信息学辅导-上海
图片预览











文档简介
(共126张PPT)
上海市控江中学 王建德
2、2002年—分区联赛高中组试题解析
1、计算机基础知识
3、改善高精度运算的效率
4、构造法
一、 计算机的发展与应用
二、计算机组成与工作原理 和信息的表示与存储
三、多媒体应用
四、计算机网络使用基础
五、程序设计语言基础
六、程序的阅读分析
⑴计算机的发展历经了哪几个阶段;
⑵按照功能和规模,可将计算机分成哪几大类,它们各自的分工是什么;
⑶武装计算机的软件系统包括了哪些东西;
⑷计算机的发展怎样促使人类走向丰富多彩的信息社会;
⑸用户在使用计算机时应该遵守哪些道德规范;
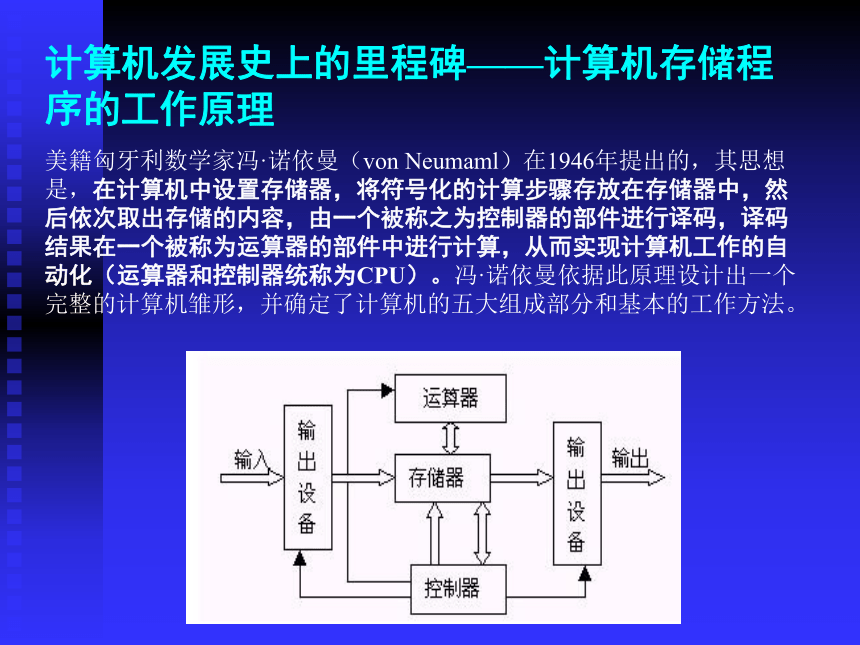
计算机发展史上的里程碑——计算机存储程序的工作原理
美籍匈牙利数学家冯·诺依曼(von Neumaml)在1946年提出的,其思想是,在计算机中设置存储器,将符号化的计算步骤存放在存储器中,然后依次取出存储的内容,由一个被称之为控制器的部件进行译码,译码结果在一个被称为运算器的部件中进行计算,从而实现计算机工作的自动化(运算器和控制器统称为CPU)。冯·诺依曼依据此原理设计出一个完整的计算机雏形,并确定了计算机的五大组成部分和基本的工作方法。
操作系统是计算机系统中的一种系统软件,它能对计算机系统中的软件和硬件资源进行有效地管理和控制,合理地组织计算机的工作流程,为用户提供一个使用计算机的工作环境。
DOS——单用户的唯一任务占用计算机上所有的硬件和软件资源,所能访问的主存地址空间太小。
Windows——多作业、大内存管理、统一的图形用户界面 ,并且发展到网络环境使用
UNIX操作系统 、Linux操作系统 、Macintosh OS
数据库技术的特性
⑴最小冗余
⑵数据共享
⑶数据独立性
⑷安全性
⑸完整性
数据库管理系统的类型
⑴OLTP(联机事务处理)
⑵DSS(决策支持系统)
⑶EIS(行政信息系统)
⑷OA(办公室自动化)
⑸按其系统结构分为单机、Unix多用户、网络多用户、客户机/服务器、集中式、分布式、集中分布式等。
目前,世界上比较流行的数据库管理系统(DMS)有
⑴高档数据库产品,如Informix,Oracle,Sybase,Progress,Unify等
⑵中、低档数据库产品,如DBASE,Paradox,Super-Base,Foxpro,Clipper,SQL Base,Focus等;
⑶数据库开发工具,如Access,Visual Basic,Uniface,Power Builder,Q+EDatabase Editor等。
计算机病毒的特征
⑴能够将自身复制到其他程序中。
⑵不独立以文件形式存在,仅附加在别的程序上。当调用该程序运行时,此病毒则首先运行。
防治病毒的步骤:
⑴不要用软盘启动机器
⑵不要运行来路不明的软件
⑶定期备份重要系统数据
⑷重要的数据盘,程序盘应写保护
⑸使用杀毒软件检查和清除病毒
进位计数制之间的转换问题。
1、R进制转换为十进制
基数为R的数字,只要将各位数字与它的权相乘,其积相加,和数就是十进制数
(xp…x0.x-1…x-k)R=( )10
例:
1101101.01012
=1×2°+0×21+1×22+1×23十0×24+1×25+1×26+0×2-1+1×2-2+0×2-3+1×2-4
=109.3125
当从R进制转换到十进制时,可以把小数点作为起点,分别向左右两边进行,即对其整数部分和小数部分分别转换。对于二进制来说,只要把数位是1的那些位的权值相加,其和就是等效的十进制数。
2、十进制转换为R进制
将此数分成整数与小数两部分分别转换,然后再拼接起来。
+进制整数转换成R进制的整数,可用十进制数连续地除以R,其余数即为R系统的各位系数。此方法称之除R取余法。例如:将5710转换为二进制数
十进制小数转换成R进制时,可连续地乘以R,直到小数部分为0,或达到所要求的精度为止(小数部分可能永不为零),得到的整数即组成R进制的小数部分,此法称为“乘R取整”
例:将0.312510转换成二进制数
0.3125×2 =0.625 0.625×2 =1.25 0.25×2=0.5 0.5×2 =1.0
3、二、八、十六进制的相互转换
即每位八进制数相当于三位二进制数,每位十六进制数相当于四位二进制数。在转换时,位组划分是以小数点为中心向左右两边延伸,中间的0不能省略,两头不够时可以补0。
例如:将1011010.10 2转换成八进制和十六进制数
001 011 010. 100 1011010.102=132.48
1 3 2. 4
0101 1010. 1000 1011010.102=5A.816
5 A . 8
将十六进制数F7.28变为二进制数
F 7 . 2 8 F7.2816=11110111.001012
1111 0111.0010 1000
将八进制数25.63转换为二进制数
2 5 . 6 3 25.638=10101.1100112
10 101 . 110 011
三、在计算机中带符号数的表示法
1、机器数与真值
规定在数的前面增设一位符号位,正数符号位用“0”表示,负数符号位用“1”表示。
为了区别原来的数与它在计算机中的表示形式,我们将已经数码化了的带符号数称为机器数,而把原来的数称为机器数的真值。例如N1=+1001100、N2=-1001100为真值,其在计算机中的表示01001100和11001100为机器数。
2、原码〈true form〉
在用二进制原码表示的数中,符号位为0表示正数,符号位为1表示负数,其余各位表示数值部分。这种表示法称为原码表示法。字长为n的数(包括符号位)的原码表示法可定义为[x]原=
若真值丨x丨<1,其原码表示法可定义为[x]原=
例如对于8位二进制原码
[+0]原=00000000,[-0]原=10000000
[-1101001]原=10000000-(-1101001)=11101001
3、补码(two’s complement)
即[x]补=模+x
对于正数, [x]补=x,正数的补码就是该正数本身。
对于负数, [x]补=2n+x(mod 2n)。
[+0]补=[-0]补=00…0
[-2n-1]补=2n-2n-1=2n-1
4、反码〈0ne’s Complement〉
对于正数,它的反码表示与原码相同。即[x]反=[x]原
对于负数,则除符号位仍为“1”外,其余各位“1”换成”0”,”0”换成1”,即得到反码[X]反。例如[-1101001] 反=10010110。
对于0,它的反码有两种表示:[+0] 反=00…0 [-0] 反=11…1
当x为正数时,[x]反=[x]原=[x]补=x;当x为负数时,[x]补=2n+x=(2n-1)+x+1=[x]反+1,即[x]原除符号位外求反加1。若把[x]补除符号位外求反加1,就得到[x]原,即[[x]补]补=[x]原。例如x=-1101001。[x]原=11101001,[x]补=10010111, [[x]补]补=11101001 =[x]原。
5、补码的加减法运算
⑴补码的加法运算
在计算机中进行两个带符号数的加法运算时,只要将给定的真值用补码表示,就可以直接进行加法运算。在运算过程中不必判断加数和被加数的正负,一律做加法,最后将结果转换为真值即可。
⑵补码的减法运算
对于补码的减法运算,由于存在x-y=x+(-y),因此
[x-y]补=[x+(-y)] 补=[x]补+[-y]补 (mod2n)
其中[-y]补=[[y]补]补。
信息存储单位
⑴位(bit,缩写为b):度量数据的最小单位,表示一位二进制信息。
⑵字节(byte,缩写为B):一个字节由八位二进制数字组成(l byte=8bit)。字节是信息存储中最常用的基本单位。
计算机存储器(包括内存与外存)通常也是以多少字节来表示它的容量。常用的单位有:KB 1K=1024,MB 1M=1024K,GB 1G=1024M
⑶字(word):字是位的组合,并作为一个独立的信息单位处理。字又称为计算机字,它的含意取决于机器的类型、字长以及使用者的要求。常用的固定字长有8位、16位、32位等。
信息单位用来描述机器内部数据格式,即数据(包括指令)在机器内的排列形式,如单字节数据,可变长数据(以字节为单位组成几种不同长度的数据格式)等。
⑷机器字长:在讨论信息单位时,还有一个与机器硬件指标有关的单位,这就是机器字长。机器字长一般是指参加运算的寄存器所含有的二进制数的位数,它代表了机器的精度。机器的功能设计决定了机器的字长。一般大型机用于数值计算,为保证足够的精度,需要较长的字长,如32位、64位等。而小型机、微型机、微机一般字长为16位、32位等。
非数值信息的表示
西文字符编码
⑴ASCII码 ——“美国信息交换标准代码”的简称。ASCII码包括0~9十个数字,大小写英文字母及专用符号等95种可打印字符,还有33种控制字符(如回车、换行等)。一个字符的ASCII码通常占一个字节,用七位二进制数编码组成,所以ASCII码最多可表示128个不同的符号。最高位作为校验码,以便提高字符信息传输的可靠性。
数字和字母的ASCII码按照数字递增顺序或字典顺序排列排列,大写字母和小写字母的ASCII码是不同的。
⑵EBCDIC码——美国IBM公司在它的各类机器上广泛使用的一种信息代码。一个字符的EBCDIC码占用一个字符,用八位二进制码表示信息,最多可以表示出256个不同代码。
中文信息编码
目前的汉字编码方案有二字节、三字节甚至四字节的。下面我们主要介绍“国家标准信息交换用汉字编码”(CB2312-80标淮),以下简称国标码。
国际码是二字节码,用二个七位二进制数编码表示一个汉字。目前国标码收人6763个汉字,其中一级汉字(最常用)3755个,二级汉字3008个,另外还包括682个西文字符、图符。 在计算机内部,汉字编码和西文编码是共存的。区分的方法之一是对于二字节的国标码,将二个字节的最高位都置成1,而ASCIl码所用字节最高位保持0,然后由软件(或硬件)根据字节最高位来作出判断。
“多媒体技术”就是用计算机交互地综合处理文本、图形、图象、动画、音频及视频影象等多种信息,并使这些信息建立逻辑连接。
色彩数目 分辨率 特点
16 640*480 Windows的最低配置、显示速度最快
256 800*600 性能虽好一些,但易产生调色板的冲突
65536 1024*768 全彩的显示模式,色彩逼真,不会再有调色板的冲突。
16M 1284*1024 高等级的3D绘图软件和专业级的视频录制人员使用的真彩色模式,要求更多的RAM在显示卡和主机板上,CPU最好也是顶级的。
显示卡
水平分辨率×垂直分辨率×色彩数目=显示存储空间
显示加速:VRAM、EDO RAM,Windows RAM,Ramlbus DRAM
显示模式
数据压缩和解压缩技术
静止图像压缩标准JPEG(Joint Photographic ExpertsCroup)
动态图像压缩标准MPEG(Moving Picture Experts Croup)
多通道的动态图像压缩标准MP×64
相关名词
位图:由一点一点的像素点排成矩阵组成的,其中每一个像素点都可以是任意颜色。
向量图:用向量代表图中所表现的元素。
像素 :图形的最小组成单位
真彩色:人的眼睛能够分辨出的颜色大约有1万6千多种,为了能表现出这么多种色彩,我们得用24bit(224=16M)来描述一个像素的颜色,这种显示模式就称为真彩色。
RGB模式:分别代表红、绿、蓝三种颜色,计算机以RGB模式来定义计算机屏幕上的颜色。通过混色原理,不同比例的RGB色彩可调和出无穷多种颜色。
HSB模式:分别表示色调(hue)、饱和度(saturation)、亮度(bright)。不同的色调代表不同的颜色;饱和度指的是某区域中,该颜色量的多少,饱和度越低,该区域看起来就越灰暗;亮度则是指颜色的亮、暗,极亮成白色,极暗则成黑色。相对于RGB模式,HSB模式设定颜色的方式可产生更好的视觉效果。
多媒体信息处理工具
图形制作平台FreeHand
图像处理平台Photoshop
动画制作平台 Animation Pro
数字动画的类型:
⑴基于模型的动画
⑵帧动画
动画中加人声音的方法
⑴嵌人式—将声音文件经过转换合并到影片文件中去。
⑵流式—声音与文件分开,在影片播放的各个时机启动声音文件
音乐
⑴波形音频文件 :通过现场录制和模数转化产生,存储量大
⑵MIDI文件:使用键盘合成器和一个音序器 制作和编辑,存储量小
广域网( WAN ):实现远距离的计算机之间的数据传输和信息共享的计算机网络。通信线路一般租用电话线路或铺设专用电缆。
局域网络(LIN):为一个单位,或一个相对独立的局部范围内大量存在的微机能够相互通信、共享昂贵的外部设备(如大容量磁盘、激光打印机、绘图议等)、共享数据信息和应用程序而建立的计算机网络。通信线路一般不租用电话线路,使用专门铺设的线路。
互联网(Internet):将遍布全球的子网通过连网协议集成到一个共享的、开放的、易于管理的主干网。
计算机网络的物理组成
网络中心主干机 、服务器 、网络工作站
共享的外部设备
网卡
通信线路(双绞线、同轴电缆和光缆、无线传输介质(如微波、红外线和激光等))
局部网络通信设备(中继器、集线器 )
网络互连设备 (网桥、路由器和网关 )
网络软件 (对等式网络操作系统 、服务器上的网络操作系统)
计算机网络的拓扑结构
总线拓扑
星型拓扑
环型拓扑
树型拓扑
计算机网络的体系结构
所谓网络体系结构就是对构成计算机网络的各组成部分之间的关系及所要实现功能的一组精确定义。国际标准化组织(ISO)提出的开放系统互联参考模型(OSI)已成为网络体系结构的标准
Internet使用TCP/IP网络体系结构
TCP/IP的层号 TCP/IP的层次名 对应OSI模型的层次
3 应用层(ftp和telnet等协议) 应用层、表示层、会话层
2 传输控制协议TCP 传输层
1 网际协议IP 网络层
计算机网络应用模式
客户机/服务器模型:将应用分成客户机和服务器两大部分,并将它分配到整个网络上。由服务器提供资源,通常执行后台功能;而客户机使用服务器,通常执行前台功能。
文件服务器:提供操作系统中文件管理的各种功能(网络文件的访问方式:文件传输和文件访问 )
打印服务器:将一台或几台打印机物理地连接到打印服务器上,可为多个客户机用户轮流使用
数据库服务器:侧重于传统数据库管理系统的功能(如数据的定义及存取、数据的安全性与完整性、并发控制及事务处理等)的服务器
远程登录:通过用户帐号访问远地系统的资源
Internet 网络地址
IP地址:
网络数
网络主机数 主机数
A类网络 126 16387064 2064770064
B类网络 16256 64516 1048872096
C类网络 2064512 254 524386048
总计 2084894 3638028208
域名(或称主机名称):计算机主机名.子域名.子域名.最高层域名
Internet应用
文件传输 (使用匿名文件传输服务(匿名FTP)网上软件分类:公共软件 、免费软件 、共享软件 )
远程登录(Telnet 命令)
电子邮政服务 (电子邮箱地址:用户名@计算机域名)
网络新闻与公告牌服务 (网络新闻是由USENET在Internet中的新闻服务器节点之间进行传递的,阅读新闻组的软件有Outlook Express)
信息查询服务 (最为流行的信息查询服务系统是万维网(World Wide Web),简称WWW。 注意超文本和超媒体的概念 )
程序设计语言的组成
程序设计语言的基础是一组记号和规则。根据规则由记号构成的记号串的总体就是语言。 包括
语法:程序的结构或形式。编译系统会自动进行语法检验;
语义:程序的含义,亦即表示按照各种方法所表示的各个记号的特定含义,但不涉及使用者。语义的错误是在源程序编译通过后的运行过程中出现的,属于算法类的错误。
语用:程序和使用者的关系;
语言的成分
⑴数据成分,用以描述程序中所涉及的数据;
⑵运算成分,用以描述程序中所包含的运算;
⑶控制成分,用以描述程序中的控制构造;
⑷传输成分,用以表达程序中数据的传输。
语言和程序设计的发展
第一代语言——机器语言
第二代语言——汇编语言
第三代语言——高级语言、算法语言(BASIC、FORTRAN、COBOL、Pascal、C )
第四代语言——非过程化语言(SQL语言)
第五代语言——智能性语言(PROLOG语言 、LISP语言 )
面向对象方法的主要概念
⑴对象——系统中用来描述客观事物的一个实体,是构成系统的一个基本单位,对象由两个主要因素组成:
属性:描述对象静态特征的一个数据项;
服务:描述对象动态特征的一个操作序列;
⑵消息——对象之间通过服务请求发生联系,这种向对象发出的服务请求称为消息。
⑶类——为了很好地控制软件的复杂度,将具有相同属性和服务的一组对象组成类。
面向对象语言分为两大阵营
⑴Smalltalk和Eiffel为代表的纯粹型面向对象语言,主要强调软件开发的探索性和原型化开发方法;
⑵以C++、Object Pascal为代表的混合型面向对象语言,主要扩充现有语言,强调运行时的时空效率;
程序设计的特点
构造性 :不同的人为解决同一问题编制的程序,其面貌颇不相同,然而,程序的功效却是等价的。
严谨性:以上下文无关的形式语言实现。无法补充缺损信息、去掉冗余信息、将暂时不懂的信息暂时搁置起来,待下文或经过推理予以补充和理解
叠加性: 一般是将自己设计的子程序尽量分割成独立的、功能明确单一的小模块,以便充分利用;甚至还会利用系统内的库函数。
抽象性:把客观事物的描述抽象为数据和算法,并且利用抽象使得程序能够正确的映射客观事物 。抽象是有层次的 ,不同层次上的抽象是相互独立和互相作用的 。
计算程序的运行结果
一、直接推理
二、由流程图推断算法
三、动态模拟
四、由底向上阅读分析
对于一些语句少、结构简单且可读性较强的程序,不妨通过分析程序流程,直接寻找其间蕴含的计算模型。
{$n+}
var
m,n,I:integer;
t:extended;
begin
readln(n,m);
t:=1;
for i:=1 to m do t:=t*(n-i+1)/i;
writeln(t:0:0);
end.
输入
10 5
输出:
【分析】由for循环可以看出
t= ,即
i=1时,t=n;
i=2时,t=n*(n-1)/2;
i=3时,t=n* (n-1)/2 * (n-2)/3 ;
………
i=m时,t= c(n,m)=n!/(m!*(n-m)!)
显然,这是求组合数。当输入n=10、m=5时,程序应输出252。
这个算法的效率不错,因为计算与n和m的大小有直接的关系。所以,我们要设法使运算的中间结果尽可能地小。如果我们先把N~(N-M+1)这M个连续的自然数乘起来,再依次除以1~M就是一种不太明智的选择。上述程序先乘N除1,然后乘(N-1)除2,再乘(N-2)除3,……最后乘(N-M+1)除M。因为连续的K个自然数的积一定能被K!整除,所以在这一过程中不会出现除不尽的情况。同时也使得中间结果比较小,从而提高了运算速度。告诫读者的是,对于上述算法来说,n和m不能超过102。如果超过了这个上限,t就会溢出,尽管它采用了extended类型。
对于一些易读性不十分好的程序,最好的办法是画流程图。其步骤如下
⑴跟着程序画流程图,一句一框;
⑵根据上下文的联系合并流程图。若前几句计算值都要代入后一表达式,则合并为一框。接连合并几次,使程序成为一个大功能块;
⑶由大功能块推断算法;
⑷代入输入值,计算结果。
label 10,20,30;
var
s,p:string;
i,k,n,j,m:integer;
begin
readln(s); n:=length(s);
readln(p); m:=length(p);
i:=0;
10: i:=i+1; j:=i; k:=1;
20: if s[j]<>p[k]
then begin
if iend
else if kthen begin j:=j+1; k:=k+1; goto 20;end;
30:
writeln(i);
end.
输入 输出
asabcdffdin
fdi
这个程序的功能是计算s串中与p匹配的子串的首指针。当程序输入
asabcdffdin
fdi
程序应输出8,即s[8]…s[10]=p=‘fdi’。
动态模拟方法是采用人工模仿机器执行程序的方法计算结果值。首先选择程序中比较重要的变量作为工作现场。人工执行程序时,只要按照时间先后一步步记录下现场的变化,就能最后得出程序的运算结果。其具体布置如下:
⑴画表,画出程序执行时要用的现场情况表;
⑵基本读懂各语句的功能
⑶走程序,即动态模拟程序。主要根据各语句的功能,按照程序执行路径的先后顺序逐项填写现场情况表,直至得出最后结果;
动态模拟方法对简单程序、尤其是循环次数少的程序是很有效的。但对语句多和计算过程长的程序,这个方法则由于模拟速度太慢而不实用。
var
i,j:integer;
a:array[1..3,1..3]of integer;
begin
for i:=1 to 3 do
begin
for j:=1 to 3 do
begin
if i=3 then a[i,j]:=a[i-1,a[i-1,j]]+1
else a[i,j]:=j;
write(a[i,j]);
end;
writeln
end;
readln
end.
输出:
j
i
1
2
3
1
1
2
3
2
1
2
3
3
2
3
4
显然,最后应输出
1 2 3
1 2 3
2 3 4
var
a,d:array[1..100] of integer;
n,i,j,k,x,s:integer;
begin
n:=5;a[1]:=1;d[1]:=1;
for i:=1 to n do
begin
s:=i+1;x:=0;
for j:=1 to n+1-i do
begin
k:=s+x;x:=x+1;a[j+1]:=a[j]+k;
write(a[j],' ');
end;
writeln('...');d[i+1]:=d[i]+i;a[1]:=d[i+1];
end;
end.
输出:
外循环
内循环
i=
S=
d[i+1]
a[1]=
k=
x=
a[j+1]=
输出a[j]
1
2
2
2
2
1
3
1
2
3
2
6
3
3
4
3
10
6
4
5
4
15
10
5
6
5
21
15
2
3
4
4
3
1
5
2
2
4
2
9
5
3
5
3
14
9
4
6
4
20
14
3
4
7
7
4
1
8
4
2
5
2
13
8
3
6
3
19
13
4
5
11
11
5
1
12
7
2
6
2
18
12
5
6
6
1
17
11
最后应输出
1 3 6 10 15 …
2 5 9 14 …
4 8 13 …
7 12 …
11 …
由底向上分析的阅读分析方法就是在剖析了子程序和模块资源的基础上,建立对高层程序结构的理解,从而完成整个程序的阅读分析,即从最底层的子目标开始分析起,看它们做了哪些事情;然后分析上一层的子目标,看这些子目标在下一层子目标实现的基础上实现了哪些功能……。经过自底而上的阅读分析,最后得出计算模型。
const
limit = 3000;
type
tdata=array [0..limit] of longint;
var
ans ,num : tdata;
i,j,n:longint;
procedure update(var a:tdata);
var
int i;
begin
for i:=0 to limit-1 do
begin
inc(a[i+1],a[i] div 10);
a[i] := a[i] mod 10;
end;
end;
procedure mult(var a:tdata;b:integer);
var
i, j:integer;
begin
for i:=0 to limit do a[i] := a[i] * b;
update(a);
end;
procedure add(x, ob:longint);
var
i:longint;
begin
for i:=2 to x do
while (x mod i =0) do
begin
inc(num[i], ob);
x := x div i;
end;
end;
Begin
read(n);
fillchar(num, sizeof(num),0);
for i:= 0 to n do
begin
add(i+1,-1);
add(n+n-i,1);
end;{for}
add(n+1, -1);
fillchar(ans,sizeof(ans),0);
ans[0] := 1;
for i:=2 to limit do
for j:=1 to num[i] do mult(ans,i);
for i:=limit downto 0 do
if (ans[i] > 0) then
begin
for j:=i downto 0 do write(ans[j]);
writeln;break;
end;{then}
End.
输入 输出
5
update(var a)是将数组a规整为高精度的十进制数组
mult(var a,b)是将高精度的十进制数组a乘以整数b,积存储在a中。
add(x, ob)计算因子表,ob=1,num←num*x;ob=-1,num←num/x。其中num[i]为因子i的个数
主程序计算catalan数1/(n+1)*c(2*n,n) 。显然n=5,则程序输出42(1/6*c(10,5))
完善程序
填空内容:
1、变量方面的填空
2、循环方面的填空
3、分支转移方面的填空
4、主程序和子程序关系方面的填空
5、输入输出方面的填空
填空方法:
按照自顶向下的思维方法阅读程序——从主程序开始,沿控制层次向下阅读。在查到某一个子程序(子模块)时,比照题目给出的说明和调用它的“父程序(父模块)”,弄清该子程序(子模块)究竟要达到什么样的子目标,然后查程序,看它是如何实现这个子目标的。如果该子程序(子模块)有空格,则按照算法的逻辑进行填空。依次类推,直至最底层的子程序(子模块)中的空格全部填完为止。
1、完善不含子程序的程序
首先划分各个子模块的层次结构,并确定每个子模块的子目标。然后自顶向下,根据子目标和上层子模块给出的线索,对当前层次的各个模块进行填空。依次类推,直至最底层的子模块中的空格全部填完为止。
求元素之和最大的子方阵:在m×n(m,n≤20)的正整数数字方阵中,找出一个p×q的子阵(1≤p≤m,1≤q≤n)使其元素之和最大。例如,下面5×4的数字阵中,元素之和最大的一个2×3子阵。
5×4数字阵 元素之和最大的2×3子阵为
3
8
4
22
11
1
7
9
5
21
6
2
10
3
8
9
2
7
12
3
5
21
6
10
3
8
var a:array[1..20,1..20] of integer;
m,n,p,q,i,j,max,p1,q1,s,i1,j1:integer;
begin
for i:=1 to 20 do
for j:=1 to 20 do
a[i,j]:=0;
readln(m,n);
for i:=1 to m do
begin
for j:=1 to n do read(a[i,j]);
readln
end;
readln(p,q);
max:=0;
for i:=1 to m-p+1 do
for j:=1 to n-q+1 do
begin
① ;
for i1:=i to p+i-1 do
for j1:=j to q+j-1 do
② ;
if s>max then begin
③ ;
p1:=i;
q1:=j
end;
end;
for i:=p1 to ④ do
begin
for j:=q1 to ⑤ do
write(a[i,j]:3);
writeln
end;
readln
end.
模块1(初始化,白色):方阵清零;读方阵规模;读方阵;读子阵规模;子阵的最大数和初始化
模块2(湖蓝)通过枚举所有可能子阵,求数和最大的子阵 。其中
子模块1(深蓝):累计(i,j)为左上角的子阵的数和
子模块2(淡绿):调整子阵的最大数和
模块3(红色)——输出最大数和的子阵。
由此得出解
① s:=0 ② s:=s+a[i1,j1] ③ max:=s ④ p1+p-1 ⑤ q1+q-1
以下程序完成对数组每个元素向后移动n个单位。数组元素的下标依次为0到m-1,对任意一个数组元素a[i]而言,它的值移动后将存储在数组元素a[(i+n) mod m]中。
例如,m=10,n=3,移动前数组中存储的数据如下前一行所示,则程序运行后数组中存储的数据如下后一行所示。
0 3 86 20 27 67 31 16 37 42
16 37 42 0 3 86 20 27 67 31
const maxm=10000;
var i,k,m,n,rest,start,temp:longint;
a:array [0..maxm] of longint;
begin
write('input m,n:');
readln(m,n);
for i:=0 to m-1 do a[i]:=random(100);
writeln('before move');
for i:=0 to m-1 do write(a[i]:5);
writeln;
rest:=m; start:=0;
while ① do
begin
k:=start;
repeat k:=(k+n) mod m until k<=start;
if ② then
begin
temp:=a[k];
repeat
a[k]:=a[(m*n+k-n) mod m];
k:=(m*n+k-n) mod m;
③
until k=start;
④
end;
⑤
end;
writeln('after move');
for i:=0 to m-1 do write(a[i]:5);
writeln
end.
模块1——初始化
模块2——移动计算 ,其中
子模块1:判断以a[k]开始的的循环链上的元素是否都未移动过
子模块2:若以a[k]开始的的循环链上的元素都未移动过,则该循环链进行移动
子模块3:寻找下一个未移动过的循环链
模块3——输出移动后的数组
由此得出解为
① rest>0 或 rest<>0 ② k=start ③ rest:=rest-1
④ a[(k+n) mod m]:=temp 或 a[(start+n) mod m]:=temp
⑤ start:=start+1
完善含子程序结构的程序
如果子模块采用过程或函数,则通常以子程序为单位划分层次结构,这样可以使得其层次性相对不含子程序的程序来说要清晰一些。
程序的任务是用0…9中的n个数字填入如下乘法运算的*处,数字可重复使用,且所用的数字至少有一个是素数,要求输出满足下列算式的方案数。
* * *
× * *
-----------------
* * *
* * *
-----------------
* * * *
const p:set of 0..9=[2,3,5,7];
var
s:set of 0..9;
n:integer;
ans:longint;
f:text;
procedure init;
var
i:integer;
t:byte;
begin
readln(n); s:=[];
for i:=1 to n do
begin
read(t); s:=s+[t];
end;
close(f);
end;
function ok(x,l:integer):boolean; {此函数判断x是否符合条件}
var t:byte;
begin
ok:=false;
if _______①________< >l then exit;
while x<>0 do
begin
t:=x mod 10;
if not (t in s) then exit;
x:=x div 10;
end;
ok:=true;
end;
function inset(x:integer):boolean; {此函数判断x中是否包含素数字}
var t:byte;
begin
inset:=false;
while ______②_______ do
begin
t:=x mod 10;
if t in p then
begin
inset:=true;
exit;
end;
________③________
end;
end;
procedure work;
var i,i1,i2,i3,j1,j2:integer;
begin
ans:=0;
for i1:=1 to 9 do
if i1 in s then
for i2:=1 to 9 do
if i2 in s then
for i3:=1 to 9 do
if i3 in s then
begin
_________④_________
for j1:=1 to 9 do
if (j1 in s) and ok(j1*i,3) then
for j2:=1 to 9 do
if (j2 in s) and ok(j2*i,3) and _________⑤_________ then
begin
if (i1 in p) or (i2 in p) or (i3 in p) or (j1 in p) or (j2 in p) or inset(j1*i) or inset(j2*i)
then inc(ans);
end;
end;
writeln(ans);
end;
begin
init;
work;
end.
模块1——初始化。读入数字个数n和n个整数,并将它们送入集合s(init过程)。
模块2——计算和输出方案数ans(work过程)
在s集合中枚举所有可能的被乘数i1 i2 i3和所有可能的乘数j1 j2,被乘数和乘数必须满足如下条件
⑴j1*i的积和j2*i的积分别为3位,(j1 j2)*i的积为4位,且积的每一位数字在集合s中。在work过程中,通过调用布尔函数ok(x,l)来判别数字x是否满足各位数字在集合s且位数为l位的条件
⑵i1、i2、i3、j1、j2、j1*i的各位数、j2*i的各位数中至少有一个为素数。在work过程中,通过调用布尔函数inset(x)来判别多位数x中是否存在素数字
由此得出解为
①trunc(ln(x)/ln(10))+1 ②x>0 ③ x:=x div 10
④ i:=i1*100+i2*10+i3 ⑤ ok(j1*i*10+j2*i,4)
菲波拉契数列为1,1,2,3,5,8,13,21,……, 其元素产生的规则是前两个数为1,第三个数开始每个数等于它前面两个数之和。已知任意一个正整数可以表示为若干个互不相同的菲波拉契数之和。
例如:36=21+13+2
下面的程序是由键盘输入一个正整数n,输出组成n的互不相同的菲波拉契数
⑴寻找小于等于n的最大菲波拉契数a,并以a作为组成n的一个数;
⑵若n≠a,则以n-a作为n的新值,重复步骤(1)。若a=n,则结束:
var n:integer;
first:boolean;
function find(n:integer):integer;
var a,b,c:integer;
begin
a:=1;b:=1;
repeat
c:= ① ;
a:=b;b:=c;
until b>=n;
if b=n then find:= ②
else find:= ③
end;
procedure p(n:integer);
var a:integer;
begin
a:=find(n);
if first then begin
write(a:4); first:=false
end
else write('+',a:4);
if aend;
begin
readln(n); first:=true;{设定表达式首项标志}
write(n:5,'='); p(n);
writeln; readln
end.
p(n)的功能:计算和输出n对应的表达式。
p(n)的子函数find(n)的功能:寻找小于等于n的最大菲波拉契数
由此得出解为
① a+b
② n (或b , c )
③ a
④ (n-a)
题一 均分纸牌
题二 字串变换
题三 自由落体
题四 矩形覆盖
算法知识分布
虽然2002年全国奥林匹克信息学复赛中含许多可“一题多解” 的试题,但如果按照较优算法标准分类的话,大致可分为
算法 分区联赛
几何计算(点和矩形的关系) 矩形覆盖
字符串处理 字符近似查找
回溯法 选数、字串变换
构造法 级数求和、 均分纸牌、自由落体
特 点
1、凸现信息学知识和学科知识整合的趋势。为了考核学生运用学科知识的能力,激发学生的创造力,2002年全国奥林匹克信息联赛(NOIP)中学科类的试题增加,并且首次出现了计算几何类的试题(矩形覆盖)。这说明信息学与学科的依赖关系日益凸现,学科基础好、尤其是数学素质好的人虽然不一定会编程,但希望学习编程的人愈来愈多;编程解题能力强的人势必有数学的潜质和爱好,他们中愈来愈多的人也希望深造数学。各门学科的交融和整合是奥林匹克信息学联赛活动发展的一个大趋势(有专家提议,数学教材讲算法,信息科技教材讲语言,上海的信息科技教材出现真值表(初中)和c语言(高中))。
2、“构造法” 或贪心策略类试题的引入,使得算法知识的不确定性和不稳定性增加。这正体现了科学的本质—知识是不断推陈出新的。
3、试题的综合性增加,并不一定随知识的分类而发生变化,有时几乎找不到一个单一的经典算法(字串变换——回溯法中有字符串处理),也找不到一个纯粹的数据结构问题(级数求和——需要为表达式的计算结果设计合适的数据类型),关键是你从哪个角度去分析,也就是说能不能综合所学的知识,应用自如地解决问题。选手的综合素质愈高,得胜的机率愈大;
4、经常面对着不知道算法的试题,面对着谁都不知如何处置的情境(经常出现许多选手在一题中得0分、优秀选手表现失常的情况),因此必须使学生正确地理解问题、深入问题的空间并形成解决问题的意识、习惯和能力。能不能创造性地应答没有遇到过的挑战,成为培训的基本要求和目标。
1、培养问题意识和问题能力。创造始于问题。“有了问题才会思考,有了思考才有解决问题的方法,才有找到独立思路的可能(陶行知)”。有问题虽然不一定有创造,但没有问题一定没有创造(想一想当前的解法有没有缺陷,有没有更好的算法,它与哪些问题有联系,与哪些知识相关联,还可以拓延出哪些问题,要解决这些问题还需要哪些知识);
启 示
2、处理好前沿性与基础性、直线培训和散点培训、循序渐进与跳跃式的矛盾。如果恪守按部就班的培训程序,不谋求跳跃式学习,将离全国和国际奥林匹克信息学活动的前沿、离世界程序设计知识的前沿愈来愈远。因此在进行基础课程学习的同时,必须有追逐前沿的选择性学习。这里,有时候心理的障碍比科学上的障碍更难跨越,敢不敢的问题比能不能的问题更突出。其实在学习中或多或少地都有必要的跳跃,不少人还能够实现比较大的跳跃( 爱笛生小学三年级退学、比尔.盖茨大学三年级退学)
学生必须学会从浩如烟海的信息中选择最有价值的知识,构建个性化(符合自己能力结构和兴趣结构)和竞争需要的知识结构
培训内容要有选择性,因为除了出题者,谁也说不清楚在未来竞赛中究竟什么知识是必要的(对基础的理解是主观的选择。例如中国、美国和俄罗斯的理科教材大不相同,有的同年级同学科的教材相差三分之二),因此不可能把所有重要的东西都选择好了给学生,而是应该将直线培训与散点培训相结合,选择部分重要的东西交给学生,让他们自己去探索若干知识点之间的联系,补充自己认为需要补充的知识。
3、参与活动的学生应由竞争关系和独立关系(你做你的,我干我的,程序和算法互相保密,彼此津津乐道于对方的失败和自己的成功)转向合作学习的关系(通过研讨算法、集中编程、互测数据等互相合作的方式完成学习任务)
学生的心理调适:
我掌握的知识仅不过是沧海一粟(进取心);
固守错误的概念比一无所知更可怕(明智);
三人之行必有我师(谦虚);
知识生产社会化条件下人的基本素质之一是合作精神(现在的重大科学发明需要成百上千科学家进行长期甚至跨国的合作,例如制作windows,人类基因工程)(现代意识);
前提条件:水平相当的同质成员或各有所长(包括数学知识、编程能力和思维方式等解题所需的各种因素)的异质成员是开展合作学习的组织基础;
合作学习的效应:
集思广益容易出好的算法;
群体设计的测试数据相对全面;
在群体活动中能比较客观的反映自己能力情况;
每个学生在付出与给予中可提高合作精神和编程能力,成功者往往是那些相容性好、 乐于帮助他人,并且善于取他人之长的学生(符文杰、张一飞等)。
4、选手面对从未遇到过的挑战应调整好心态,不要急功近利,要只管耕耘、不问收获、潜心钻研、其乐无穷。那怕是一两次失误,也是砥砺之石,可从中汲取有益的经验和教训。“不是一番寒彻骨,哪得梅花扑鼻香”。
题一 均分纸牌
[问题描述] 有N堆纸牌,编号分别为1,2,….N。每堆上有若干张, 但纸牌总数必为N的倍数。可以在任一堆上取若干张纸牌,然后移动。移牌规则为:在编号为1堆上取的纸牌,只能移到编号为2的堆上;在编号为N的堆上取的纸牌,只能移到编号为N-1的堆上;其他堆上取的纸牌,可以移到相邻左边或右边的堆上。现在要求找出一种移动方法,用最少的移动次数使每堆上纸牌数都一样多。例如N=4,4堆纸牌数分别为:
① 9 ② 8 ③ 17 ④ 6
移动3次可达到目的:从③取4张牌放到④(9 8 13 10)→从③取3张牌放到②(9 11 10 10)→从②取1张牌放到①(10 10 10 10)。
[ 输 入 ]: N ( N 堆纸牌,1≤N≤100)
A1,A2,….An (N 堆纸牌,每堆纸牌初始数,1≤Ai≤10000)
[ 输 出 ]:所有堆均达到相等时的最少移动次数。
[输入输出样例]
输入:
4
9 8 17 6
输出:
3
设list为纸牌序列,其中list[i]为第i堆纸牌的张数(1≤i≤n),ave为均分后每堆纸牌的张数,即 ;ans为最少移动次数。
我们按照由左而右的顺序移动纸牌。若第i堆纸牌的张数list[i]超出平均值,则移动一次(ans+1),将超出部分留给下一堆,既第i+1堆纸牌的张数增加list[i]-ave;若第i堆纸牌的张数list[i]少于平均值,则移动一次(ans+1),由下一堆补充不足部分,既第i+1堆纸牌的张数减少ave-list[i];
右邻堆取的牌
问题是,在从第i+1堆中取出纸牌补充第i堆的过程中,可能会出现第i+1堆的纸牌数小于零(list[i+1]-(ave-list[i])<0 )的情况,这时可以理解为一个“先出后进”的栈。由于纸牌的总数是n的倍数,因此后面的堆会补充第i+1堆ave-list[i]-list[i+1]+ ave张纸牌,使其达到均分的要求。
第四堆补充第三堆
第三堆补充第二堆
第二堆补充第一堆
在枚举分牌方案时,是否可以利用上述计数方法呢?
题二 字串变换
[问题描述]:已知有两个字串A$,B$及一组字串变换的规则:
A1$→B1$
A2$→B2$
………
规则的含义为:在A$中的子串A1$可以变换为B1$、A2$可以变换为B2$…..。例如:
A$ =‘abcd’ B$=‘xyz’
变换规则为:
‘abc’→‘xu’ ‘ud’→‘y’ ‘y’→‘yz’
则此时,A$可以经过一系列的变换变为B$,其变换的过程为:
‘abcd’→‘xud’→‘xy’→‘xyz’
共进行了三次变换,使得A$变换为B$。
[输入]:输入文件名为A.in。文件格式如下:
A$,B$
A1$ → B1$
A2$ → B2$ 变换规则
………
所有字符串长度的上限为255。
[输 出]:输出文件名为A.out。若在30步(包含30步)以内能将A$变换为B$,则向A.out输出最少的变换步数;否则向A.out输出‘ERROR!’。
[输入输出样例]
A.in文件:
abcd,xyz
abc->xu
ud->y
y->yz
A.out文件:
3
1、分析变换规则
设
规则序列为rule,其中第i条规则为rule[i,1]→rule[i,2];
当前串为now,其中tmp为now的一个待匹配子串。由于匹配过程的由左而右进行的,因此设j为now的指针,即从now的第j个字符开始匹配rule[i,1]。now适用第i条规则的条件是
now中的子串被第i条规则替换后的长度小于255,即
length(now)+length(rule[i,2])-length(rule[i,1])≤255
rule[i,1]是now的一个子串(k=pos(rule[i,1],tmp)≠0)
在使用了第i条规则后,now变换为
now= copy(now,1,j+k-1)+rule[i,2]+copy(now,j+k+length(rule[i,1]),255)
由于now中可能有多个子串被第i条规则替换,因此每替换一次后,为了方便地找出下一个替换位置,我们将当前被替换串前(包括被替换串)的子串删除。
2、使用回溯法计算最少替换次数
由于原串a、目标串b和规则rule是随机输入的,因此不可能找出直接计算最少替换次数best的数学规律,只能采用回溯搜索的办法。设
状态(need,now):替换次数为need,替换结果为now;
边界条件(need≥best)和目标状态(now=b):替换次数达到或超过目前得出的最小值为边界;已经替换出目标串为目标状态;
搜索范围i:尝试每一条规则,即1≤i≤规则数n;
约束条件(length(now)+length(rule[i,2])-length(rule[i,1])≤255):now中的子串被第i条规则替换后的长度小于255;
由此得出计算过程:
procedure solve(need;now);{从当前串now出发,递归第need次替换}
var
i,k,j:integer;
tmp:string;
begin
if need>=best then exit; {若到达边界,则回溯}
if now=b then begin{若达到目标状态,则记下替换次数,并回溯}
best←need; exit;
end;{then}
for i←1 to n do {搜索每一条规则}
if length(now)+length(rule[i,2])-length(rule[i,1])<=255
then begin {若使用了第i条规则后,串长不会超过上限}
j←0; tmp←now;{匹配指针初始化和待匹配子串初始化}
k←pos(rule[i,1],tmp); {尝试第i条规则}
while k>0 do {反复在tmp 中寻找子串rule[i,1]}
begin
solve(need+1,copy(now,1,j+k-1)+rule[i,2]+copy(now,j+k+length(rule[i,1]),255)); {递归下一次替换}
delete(tmp,1,k);{将当前被替换串前(包括被替换串)的子串删除}
j←j+k; {右移匹配指针}
k←pos(rule[i,1],tmp); {继续尝试第i条规则}
end;{while}
end;{then}
end;{ solve }
由此得出主程序:
读入初始串a和目标串;
读入替换规则rule;
best←31; {设定替换次数的上限}
solve(0,a); {回溯搜索最少的替换次数}
if best<=30 {输出最少替换次数}
then writeln(best)
else writeln('ERROR!');
、
题三 自由落体
[问题描述]: 在高为H 的天花板上有n个小球,体积不计,位置分别为0,1,2,…n-1。在地面上有一个小车(长为L,高为K,距原点距离为S1)。已知小球下落距离计算公式为 S=1/2*g*t2,其中 g=10, t为下落时间。地面上的小车以速度 V 前进。如下图:
小车与所有小球同时开始运动,当小球距小车的距离≤0.00001时,即认为小球被小车接受(小球落到地面后不能被接受)。请你计算出小车能接受到多少个小球。
[输入]:H,S1,v,L,k,n (1≤H,S1,v,L,k,n≤100000)
[输出]:小车能接受到的小球个数。
这是分区联赛最容易失误的一道试题,关键是弄清小车行程的物理意义和计算的精度误差!
算法分析
由题意可知,车顶与天花板的距离为h-k,小球由天花板落至车顶所花费的时间为t1= ,由天花板落至地面的时间为t2= 。小车与所有小球同时开始运动,当小球距小车的距离≤0.00001时,即认为小球被小车接受(小球落到地面后不能被接受)。
显然,若n1≥n2,则小车接受的小球数为n1-n2+1;否则小车未接受任何一个小球。
小车在行驶了t1*v-0.00001路程后接受了第一个小球,其编号为n1=min{n-1, }
小车在行驶了t2*v+0.00001路程后小球落地,小车接受最后一个小球的编号为n2=max{0, }。
为什么在n1的公式中加上L?为什么在n2的公式中加上0.5?为什么n1取下整、n2取上整?
矩形覆盖
[问题描述]:在平面上有n个点 (n≤100),每个点用一对整数坐标表示。例如:当n=4 时,4 个点的坐标分别为: p1(1,1), p2(2,2), p3 (6,3), p4(7,0)
这些点可以用 k 个矩形( k<4) 全部覆盖,矩形的边平行于坐标轴。如图一,当 k=2时,可用如图二的两个矩形s1,s2覆盖, s1,s2面积和为4。问题是当 n个点坐标和 k 给出后,怎样才能使得覆盖所有点的k个矩形的面积之和为最小呢。约定:
覆盖一个点的矩形面积为0;
覆盖平行于坐标轴直线上点的矩形面积也为0;
各个矩形间必须完全分开(边线也不能重合);
本试题是高中组复赛中最难的一道试题,对选手的几何基础和编程能力是一个比较严峻的考验。
算法分析
1、点和矩形的描述和关系
平面上的点由坐标(x,y)表示。由于计算过程是按照由下而上、由左而右进行的,因此我们按照x坐标递增的顺序和y坐标递增的顺序将n个点存入a序列。
矩形由2条平行于x轴的边界线和2条平行于y轴的边界线围成。为了计算最小矩形的方便,我们将空矩形的左边界设为∞、右边界为设-∞、下边界设为∞、上边界设为-∞。
2、计算覆盖所有点的一个最小矩形
设目前最小矩形的四条边界为maxx,maxy,minx,miny。如何按照面积最小的要求将a点加入矩形呢?显然需要调整边界线,使a点位于对应的边界线上。
初始时,我们设最小矩形为空,即左边界left为∞、右边界right为-∞、下边界top为∞、上边界bottom为-∞。然后由左而右,依次往矩形放入n个点,调整对应的边界线。最后得出的矩形为最小矩形,其面积为(右边界-左边界)*(上边界-下边界)
3、计算覆盖所有点的两个面积和最小的独立矩形
我们称彼此完全分开的矩形是独立的。两个覆盖所有点的独立矩形有两种形态:
我们将覆盖x轴左方点集a[1,1..j]的最小独立矩形存入tac[1,j];将覆盖x轴右方点集a[1,j..n]的最小独立矩形存入tdc[1,j];将覆盖y轴下方点集a[2,1..j]的最小独立矩形存入tac[2,j];将覆盖y轴上方点集a[2,j..n]的最小独立矩形存入tdc[2,j](注意:当k=3时,对应的点集不包括被矩形1覆盖的点(1≤j ≤n )。
Tac[1,j-1]
Tdc[1,j]
Tac[2,j-1]
Tdc[2,j]
为什么一定要考虑两个轴向,如果仅考虑一个轴向的话,有什么反例
问题是面积和最小的两个独立矩形究竟取哪一个形态,区分两个矩形的分界线j为何值,我们无法确定。不得已,只能将所有可能的情况枚举出来。设
var
best,now:longint;{两个独立矩形的最小面积和、当前方案中两个独立矩形的面积和}
枚举过程如下:
计算tac和tdc序列;
best←maxlongint; {最小矩形面积初始化}
for i←1 to 2 do begin {依次分析x轴向和y轴向}
k=3时顺序寻找i轴向上第一个未被矩形1覆盖的点j;
while j≤n do{枚举i轴向上所有可能的两个独立矩形,从中找出最佳方案}
begin
记下i轴向上点j的坐标h;
顺序寻找i轴向上最接近h点(k=3时,该点未被矩形1覆盖)的点j;
if 点j存在并且k=2,或者k=3时以点j为分界线的左矩形和右矩形与矩形1没有交集
then begin
now←(tac[i,j-1,1]-tac[i,j-1,3])*(tac[i,j-1,2]-tac[i,j-1,4])+(tdc[i,j,1]-tdc[i,j,3])*(tdc[i,j,2]-tdc[i,j,4]);{则计算两个独立矩形的面积和}
if nowend;{then}
end;{while}
end;{for}
if best=maxlongint {若找不到的两个独立矩形}
then返回失败标志-1
else返回两个矩形的最小面积和best;
end;{getans}
4、计算覆盖所有点的三个面积和最小的独立矩形
我们先枚举第一个矩形,该矩形覆盖x轴向上的点1、点i、点j、点h(1≤i≤n, i≤j≤n, j≤h≤n),求出覆盖它们的最小矩形。该矩形的上边界、下边界、左边界和右边界分别记为bottom、top、left、right。显然其面积为(bottom-top)*(right-left)。我们将该矩形称为矩形1。那么,平面上还有哪些点未在矩形1内,这些点将被另外两个独立的矩形所覆盖。
判断(x,y)是否在矩形1内的条件
(x≥left) and (x≤right) and (y≤bottom) and (y≥top)
判断矩形是否与矩形1相交的条件
(min(x1,right) ≥max(x2,left)) and (min(y1,bottom) ≥max(y2,top))
我们在得出矩形1的基础上,直接调用上述算法计算与矩形1分开的另外两个独立矩形的面积和,加上矩形1的面积便是三个独立矩形的面积和。问题是矩形1究竟覆盖了哪些点才能得出最优解呢?我们无法得知。无奈之下,只能通过枚举法搜索所有的可能情况
for i←1 to n do {枚举x轴向上三个点(点i、点j、点h)的所有可能组合}
for j←i to n do
for h←j to n do
begin
计算覆盖点1、点i、点j、点h的最小矩形(矩形1)的四条边界right、bottom、left、top;
now←(bottom-top)*(right-left); {计算矩形1的面积}
计算未被矩形1覆盖的点集u;
计算覆盖u且与矩形1不相交的两个独立矩形的最小面积和g;
if (g≥0) and (g+nowend;{for}
输出最小面积和best;
由此得出主程序:
读点数n和矩形数k;
读平面上的n个点;
分别沿x轴和y轴对n个点进行排序;
case k of
1: 计算和输出覆盖所有点的一个最小矩形面积;
2: 计算和输出覆盖所有点的两个最小独立矩形的面积和;
3: 计算和输出覆盖所有点的三个最小独立矩形的面积和;
end;{case}
如果k≥4,则算法将如何修改?
改善高精度运算的效率
用一个整型数组来表示一个很大的数,数组中的每一个数表示一位十进制数字。这种方法的缺点是,如果十进制数的位数很多,则对应数组的长度会很长,并增加了高精度计算的时间。改善高精度运算效率的两种方法 ⑴扩大进制数 ⑵建立因子表 一、扩大进制数 用一个Longint记录4位数字是最佳的方案。那么这个数组就相当于一个10000进制的数,其中每一个元素都是10000进制下的一位数。 1、数据类型 type numtype=array[0..9999] of longint; {整数数组类型,可存储40000位十进制数} var a,n: numtype; {a和n为10000进制的整数数组} st:string; {数串} la,ln integer; {整数数组a和n的长度}
2、整数数组的建立和输出 当输入数串st后,我们从左而右扫描数串st,以四个数码为一组,将之对应的10000进制数存入n数组中。具体方法如下: readln(st); {输入数串st} k←length(st); {取得数串st的长度} for i←0 to k-1 do begin {把st对应的整数保存到数组n中} j←(k-i+3) div 4-1; n[j]←n[j]*10+ord(st[i+1])-48; end;{for} ln←(k+3) div 4;
当得出最后结果a后,必须按照由次高位(a[la-2])到最底位(a[0])的顺序,将每一位元素由10000进制数转换成10进制数,即必须保证每个元素对应四位10进制数。例如a[i]=0015(0≤i≤la-2),对应的10进制数不能为15,否则会导致错误结果。我们按照如下方法输出a对应的10进制数: write(a[la-1]); {输出结果} for i←la-2 downto 0 do write(a[i] div 1000,(a[i]div 100)mod 10,(a[i]div 10)mod 10,a[i]mod 10);
3、介绍几个基本运算
⑴整数数组-1(n←n-1,n为整数数组)
我们从n[0]出发往左扫描,寻找第一个非零的元素(n[j]≠0,n[j-1]=n[j-2]=…=n[0]=0)。由于该位接受了底位的借位,因此减1,其后缀全为9999(n[j]= n[j]-1,n[j-1]=n[j-2]=…=n[0]=9999)。如果最高位为0(n[ln]=0),则n的长度减1。
j←0; {从n[0]出发往左扫描,寻找第一个非零的元素}
while (n[j]=0) do inc(j);
dec(n[j]); {由于该位接受了底位的借位,因此减1}
for k←=0 to j-1 do n[k]←9999; {其后缀全为9999}
if ((j=ln-1)and(n[j]=0)) then dec(ln); {如果最高位为0,则n的长度减1}
⑵整数数组除以整数(a←a/i,a为整数数组,i为整数)
我们按照由高位到底位的顺序,逐位相除。在除到第j位时,该位在接受了来自j+1位的余数(a[j]←a[j]+(j+1位相除的余数)*10000)后与i相除。如果最高位为0(n[ln]=0),则n的长度减1。
l←0; {余数初始化}
for j←la-1 downto 0 do begin{按照由高位到底位的顺序,逐位相除}
inc(a[j],l*10000); {接受了来自第j+1位的余数}
l←a[j] mod i; {计算第j位的余数}
a[j] ←a[j] div i; {计算商的第j位}
end;{for}
while (a[la-1]=0) do dec(la); {计算商的有效位数}
⑶两个整数数组相乘(a←a*n, a和n为为整数数组)
我们按照由高位到底位的顺序,将a数组的每一个元素与n相乘。当计算到a[j]*n时,根据乘法规则,a[j-1], …,a[0]不变,a[j]为a[j]为a[j]与n[0]的乘积,a[j+k]加上a[j]*n[k]的乘积(k=ln-1,ln-2, …,1),然后按照由底位到高位的顺序处理进位。最后,如果a[la-1]*n有进位,则乘积a的有效位数为la+ln;否则a的有效位数为la+ln-1。
for j←la-1 downto 0 do begin {a←a*n}
for k←ln-1 downto 1 do inc(a[j+k],a[j]*n[k]);
a[j] ←a[j]*n[0];
end;{for}
l←0; {进位初始化}
for j←0 to la+ln-1 do begin {按照由底位到高位的顺序处理进位}
inc(l,a[j]); {计算经过进位后的第j位}
a[j] ←l mod 10000; {将第j位规整为10000进制数}
l←l div 10000; {计算进位}
end;{for}
if (a[la+ln-1]<>0) {修改有效位数}
then inc(la,ln)
else inc(la,ln-1);
二、建立因子表
任何自然数都可以表示为n=p1k1*p2k2*……*ptkt的形式,p1,p2,……,pt为质因子。设num数组为自然数n,其中num[i]为因子i的次幂数(1≤i≤k)。显然,num[k], num[k-1]……, num[2]构成了一个自然数,该自然数可以用十进制整数数组ans存储。ans的计算过程如下
ans[0] ← 1; {将num转换为ans}
for i←2 to k do {枚举每一个因子}
for j←1 to num[i] do multiply (ans,i);{连乘num[i]个因子i}
multiply的过程为高精度十进制运算中的乘法运算(ans ans*I)
有了自然数n的因子表num,可以十分方便地进行乘法或除法运算。例如整数x含有k个因子i,经过乘法或除法后,num[i]=
我们按照上述方法依次处理x的每一个因子,得出的num即为积或商
procedure add(x, ob:longint);{ob=1,num←num*x;ob=-1,num←num/x}
var
i:longint;
Begin
for i←2 to x do {搜索x的每一个因子i}
while (x mod i =0) do {计算x含因子i的个数k。num[i]= }
begin
inc(num[i], ob);x ← x div i;
end;{while}
end;{add}
显然,如果n1=x1*x2*…*xk,则可以通过连续调用
add(x1,1);add(x2,1);…;add(xk,1);
得出n1对应的因子表num。如果n2=1/(x1,x2…xk),则可以通过连续调用
add(x1,-1);add(x2,-1);…;add(xk,-1);
得出n2对应的因子表num。注意,初始时num数组清零。
对一些不能套用简单的条条框框和现成模式、需要独立思考、见解独创和有所创新的非标准题,通过构造数学模型解决问题。数学模型的功能:
⑴解释功能:就是用数学模型说明事物发生的原因;
⑵判断功能:用数学模型判断原来的知识和认识的可靠性。
⑶预见功能:利用数学模型揭示事物的发展规律,为人们的行为提供指导或参考。
构造法解题的思路或步骤可以归纳为:
构造法解题的类型
⑴数学建模:通过沿用经典的数学思想建立起模型;或者提取现实世界中的有效信息,用简明的方式表达其规律,这种规律可以是一条代数公式、一幅几何图形,一个物理原理、一个化学方程式,等等。
⑵直接构造问题解答:只是构造法运用的一种简单类型。它只能针对问题本身,探索其独有性质,不具备可推广性。
通常考虑的因素
⑴选择的模型必须尽量多地体现问题的本质特征。但这并不意味着模型越复杂越好,累赘的信息会影响算法的效率。⑵模型的建立不是一个一蹴而就的过程,而是要经过反复地检验、修改,在实践中不断完善。⑶数学模型通常有严格的格式,但程序编写形式可不拘一格。
在建模过程中经常使用的策略有
⑴对应策略:将问题a对应另一个便于思考或有求解方法的问题b,化繁为简,变未知为已知。
⑵分治策略:将问题的规模逐渐减少,可明显降低解决问题复杂程度。算法设计的这种策略称之为分治策略,即对问题分而治之。
⑴递推的分治策略
⑵递归的分治策略
⑶归纳策略:归纳策略则是通过列举试题本身的特殊情况,经过深入分析,最后概括出事物内在的一般规律,并得到一种高度抽象的解题模型。
⑴递推式
⑵递归式
⑶制定目标
⑷贪心方案
⑷模拟策略:模拟某个过程,通过改变数学模型的各种参数,进而观察变更这些参数所引起过程状态的变化,由此展开算法设计。模拟题没有固定的模式,一般形式有两种:
⑴随机模拟:题目给定或者隐含某一概率。设计者利用随机函数和取整函数设定某一范围的随机值,将符合概率的随机值作为参数。然后根据这一模拟的数学模型展开算法设计。由于解题过程借助了计算机的伪随机数发生数,其随机的意义要比实际问题中真实的随机变量稍差一些,因此模拟效果有不确定的因素;
⑵过程模拟:题目不给出概率,要求编程者按照题意设计数学模型的各种参数,观察变更这些参数所引起过程状态的变化,由此展开算法设计。模拟效果完全取决于过程模拟的真实性和算法的正确性,不含任何不确定因素。由于过程模拟的结果无二义性,因此竞赛大都采用过程模拟。
模拟的解题方法一般有三种类型
⑴直叙式模拟
⑵筛选法模拟
⑶构造法模拟
一般方法:
⑴机理分析法
⑵统计分析法
1、机理分析法
根据客观事物的特性,分析其内部的机理,弄清关系,在适当抽象的条件下,得到可以描述事物属性的数学工具。
我们在联赛中可以用这种方法建立数学模型,然后根据所对应的算法求出解。如下图所示:
空中都市
在一个未来的空中都市中,有很多个小岛(城区)。现在要求在这些岛之间架一些桥梁(桥是架在两个岛之间的)。要求,首先,如果A与B之间有桥,B与C之间有桥,则A与C之间就不能再架桥了。即对于城市中的任意三个岛,不能在其中两两都架上桥。在这样的前提下,要求架的桥数最多(不考虑具体的空间结构问题),并计算其中的一个可行方案。
输入文件只包含一行,该行为一个非负整数n(0≤n≤1000),即城市中有n个小岛。
输出文件
桥数的最大值k
以下为k行,每行为一座桥相邻的两个小岛序号(a,b)
输入示例:
6
输出示例:
9
(1,2)
(2,3)
(3,4)
(4,5)
(5,6)
(6,1)
(1,4)
(2,5)
(3,6)
按照题意,如果小岛A与小岛B之间、小岛B与小岛C之间和小岛A与小岛C之间都有桥的话,则说明A、B、C三个小岛之间存在传递性。试题要求构造一个含n个顶点且满足下述条件的图
①任三个顶点间不含传递性
②图中所含边数最多。
我们通过下述方法将空中都市问题对应一个简单问题:
把n个小岛分为尽量平均的两部分,第一组为(或)个顶点,第二组为(或)个顶点。然后第一组的每一个顶点分别向第二组的所有顶点引出边。
下面,我们来证明这个构造方法的正确性。
由于两组的任一对顶点之间都有边相连,因此如果再架桥的话,只能在同组的一对顶点之间进行。如果在某一组的顶点i和顶点j间架桥,则由于顶点i和顶点j与另一组的任一个顶点k相连,使得顶点i、顶点j和顶点k之间存在传递关系,这是不允许的。而一个数拆分成两个数的积,两个数的值愈接近,积愈大。由此可见,按照上述方法得出的图所含边数最多。下面给出解法:
Readln(n);
k←ord(odd(n)); {n为偶数时,k=0;n为奇数时,k=1}
if k=1 {输出桥数的最大值}
then writeln((n-1)*(n+1)div 4)
else writeln((n*n) div 4);
for i←1 to (n-k)div 2 do {枚举第一组的每一个小岛}
for j←(n-k)div 2+1 to n do {枚举第二组的每一个小岛}
writeln(‘(‘,i,’,’,j,’)’); {输出架桥方案}
国际象棋(knight)
国际象棋是我们休息娱乐时所常玩的游戏。在各个棋子中,马的行进方式最为特殊,也为人们所津津乐道。我们都知道:马走的是“日”字,也就是说每次都是向水平或竖直方向移动1格,而向另一个方向移动2格,所以也可称作是1*2的马(走法如下图所示)。在图中我们看到一个马由8种跳的方向。
小明是一个数学爱好者,他将马的走法重新定义了一下,重新定义后的广义马成为n*m的马。为了研究广义马,小明让马从(0,0)出发,随意的在一张足够大的棋盘上跳。他发现,有时候广义马总是无法跳入某些格子中,比如从2*2的马永远不可能跳到(1,1),这令他非常感兴趣。他希望知道对于给定的n,m,n*m的广义马是否能够跳到所有的格子。由于n,m可以非常大,这令小明花了许多功夫在尝试上,但仍不能得出肯定的结论。于是他就来找你这个计算机专家了帮忙。
【输入】
在输入文件knIGHT.In中包含了多组测试数据,每个测试数据占一行。
每组测试数据由2个数n,m(1≤n,m≤108)组成,表示广义马的类型。文件最后一行由2个0表示文件结束。
【输出】
将答案输出到文件knIGHT.OUT中,每组测试数据占一行。如果马能跳到指定的位置输出YES,否则输出ImPOSSIbLE。
⑴当n为奇数时,将棋盘染色成黑白相间。自(0,0)出发的马始终在白格子上跳跃,黑色的格子是马永远到不了的。
⑵当n为偶数时,我们有这样的移动方案(如上图(b)所示),使得马从(0,0)开始经过一系列的跳步后,到(1,0)的位置,也就是说可是让马到达相邻的格子,所以马可以遍历整个棋盘。
从最简单的1*n的广义马开始分析
将n*m的广义马对应1*n的广义马
第1种情况:若n,m有最大公约数p(p>1),则马只能跳到形似(p*s,p*t)的格子上,其他的格子都到达到不了。
第2种情况:若n+m是偶数,类似于1*n马的情况,马只能在同色的格子内跳动,不能遍历棋盘。
第3种情况:若n+m为奇数且n,m互质。不妨设n为奇数,那么m为偶数。因为1*n马的问题已经被彻底解决,所以很自然的想将n*m经过一系列变换转化成1*n马的问题。我们可以看到马的跳法本质上是4种(另4种可以看成是以下4种跳法反跳一步):
①(m,n) ②(m,-n) ③(n,m) ④(n,-m)
马经过跳p次①、q次②、r次③、s次④后
水平方向的位移为(p+q)*m+(r+s)*n 竖直方向的位移为(p-q)*n+(r-s)*m
为了利用1*n马的结论,解不定方程(p+q)*m+(r+s)*n=1。
∵n,m互质。∴该方程一定有解(p0,q0,r0,s0)。
又∵m是偶数n是奇数。∴(p0+q0)是偶数,(r0+s0)是奇数。
∵(p0+q0)与(p0-q0)同奇偶,而(r0+s0)与(r0-s0)同奇偶。
∴(p0-q0)是偶数,(r0-s0)是奇数。
∴(p0-q0)*n+(r0-s0)*m是偶数。
也就是马通过一系列的跳动所得到的效果相当于1*len的马跳一步的效果(len=(p0-q0)*n+(r0-s0)*m)。根据前面的结论,1*len的马可以遍历整个棋盘,所以当n+m为奇数且n,m互质时,n*m的马可以遍历整个棋盘。算法的时间复杂度为W(1),空间需求为W(1)。
var
n,m,temp:longint;{ n,m为广义马的类型}
function gcd(a,b:longint):longint;{计算n和m的最大公约数}
begin
if b=0 then gcd←a
else gcd←gcd(b,a mod b);
end;{ gcd }
begin
readln(n,m); {读广义马的类型}
if(n+m)mod2=0 {若n+m偶数,则无解}
then writeln('ImPOSSIbLE')
else begin
if nm,若不满足,则交换n,m}
temp←n;n←m;
m←temp;
end;{then}
if gcd(n,m)=1{若n,m互质,则输出成功信息;否则输出失败信息}
then writeln('YES')
else writeln('ImPOSSIbLE');
end;{else}
end.{main}
Dr. Steven最近在研究一种叫作X数列的整数数列。X数列有两个独特的性质:它的首项是0,任意相邻两项的差是1或者-1。
Dr. Steven正在研究X数列的长度与它的各项之和之间的关系。你是他的一名学生,也参加了这个课题。为了研究的方便,他希望你能够编一个程序:从输入文件中读入X数列的长度、X数列中所有项的和,找一个满足要求的X数列,并把结果写到输出文件中。
输入:
输入文件Sum.in的第一行是一个整数n(1≤n≤10 000),表示X数列中的项数。第二行是一个整数S(|S| ≤ 50 000 000),表示X数列中所有项的和。
输出:
把找到的满足要求的X数列输出到文件Sum.out中,每一项占一行,第k项输出在第k行,共n行。如果不存在这样的X数列,则输出“nO”。
X数列的和(Sum of X-Sequence)
长度为n的X数列共有2n-1个,要全部枚举一遍是不现实的。所以,一定有更好的方法。这就需要我们对题目作进一步的研究。只要做适当的变换,其中的奥秘就会浮出水面。
我们假设存在这样的一个数列{ai}满足题目要求,讨论S应满足的条件。
令bi=ai+1-ai,则由题目知,bi=1或-1。且a1=0,a2=b1,a3=b1+b2,……,an=b1+b2+……+bn-1。所以S=a1+a2+…+an=0+b1+(b1+b2)+…+(b1+b2+…+bn-1)=(n-1)b1+(n-2)b2+…+2*bn-2+bn-1 (1)
易知|S| (n-1)+(n-2)+……+1=(n-1)*n/2。1+2+……+(n-1)=(n-1)*n/2 (2)
由(2)式-(1)式得:(n-1)*n/2-S=(n-1)*(1- b1)+(n-2)*(1- b2)+……+2*(1- bn-2)+(1- bn-1)
因为1-bk=0或2,所以上式右端为偶数。要使等式成立,则其左端也为偶数,即S与(n-1)*n/2同奇偶。
再把等式两边同除以2,令ci=(1-bi)/2(易知ci=0或1),得[(n-1)*n/2-S]/2=(n-1) c1+(n-2) c2+……+ 2*cn-2+ cn-1
令T=[(n-1)*n/2-S]/2
所以原问题转化为一个简单的数学问题:T能否表示成1,2,……,(n-1)中若干个不重复的数之和。
这个问题不难解决。当0 T (n-1)*n/2时,T能够表示成1,2,……,(n-1)中若干个不重复的数之和。问题转化的必要性是显然的。接着用数学归纳法来证明它的充分性。证:
(1)当n=1时,0 T 0,0=0。
当n=2时,0 T 1,0=0,1=1。
当n=3时,0 T 3,0=0,1=1,2=2,3=1+2。
均成立。
(2)当n=k(k 3)时,归纳假设成立。则当n=k+1时:
①若0 T②若k T k*(k+1)/2,则先取出一个k,易知k*(k+1)/2 - k=(k-1)*k/2。归纳假设T-k可以表示成1,2,……,(k-1)中若干个不重复的数之和。此时c1= 1。
由此可证,对于满足0 T k*(k+1)/2的T,一定能够表示成1,2,……,k中若干个不重复的数之和。即n=k+1时,归纳假设亦成立。证毕。
由上面的分析证明过程可以得出,T的取值范围是[0, (n-1)*n/2],且T为整数。S的取值范围是[-(n-1)*n/2, (n-1)*n/2],且S为整数,S与(n-1)*n/2同奇偶。有了这个基础,我们便可以将原问题对应一个简单问题:
首先判断S是否在[-(n-1)*n/2, (n-1)*n/2]的范围内,且S是否与(n-1)*n/2同奇偶。如果这两个条件不成立,则所求的数列不存在。如果满足这两个条件,则令T=[(n-1)*n/2-S]/2,然后就按照上文中证明里的方法求ci,而ai=ai-1+bi-1= ai-1+1-2*ci-1,所以ai 的值也就迎刃而解了
var
a,i,n,s,t:longint;{n为数列的项数;s为各项的和;a为数列中的一项}
begin
readln(n);{输入x数列的项数和所有项的和}
readln(s);
t←n*(n-1) div 2;
if odd(s-t) or(abs(s)>t){ 判断S是否在[-(n-1)*n/2, (n-1)*n/2]的范围内,且S是否与(n-1)*n/2同奇偶}
then writeln('nO')
else begin
t←(t-s)div2;{令T=[(n-1)*n/2-S]/2}
a←0;{首项为0}
writeln(a);
for i←n-1 downto 1 do begin {逐项计算}
if t>=i {c=1,即aj=aj-1-1}
then begin
dec(t,i);dec(a)
end{then}
else inc(a);{c=0,即aj=aj-1+1}
writeln(a) {输出数列中的一项}
end;{for}
end;{else}
end.{main}
2、统计分析法:
我们在一时得不到事物的特征机理的情况下,通过某种方法测试得到一些数据(即问题的部分解),再利用数理统计知识对数据进行处理,从而得到最终的数学模型
极值问题
m,n 为整数,且满足下列两个条件:
① m,n ∈1, 2, 3, ……,k (1≤k≤109);
② (n2-mn-m2)2=1。
由键盘输入k,求一组满足上述两个条件的m,n 并且使m2+n2的值最大。
K
2
3
4
8
16
32
64
N
2
3
3
8
13
21
55
M
1
2
2
5
8
13
34
如果我们的猜想正确,那么当(n,m)是方程(n2-mn-m2)2=1的一组解时,根据斐波拉契数列关系,(n+m,n)也一定是方程的一组解。
若((n+m)2-(m+n)n-n2)2=1成立,则
=>(n2+(m+n)n-(n+m)2)2=1=>(n2+mn+n2-n2-2mn-m2)2=1=>(n2-mn-m2)2=1成立
以上各步可逆,所以当(n,m)是方程(n2-mn-m2)2=1的一组解时,(n+m,n)一定是方程的另一组解。
var m,n,next,k :longint;
begin
write('k= '); readln(k); {读入n和m的上限k}
if (k<1) or (k>1000000000) then halt; {如果k不在要求范围内,就终止}
m←1; n←1; next←m+n; {确定斐波拉契数列的头三项}
while next<=k do {顺推,求出m,n的最大值}
begin
m←n; n←next;next←m+n;
end;{while}
writeln('m= ',m); writeln('n= ',n); {输出可使m2+n2的值最大的m和n} end.{main}
取石子问题
有两堆石子,数量可能不同。有两个人轮流取。每次有两种不同的取法。一是在任意一堆中取走任意多的石子。二是在两堆中同时取走相同数量的石子。最后把石子全部取完的是胜者。现在给出初始的两堆石子的数目,现在如果轮到你来取,又假设双方都采取最好的策略,问最后你是胜者还是败者。
输入文件只有一行,其中包含两个非负整数a和b,表示两堆石子的数目。(a,b≤1,000,000,000)。
输出文件也只有一行,包含一个数字。如果最后你是胜者,则输出1。反之,则输出0。
输入示例:6 10
输出示例:0
1、分析失败的情况
测试结果有两种可能
①失败的情况:(1,2) (3,5) (4,7) (6,10) (8,13) (9,15) (11,18) (12,20) (14,23) (16,26) (17,28)(19,31) (21,34)…。
②胜利的情况:(1,1)(1,3)(1,4)…。 胜利的情况比失败的情况多得多。
在上述两种情况中,我们选择相对容易得出的失败情况展开分析,寻找规律;
① 从1开始的每一个数字,在这些数字对中都会出现一次且仅会出现一次;
②数对的差成等差数列1,2,3,4…;
③有些数对的数字排列来自斐波那契数列
④有些数对虽然不是标准斐波那契数列中的数字,但还是符合斐波那契数列的规则;
⑤如果数对(a,b)出现在其中,则(a+b,a+2b)也必然出现在数对中(相反的结论是不对的);
⑥数对中两个数之比都非常接近于=0.618,即著名的黄金分割数。
2 、判别a、b的输赢
由于从1开始的每一个自然数,按照斐波那契数列的规则不重复地出现在失败的数对中,因此,可以得出如下结论:
在失败的数对中如果一个数为x,则取(x*0.618)的小数部分k。
若数对按照递增顺序排列成(a,b),且满足a=,则确定(a,b)失败。由此得出算法:
readln(x,y);
if x>y then begin c←y;y←x;x←c;end; {按照递增顺序排列x和y}
if x=y div 1.618 then writeln(0) {若x和y接近黄金分割数,则失败;否则胜利}
else writeln(1);
复习内容
计算机的基础知识
学科知识(物理和数学知识、高精度运算、 表达式处理、进制转换)
PASCAL语言
数据结构(顺序存储结构的线性表、栈、队列、串、非线性结构—树和图)
归纳策略(递推法和递归法、贪心法)
开放性试题(用开放性的思维方式解题)
搜索策略( 枚举法、 回溯法、宽度优先搜索)
动态程序设计方法
参考资料
普及类参考书目基本体现了全国青少年信息学奥林匹克联赛的知识要求,并且涵盖了历年联赛的试题解析
书 名 出 版 社 作 者 出版日期
《计算机文化基础》 高等教育出版社 杨振山 龚沛曾 1999年
《计算机信息处理》 机械工业出版社 Stenven L.Mandell 著 尤晓东 杨小平 周靖 等译 1999年
《C常用算法程序集》 清华大学出版社 徐士良 1996年
《程序设计》 复旦大学出版社 吴伟国 王建德 2002年
《数据结构与算法分析》 南京师范大学出版社 王建德 2000年
《联赛模拟题及其解析》 中国青年出版社 王建德等 2003年
全国青少年信息学奥林匹克联赛试题解析 南京大学出版社 章维铣 2001年
祝同学们考出好成绩
谢谢!
上海市控江中学 王建德
2、2002年—分区联赛高中组试题解析
1、计算机基础知识
3、改善高精度运算的效率
4、构造法
一、 计算机的发展与应用
二、计算机组成与工作原理 和信息的表示与存储
三、多媒体应用
四、计算机网络使用基础
五、程序设计语言基础
六、程序的阅读分析
⑴计算机的发展历经了哪几个阶段;
⑵按照功能和规模,可将计算机分成哪几大类,它们各自的分工是什么;
⑶武装计算机的软件系统包括了哪些东西;
⑷计算机的发展怎样促使人类走向丰富多彩的信息社会;
⑸用户在使用计算机时应该遵守哪些道德规范;
计算机发展史上的里程碑——计算机存储程序的工作原理
美籍匈牙利数学家冯·诺依曼(von Neumaml)在1946年提出的,其思想是,在计算机中设置存储器,将符号化的计算步骤存放在存储器中,然后依次取出存储的内容,由一个被称之为控制器的部件进行译码,译码结果在一个被称为运算器的部件中进行计算,从而实现计算机工作的自动化(运算器和控制器统称为CPU)。冯·诺依曼依据此原理设计出一个完整的计算机雏形,并确定了计算机的五大组成部分和基本的工作方法。
操作系统是计算机系统中的一种系统软件,它能对计算机系统中的软件和硬件资源进行有效地管理和控制,合理地组织计算机的工作流程,为用户提供一个使用计算机的工作环境。
DOS——单用户的唯一任务占用计算机上所有的硬件和软件资源,所能访问的主存地址空间太小。
Windows——多作业、大内存管理、统一的图形用户界面 ,并且发展到网络环境使用
UNIX操作系统 、Linux操作系统 、Macintosh OS
数据库技术的特性
⑴最小冗余
⑵数据共享
⑶数据独立性
⑷安全性
⑸完整性
数据库管理系统的类型
⑴OLTP(联机事务处理)
⑵DSS(决策支持系统)
⑶EIS(行政信息系统)
⑷OA(办公室自动化)
⑸按其系统结构分为单机、Unix多用户、网络多用户、客户机/服务器、集中式、分布式、集中分布式等。
目前,世界上比较流行的数据库管理系统(DMS)有
⑴高档数据库产品,如Informix,Oracle,Sybase,Progress,Unify等
⑵中、低档数据库产品,如DBASE,Paradox,Super-Base,Foxpro,Clipper,SQL Base,Focus等;
⑶数据库开发工具,如Access,Visual Basic,Uniface,Power Builder,Q+EDatabase Editor等。
计算机病毒的特征
⑴能够将自身复制到其他程序中。
⑵不独立以文件形式存在,仅附加在别的程序上。当调用该程序运行时,此病毒则首先运行。
防治病毒的步骤:
⑴不要用软盘启动机器
⑵不要运行来路不明的软件
⑶定期备份重要系统数据
⑷重要的数据盘,程序盘应写保护
⑸使用杀毒软件检查和清除病毒
进位计数制之间的转换问题。
1、R进制转换为十进制
基数为R的数字,只要将各位数字与它的权相乘,其积相加,和数就是十进制数
(xp…x0.x-1…x-k)R=( )10
例:
1101101.01012
=1×2°+0×21+1×22+1×23十0×24+1×25+1×26+0×2-1+1×2-2+0×2-3+1×2-4
=109.3125
当从R进制转换到十进制时,可以把小数点作为起点,分别向左右两边进行,即对其整数部分和小数部分分别转换。对于二进制来说,只要把数位是1的那些位的权值相加,其和就是等效的十进制数。
2、十进制转换为R进制
将此数分成整数与小数两部分分别转换,然后再拼接起来。
+进制整数转换成R进制的整数,可用十进制数连续地除以R,其余数即为R系统的各位系数。此方法称之除R取余法。例如:将5710转换为二进制数
十进制小数转换成R进制时,可连续地乘以R,直到小数部分为0,或达到所要求的精度为止(小数部分可能永不为零),得到的整数即组成R进制的小数部分,此法称为“乘R取整”
例:将0.312510转换成二进制数
0.3125×2 =0.625 0.625×2 =1.25 0.25×2=0.5 0.5×2 =1.0
3、二、八、十六进制的相互转换
即每位八进制数相当于三位二进制数,每位十六进制数相当于四位二进制数。在转换时,位组划分是以小数点为中心向左右两边延伸,中间的0不能省略,两头不够时可以补0。
例如:将1011010.10 2转换成八进制和十六进制数
001 011 010. 100 1011010.102=132.48
1 3 2. 4
0101 1010. 1000 1011010.102=5A.816
5 A . 8
将十六进制数F7.28变为二进制数
F 7 . 2 8 F7.2816=11110111.001012
1111 0111.0010 1000
将八进制数25.63转换为二进制数
2 5 . 6 3 25.638=10101.1100112
10 101 . 110 011
三、在计算机中带符号数的表示法
1、机器数与真值
规定在数的前面增设一位符号位,正数符号位用“0”表示,负数符号位用“1”表示。
为了区别原来的数与它在计算机中的表示形式,我们将已经数码化了的带符号数称为机器数,而把原来的数称为机器数的真值。例如N1=+1001100、N2=-1001100为真值,其在计算机中的表示01001100和11001100为机器数。
2、原码〈true form〉
在用二进制原码表示的数中,符号位为0表示正数,符号位为1表示负数,其余各位表示数值部分。这种表示法称为原码表示法。字长为n的数(包括符号位)的原码表示法可定义为[x]原=
若真值丨x丨<1,其原码表示法可定义为[x]原=
例如对于8位二进制原码
[+0]原=00000000,[-0]原=10000000
[-1101001]原=10000000-(-1101001)=11101001
3、补码(two’s complement)
即[x]补=模+x
对于正数, [x]补=x,正数的补码就是该正数本身。
对于负数, [x]补=2n+x(mod 2n)。
[+0]补=[-0]补=00…0
[-2n-1]补=2n-2n-1=2n-1
4、反码〈0ne’s Complement〉
对于正数,它的反码表示与原码相同。即[x]反=[x]原
对于负数,则除符号位仍为“1”外,其余各位“1”换成”0”,”0”换成1”,即得到反码[X]反。例如[-1101001] 反=10010110。
对于0,它的反码有两种表示:[+0] 反=00…0 [-0] 反=11…1
当x为正数时,[x]反=[x]原=[x]补=x;当x为负数时,[x]补=2n+x=(2n-1)+x+1=[x]反+1,即[x]原除符号位外求反加1。若把[x]补除符号位外求反加1,就得到[x]原,即[[x]补]补=[x]原。例如x=-1101001。[x]原=11101001,[x]补=10010111, [[x]补]补=11101001 =[x]原。
5、补码的加减法运算
⑴补码的加法运算
在计算机中进行两个带符号数的加法运算时,只要将给定的真值用补码表示,就可以直接进行加法运算。在运算过程中不必判断加数和被加数的正负,一律做加法,最后将结果转换为真值即可。
⑵补码的减法运算
对于补码的减法运算,由于存在x-y=x+(-y),因此
[x-y]补=[x+(-y)] 补=[x]补+[-y]补 (mod2n)
其中[-y]补=[[y]补]补。
信息存储单位
⑴位(bit,缩写为b):度量数据的最小单位,表示一位二进制信息。
⑵字节(byte,缩写为B):一个字节由八位二进制数字组成(l byte=8bit)。字节是信息存储中最常用的基本单位。
计算机存储器(包括内存与外存)通常也是以多少字节来表示它的容量。常用的单位有:KB 1K=1024,MB 1M=1024K,GB 1G=1024M
⑶字(word):字是位的组合,并作为一个独立的信息单位处理。字又称为计算机字,它的含意取决于机器的类型、字长以及使用者的要求。常用的固定字长有8位、16位、32位等。
信息单位用来描述机器内部数据格式,即数据(包括指令)在机器内的排列形式,如单字节数据,可变长数据(以字节为单位组成几种不同长度的数据格式)等。
⑷机器字长:在讨论信息单位时,还有一个与机器硬件指标有关的单位,这就是机器字长。机器字长一般是指参加运算的寄存器所含有的二进制数的位数,它代表了机器的精度。机器的功能设计决定了机器的字长。一般大型机用于数值计算,为保证足够的精度,需要较长的字长,如32位、64位等。而小型机、微型机、微机一般字长为16位、32位等。
非数值信息的表示
西文字符编码
⑴ASCII码 ——“美国信息交换标准代码”的简称。ASCII码包括0~9十个数字,大小写英文字母及专用符号等95种可打印字符,还有33种控制字符(如回车、换行等)。一个字符的ASCII码通常占一个字节,用七位二进制数编码组成,所以ASCII码最多可表示128个不同的符号。最高位作为校验码,以便提高字符信息传输的可靠性。
数字和字母的ASCII码按照数字递增顺序或字典顺序排列排列,大写字母和小写字母的ASCII码是不同的。
⑵EBCDIC码——美国IBM公司在它的各类机器上广泛使用的一种信息代码。一个字符的EBCDIC码占用一个字符,用八位二进制码表示信息,最多可以表示出256个不同代码。
中文信息编码
目前的汉字编码方案有二字节、三字节甚至四字节的。下面我们主要介绍“国家标准信息交换用汉字编码”(CB2312-80标淮),以下简称国标码。
国际码是二字节码,用二个七位二进制数编码表示一个汉字。目前国标码收人6763个汉字,其中一级汉字(最常用)3755个,二级汉字3008个,另外还包括682个西文字符、图符。 在计算机内部,汉字编码和西文编码是共存的。区分的方法之一是对于二字节的国标码,将二个字节的最高位都置成1,而ASCIl码所用字节最高位保持0,然后由软件(或硬件)根据字节最高位来作出判断。
“多媒体技术”就是用计算机交互地综合处理文本、图形、图象、动画、音频及视频影象等多种信息,并使这些信息建立逻辑连接。
色彩数目 分辨率 特点
16 640*480 Windows的最低配置、显示速度最快
256 800*600 性能虽好一些,但易产生调色板的冲突
65536 1024*768 全彩的显示模式,色彩逼真,不会再有调色板的冲突。
16M 1284*1024 高等级的3D绘图软件和专业级的视频录制人员使用的真彩色模式,要求更多的RAM在显示卡和主机板上,CPU最好也是顶级的。
显示卡
水平分辨率×垂直分辨率×色彩数目=显示存储空间
显示加速:VRAM、EDO RAM,Windows RAM,Ramlbus DRAM
显示模式
数据压缩和解压缩技术
静止图像压缩标准JPEG(Joint Photographic ExpertsCroup)
动态图像压缩标准MPEG(Moving Picture Experts Croup)
多通道的动态图像压缩标准MP×64
相关名词
位图:由一点一点的像素点排成矩阵组成的,其中每一个像素点都可以是任意颜色。
向量图:用向量代表图中所表现的元素。
像素 :图形的最小组成单位
真彩色:人的眼睛能够分辨出的颜色大约有1万6千多种,为了能表现出这么多种色彩,我们得用24bit(224=16M)来描述一个像素的颜色,这种显示模式就称为真彩色。
RGB模式:分别代表红、绿、蓝三种颜色,计算机以RGB模式来定义计算机屏幕上的颜色。通过混色原理,不同比例的RGB色彩可调和出无穷多种颜色。
HSB模式:分别表示色调(hue)、饱和度(saturation)、亮度(bright)。不同的色调代表不同的颜色;饱和度指的是某区域中,该颜色量的多少,饱和度越低,该区域看起来就越灰暗;亮度则是指颜色的亮、暗,极亮成白色,极暗则成黑色。相对于RGB模式,HSB模式设定颜色的方式可产生更好的视觉效果。
多媒体信息处理工具
图形制作平台FreeHand
图像处理平台Photoshop
动画制作平台 Animation Pro
数字动画的类型:
⑴基于模型的动画
⑵帧动画
动画中加人声音的方法
⑴嵌人式—将声音文件经过转换合并到影片文件中去。
⑵流式—声音与文件分开,在影片播放的各个时机启动声音文件
音乐
⑴波形音频文件 :通过现场录制和模数转化产生,存储量大
⑵MIDI文件:使用键盘合成器和一个音序器 制作和编辑,存储量小
广域网( WAN ):实现远距离的计算机之间的数据传输和信息共享的计算机网络。通信线路一般租用电话线路或铺设专用电缆。
局域网络(LIN):为一个单位,或一个相对独立的局部范围内大量存在的微机能够相互通信、共享昂贵的外部设备(如大容量磁盘、激光打印机、绘图议等)、共享数据信息和应用程序而建立的计算机网络。通信线路一般不租用电话线路,使用专门铺设的线路。
互联网(Internet):将遍布全球的子网通过连网协议集成到一个共享的、开放的、易于管理的主干网。
计算机网络的物理组成
网络中心主干机 、服务器 、网络工作站
共享的外部设备
网卡
通信线路(双绞线、同轴电缆和光缆、无线传输介质(如微波、红外线和激光等))
局部网络通信设备(中继器、集线器 )
网络互连设备 (网桥、路由器和网关 )
网络软件 (对等式网络操作系统 、服务器上的网络操作系统)
计算机网络的拓扑结构
总线拓扑
星型拓扑
环型拓扑
树型拓扑
计算机网络的体系结构
所谓网络体系结构就是对构成计算机网络的各组成部分之间的关系及所要实现功能的一组精确定义。国际标准化组织(ISO)提出的开放系统互联参考模型(OSI)已成为网络体系结构的标准
Internet使用TCP/IP网络体系结构
TCP/IP的层号 TCP/IP的层次名 对应OSI模型的层次
3 应用层(ftp和telnet等协议) 应用层、表示层、会话层
2 传输控制协议TCP 传输层
1 网际协议IP 网络层
计算机网络应用模式
客户机/服务器模型:将应用分成客户机和服务器两大部分,并将它分配到整个网络上。由服务器提供资源,通常执行后台功能;而客户机使用服务器,通常执行前台功能。
文件服务器:提供操作系统中文件管理的各种功能(网络文件的访问方式:文件传输和文件访问 )
打印服务器:将一台或几台打印机物理地连接到打印服务器上,可为多个客户机用户轮流使用
数据库服务器:侧重于传统数据库管理系统的功能(如数据的定义及存取、数据的安全性与完整性、并发控制及事务处理等)的服务器
远程登录:通过用户帐号访问远地系统的资源
Internet 网络地址
IP地址:
网络数
网络主机数 主机数
A类网络 126 16387064 2064770064
B类网络 16256 64516 1048872096
C类网络 2064512 254 524386048
总计 2084894 3638028208
域名(或称主机名称):计算机主机名.子域名.子域名.最高层域名
Internet应用
文件传输 (使用匿名文件传输服务(匿名FTP)网上软件分类:公共软件 、免费软件 、共享软件 )
远程登录(Telnet 命令)
电子邮政服务 (电子邮箱地址:用户名@计算机域名)
网络新闻与公告牌服务 (网络新闻是由USENET在Internet中的新闻服务器节点之间进行传递的,阅读新闻组的软件有Outlook Express)
信息查询服务 (最为流行的信息查询服务系统是万维网(World Wide Web),简称WWW。 注意超文本和超媒体的概念 )
程序设计语言的组成
程序设计语言的基础是一组记号和规则。根据规则由记号构成的记号串的总体就是语言。 包括
语法:程序的结构或形式。编译系统会自动进行语法检验;
语义:程序的含义,亦即表示按照各种方法所表示的各个记号的特定含义,但不涉及使用者。语义的错误是在源程序编译通过后的运行过程中出现的,属于算法类的错误。
语用:程序和使用者的关系;
语言的成分
⑴数据成分,用以描述程序中所涉及的数据;
⑵运算成分,用以描述程序中所包含的运算;
⑶控制成分,用以描述程序中的控制构造;
⑷传输成分,用以表达程序中数据的传输。
语言和程序设计的发展
第一代语言——机器语言
第二代语言——汇编语言
第三代语言——高级语言、算法语言(BASIC、FORTRAN、COBOL、Pascal、C )
第四代语言——非过程化语言(SQL语言)
第五代语言——智能性语言(PROLOG语言 、LISP语言 )
面向对象方法的主要概念
⑴对象——系统中用来描述客观事物的一个实体,是构成系统的一个基本单位,对象由两个主要因素组成:
属性:描述对象静态特征的一个数据项;
服务:描述对象动态特征的一个操作序列;
⑵消息——对象之间通过服务请求发生联系,这种向对象发出的服务请求称为消息。
⑶类——为了很好地控制软件的复杂度,将具有相同属性和服务的一组对象组成类。
面向对象语言分为两大阵营
⑴Smalltalk和Eiffel为代表的纯粹型面向对象语言,主要强调软件开发的探索性和原型化开发方法;
⑵以C++、Object Pascal为代表的混合型面向对象语言,主要扩充现有语言,强调运行时的时空效率;
程序设计的特点
构造性 :不同的人为解决同一问题编制的程序,其面貌颇不相同,然而,程序的功效却是等价的。
严谨性:以上下文无关的形式语言实现。无法补充缺损信息、去掉冗余信息、将暂时不懂的信息暂时搁置起来,待下文或经过推理予以补充和理解
叠加性: 一般是将自己设计的子程序尽量分割成独立的、功能明确单一的小模块,以便充分利用;甚至还会利用系统内的库函数。
抽象性:把客观事物的描述抽象为数据和算法,并且利用抽象使得程序能够正确的映射客观事物 。抽象是有层次的 ,不同层次上的抽象是相互独立和互相作用的 。
计算程序的运行结果
一、直接推理
二、由流程图推断算法
三、动态模拟
四、由底向上阅读分析
对于一些语句少、结构简单且可读性较强的程序,不妨通过分析程序流程,直接寻找其间蕴含的计算模型。
{$n+}
var
m,n,I:integer;
t:extended;
begin
readln(n,m);
t:=1;
for i:=1 to m do t:=t*(n-i+1)/i;
writeln(t:0:0);
end.
输入
10 5
输出:
【分析】由for循环可以看出
t= ,即
i=1时,t=n;
i=2时,t=n*(n-1)/2;
i=3时,t=n* (n-1)/2 * (n-2)/3 ;
………
i=m时,t= c(n,m)=n!/(m!*(n-m)!)
显然,这是求组合数。当输入n=10、m=5时,程序应输出252。
这个算法的效率不错,因为计算与n和m的大小有直接的关系。所以,我们要设法使运算的中间结果尽可能地小。如果我们先把N~(N-M+1)这M个连续的自然数乘起来,再依次除以1~M就是一种不太明智的选择。上述程序先乘N除1,然后乘(N-1)除2,再乘(N-2)除3,……最后乘(N-M+1)除M。因为连续的K个自然数的积一定能被K!整除,所以在这一过程中不会出现除不尽的情况。同时也使得中间结果比较小,从而提高了运算速度。告诫读者的是,对于上述算法来说,n和m不能超过102。如果超过了这个上限,t就会溢出,尽管它采用了extended类型。
对于一些易读性不十分好的程序,最好的办法是画流程图。其步骤如下
⑴跟着程序画流程图,一句一框;
⑵根据上下文的联系合并流程图。若前几句计算值都要代入后一表达式,则合并为一框。接连合并几次,使程序成为一个大功能块;
⑶由大功能块推断算法;
⑷代入输入值,计算结果。
label 10,20,30;
var
s,p:string;
i,k,n,j,m:integer;
begin
readln(s); n:=length(s);
readln(p); m:=length(p);
i:=0;
10: i:=i+1; j:=i; k:=1;
20: if s[j]<>p[k]
then begin
if i
else if k
30:
writeln(i);
end.
输入 输出
asabcdffdin
fdi
这个程序的功能是计算s串中与p匹配的子串的首指针。当程序输入
asabcdffdin
fdi
程序应输出8,即s[8]…s[10]=p=‘fdi’。
动态模拟方法是采用人工模仿机器执行程序的方法计算结果值。首先选择程序中比较重要的变量作为工作现场。人工执行程序时,只要按照时间先后一步步记录下现场的变化,就能最后得出程序的运算结果。其具体布置如下:
⑴画表,画出程序执行时要用的现场情况表;
⑵基本读懂各语句的功能
⑶走程序,即动态模拟程序。主要根据各语句的功能,按照程序执行路径的先后顺序逐项填写现场情况表,直至得出最后结果;
动态模拟方法对简单程序、尤其是循环次数少的程序是很有效的。但对语句多和计算过程长的程序,这个方法则由于模拟速度太慢而不实用。
var
i,j:integer;
a:array[1..3,1..3]of integer;
begin
for i:=1 to 3 do
begin
for j:=1 to 3 do
begin
if i=3 then a[i,j]:=a[i-1,a[i-1,j]]+1
else a[i,j]:=j;
write(a[i,j]);
end;
writeln
end;
readln
end.
输出:
j
i
1
2
3
1
1
2
3
2
1
2
3
3
2
3
4
显然,最后应输出
1 2 3
1 2 3
2 3 4
var
a,d:array[1..100] of integer;
n,i,j,k,x,s:integer;
begin
n:=5;a[1]:=1;d[1]:=1;
for i:=1 to n do
begin
s:=i+1;x:=0;
for j:=1 to n+1-i do
begin
k:=s+x;x:=x+1;a[j+1]:=a[j]+k;
write(a[j],' ');
end;
writeln('...');d[i+1]:=d[i]+i;a[1]:=d[i+1];
end;
end.
输出:
外循环
内循环
i=
S=
d[i+1]
a[1]=
k=
x=
a[j+1]=
输出a[j]
1
2
2
2
2
1
3
1
2
3
2
6
3
3
4
3
10
6
4
5
4
15
10
5
6
5
21
15
2
3
4
4
3
1
5
2
2
4
2
9
5
3
5
3
14
9
4
6
4
20
14
3
4
7
7
4
1
8
4
2
5
2
13
8
3
6
3
19
13
4
5
11
11
5
1
12
7
2
6
2
18
12
5
6
6
1
17
11
最后应输出
1 3 6 10 15 …
2 5 9 14 …
4 8 13 …
7 12 …
11 …
由底向上分析的阅读分析方法就是在剖析了子程序和模块资源的基础上,建立对高层程序结构的理解,从而完成整个程序的阅读分析,即从最底层的子目标开始分析起,看它们做了哪些事情;然后分析上一层的子目标,看这些子目标在下一层子目标实现的基础上实现了哪些功能……。经过自底而上的阅读分析,最后得出计算模型。
const
limit = 3000;
type
tdata=array [0..limit] of longint;
var
ans ,num : tdata;
i,j,n:longint;
procedure update(var a:tdata);
var
int i;
begin
for i:=0 to limit-1 do
begin
inc(a[i+1],a[i] div 10);
a[i] := a[i] mod 10;
end;
end;
procedure mult(var a:tdata;b:integer);
var
i, j:integer;
begin
for i:=0 to limit do a[i] := a[i] * b;
update(a);
end;
procedure add(x, ob:longint);
var
i:longint;
begin
for i:=2 to x do
while (x mod i =0) do
begin
inc(num[i], ob);
x := x div i;
end;
end;
Begin
read(n);
fillchar(num, sizeof(num),0);
for i:= 0 to n do
begin
add(i+1,-1);
add(n+n-i,1);
end;{for}
add(n+1, -1);
fillchar(ans,sizeof(ans),0);
ans[0] := 1;
for i:=2 to limit do
for j:=1 to num[i] do mult(ans,i);
for i:=limit downto 0 do
if (ans[i] > 0) then
begin
for j:=i downto 0 do write(ans[j]);
writeln;break;
end;{then}
End.
输入 输出
5
update(var a)是将数组a规整为高精度的十进制数组
mult(var a,b)是将高精度的十进制数组a乘以整数b,积存储在a中。
add(x, ob)计算因子表,ob=1,num←num*x;ob=-1,num←num/x。其中num[i]为因子i的个数
主程序计算catalan数1/(n+1)*c(2*n,n) 。显然n=5,则程序输出42(1/6*c(10,5))
完善程序
填空内容:
1、变量方面的填空
2、循环方面的填空
3、分支转移方面的填空
4、主程序和子程序关系方面的填空
5、输入输出方面的填空
填空方法:
按照自顶向下的思维方法阅读程序——从主程序开始,沿控制层次向下阅读。在查到某一个子程序(子模块)时,比照题目给出的说明和调用它的“父程序(父模块)”,弄清该子程序(子模块)究竟要达到什么样的子目标,然后查程序,看它是如何实现这个子目标的。如果该子程序(子模块)有空格,则按照算法的逻辑进行填空。依次类推,直至最底层的子程序(子模块)中的空格全部填完为止。
1、完善不含子程序的程序
首先划分各个子模块的层次结构,并确定每个子模块的子目标。然后自顶向下,根据子目标和上层子模块给出的线索,对当前层次的各个模块进行填空。依次类推,直至最底层的子模块中的空格全部填完为止。
求元素之和最大的子方阵:在m×n(m,n≤20)的正整数数字方阵中,找出一个p×q的子阵(1≤p≤m,1≤q≤n)使其元素之和最大。例如,下面5×4的数字阵中,元素之和最大的一个2×3子阵。
5×4数字阵 元素之和最大的2×3子阵为
3
8
4
22
11
1
7
9
5
21
6
2
10
3
8
9
2
7
12
3
5
21
6
10
3
8
var a:array[1..20,1..20] of integer;
m,n,p,q,i,j,max,p1,q1,s,i1,j1:integer;
begin
for i:=1 to 20 do
for j:=1 to 20 do
a[i,j]:=0;
readln(m,n);
for i:=1 to m do
begin
for j:=1 to n do read(a[i,j]);
readln
end;
readln(p,q);
max:=0;
for i:=1 to m-p+1 do
for j:=1 to n-q+1 do
begin
① ;
for i1:=i to p+i-1 do
for j1:=j to q+j-1 do
② ;
if s>max then begin
③ ;
p1:=i;
q1:=j
end;
end;
for i:=p1 to ④ do
begin
for j:=q1 to ⑤ do
write(a[i,j]:3);
writeln
end;
readln
end.
模块1(初始化,白色):方阵清零;读方阵规模;读方阵;读子阵规模;子阵的最大数和初始化
模块2(湖蓝)通过枚举所有可能子阵,求数和最大的子阵 。其中
子模块1(深蓝):累计(i,j)为左上角的子阵的数和
子模块2(淡绿):调整子阵的最大数和
模块3(红色)——输出最大数和的子阵。
由此得出解
① s:=0 ② s:=s+a[i1,j1] ③ max:=s ④ p1+p-1 ⑤ q1+q-1
以下程序完成对数组每个元素向后移动n个单位。数组元素的下标依次为0到m-1,对任意一个数组元素a[i]而言,它的值移动后将存储在数组元素a[(i+n) mod m]中。
例如,m=10,n=3,移动前数组中存储的数据如下前一行所示,则程序运行后数组中存储的数据如下后一行所示。
0 3 86 20 27 67 31 16 37 42
16 37 42 0 3 86 20 27 67 31
const maxm=10000;
var i,k,m,n,rest,start,temp:longint;
a:array [0..maxm] of longint;
begin
write('input m,n:');
readln(m,n);
for i:=0 to m-1 do a[i]:=random(100);
writeln('before move');
for i:=0 to m-1 do write(a[i]:5);
writeln;
rest:=m; start:=0;
while ① do
begin
k:=start;
repeat k:=(k+n) mod m until k<=start;
if ② then
begin
temp:=a[k];
repeat
a[k]:=a[(m*n+k-n) mod m];
k:=(m*n+k-n) mod m;
③
until k=start;
④
end;
⑤
end;
writeln('after move');
for i:=0 to m-1 do write(a[i]:5);
writeln
end.
模块1——初始化
模块2——移动计算 ,其中
子模块1:判断以a[k]开始的的循环链上的元素是否都未移动过
子模块2:若以a[k]开始的的循环链上的元素都未移动过,则该循环链进行移动
子模块3:寻找下一个未移动过的循环链
模块3——输出移动后的数组
由此得出解为
① rest>0 或 rest<>0 ② k=start ③ rest:=rest-1
④ a[(k+n) mod m]:=temp 或 a[(start+n) mod m]:=temp
⑤ start:=start+1
完善含子程序结构的程序
如果子模块采用过程或函数,则通常以子程序为单位划分层次结构,这样可以使得其层次性相对不含子程序的程序来说要清晰一些。
程序的任务是用0…9中的n个数字填入如下乘法运算的*处,数字可重复使用,且所用的数字至少有一个是素数,要求输出满足下列算式的方案数。
* * *
× * *
-----------------
* * *
* * *
-----------------
* * * *
const p:set of 0..9=[2,3,5,7];
var
s:set of 0..9;
n:integer;
ans:longint;
f:text;
procedure init;
var
i:integer;
t:byte;
begin
readln(n); s:=[];
for i:=1 to n do
begin
read(t); s:=s+[t];
end;
close(f);
end;
function ok(x,l:integer):boolean; {此函数判断x是否符合条件}
var t:byte;
begin
ok:=false;
if _______①________< >l then exit;
while x<>0 do
begin
t:=x mod 10;
if not (t in s) then exit;
x:=x div 10;
end;
ok:=true;
end;
function inset(x:integer):boolean; {此函数判断x中是否包含素数字}
var t:byte;
begin
inset:=false;
while ______②_______ do
begin
t:=x mod 10;
if t in p then
begin
inset:=true;
exit;
end;
________③________
end;
end;
procedure work;
var i,i1,i2,i3,j1,j2:integer;
begin
ans:=0;
for i1:=1 to 9 do
if i1 in s then
for i2:=1 to 9 do
if i2 in s then
for i3:=1 to 9 do
if i3 in s then
begin
_________④_________
for j1:=1 to 9 do
if (j1 in s) and ok(j1*i,3) then
for j2:=1 to 9 do
if (j2 in s) and ok(j2*i,3) and _________⑤_________ then
begin
if (i1 in p) or (i2 in p) or (i3 in p) or (j1 in p) or (j2 in p) or inset(j1*i) or inset(j2*i)
then inc(ans);
end;
end;
writeln(ans);
end;
begin
init;
work;
end.
模块1——初始化。读入数字个数n和n个整数,并将它们送入集合s(init过程)。
模块2——计算和输出方案数ans(work过程)
在s集合中枚举所有可能的被乘数i1 i2 i3和所有可能的乘数j1 j2,被乘数和乘数必须满足如下条件
⑴j1*i的积和j2*i的积分别为3位,(j1 j2)*i的积为4位,且积的每一位数字在集合s中。在work过程中,通过调用布尔函数ok(x,l)来判别数字x是否满足各位数字在集合s且位数为l位的条件
⑵i1、i2、i3、j1、j2、j1*i的各位数、j2*i的各位数中至少有一个为素数。在work过程中,通过调用布尔函数inset(x)来判别多位数x中是否存在素数字
由此得出解为
①trunc(ln(x)/ln(10))+1 ②x>0 ③ x:=x div 10
④ i:=i1*100+i2*10+i3 ⑤ ok(j1*i*10+j2*i,4)
菲波拉契数列为1,1,2,3,5,8,13,21,……, 其元素产生的规则是前两个数为1,第三个数开始每个数等于它前面两个数之和。已知任意一个正整数可以表示为若干个互不相同的菲波拉契数之和。
例如:36=21+13+2
下面的程序是由键盘输入一个正整数n,输出组成n的互不相同的菲波拉契数
⑴寻找小于等于n的最大菲波拉契数a,并以a作为组成n的一个数;
⑵若n≠a,则以n-a作为n的新值,重复步骤(1)。若a=n,则结束:
var n:integer;
first:boolean;
function find(n:integer):integer;
var a,b,c:integer;
begin
a:=1;b:=1;
repeat
c:= ① ;
a:=b;b:=c;
until b>=n;
if b=n then find:= ②
else find:= ③
end;
procedure p(n:integer);
var a:integer;
begin
a:=find(n);
if first then begin
write(a:4); first:=false
end
else write('+',a:4);
if a
begin
readln(n); first:=true;{设定表达式首项标志}
write(n:5,'='); p(n);
writeln; readln
end.
p(n)的功能:计算和输出n对应的表达式。
p(n)的子函数find(n)的功能:寻找小于等于n的最大菲波拉契数
由此得出解为
① a+b
② n (或b , c )
③ a
④ (n-a)
题一 均分纸牌
题二 字串变换
题三 自由落体
题四 矩形覆盖
算法知识分布
虽然2002年全国奥林匹克信息学复赛中含许多可“一题多解” 的试题,但如果按照较优算法标准分类的话,大致可分为
算法 分区联赛
几何计算(点和矩形的关系) 矩形覆盖
字符串处理 字符近似查找
回溯法 选数、字串变换
构造法 级数求和、 均分纸牌、自由落体
特 点
1、凸现信息学知识和学科知识整合的趋势。为了考核学生运用学科知识的能力,激发学生的创造力,2002年全国奥林匹克信息联赛(NOIP)中学科类的试题增加,并且首次出现了计算几何类的试题(矩形覆盖)。这说明信息学与学科的依赖关系日益凸现,学科基础好、尤其是数学素质好的人虽然不一定会编程,但希望学习编程的人愈来愈多;编程解题能力强的人势必有数学的潜质和爱好,他们中愈来愈多的人也希望深造数学。各门学科的交融和整合是奥林匹克信息学联赛活动发展的一个大趋势(有专家提议,数学教材讲算法,信息科技教材讲语言,上海的信息科技教材出现真值表(初中)和c语言(高中))。
2、“构造法” 或贪心策略类试题的引入,使得算法知识的不确定性和不稳定性增加。这正体现了科学的本质—知识是不断推陈出新的。
3、试题的综合性增加,并不一定随知识的分类而发生变化,有时几乎找不到一个单一的经典算法(字串变换——回溯法中有字符串处理),也找不到一个纯粹的数据结构问题(级数求和——需要为表达式的计算结果设计合适的数据类型),关键是你从哪个角度去分析,也就是说能不能综合所学的知识,应用自如地解决问题。选手的综合素质愈高,得胜的机率愈大;
4、经常面对着不知道算法的试题,面对着谁都不知如何处置的情境(经常出现许多选手在一题中得0分、优秀选手表现失常的情况),因此必须使学生正确地理解问题、深入问题的空间并形成解决问题的意识、习惯和能力。能不能创造性地应答没有遇到过的挑战,成为培训的基本要求和目标。
1、培养问题意识和问题能力。创造始于问题。“有了问题才会思考,有了思考才有解决问题的方法,才有找到独立思路的可能(陶行知)”。有问题虽然不一定有创造,但没有问题一定没有创造(想一想当前的解法有没有缺陷,有没有更好的算法,它与哪些问题有联系,与哪些知识相关联,还可以拓延出哪些问题,要解决这些问题还需要哪些知识);
启 示
2、处理好前沿性与基础性、直线培训和散点培训、循序渐进与跳跃式的矛盾。如果恪守按部就班的培训程序,不谋求跳跃式学习,将离全国和国际奥林匹克信息学活动的前沿、离世界程序设计知识的前沿愈来愈远。因此在进行基础课程学习的同时,必须有追逐前沿的选择性学习。这里,有时候心理的障碍比科学上的障碍更难跨越,敢不敢的问题比能不能的问题更突出。其实在学习中或多或少地都有必要的跳跃,不少人还能够实现比较大的跳跃( 爱笛生小学三年级退学、比尔.盖茨大学三年级退学)
学生必须学会从浩如烟海的信息中选择最有价值的知识,构建个性化(符合自己能力结构和兴趣结构)和竞争需要的知识结构
培训内容要有选择性,因为除了出题者,谁也说不清楚在未来竞赛中究竟什么知识是必要的(对基础的理解是主观的选择。例如中国、美国和俄罗斯的理科教材大不相同,有的同年级同学科的教材相差三分之二),因此不可能把所有重要的东西都选择好了给学生,而是应该将直线培训与散点培训相结合,选择部分重要的东西交给学生,让他们自己去探索若干知识点之间的联系,补充自己认为需要补充的知识。
3、参与活动的学生应由竞争关系和独立关系(你做你的,我干我的,程序和算法互相保密,彼此津津乐道于对方的失败和自己的成功)转向合作学习的关系(通过研讨算法、集中编程、互测数据等互相合作的方式完成学习任务)
学生的心理调适:
我掌握的知识仅不过是沧海一粟(进取心);
固守错误的概念比一无所知更可怕(明智);
三人之行必有我师(谦虚);
知识生产社会化条件下人的基本素质之一是合作精神(现在的重大科学发明需要成百上千科学家进行长期甚至跨国的合作,例如制作windows,人类基因工程)(现代意识);
前提条件:水平相当的同质成员或各有所长(包括数学知识、编程能力和思维方式等解题所需的各种因素)的异质成员是开展合作学习的组织基础;
合作学习的效应:
集思广益容易出好的算法;
群体设计的测试数据相对全面;
在群体活动中能比较客观的反映自己能力情况;
每个学生在付出与给予中可提高合作精神和编程能力,成功者往往是那些相容性好、 乐于帮助他人,并且善于取他人之长的学生(符文杰、张一飞等)。
4、选手面对从未遇到过的挑战应调整好心态,不要急功近利,要只管耕耘、不问收获、潜心钻研、其乐无穷。那怕是一两次失误,也是砥砺之石,可从中汲取有益的经验和教训。“不是一番寒彻骨,哪得梅花扑鼻香”。
题一 均分纸牌
[问题描述] 有N堆纸牌,编号分别为1,2,….N。每堆上有若干张, 但纸牌总数必为N的倍数。可以在任一堆上取若干张纸牌,然后移动。移牌规则为:在编号为1堆上取的纸牌,只能移到编号为2的堆上;在编号为N的堆上取的纸牌,只能移到编号为N-1的堆上;其他堆上取的纸牌,可以移到相邻左边或右边的堆上。现在要求找出一种移动方法,用最少的移动次数使每堆上纸牌数都一样多。例如N=4,4堆纸牌数分别为:
① 9 ② 8 ③ 17 ④ 6
移动3次可达到目的:从③取4张牌放到④(9 8 13 10)→从③取3张牌放到②(9 11 10 10)→从②取1张牌放到①(10 10 10 10)。
[ 输 入 ]: N ( N 堆纸牌,1≤N≤100)
A1,A2,….An (N 堆纸牌,每堆纸牌初始数,1≤Ai≤10000)
[ 输 出 ]:所有堆均达到相等时的最少移动次数。
[输入输出样例]
输入:
4
9 8 17 6
输出:
3
设list为纸牌序列,其中list[i]为第i堆纸牌的张数(1≤i≤n),ave为均分后每堆纸牌的张数,即 ;ans为最少移动次数。
我们按照由左而右的顺序移动纸牌。若第i堆纸牌的张数list[i]超出平均值,则移动一次(ans+1),将超出部分留给下一堆,既第i+1堆纸牌的张数增加list[i]-ave;若第i堆纸牌的张数list[i]少于平均值,则移动一次(ans+1),由下一堆补充不足部分,既第i+1堆纸牌的张数减少ave-list[i];
右邻堆取的牌
问题是,在从第i+1堆中取出纸牌补充第i堆的过程中,可能会出现第i+1堆的纸牌数小于零(list[i+1]-(ave-list[i])<0 )的情况,这时可以理解为一个“先出后进”的栈。由于纸牌的总数是n的倍数,因此后面的堆会补充第i+1堆ave-list[i]-list[i+1]+ ave张纸牌,使其达到均分的要求。
第四堆补充第三堆
第三堆补充第二堆
第二堆补充第一堆
在枚举分牌方案时,是否可以利用上述计数方法呢?
题二 字串变换
[问题描述]:已知有两个字串A$,B$及一组字串变换的规则:
A1$→B1$
A2$→B2$
………
规则的含义为:在A$中的子串A1$可以变换为B1$、A2$可以变换为B2$…..。例如:
A$ =‘abcd’ B$=‘xyz’
变换规则为:
‘abc’→‘xu’ ‘ud’→‘y’ ‘y’→‘yz’
则此时,A$可以经过一系列的变换变为B$,其变换的过程为:
‘abcd’→‘xud’→‘xy’→‘xyz’
共进行了三次变换,使得A$变换为B$。
[输入]:输入文件名为A.in。文件格式如下:
A$,B$
A1$ → B1$
A2$ → B2$ 变换规则
………
所有字符串长度的上限为255。
[输 出]:输出文件名为A.out。若在30步(包含30步)以内能将A$变换为B$,则向A.out输出最少的变换步数;否则向A.out输出‘ERROR!’。
[输入输出样例]
A.in文件:
abcd,xyz
abc->xu
ud->y
y->yz
A.out文件:
3
1、分析变换规则
设
规则序列为rule,其中第i条规则为rule[i,1]→rule[i,2];
当前串为now,其中tmp为now的一个待匹配子串。由于匹配过程的由左而右进行的,因此设j为now的指针,即从now的第j个字符开始匹配rule[i,1]。now适用第i条规则的条件是
now中的子串被第i条规则替换后的长度小于255,即
length(now)+length(rule[i,2])-length(rule[i,1])≤255
rule[i,1]是now的一个子串(k=pos(rule[i,1],tmp)≠0)
在使用了第i条规则后,now变换为
now= copy(now,1,j+k-1)+rule[i,2]+copy(now,j+k+length(rule[i,1]),255)
由于now中可能有多个子串被第i条规则替换,因此每替换一次后,为了方便地找出下一个替换位置,我们将当前被替换串前(包括被替换串)的子串删除。
2、使用回溯法计算最少替换次数
由于原串a、目标串b和规则rule是随机输入的,因此不可能找出直接计算最少替换次数best的数学规律,只能采用回溯搜索的办法。设
状态(need,now):替换次数为need,替换结果为now;
边界条件(need≥best)和目标状态(now=b):替换次数达到或超过目前得出的最小值为边界;已经替换出目标串为目标状态;
搜索范围i:尝试每一条规则,即1≤i≤规则数n;
约束条件(length(now)+length(rule[i,2])-length(rule[i,1])≤255):now中的子串被第i条规则替换后的长度小于255;
由此得出计算过程:
procedure solve(need;now);{从当前串now出发,递归第need次替换}
var
i,k,j:integer;
tmp:string;
begin
if need>=best then exit; {若到达边界,则回溯}
if now=b then begin{若达到目标状态,则记下替换次数,并回溯}
best←need; exit;
end;{then}
for i←1 to n do {搜索每一条规则}
if length(now)+length(rule[i,2])-length(rule[i,1])<=255
then begin {若使用了第i条规则后,串长不会超过上限}
j←0; tmp←now;{匹配指针初始化和待匹配子串初始化}
k←pos(rule[i,1],tmp); {尝试第i条规则}
while k>0 do {反复在tmp 中寻找子串rule[i,1]}
begin
solve(need+1,copy(now,1,j+k-1)+rule[i,2]+copy(now,j+k+length(rule[i,1]),255)); {递归下一次替换}
delete(tmp,1,k);{将当前被替换串前(包括被替换串)的子串删除}
j←j+k; {右移匹配指针}
k←pos(rule[i,1],tmp); {继续尝试第i条规则}
end;{while}
end;{then}
end;{ solve }
由此得出主程序:
读入初始串a和目标串;
读入替换规则rule;
best←31; {设定替换次数的上限}
solve(0,a); {回溯搜索最少的替换次数}
if best<=30 {输出最少替换次数}
then writeln(best)
else writeln('ERROR!');
、
题三 自由落体
[问题描述]: 在高为H 的天花板上有n个小球,体积不计,位置分别为0,1,2,…n-1。在地面上有一个小车(长为L,高为K,距原点距离为S1)。已知小球下落距离计算公式为 S=1/2*g*t2,其中 g=10, t为下落时间。地面上的小车以速度 V 前进。如下图:
小车与所有小球同时开始运动,当小球距小车的距离≤0.00001时,即认为小球被小车接受(小球落到地面后不能被接受)。请你计算出小车能接受到多少个小球。
[输入]:H,S1,v,L,k,n (1≤H,S1,v,L,k,n≤100000)
[输出]:小车能接受到的小球个数。
这是分区联赛最容易失误的一道试题,关键是弄清小车行程的物理意义和计算的精度误差!
算法分析
由题意可知,车顶与天花板的距离为h-k,小球由天花板落至车顶所花费的时间为t1= ,由天花板落至地面的时间为t2= 。小车与所有小球同时开始运动,当小球距小车的距离≤0.00001时,即认为小球被小车接受(小球落到地面后不能被接受)。
显然,若n1≥n2,则小车接受的小球数为n1-n2+1;否则小车未接受任何一个小球。
小车在行驶了t1*v-0.00001路程后接受了第一个小球,其编号为n1=min{n-1, }
小车在行驶了t2*v+0.00001路程后小球落地,小车接受最后一个小球的编号为n2=max{0, }。
为什么在n1的公式中加上L?为什么在n2的公式中加上0.5?为什么n1取下整、n2取上整?
矩形覆盖
[问题描述]:在平面上有n个点 (n≤100),每个点用一对整数坐标表示。例如:当n=4 时,4 个点的坐标分别为: p1(1,1), p2(2,2), p3 (6,3), p4(7,0)
这些点可以用 k 个矩形( k<4) 全部覆盖,矩形的边平行于坐标轴。如图一,当 k=2时,可用如图二的两个矩形s1,s2覆盖, s1,s2面积和为4。问题是当 n个点坐标和 k 给出后,怎样才能使得覆盖所有点的k个矩形的面积之和为最小呢。约定:
覆盖一个点的矩形面积为0;
覆盖平行于坐标轴直线上点的矩形面积也为0;
各个矩形间必须完全分开(边线也不能重合);
本试题是高中组复赛中最难的一道试题,对选手的几何基础和编程能力是一个比较严峻的考验。
算法分析
1、点和矩形的描述和关系
平面上的点由坐标(x,y)表示。由于计算过程是按照由下而上、由左而右进行的,因此我们按照x坐标递增的顺序和y坐标递增的顺序将n个点存入a序列。
矩形由2条平行于x轴的边界线和2条平行于y轴的边界线围成。为了计算最小矩形的方便,我们将空矩形的左边界设为∞、右边界为设-∞、下边界设为∞、上边界设为-∞。
2、计算覆盖所有点的一个最小矩形
设目前最小矩形的四条边界为maxx,maxy,minx,miny。如何按照面积最小的要求将a点加入矩形呢?显然需要调整边界线,使a点位于对应的边界线上。
初始时,我们设最小矩形为空,即左边界left为∞、右边界right为-∞、下边界top为∞、上边界bottom为-∞。然后由左而右,依次往矩形放入n个点,调整对应的边界线。最后得出的矩形为最小矩形,其面积为(右边界-左边界)*(上边界-下边界)
3、计算覆盖所有点的两个面积和最小的独立矩形
我们称彼此完全分开的矩形是独立的。两个覆盖所有点的独立矩形有两种形态:
我们将覆盖x轴左方点集a[1,1..j]的最小独立矩形存入tac[1,j];将覆盖x轴右方点集a[1,j..n]的最小独立矩形存入tdc[1,j];将覆盖y轴下方点集a[2,1..j]的最小独立矩形存入tac[2,j];将覆盖y轴上方点集a[2,j..n]的最小独立矩形存入tdc[2,j](注意:当k=3时,对应的点集不包括被矩形1覆盖的点(1≤j ≤n )。
Tac[1,j-1]
Tdc[1,j]
Tac[2,j-1]
Tdc[2,j]
为什么一定要考虑两个轴向,如果仅考虑一个轴向的话,有什么反例
问题是面积和最小的两个独立矩形究竟取哪一个形态,区分两个矩形的分界线j为何值,我们无法确定。不得已,只能将所有可能的情况枚举出来。设
var
best,now:longint;{两个独立矩形的最小面积和、当前方案中两个独立矩形的面积和}
枚举过程如下:
计算tac和tdc序列;
best←maxlongint; {最小矩形面积初始化}
for i←1 to 2 do begin {依次分析x轴向和y轴向}
k=3时顺序寻找i轴向上第一个未被矩形1覆盖的点j;
while j≤n do{枚举i轴向上所有可能的两个独立矩形,从中找出最佳方案}
begin
记下i轴向上点j的坐标h;
顺序寻找i轴向上最接近h点(k=3时,该点未被矩形1覆盖)的点j;
if 点j存在并且k=2,或者k=3时以点j为分界线的左矩形和右矩形与矩形1没有交集
then begin
now←(tac[i,j-1,1]-tac[i,j-1,3])*(tac[i,j-1,2]-tac[i,j-1,4])+(tdc[i,j,1]-tdc[i,j,3])*(tdc[i,j,2]-tdc[i,j,4]);{则计算两个独立矩形的面积和}
if now
end;{while}
end;{for}
if best=maxlongint {若找不到的两个独立矩形}
then返回失败标志-1
else返回两个矩形的最小面积和best;
end;{getans}
4、计算覆盖所有点的三个面积和最小的独立矩形
我们先枚举第一个矩形,该矩形覆盖x轴向上的点1、点i、点j、点h(1≤i≤n, i≤j≤n, j≤h≤n),求出覆盖它们的最小矩形。该矩形的上边界、下边界、左边界和右边界分别记为bottom、top、left、right。显然其面积为(bottom-top)*(right-left)。我们将该矩形称为矩形1。那么,平面上还有哪些点未在矩形1内,这些点将被另外两个独立的矩形所覆盖。
判断(x,y)是否在矩形1内的条件
(x≥left) and (x≤right) and (y≤bottom) and (y≥top)
判断矩形是否与矩形1相交的条件
(min(x1,right) ≥max(x2,left)) and (min(y1,bottom) ≥max(y2,top))
我们在得出矩形1的基础上,直接调用上述算法计算与矩形1分开的另外两个独立矩形的面积和,加上矩形1的面积便是三个独立矩形的面积和。问题是矩形1究竟覆盖了哪些点才能得出最优解呢?我们无法得知。无奈之下,只能通过枚举法搜索所有的可能情况
for i←1 to n do {枚举x轴向上三个点(点i、点j、点h)的所有可能组合}
for j←i to n do
for h←j to n do
begin
计算覆盖点1、点i、点j、点h的最小矩形(矩形1)的四条边界right、bottom、left、top;
now←(bottom-top)*(right-left); {计算矩形1的面积}
计算未被矩形1覆盖的点集u;
计算覆盖u且与矩形1不相交的两个独立矩形的最小面积和g;
if (g≥0) and (g+now
输出最小面积和best;
由此得出主程序:
读点数n和矩形数k;
读平面上的n个点;
分别沿x轴和y轴对n个点进行排序;
case k of
1: 计算和输出覆盖所有点的一个最小矩形面积;
2: 计算和输出覆盖所有点的两个最小独立矩形的面积和;
3: 计算和输出覆盖所有点的三个最小独立矩形的面积和;
end;{case}
如果k≥4,则算法将如何修改?
改善高精度运算的效率
用一个整型数组来表示一个很大的数,数组中的每一个数表示一位十进制数字。这种方法的缺点是,如果十进制数的位数很多,则对应数组的长度会很长,并增加了高精度计算的时间。改善高精度运算效率的两种方法 ⑴扩大进制数 ⑵建立因子表 一、扩大进制数 用一个Longint记录4位数字是最佳的方案。那么这个数组就相当于一个10000进制的数,其中每一个元素都是10000进制下的一位数。 1、数据类型 type numtype=array[0..9999] of longint; {整数数组类型,可存储40000位十进制数} var a,n: numtype; {a和n为10000进制的整数数组} st:string; {数串} la,ln integer; {整数数组a和n的长度}
2、整数数组的建立和输出 当输入数串st后,我们从左而右扫描数串st,以四个数码为一组,将之对应的10000进制数存入n数组中。具体方法如下: readln(st); {输入数串st} k←length(st); {取得数串st的长度} for i←0 to k-1 do begin {把st对应的整数保存到数组n中} j←(k-i+3) div 4-1; n[j]←n[j]*10+ord(st[i+1])-48; end;{for} ln←(k+3) div 4;
当得出最后结果a后,必须按照由次高位(a[la-2])到最底位(a[0])的顺序,将每一位元素由10000进制数转换成10进制数,即必须保证每个元素对应四位10进制数。例如a[i]=0015(0≤i≤la-2),对应的10进制数不能为15,否则会导致错误结果。我们按照如下方法输出a对应的10进制数: write(a[la-1]); {输出结果} for i←la-2 downto 0 do write(a[i] div 1000,(a[i]div 100)mod 10,(a[i]div 10)mod 10,a[i]mod 10);
3、介绍几个基本运算
⑴整数数组-1(n←n-1,n为整数数组)
我们从n[0]出发往左扫描,寻找第一个非零的元素(n[j]≠0,n[j-1]=n[j-2]=…=n[0]=0)。由于该位接受了底位的借位,因此减1,其后缀全为9999(n[j]= n[j]-1,n[j-1]=n[j-2]=…=n[0]=9999)。如果最高位为0(n[ln]=0),则n的长度减1。
j←0; {从n[0]出发往左扫描,寻找第一个非零的元素}
while (n[j]=0) do inc(j);
dec(n[j]); {由于该位接受了底位的借位,因此减1}
for k←=0 to j-1 do n[k]←9999; {其后缀全为9999}
if ((j=ln-1)and(n[j]=0)) then dec(ln); {如果最高位为0,则n的长度减1}
⑵整数数组除以整数(a←a/i,a为整数数组,i为整数)
我们按照由高位到底位的顺序,逐位相除。在除到第j位时,该位在接受了来自j+1位的余数(a[j]←a[j]+(j+1位相除的余数)*10000)后与i相除。如果最高位为0(n[ln]=0),则n的长度减1。
l←0; {余数初始化}
for j←la-1 downto 0 do begin{按照由高位到底位的顺序,逐位相除}
inc(a[j],l*10000); {接受了来自第j+1位的余数}
l←a[j] mod i; {计算第j位的余数}
a[j] ←a[j] div i; {计算商的第j位}
end;{for}
while (a[la-1]=0) do dec(la); {计算商的有效位数}
⑶两个整数数组相乘(a←a*n, a和n为为整数数组)
我们按照由高位到底位的顺序,将a数组的每一个元素与n相乘。当计算到a[j]*n时,根据乘法规则,a[j-1], …,a[0]不变,a[j]为a[j]为a[j]与n[0]的乘积,a[j+k]加上a[j]*n[k]的乘积(k=ln-1,ln-2, …,1),然后按照由底位到高位的顺序处理进位。最后,如果a[la-1]*n有进位,则乘积a的有效位数为la+ln;否则a的有效位数为la+ln-1。
for j←la-1 downto 0 do begin {a←a*n}
for k←ln-1 downto 1 do inc(a[j+k],a[j]*n[k]);
a[j] ←a[j]*n[0];
end;{for}
l←0; {进位初始化}
for j←0 to la+ln-1 do begin {按照由底位到高位的顺序处理进位}
inc(l,a[j]); {计算经过进位后的第j位}
a[j] ←l mod 10000; {将第j位规整为10000进制数}
l←l div 10000; {计算进位}
end;{for}
if (a[la+ln-1]<>0) {修改有效位数}
then inc(la,ln)
else inc(la,ln-1);
二、建立因子表
任何自然数都可以表示为n=p1k1*p2k2*……*ptkt的形式,p1,p2,……,pt为质因子。设num数组为自然数n,其中num[i]为因子i的次幂数(1≤i≤k)。显然,num[k], num[k-1]……, num[2]构成了一个自然数,该自然数可以用十进制整数数组ans存储。ans的计算过程如下
ans[0] ← 1; {将num转换为ans}
for i←2 to k do {枚举每一个因子}
for j←1 to num[i] do multiply (ans,i);{连乘num[i]个因子i}
multiply的过程为高精度十进制运算中的乘法运算(ans ans*I)
有了自然数n的因子表num,可以十分方便地进行乘法或除法运算。例如整数x含有k个因子i,经过乘法或除法后,num[i]=
我们按照上述方法依次处理x的每一个因子,得出的num即为积或商
procedure add(x, ob:longint);{ob=1,num←num*x;ob=-1,num←num/x}
var
i:longint;
Begin
for i←2 to x do {搜索x的每一个因子i}
while (x mod i =0) do {计算x含因子i的个数k。num[i]= }
begin
inc(num[i], ob);x ← x div i;
end;{while}
end;{add}
显然,如果n1=x1*x2*…*xk,则可以通过连续调用
add(x1,1);add(x2,1);…;add(xk,1);
得出n1对应的因子表num。如果n2=1/(x1,x2…xk),则可以通过连续调用
add(x1,-1);add(x2,-1);…;add(xk,-1);
得出n2对应的因子表num。注意,初始时num数组清零。
对一些不能套用简单的条条框框和现成模式、需要独立思考、见解独创和有所创新的非标准题,通过构造数学模型解决问题。数学模型的功能:
⑴解释功能:就是用数学模型说明事物发生的原因;
⑵判断功能:用数学模型判断原来的知识和认识的可靠性。
⑶预见功能:利用数学模型揭示事物的发展规律,为人们的行为提供指导或参考。
构造法解题的思路或步骤可以归纳为:
构造法解题的类型
⑴数学建模:通过沿用经典的数学思想建立起模型;或者提取现实世界中的有效信息,用简明的方式表达其规律,这种规律可以是一条代数公式、一幅几何图形,一个物理原理、一个化学方程式,等等。
⑵直接构造问题解答:只是构造法运用的一种简单类型。它只能针对问题本身,探索其独有性质,不具备可推广性。
通常考虑的因素
⑴选择的模型必须尽量多地体现问题的本质特征。但这并不意味着模型越复杂越好,累赘的信息会影响算法的效率。⑵模型的建立不是一个一蹴而就的过程,而是要经过反复地检验、修改,在实践中不断完善。⑶数学模型通常有严格的格式,但程序编写形式可不拘一格。
在建模过程中经常使用的策略有
⑴对应策略:将问题a对应另一个便于思考或有求解方法的问题b,化繁为简,变未知为已知。
⑵分治策略:将问题的规模逐渐减少,可明显降低解决问题复杂程度。算法设计的这种策略称之为分治策略,即对问题分而治之。
⑴递推的分治策略
⑵递归的分治策略
⑶归纳策略:归纳策略则是通过列举试题本身的特殊情况,经过深入分析,最后概括出事物内在的一般规律,并得到一种高度抽象的解题模型。
⑴递推式
⑵递归式
⑶制定目标
⑷贪心方案
⑷模拟策略:模拟某个过程,通过改变数学模型的各种参数,进而观察变更这些参数所引起过程状态的变化,由此展开算法设计。模拟题没有固定的模式,一般形式有两种:
⑴随机模拟:题目给定或者隐含某一概率。设计者利用随机函数和取整函数设定某一范围的随机值,将符合概率的随机值作为参数。然后根据这一模拟的数学模型展开算法设计。由于解题过程借助了计算机的伪随机数发生数,其随机的意义要比实际问题中真实的随机变量稍差一些,因此模拟效果有不确定的因素;
⑵过程模拟:题目不给出概率,要求编程者按照题意设计数学模型的各种参数,观察变更这些参数所引起过程状态的变化,由此展开算法设计。模拟效果完全取决于过程模拟的真实性和算法的正确性,不含任何不确定因素。由于过程模拟的结果无二义性,因此竞赛大都采用过程模拟。
模拟的解题方法一般有三种类型
⑴直叙式模拟
⑵筛选法模拟
⑶构造法模拟
一般方法:
⑴机理分析法
⑵统计分析法
1、机理分析法
根据客观事物的特性,分析其内部的机理,弄清关系,在适当抽象的条件下,得到可以描述事物属性的数学工具。
我们在联赛中可以用这种方法建立数学模型,然后根据所对应的算法求出解。如下图所示:
空中都市
在一个未来的空中都市中,有很多个小岛(城区)。现在要求在这些岛之间架一些桥梁(桥是架在两个岛之间的)。要求,首先,如果A与B之间有桥,B与C之间有桥,则A与C之间就不能再架桥了。即对于城市中的任意三个岛,不能在其中两两都架上桥。在这样的前提下,要求架的桥数最多(不考虑具体的空间结构问题),并计算其中的一个可行方案。
输入文件只包含一行,该行为一个非负整数n(0≤n≤1000),即城市中有n个小岛。
输出文件
桥数的最大值k
以下为k行,每行为一座桥相邻的两个小岛序号(a,b)
输入示例:
6
输出示例:
9
(1,2)
(2,3)
(3,4)
(4,5)
(5,6)
(6,1)
(1,4)
(2,5)
(3,6)
按照题意,如果小岛A与小岛B之间、小岛B与小岛C之间和小岛A与小岛C之间都有桥的话,则说明A、B、C三个小岛之间存在传递性。试题要求构造一个含n个顶点且满足下述条件的图
①任三个顶点间不含传递性
②图中所含边数最多。
我们通过下述方法将空中都市问题对应一个简单问题:
把n个小岛分为尽量平均的两部分,第一组为(或)个顶点,第二组为(或)个顶点。然后第一组的每一个顶点分别向第二组的所有顶点引出边。
下面,我们来证明这个构造方法的正确性。
由于两组的任一对顶点之间都有边相连,因此如果再架桥的话,只能在同组的一对顶点之间进行。如果在某一组的顶点i和顶点j间架桥,则由于顶点i和顶点j与另一组的任一个顶点k相连,使得顶点i、顶点j和顶点k之间存在传递关系,这是不允许的。而一个数拆分成两个数的积,两个数的值愈接近,积愈大。由此可见,按照上述方法得出的图所含边数最多。下面给出解法:
Readln(n);
k←ord(odd(n)); {n为偶数时,k=0;n为奇数时,k=1}
if k=1 {输出桥数的最大值}
then writeln((n-1)*(n+1)div 4)
else writeln((n*n) div 4);
for i←1 to (n-k)div 2 do {枚举第一组的每一个小岛}
for j←(n-k)div 2+1 to n do {枚举第二组的每一个小岛}
writeln(‘(‘,i,’,’,j,’)’); {输出架桥方案}
国际象棋(knight)
国际象棋是我们休息娱乐时所常玩的游戏。在各个棋子中,马的行进方式最为特殊,也为人们所津津乐道。我们都知道:马走的是“日”字,也就是说每次都是向水平或竖直方向移动1格,而向另一个方向移动2格,所以也可称作是1*2的马(走法如下图所示)。在图中我们看到一个马由8种跳的方向。
小明是一个数学爱好者,他将马的走法重新定义了一下,重新定义后的广义马成为n*m的马。为了研究广义马,小明让马从(0,0)出发,随意的在一张足够大的棋盘上跳。他发现,有时候广义马总是无法跳入某些格子中,比如从2*2的马永远不可能跳到(1,1),这令他非常感兴趣。他希望知道对于给定的n,m,n*m的广义马是否能够跳到所有的格子。由于n,m可以非常大,这令小明花了许多功夫在尝试上,但仍不能得出肯定的结论。于是他就来找你这个计算机专家了帮忙。
【输入】
在输入文件knIGHT.In中包含了多组测试数据,每个测试数据占一行。
每组测试数据由2个数n,m(1≤n,m≤108)组成,表示广义马的类型。文件最后一行由2个0表示文件结束。
【输出】
将答案输出到文件knIGHT.OUT中,每组测试数据占一行。如果马能跳到指定的位置输出YES,否则输出ImPOSSIbLE。
⑴当n为奇数时,将棋盘染色成黑白相间。自(0,0)出发的马始终在白格子上跳跃,黑色的格子是马永远到不了的。
⑵当n为偶数时,我们有这样的移动方案(如上图(b)所示),使得马从(0,0)开始经过一系列的跳步后,到(1,0)的位置,也就是说可是让马到达相邻的格子,所以马可以遍历整个棋盘。
从最简单的1*n的广义马开始分析
将n*m的广义马对应1*n的广义马
第1种情况:若n,m有最大公约数p(p>1),则马只能跳到形似(p*s,p*t)的格子上,其他的格子都到达到不了。
第2种情况:若n+m是偶数,类似于1*n马的情况,马只能在同色的格子内跳动,不能遍历棋盘。
第3种情况:若n+m为奇数且n,m互质。不妨设n为奇数,那么m为偶数。因为1*n马的问题已经被彻底解决,所以很自然的想将n*m经过一系列变换转化成1*n马的问题。我们可以看到马的跳法本质上是4种(另4种可以看成是以下4种跳法反跳一步):
①(m,n) ②(m,-n) ③(n,m) ④(n,-m)
马经过跳p次①、q次②、r次③、s次④后
水平方向的位移为(p+q)*m+(r+s)*n 竖直方向的位移为(p-q)*n+(r-s)*m
为了利用1*n马的结论,解不定方程(p+q)*m+(r+s)*n=1。
∵n,m互质。∴该方程一定有解(p0,q0,r0,s0)。
又∵m是偶数n是奇数。∴(p0+q0)是偶数,(r0+s0)是奇数。
∵(p0+q0)与(p0-q0)同奇偶,而(r0+s0)与(r0-s0)同奇偶。
∴(p0-q0)是偶数,(r0-s0)是奇数。
∴(p0-q0)*n+(r0-s0)*m是偶数。
也就是马通过一系列的跳动所得到的效果相当于1*len的马跳一步的效果(len=(p0-q0)*n+(r0-s0)*m)。根据前面的结论,1*len的马可以遍历整个棋盘,所以当n+m为奇数且n,m互质时,n*m的马可以遍历整个棋盘。算法的时间复杂度为W(1),空间需求为W(1)。
var
n,m,temp:longint;{ n,m为广义马的类型}
function gcd(a,b:longint):longint;{计算n和m的最大公约数}
begin
if b=0 then gcd←a
else gcd←gcd(b,a mod b);
end;{ gcd }
begin
readln(n,m); {读广义马的类型}
if(n+m)mod2=0 {若n+m偶数,则无解}
then writeln('ImPOSSIbLE')
else begin
if n
temp←n;n←m;
m←temp;
end;{then}
if gcd(n,m)=1{若n,m互质,则输出成功信息;否则输出失败信息}
then writeln('YES')
else writeln('ImPOSSIbLE');
end;{else}
end.{main}
Dr. Steven最近在研究一种叫作X数列的整数数列。X数列有两个独特的性质:它的首项是0,任意相邻两项的差是1或者-1。
Dr. Steven正在研究X数列的长度与它的各项之和之间的关系。你是他的一名学生,也参加了这个课题。为了研究的方便,他希望你能够编一个程序:从输入文件中读入X数列的长度、X数列中所有项的和,找一个满足要求的X数列,并把结果写到输出文件中。
输入:
输入文件Sum.in的第一行是一个整数n(1≤n≤10 000),表示X数列中的项数。第二行是一个整数S(|S| ≤ 50 000 000),表示X数列中所有项的和。
输出:
把找到的满足要求的X数列输出到文件Sum.out中,每一项占一行,第k项输出在第k行,共n行。如果不存在这样的X数列,则输出“nO”。
X数列的和(Sum of X-Sequence)
长度为n的X数列共有2n-1个,要全部枚举一遍是不现实的。所以,一定有更好的方法。这就需要我们对题目作进一步的研究。只要做适当的变换,其中的奥秘就会浮出水面。
我们假设存在这样的一个数列{ai}满足题目要求,讨论S应满足的条件。
令bi=ai+1-ai,则由题目知,bi=1或-1。且a1=0,a2=b1,a3=b1+b2,……,an=b1+b2+……+bn-1。所以S=a1+a2+…+an=0+b1+(b1+b2)+…+(b1+b2+…+bn-1)=(n-1)b1+(n-2)b2+…+2*bn-2+bn-1 (1)
易知|S| (n-1)+(n-2)+……+1=(n-1)*n/2。1+2+……+(n-1)=(n-1)*n/2 (2)
由(2)式-(1)式得:(n-1)*n/2-S=(n-1)*(1- b1)+(n-2)*(1- b2)+……+2*(1- bn-2)+(1- bn-1)
因为1-bk=0或2,所以上式右端为偶数。要使等式成立,则其左端也为偶数,即S与(n-1)*n/2同奇偶。
再把等式两边同除以2,令ci=(1-bi)/2(易知ci=0或1),得[(n-1)*n/2-S]/2=(n-1) c1+(n-2) c2+……+ 2*cn-2+ cn-1
令T=[(n-1)*n/2-S]/2
所以原问题转化为一个简单的数学问题:T能否表示成1,2,……,(n-1)中若干个不重复的数之和。
这个问题不难解决。当0 T (n-1)*n/2时,T能够表示成1,2,……,(n-1)中若干个不重复的数之和。问题转化的必要性是显然的。接着用数学归纳法来证明它的充分性。证:
(1)当n=1时,0 T 0,0=0。
当n=2时,0 T 1,0=0,1=1。
当n=3时,0 T 3,0=0,1=1,2=2,3=1+2。
均成立。
(2)当n=k(k 3)时,归纳假设成立。则当n=k+1时:
①若0 T
由此可证,对于满足0 T k*(k+1)/2的T,一定能够表示成1,2,……,k中若干个不重复的数之和。即n=k+1时,归纳假设亦成立。证毕。
由上面的分析证明过程可以得出,T的取值范围是[0, (n-1)*n/2],且T为整数。S的取值范围是[-(n-1)*n/2, (n-1)*n/2],且S为整数,S与(n-1)*n/2同奇偶。有了这个基础,我们便可以将原问题对应一个简单问题:
首先判断S是否在[-(n-1)*n/2, (n-1)*n/2]的范围内,且S是否与(n-1)*n/2同奇偶。如果这两个条件不成立,则所求的数列不存在。如果满足这两个条件,则令T=[(n-1)*n/2-S]/2,然后就按照上文中证明里的方法求ci,而ai=ai-1+bi-1= ai-1+1-2*ci-1,所以ai 的值也就迎刃而解了
var
a,i,n,s,t:longint;{n为数列的项数;s为各项的和;a为数列中的一项}
begin
readln(n);{输入x数列的项数和所有项的和}
readln(s);
t←n*(n-1) div 2;
if odd(s-t) or(abs(s)>t){ 判断S是否在[-(n-1)*n/2, (n-1)*n/2]的范围内,且S是否与(n-1)*n/2同奇偶}
then writeln('nO')
else begin
t←(t-s)div2;{令T=[(n-1)*n/2-S]/2}
a←0;{首项为0}
writeln(a);
for i←n-1 downto 1 do begin {逐项计算}
if t>=i {c=1,即aj=aj-1-1}
then begin
dec(t,i);dec(a)
end{then}
else inc(a);{c=0,即aj=aj-1+1}
writeln(a) {输出数列中的一项}
end;{for}
end;{else}
end.{main}
2、统计分析法:
我们在一时得不到事物的特征机理的情况下,通过某种方法测试得到一些数据(即问题的部分解),再利用数理统计知识对数据进行处理,从而得到最终的数学模型
极值问题
m,n 为整数,且满足下列两个条件:
① m,n ∈1, 2, 3, ……,k (1≤k≤109);
② (n2-mn-m2)2=1。
由键盘输入k,求一组满足上述两个条件的m,n 并且使m2+n2的值最大。
K
2
3
4
8
16
32
64
N
2
3
3
8
13
21
55
M
1
2
2
5
8
13
34
如果我们的猜想正确,那么当(n,m)是方程(n2-mn-m2)2=1的一组解时,根据斐波拉契数列关系,(n+m,n)也一定是方程的一组解。
若((n+m)2-(m+n)n-n2)2=1成立,则
=>(n2+(m+n)n-(n+m)2)2=1=>(n2+mn+n2-n2-2mn-m2)2=1=>(n2-mn-m2)2=1成立
以上各步可逆,所以当(n,m)是方程(n2-mn-m2)2=1的一组解时,(n+m,n)一定是方程的另一组解。
var m,n,next,k :longint;
begin
write('k= '); readln(k); {读入n和m的上限k}
if (k<1) or (k>1000000000) then halt; {如果k不在要求范围内,就终止}
m←1; n←1; next←m+n; {确定斐波拉契数列的头三项}
while next<=k do {顺推,求出m,n的最大值}
begin
m←n; n←next;next←m+n;
end;{while}
writeln('m= ',m); writeln('n= ',n); {输出可使m2+n2的值最大的m和n} end.{main}
取石子问题
有两堆石子,数量可能不同。有两个人轮流取。每次有两种不同的取法。一是在任意一堆中取走任意多的石子。二是在两堆中同时取走相同数量的石子。最后把石子全部取完的是胜者。现在给出初始的两堆石子的数目,现在如果轮到你来取,又假设双方都采取最好的策略,问最后你是胜者还是败者。
输入文件只有一行,其中包含两个非负整数a和b,表示两堆石子的数目。(a,b≤1,000,000,000)。
输出文件也只有一行,包含一个数字。如果最后你是胜者,则输出1。反之,则输出0。
输入示例:6 10
输出示例:0
1、分析失败的情况
测试结果有两种可能
①失败的情况:(1,2) (3,5) (4,7) (6,10) (8,13) (9,15) (11,18) (12,20) (14,23) (16,26) (17,28)(19,31) (21,34)…。
②胜利的情况:(1,1)(1,3)(1,4)…。 胜利的情况比失败的情况多得多。
在上述两种情况中,我们选择相对容易得出的失败情况展开分析,寻找规律;
① 从1开始的每一个数字,在这些数字对中都会出现一次且仅会出现一次;
②数对的差成等差数列1,2,3,4…;
③有些数对的数字排列来自斐波那契数列
④有些数对虽然不是标准斐波那契数列中的数字,但还是符合斐波那契数列的规则;
⑤如果数对(a,b)出现在其中,则(a+b,a+2b)也必然出现在数对中(相反的结论是不对的);
⑥数对中两个数之比都非常接近于=0.618,即著名的黄金分割数。
2 、判别a、b的输赢
由于从1开始的每一个自然数,按照斐波那契数列的规则不重复地出现在失败的数对中,因此,可以得出如下结论:
在失败的数对中如果一个数为x,则取(x*0.618)的小数部分k。
若数对按照递增顺序排列成(a,b),且满足a=,则确定(a,b)失败。由此得出算法:
readln(x,y);
if x>y then begin c←y;y←x;x←c;end; {按照递增顺序排列x和y}
if x=y div 1.618 then writeln(0) {若x和y接近黄金分割数,则失败;否则胜利}
else writeln(1);
复习内容
计算机的基础知识
学科知识(物理和数学知识、高精度运算、 表达式处理、进制转换)
PASCAL语言
数据结构(顺序存储结构的线性表、栈、队列、串、非线性结构—树和图)
归纳策略(递推法和递归法、贪心法)
开放性试题(用开放性的思维方式解题)
搜索策略( 枚举法、 回溯法、宽度优先搜索)
动态程序设计方法
参考资料
普及类参考书目基本体现了全国青少年信息学奥林匹克联赛的知识要求,并且涵盖了历年联赛的试题解析
书 名 出 版 社 作 者 出版日期
《计算机文化基础》 高等教育出版社 杨振山 龚沛曾 1999年
《计算机信息处理》 机械工业出版社 Stenven L.Mandell 著 尤晓东 杨小平 周靖 等译 1999年
《C常用算法程序集》 清华大学出版社 徐士良 1996年
《程序设计》 复旦大学出版社 吴伟国 王建德 2002年
《数据结构与算法分析》 南京师范大学出版社 王建德 2000年
《联赛模拟题及其解析》 中国青年出版社 王建德等 2003年
全国青少年信息学奥林匹克联赛试题解析 南京大学出版社 章维铣 2001年
祝同学们考出好成绩
谢谢!
同课章节目录