01第一章dna的结构与功能
图片预览




文档简介
(共66张PPT)
第一章 DNA的结构与功能
第一节 DNA的物理结构
一、 DNA的一级结构
四、 DNA的高级结构
三、 DNA构象的多样性
二、 DNA的二级结构
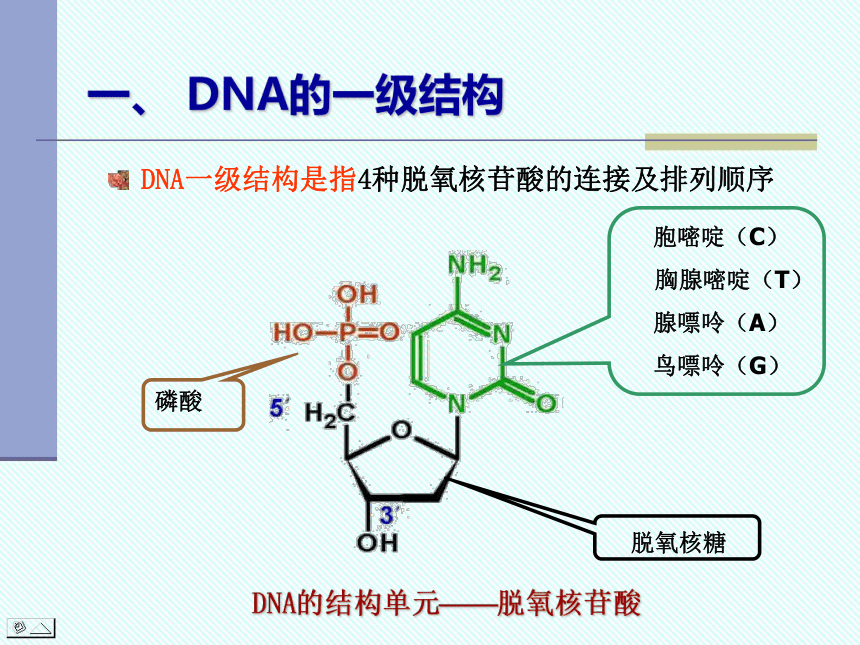
一、 DNA的一级结构
DNA一级结构是指4种脱氧核苷酸的连接及排列顺序
胞嘧啶(C)
胸腺嘧啶(T)
腺嘌呤(A)
鸟嘌呤(G)
磷酸
脱氧核糖
DNA的结构单元——脱氧核苷酸
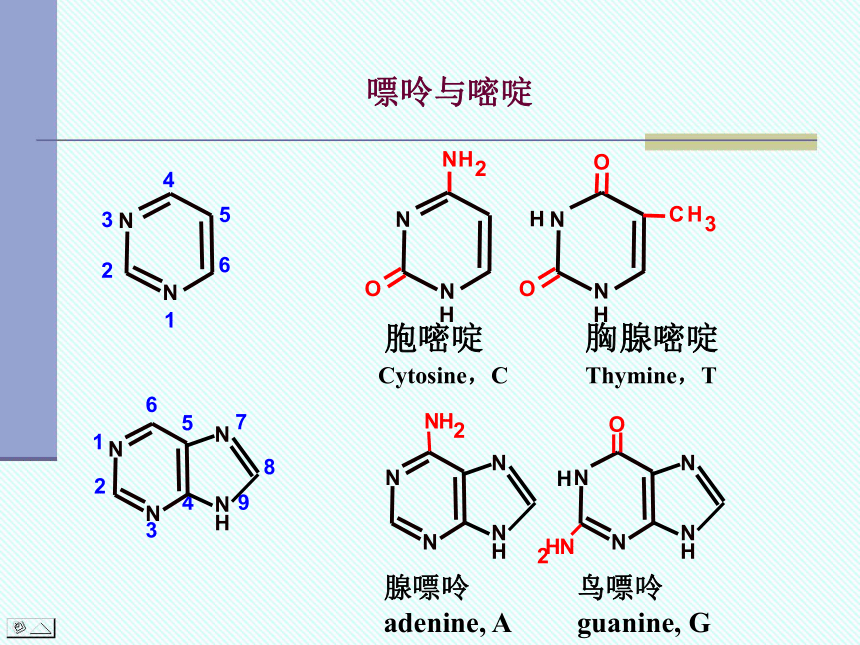
腺嘌呤adenine, A
鸟嘌呤guanine, G
3
1
2
4
5
6
7
8
9
N
N
N
N
H
N
H
2
N
N
N
N
H
N
N
N
N
H
N
H
2
O
H
胞嘧啶 胸腺嘧啶
Cytosine,C Thymine,T
3
1
2
4
5
6
N
N
N
N
O
H
N
H
2
N
N
O
O
H
H
C
H
3
嘌呤与嘧啶
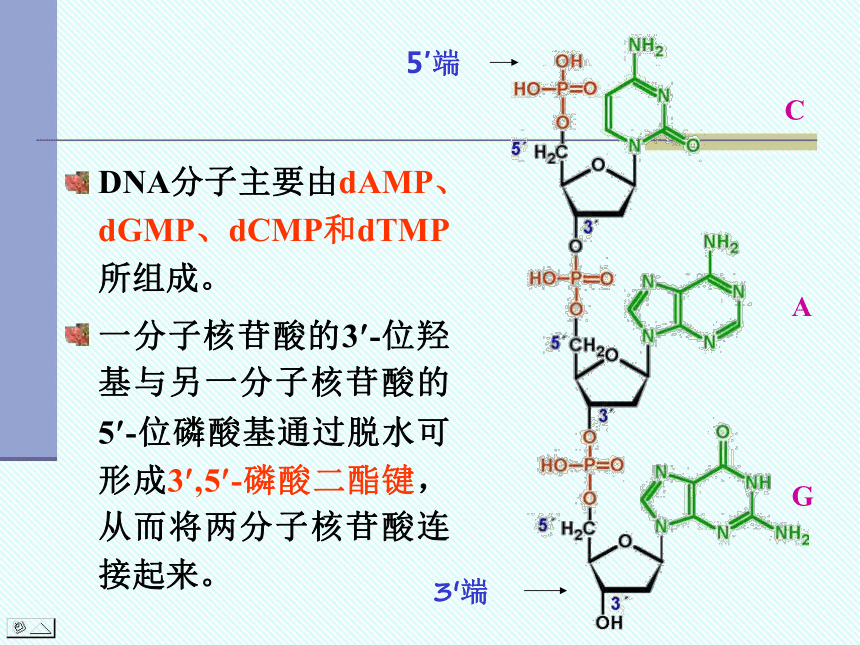
DNA分子主要由dAMP、dGMP、dCMP和dTMP所组成。
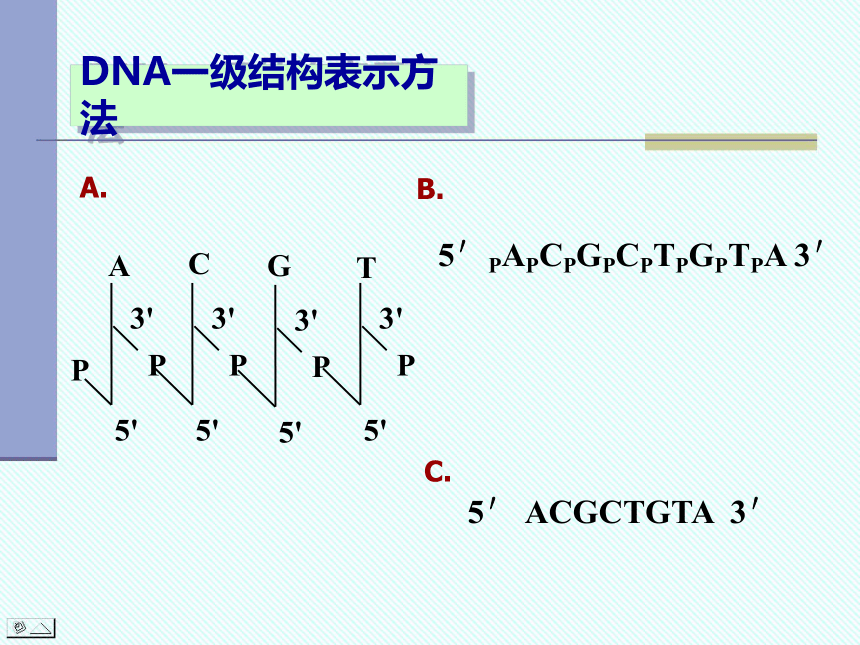
一分子核苷酸的3 -位羟基与另一分子核苷酸的5 -位磷酸基通过脱水可形成3 ,5 -磷酸二酯键,从而将两分子核苷酸连接起来。
5′端
3′端
C
G
A
5′PAPCPGPCPTPGPTPA 3′
P
P
5'
3'
3'
5'
P
P
5'
3'
P
5'
3'
A
C
G
T
5′ ACGCTGTA 3′
A.
B.
C.
DNA一级结构表示方法
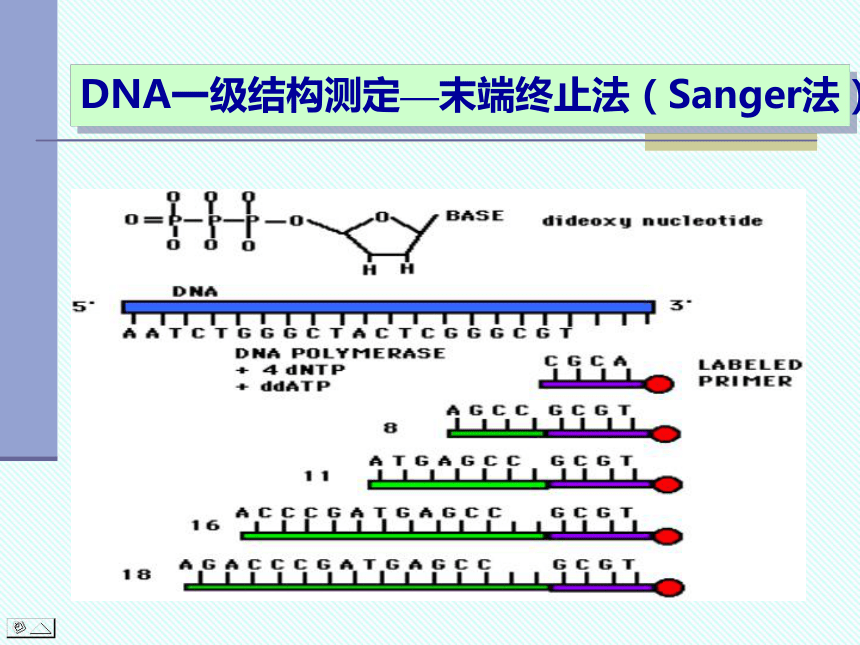
DNA一级结构测定—末端终止法(Sanger法)
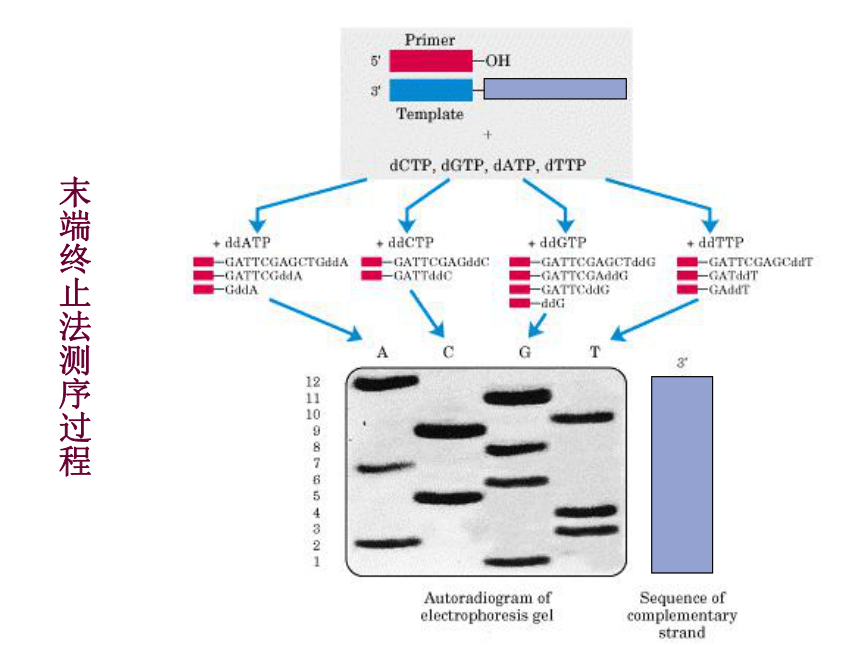
末端终止法测序过程
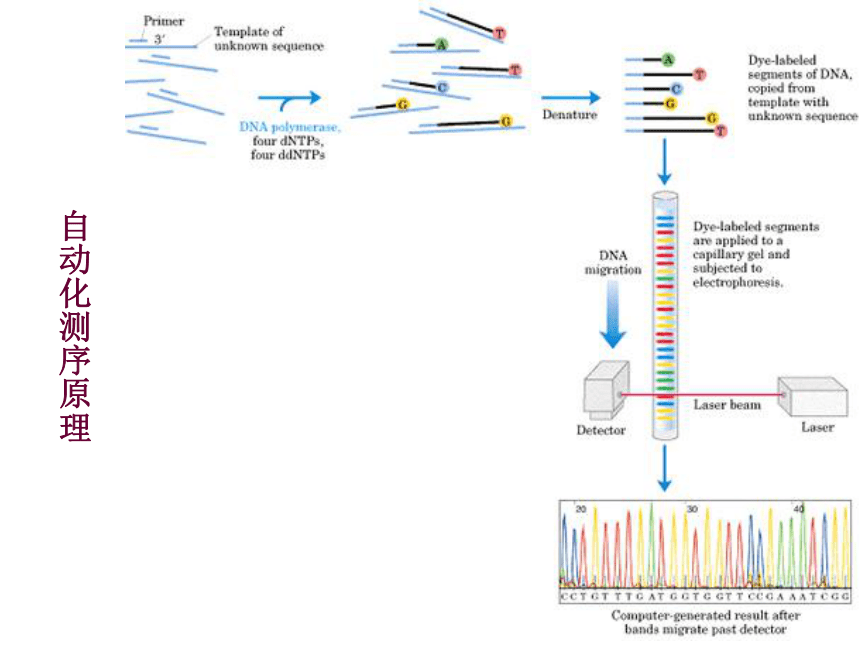
自动化测序原理
DNA分子的多样性
碱基的排列顺序,构成了DNA分子的多样性基础。
100 bp DNA分子可能排列方式就是4100 。
二、 DNA的二级结构——双螺旋模型
DNA双螺旋结构(double helix structure)是DNA二级结构的一种重要形式,它是Watson和Crick两位科学家于1953年提出来的一种结构模型。
Linus Pauling
(1901-1994)
Rosalind Franklin
(1920-1958)
Maurice Wilkins
(1916- )
与双螺旋模型相关的几位科学家
双螺旋模型的要点
1. 为右手反平行双螺旋;
2. 主链位于螺旋外侧,碱基位于内侧;
3. 两条链间存在碱基互补:A与T或G与C配对形成氢键,称为碱基互补原则(A与T为两个氢键,G与C为三个氢键);
4. 螺旋的稳定因素为氢键和碱基堆砌力;
5. 螺旋的螺距3.4nm,直径2nm,包含10个碱基对。
6. 螺旋表面形成两个凹槽——大沟与小沟
DNA双螺旋结构模式图
三、 DNA构象的多样性
经典的双螺旋模型是B-DNA双螺旋模型,也是在细胞体内最常见的DNA结构。
目前已知DNA双螺旋结构可分为A、B、C、D及Z型等数种,除Z型为左手双螺旋外,其余均为右手双螺旋。
B, A, Z型DNA结构模式图
Z-DNA
Z-DNA的发现: 1979年发现人工合成的DNA片段(CGCGCG)形成左手螺旋结构,即Z-DNA。
Z-DNA在转录调控有作用,并有可能造成基因突变。
它是双螺旋DNA分子中一条链的某一节段,通过链的折叠与同一分子中DNA结合而形成。
其中一条链只有嘌呤AG,另一条链只有嘧啶CT
H-DNA可在转录水平上阻止基因的转录,这就是反基因策略,或称反义核酸技术。
DNA的三股螺旋结构——H-DNA
三螺旋结构示意图
四、 DNA的高级结构——超螺旋
超螺旋结构
DNA双螺旋链再盘绕即形成超螺旋结构。
正超螺旋 盘绕方向与DNA双螺旋方同相同。
负超螺旋 盘绕方向与DNA双螺旋方向相反。
环状DNA分子常以超螺旋结构存在,并以负超螺旋为主。
DNA超螺旋结构
第二节 DNA的变性、复性与杂交
一、 DNA的变性
二、 DNA的复性
三、 分子杂交
在理化因素作用下,DNA双螺旋的两条互补链松散而分开成为单链,从而导致DNA的理化性质及生物学性质发生改变,称为DNA的变性(denaturation)。
常用的变性方法有热变性和碱变性等。
一、 DNA的变性
DNA的热变性称为DNA的“融解”,50% DNA分子解链的温度称为变性温度,用Tm表示。
Tm值受以下因素影响
DNA序列长度
(G+C)含量
环境因素(离子强度,pH值等)
Tm值及其影响因素
高盐
低盐
增色效应:指DNA变性后对260nm紫外光的光吸收度增加的现象;利用增色效应可以检测DNA变性程度,测定Tm值。
二、 DNA的复性
将热变性后的DNA溶液缓慢冷却,在低温条件下保温一段时间(退火),变性的两条单链DNA可以重新形成原来的双螺旋结构称为DNA的复性。
复性过程依赖于单链分子间的随机碰撞,特定环境下复性影响因素:单链DNA浓度与复杂度。
DNA的复性动力学
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATATATATATAT-5’
5‘-TATATATATATA-3’
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATATATATATAT-5’
5‘-TATATATATATA-3’
3’-ATATATATATAT-5’
5‘-TATATATATATA-3’
两条来源不同的单链核酸(DNA或RNA),只要它们有大致相同的互补碱基顺序,经退火处理即可复性,形成新的杂种双螺旋,这一现象称为核酸的分子杂交(hybridization)。
核酸杂交可以是DNA-DNA,也可以是DNA-RNA杂交。
三、 分子杂交
Southern杂交
利用DNA与DNA之间的杂交,确定或寻找不同样本中是否含有特定序列的DNA片段。
在核酸杂交分析过程中,常将已知顺序的核酸片段用放射性同位素进行标记。这种带有一定标记的已知顺序的核酸片段称为探针(Probe)。
琼脂糖凝胶电泳分离
转膜
限制性酶切
碱变性
杂交
显影
第三节 基因与基因组
一、 基因组与C值矛盾
二、DNA序列的不均一性
一、 基因组与C值矛盾
基因(gene) 是指表达一种蛋白质或功能RNA的基本单位。某种生物所包含的全套基因称为基因组(genome)。基因组的大小与生物的复杂性有关。
C值表示每一种生物中单倍体基因组的总量。
如 病毒SV40 5.1×103bp,
大肠杆菌 5.7×106bp,
人 3.2×109bp。
C值矛盾的含义:
C值和生物结构或组成的复杂性不一致
与预期的编码蛋白质的基因的数量相比,基因组的DNA含量过多
C值矛盾
有花植物
鸟类
哺乳类
爬行类
两栖类
有骨鱼类
软骨鱼类
棘皮类
甲壳类
昆虫
软体动物
蠕虫
霉菌
藻类
真菌
革兰氏阳性细菌
革兰氏阴性细菌
支原体
不同生物的基因组大小
各种生物体基因的数目比较
Bets
165
Mean
61,710
Lowest
27,462
Highest
153,478
Last Genesweep Votes Vote distribution
“基因轮盘赌”
病毒基因组
病毒基因组可以由DNA组成,也可以由RNA组成 。
基因组较小,不同病毒间差异较大,3500bp——500kb,编码5-300个基因。
采取多种策略扩大基因容量,尽可能以较少的核苷酸编码较多的蛋白质,如重叠基因。
采莲人在绿杨津
采莲人在绿杨津一阙新歌声漱玉
采莲人在绿杨津
在绿杨津一阙新
一阙新歌声漱玉
歌声漱玉采莲人
原核基因组
细菌基因组含有染色体和染色体外的DNA—质粒。
受同一个启动子调控,几个基因转录在同一条mRNA上,形成多顺反子mRNA
功能上相关的基因串联在一起组成操纵子结构
大部分是编码区,非编码区主要是调控基因表达的序列
真核基因组
断裂基因——基因内部存在内含子(Intron),将外显子(Exon)分割,内含子则存在广泛的序列变异
含有大量非编码序列,编码序列只占很小一部分
含有大量的重复序列
包括核基因组与细胞器基因组
二、 DNA序列的不均一性
高度重复序列
中度重复序列
非重复序列
基因家族
高度重复序列常称为卫星DNA,由较短的序列组成,次数可高达几百万次。
基因组DNA中的G :C碱基对的分布是不均一的,在CsCl等密度梯度超离心后,出现一个主峰和1~2个小峰。
高度重复序列
按照重复序列的长短将卫星DNA分成3类:
卫星DNA: 100 bp左右
小卫星DNA: 15~70 bp
微卫星DNA: 2~6 bp
不同个体DNA序列有所不同,即DNA序列多态性,表现为两类,一类为序列多态性,另一类为串联重复序列多态。两类多态性都可以作为区别个体的标记,即DNA分子标记。
可变数串联重复(Variable number tamdem repeat, VNTR) 由短重复单位(6-40bp)串联重复而成,不同个体重复次数是高度多态性的,可作为分子标记。
重复序列作为DNA分子标记的应用
为什么VNTR可用于个人识别?
小李 老刘 张三
2-3 3-3 2-4
烟头VNTR分析
序列系统 检材 嫌疑人1 嫌疑人2 嫌疑人3 嫌疑人4
TH01 7-9 7-9 7-9 6-9 7-9
VWA 14-17 15-17 14-17 15-19 14-18
FES 11-12 12-13 11-12 10-11 10-12
3个系统累积符合概率大于99%
此案件1997年在华西医科大学法医学系鉴定
VNTR用于亲子鉴定原理
父 子 母
2-3 3-4 2-4
亲子鉴定的D8S384分型
被控男 子 母 对照 母 子 被控男 对照
7-9 5-7 5-8 5-10 6-11 8-11 7 9
亲子鉴定实例
遗传标记 被控父亲 母亲 孩子 PI
TH01 9-10 9-10 9-10 1.8904
VWA 17-17 16-18 16-17 3.3113
FES 11-13 11-11 11-13 2.6882
D19S400 12-12 12-13 12-13 2.0263
D19S253 11-12 12-13 11-13 5.2521
D8S1179 13-18 14-15 15-18 12.6263
D21S1409 7-7 10-11 7-10 2.5157
D21S2055 17-20 18-26 17-18 4.2315
D5S818 7-9 8-10 8-9 2.3545
D7S820 6-10 7-7 6-7 3.3324
FGA 18-22 20-24 18-20 8.9278
累积父权指数=2684954.3717 相对父权概率 〉99.99%
重复次数在10~104 之间。 包括各种rRNA、tRNA等基因,Alu序列等。
序列的长度和拷贝数非常不均一
中度重复序列
真核生物的 Alu序列
转座子
功能
300bp
300bp
300bp
6000bp
6000bp
6000bp
6000bp
DR
DR
IR
IR
AGCT
Alu site
A copy of Alu family
也称单拷贝序列,包括大多数编码蛋白质的结构基因和基因间间隔序列
非重复序列
基因家族(Gene Family)是指一组功能相似且核苷酸序列具有同源性的基因,由某一共同祖先基因经扩增和突变产生。
基因家族
基因家族的成员往往串联排列在一起,形成基因簇(Gene Cluster) ,如rRNA、tRNA和组蛋白的基因,也有些基因家族的成员位于不同的染色体上,如珠蛋白基因。
基因家族中有些成员不产生有功能的基因产物,这种基因称为假基因(Pseudogene),往往用Ψ X表示。
第四节 染色体
一、 原核染色体
二、 真核染色体
原核染色体
原核染色体结构比较简单,近年来研究发现,也有DNA与蛋白质共同组成。如大肠杆菌,其染色体由支架与约100个DNA环构成。
真核染色体包括DNA,组蛋白,非组蛋白及少量RNA。基本单元:双螺旋的DNA分子围绕一蛋白质八聚体进行盘绕,从而形成特殊的串珠状结构,称为核小体(nucleosome)。
真核染色体
核小体模型
核小体由5种组蛋白构成(H1,H2A,H2B,H3,H4),组蛋白的序列高度保守,带有正电荷。
H2A,H2B,H3,H4各2个分子生成八聚体,位于核心,DNA盘绕在核心上,1分子的H1在核心外,起稳定核小体结构作用。
每个核小体单元约含200bp的DNA,其中146 bpDNA缠绕在组蛋白核心上。
核小体的结构
核小体、染色质与染色体
本章要点
DNA的一级结构,二级结构
DNA序列的测定方法(末端终止法)
DNA是遗传物质的实验证据
DNA变性,复性和分子杂交的概念,Tm值的含义
Southern杂交的基本原理
基因组与C值的概念,C值矛盾的含义
重复序列、卫星DNA的概念及应用
基因家族的概念
核小体模型
第一章 DNA的结构与功能
第一节 DNA的物理结构
一、 DNA的一级结构
四、 DNA的高级结构
三、 DNA构象的多样性
二、 DNA的二级结构
一、 DNA的一级结构
DNA一级结构是指4种脱氧核苷酸的连接及排列顺序
胞嘧啶(C)
胸腺嘧啶(T)
腺嘌呤(A)
鸟嘌呤(G)
磷酸
脱氧核糖
DNA的结构单元——脱氧核苷酸
腺嘌呤adenine, A
鸟嘌呤guanine, G
3
1
2
4
5
6
7
8
9
N
N
N
N
H
N
H
2
N
N
N
N
H
N
N
N
N
H
N
H
2
O
H
胞嘧啶 胸腺嘧啶
Cytosine,C Thymine,T
3
1
2
4
5
6
N
N
N
N
O
H
N
H
2
N
N
O
O
H
H
C
H
3
嘌呤与嘧啶
DNA分子主要由dAMP、dGMP、dCMP和dTMP所组成。
一分子核苷酸的3 -位羟基与另一分子核苷酸的5 -位磷酸基通过脱水可形成3 ,5 -磷酸二酯键,从而将两分子核苷酸连接起来。
5′端
3′端
C
G
A
5′PAPCPGPCPTPGPTPA 3′
P
P
5'
3'
3'
5'
P
P
5'
3'
P
5'
3'
A
C
G
T
5′ ACGCTGTA 3′
A.
B.
C.
DNA一级结构表示方法
DNA一级结构测定—末端终止法(Sanger法)
末端终止法测序过程
自动化测序原理
DNA分子的多样性
碱基的排列顺序,构成了DNA分子的多样性基础。
100 bp DNA分子可能排列方式就是4100 。
二、 DNA的二级结构——双螺旋模型
DNA双螺旋结构(double helix structure)是DNA二级结构的一种重要形式,它是Watson和Crick两位科学家于1953年提出来的一种结构模型。
Linus Pauling
(1901-1994)
Rosalind Franklin
(1920-1958)
Maurice Wilkins
(1916- )
与双螺旋模型相关的几位科学家
双螺旋模型的要点
1. 为右手反平行双螺旋;
2. 主链位于螺旋外侧,碱基位于内侧;
3. 两条链间存在碱基互补:A与T或G与C配对形成氢键,称为碱基互补原则(A与T为两个氢键,G与C为三个氢键);
4. 螺旋的稳定因素为氢键和碱基堆砌力;
5. 螺旋的螺距3.4nm,直径2nm,包含10个碱基对。
6. 螺旋表面形成两个凹槽——大沟与小沟
DNA双螺旋结构模式图
三、 DNA构象的多样性
经典的双螺旋模型是B-DNA双螺旋模型,也是在细胞体内最常见的DNA结构。
目前已知DNA双螺旋结构可分为A、B、C、D及Z型等数种,除Z型为左手双螺旋外,其余均为右手双螺旋。
B, A, Z型DNA结构模式图
Z-DNA
Z-DNA的发现: 1979年发现人工合成的DNA片段(CGCGCG)形成左手螺旋结构,即Z-DNA。
Z-DNA在转录调控有作用,并有可能造成基因突变。
它是双螺旋DNA分子中一条链的某一节段,通过链的折叠与同一分子中DNA结合而形成。
其中一条链只有嘌呤AG,另一条链只有嘧啶CT
H-DNA可在转录水平上阻止基因的转录,这就是反基因策略,或称反义核酸技术。
DNA的三股螺旋结构——H-DNA
三螺旋结构示意图
四、 DNA的高级结构——超螺旋
超螺旋结构
DNA双螺旋链再盘绕即形成超螺旋结构。
正超螺旋 盘绕方向与DNA双螺旋方同相同。
负超螺旋 盘绕方向与DNA双螺旋方向相反。
环状DNA分子常以超螺旋结构存在,并以负超螺旋为主。
DNA超螺旋结构
第二节 DNA的变性、复性与杂交
一、 DNA的变性
二、 DNA的复性
三、 分子杂交
在理化因素作用下,DNA双螺旋的两条互补链松散而分开成为单链,从而导致DNA的理化性质及生物学性质发生改变,称为DNA的变性(denaturation)。
常用的变性方法有热变性和碱变性等。
一、 DNA的变性
DNA的热变性称为DNA的“融解”,50% DNA分子解链的温度称为变性温度,用Tm表示。
Tm值受以下因素影响
DNA序列长度
(G+C)含量
环境因素(离子强度,pH值等)
Tm值及其影响因素
高盐
低盐
增色效应:指DNA变性后对260nm紫外光的光吸收度增加的现象;利用增色效应可以检测DNA变性程度,测定Tm值。
二、 DNA的复性
将热变性后的DNA溶液缓慢冷却,在低温条件下保温一段时间(退火),变性的两条单链DNA可以重新形成原来的双螺旋结构称为DNA的复性。
复性过程依赖于单链分子间的随机碰撞,特定环境下复性影响因素:单链DNA浓度与复杂度。
DNA的复性动力学
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATATATATATAT-5’
5‘-TATATATATATA-3’
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATCTATGCTGTCAT-5’
5‘-TAGATACGACAGTA-3’
3’-ATATATATATAT-5’
5‘-TATATATATATA-3’
3’-ATATATATATAT-5’
5‘-TATATATATATA-3’
两条来源不同的单链核酸(DNA或RNA),只要它们有大致相同的互补碱基顺序,经退火处理即可复性,形成新的杂种双螺旋,这一现象称为核酸的分子杂交(hybridization)。
核酸杂交可以是DNA-DNA,也可以是DNA-RNA杂交。
三、 分子杂交
Southern杂交
利用DNA与DNA之间的杂交,确定或寻找不同样本中是否含有特定序列的DNA片段。
在核酸杂交分析过程中,常将已知顺序的核酸片段用放射性同位素进行标记。这种带有一定标记的已知顺序的核酸片段称为探针(Probe)。
琼脂糖凝胶电泳分离
转膜
限制性酶切
碱变性
杂交
显影
第三节 基因与基因组
一、 基因组与C值矛盾
二、DNA序列的不均一性
一、 基因组与C值矛盾
基因(gene) 是指表达一种蛋白质或功能RNA的基本单位。某种生物所包含的全套基因称为基因组(genome)。基因组的大小与生物的复杂性有关。
C值表示每一种生物中单倍体基因组的总量。
如 病毒SV40 5.1×103bp,
大肠杆菌 5.7×106bp,
人 3.2×109bp。
C值矛盾的含义:
C值和生物结构或组成的复杂性不一致
与预期的编码蛋白质的基因的数量相比,基因组的DNA含量过多
C值矛盾
有花植物
鸟类
哺乳类
爬行类
两栖类
有骨鱼类
软骨鱼类
棘皮类
甲壳类
昆虫
软体动物
蠕虫
霉菌
藻类
真菌
革兰氏阳性细菌
革兰氏阴性细菌
支原体
不同生物的基因组大小
各种生物体基因的数目比较
Bets
165
Mean
61,710
Lowest
27,462
Highest
153,478
Last Genesweep Votes Vote distribution
“基因轮盘赌”
病毒基因组
病毒基因组可以由DNA组成,也可以由RNA组成 。
基因组较小,不同病毒间差异较大,3500bp——500kb,编码5-300个基因。
采取多种策略扩大基因容量,尽可能以较少的核苷酸编码较多的蛋白质,如重叠基因。
采莲人在绿杨津
采莲人在绿杨津一阙新歌声漱玉
采莲人在绿杨津
在绿杨津一阙新
一阙新歌声漱玉
歌声漱玉采莲人
原核基因组
细菌基因组含有染色体和染色体外的DNA—质粒。
受同一个启动子调控,几个基因转录在同一条mRNA上,形成多顺反子mRNA
功能上相关的基因串联在一起组成操纵子结构
大部分是编码区,非编码区主要是调控基因表达的序列
真核基因组
断裂基因——基因内部存在内含子(Intron),将外显子(Exon)分割,内含子则存在广泛的序列变异
含有大量非编码序列,编码序列只占很小一部分
含有大量的重复序列
包括核基因组与细胞器基因组
二、 DNA序列的不均一性
高度重复序列
中度重复序列
非重复序列
基因家族
高度重复序列常称为卫星DNA,由较短的序列组成,次数可高达几百万次。
基因组DNA中的G :C碱基对的分布是不均一的,在CsCl等密度梯度超离心后,出现一个主峰和1~2个小峰。
高度重复序列
按照重复序列的长短将卫星DNA分成3类:
卫星DNA: 100 bp左右
小卫星DNA: 15~70 bp
微卫星DNA: 2~6 bp
不同个体DNA序列有所不同,即DNA序列多态性,表现为两类,一类为序列多态性,另一类为串联重复序列多态。两类多态性都可以作为区别个体的标记,即DNA分子标记。
可变数串联重复(Variable number tamdem repeat, VNTR) 由短重复单位(6-40bp)串联重复而成,不同个体重复次数是高度多态性的,可作为分子标记。
重复序列作为DNA分子标记的应用
为什么VNTR可用于个人识别?
小李 老刘 张三
2-3 3-3 2-4
烟头VNTR分析
序列系统 检材 嫌疑人1 嫌疑人2 嫌疑人3 嫌疑人4
TH01 7-9 7-9 7-9 6-9 7-9
VWA 14-17 15-17 14-17 15-19 14-18
FES 11-12 12-13 11-12 10-11 10-12
3个系统累积符合概率大于99%
此案件1997年在华西医科大学法医学系鉴定
VNTR用于亲子鉴定原理
父 子 母
2-3 3-4 2-4
亲子鉴定的D8S384分型
被控男 子 母 对照 母 子 被控男 对照
7-9 5-7 5-8 5-10 6-11 8-11 7 9
亲子鉴定实例
遗传标记 被控父亲 母亲 孩子 PI
TH01 9-10 9-10 9-10 1.8904
VWA 17-17 16-18 16-17 3.3113
FES 11-13 11-11 11-13 2.6882
D19S400 12-12 12-13 12-13 2.0263
D19S253 11-12 12-13 11-13 5.2521
D8S1179 13-18 14-15 15-18 12.6263
D21S1409 7-7 10-11 7-10 2.5157
D21S2055 17-20 18-26 17-18 4.2315
D5S818 7-9 8-10 8-9 2.3545
D7S820 6-10 7-7 6-7 3.3324
FGA 18-22 20-24 18-20 8.9278
累积父权指数=2684954.3717 相对父权概率 〉99.99%
重复次数在10~104 之间。 包括各种rRNA、tRNA等基因,Alu序列等。
序列的长度和拷贝数非常不均一
中度重复序列
真核生物的 Alu序列
转座子
功能
300bp
300bp
300bp
6000bp
6000bp
6000bp
6000bp
DR
DR
IR
IR
AGCT
Alu site
A copy of Alu family
也称单拷贝序列,包括大多数编码蛋白质的结构基因和基因间间隔序列
非重复序列
基因家族(Gene Family)是指一组功能相似且核苷酸序列具有同源性的基因,由某一共同祖先基因经扩增和突变产生。
基因家族
基因家族的成员往往串联排列在一起,形成基因簇(Gene Cluster) ,如rRNA、tRNA和组蛋白的基因,也有些基因家族的成员位于不同的染色体上,如珠蛋白基因。
基因家族中有些成员不产生有功能的基因产物,这种基因称为假基因(Pseudogene),往往用Ψ X表示。
第四节 染色体
一、 原核染色体
二、 真核染色体
原核染色体
原核染色体结构比较简单,近年来研究发现,也有DNA与蛋白质共同组成。如大肠杆菌,其染色体由支架与约100个DNA环构成。
真核染色体包括DNA,组蛋白,非组蛋白及少量RNA。基本单元:双螺旋的DNA分子围绕一蛋白质八聚体进行盘绕,从而形成特殊的串珠状结构,称为核小体(nucleosome)。
真核染色体
核小体模型
核小体由5种组蛋白构成(H1,H2A,H2B,H3,H4),组蛋白的序列高度保守,带有正电荷。
H2A,H2B,H3,H4各2个分子生成八聚体,位于核心,DNA盘绕在核心上,1分子的H1在核心外,起稳定核小体结构作用。
每个核小体单元约含200bp的DNA,其中146 bpDNA缠绕在组蛋白核心上。
核小体的结构
核小体、染色质与染色体
本章要点
DNA的一级结构,二级结构
DNA序列的测定方法(末端终止法)
DNA是遗传物质的实验证据
DNA变性,复性和分子杂交的概念,Tm值的含义
Southern杂交的基本原理
基因组与C值的概念,C值矛盾的含义
重复序列、卫星DNA的概念及应用
基因家族的概念
核小体模型