程序,才能在计算机上执行。
C语言源程序一般保存在一个以扩展名为.c的文本文件中,这个文件能够被我们理解,但是不能被计算机理解。我们需要通过编译程序将源文件编译成目标文件,目标文件保存在一个扩展名为.obj的文件中。
C语言的每一条指令都最终要转换成二进制的机器指令。
目标文件虽然保存了计算机能够理解的机器指令,但是它不能别计算机执行。
为了得到计算机能够理解的可执行文件,必须使用链接链接程序把这些目标文件链接成一个可执行文件。这个可执行文件的扩展名为.exe。
总之,把C语言源程序变为可执行文件,必须经过编译和链接两个步骤。
无论C语言源程序由多少个文件组成,main函数有且仅有一个。
注意:
在C语言的基本数据类型中没有专门的逻辑类型。C语言使用整数来表示逻辑值,其中0表示假,非0表示真。
为了处理数据方便,C语言提供了构造类型。例如,数组、结构体、共用体都是构造类型。构造类型又称为集合类型。
C语言由三种基本结构组成:顺序结构、选择结构和循环结构。这三种结构可以完成任何符合结构化的任务。
使用C语言可以很方便的实现算法。
算法的几个基本特征:
(1)有穷性:指算法必须在执行有限个步骤后终止。
(2)可行性:针对实际问题设计的算法,应该能够得到满意的结果。
(3)确定性:算法中的每个步骤必须有明确的定义,不允许有模棱两可的解释,也不允许有多义性。
(4)零个或多个输入:作为一个算法,可以有一个或多个输入,也可没有输入。
(5)一个或多个输出:算法的目的是为了求解,“解”就是输出。作为一个算法,至少有一个输出,也可以有多个输出。
同课章节目录