人教中图版(2019)高中信息技术第二章算法与程序综合应用 (第二十课时)-课件(53ppt)
文档属性
| 名称 | 人教中图版(2019)高中信息技术第二章算法与程序综合应用 (第二十课时)-课件(53ppt) |

|
|
| 格式 | pptx | ||
| 文件大小 | 17.7MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 中图版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2021-02-04 00:00:00 | ||
图片预览






文档简介
算法与程序综合应用2(第二十课时)
引 入
编程解决问题
文本数据
数值数据
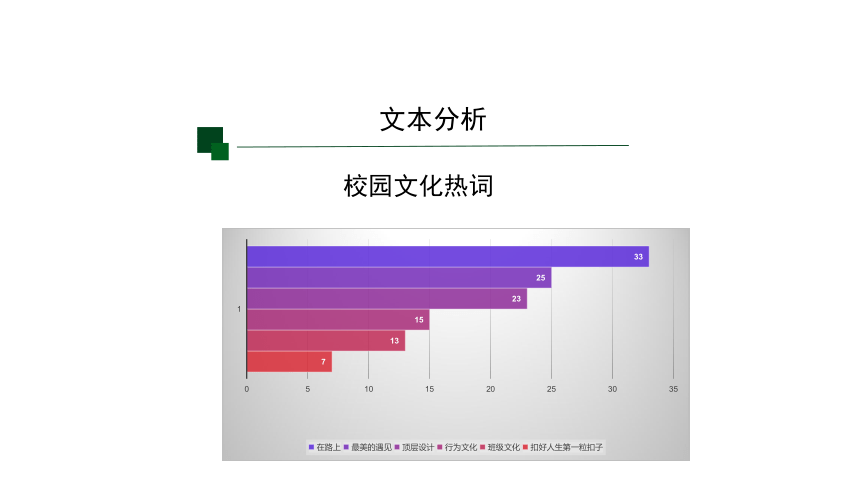
文本分析
校园文化热词
文本分析
《老人与海》词云图
文本分析
某地区上半年舆情领域分布
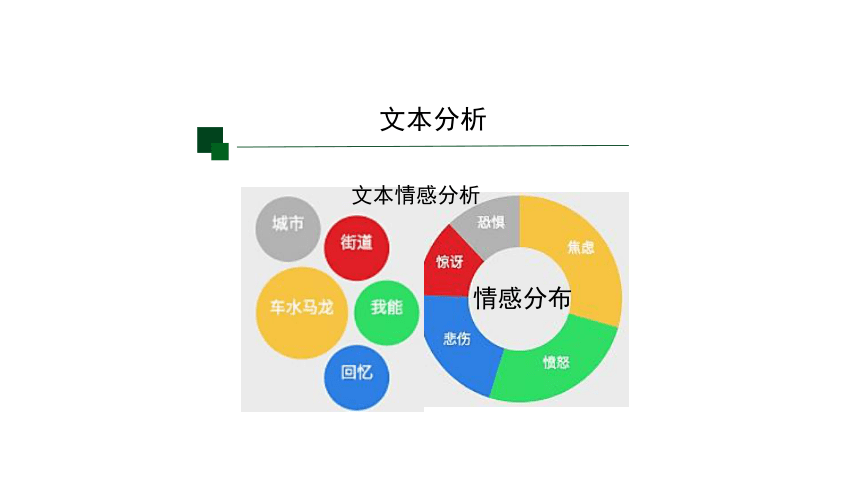
文本分析
情感分布
文本情感分析
问题呈现
学校开展经典诵读活动,小明在阅读《三国演义》时,为了分析该文学作品内容及其写作特色,想把小说中出现次数最多的20个词查找出来。如何通过编写程序来实现呢?
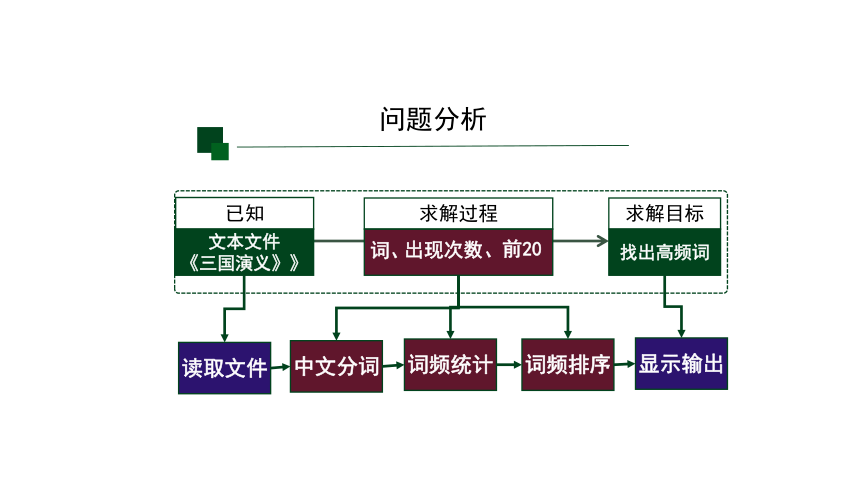
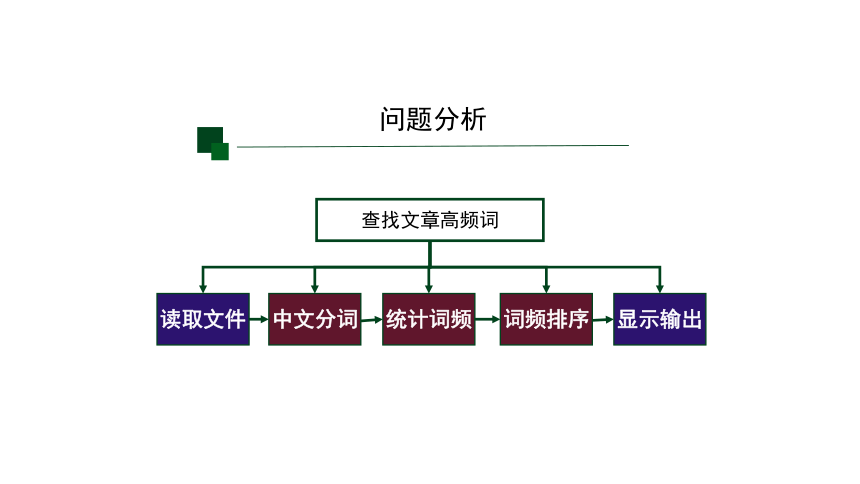
问题分析
文本文件
《三国演义》》
已知
找出高频词
求解目标
求解过程
读取文件
中文分词
词频统计
词频排序
显示输出
词、
出现次数、
前20
问题分析
读取文件
中文分词
统计词频
词频排序
显示输出
查找文章高频词
1.读取文件
中文分词
词频统计
词频排序
读取文件
显示输出
1.读取文件
实践活动一:读取文本数据
阅读任务单活动一的学习材料;
输入并尝试理解相关语句。
1.读取文件
f = open(“d:/三国演义.txt", "r", encoding='utf-8')
txt = f.read()
#读取文件内容
#打开指定文件,创建返回一个文件对象
1.读取文件
问题:运行代码,看不到效果。有什么办法可以观察和了解程序的进展呢?
1.读取文件
调试方法:
函数print() / print(type())
输出变量值或变量类型,观察程序的进展。
1.读取文件
f = open(" d:/三国演义.txt", "r", encoding='utf-8')
txt = f.read()
试一试:下面代码执行后的结果。
print(txt)
print(type(txt))
1.读取文件
1.读取文件
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
2.中文分词
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
2.中文分词
中文分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
如:小明是一名学生。
小明 是 一名 学生 。.
2.中文分词
.jieba模块,对中文有着很强大的分词能力。
由于它是第三方模块,使用前需要下载安装。
2.中文分词
实践活动二:
请同学们参照任务单中说明完成jieba模块的安装。
自学中文分词相关内容。
2.中文分词
.import jieba
. words=jieba.lcut(txt)
#导入jieba模块
#将txt中的中文拆分为词语保存到words中
2.中文分词
。import jieba
。f = open("d:/三国演义.txt", "r", encoding='utf-8')
。txt = f.read()
。words=jieba.lcut(txt)
2.中文分词
试一试:
利用前面用到的调试方法,观察程序的进展。
2.中文分词
2.中文分词
中文分词
词频统计
词频排序
读取文件
显示输出
3.词频统计
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
3.词频统计
解析算法:表达式
枚举算法:
逐一判断
实践活动三:如何统计词语的出现次数呢?
3.词频统计
如何利用枚举算法来统计词频呢?
提示:高频词应该是具有明确指向意义的词语,不包括单字的词。
3.词频统计
统计表中添加该词,次数为1
统计开始
False
统计结束
True
是
单字词
False
True
False
True
统计表中已有该词
统计表中
该词次数+1
3.词频统计
依序从词表中取一词
3.词频统计
想一想:如何记录词语内容及其出现次数呢?
(假设词频为:汉朝15次,建宁6次,英雄60次)
{5940675A-B579-460E-94D1-54222C63F5DA}?汉朝
?建宁
?英雄
?……
……?
{5940675A-B579-460E-94D1-54222C63F5DA}?15
?6
?60
?……
?……
方案1
A[0]
A[1]
A[2]
A[3]
B[0]
B[1]
B[2]
B[3]
{5940675A-B579-460E-94D1-54222C63F5DA}?汉朝
?15
?建宁
?6
?……
方案2
A[0]
A[1]
A[2]
A[3]
这种记录方式,一旦词语顺序发生调整和变化,容易出现次数对应上的错误。
3.词频统计
{ }
:
6
:
新的数据类型——字典
'香蕉'
5
字典是无序集合。
,
,
'苹果'
:
'山楂'
2
键值对(key-value)
字典中键与值是一一对应的,数据没有先后顺序关系。
3.词频统计
活动:
参考任务单活动三的材料,学习字典的相关内容。
尝试编写相关代码,实现词频统计。
3.词频统计
counts = {}
#建立空字典,用于存储词和出现次数
#单字的词语忽略不计
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
3.词频统计
试一试:
利用前面用到的调试方法,观察程序的进展。
3.词频统计
3.词频统计
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
.枚举、字典
4.词频排序
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
.枚举、字典
4.词频排序
实践活动四:如何实现按词频排序?
思考问题1:词频存储在字典中。字典中的元素能否进行排序呢?
思考问题2:如何实现按词语的出现次数进行排序?
参看任务单的学习材料。动手尝试编程实现。
4.词频排序
items = list(counts.items())
#字典转化为列表
items.sort( )
#按出现次数进行降序排列
降序
按出现次数排序
reverse = True
key = lambda x:x[1],
4.词频排序
试一试:
运行调试程序,观察程序进展。
4.词频排序
4.词频排序
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut( )
.字典、枚举
list ( )
sort ( )
5.显示输出
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
.字典、枚举
list ( )
sort ( )
5.显示输出
实践:请同学们思考并自行完成显示输出功能。
5.显示输出
#输出前20个元素的值
for i in range(20):
print (items[i][0], items[i][1])
5.显示输出
查找文章高频词
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
.字典、枚举
list ( )
sort ( )
循环结构
小明的收获
曹操 595
孔明 534
将军 508
却说 446
玄德 396
丞相 323
关公 320
二人 307
荆州 297
玄德曰 275
不可 272
不能 262
如此 252
孔明曰 247
张飞 228
主公 223
商议 217
刘备 196
引兵 190
军士 184
拓 展
《三国演义》作品核心人物
拓 展
蜀国主要人物在全书活动分布情况
5.显示输出
课后练习
1.请同学们修改程序,实现如下功能:查找出场次数最多的5个人物。
2.尝试着分析其它作品如《乡土中国》《老人与海》,说一说你的发现。
引 入
编程解决问题
文本数据
数值数据
文本分析
校园文化热词
文本分析
《老人与海》词云图
文本分析
某地区上半年舆情领域分布
文本分析
情感分布
文本情感分析
问题呈现
学校开展经典诵读活动,小明在阅读《三国演义》时,为了分析该文学作品内容及其写作特色,想把小说中出现次数最多的20个词查找出来。如何通过编写程序来实现呢?
问题分析
文本文件
《三国演义》》
已知
找出高频词
求解目标
求解过程
读取文件
中文分词
词频统计
词频排序
显示输出
词、
出现次数、
前20
问题分析
读取文件
中文分词
统计词频
词频排序
显示输出
查找文章高频词
1.读取文件
中文分词
词频统计
词频排序
读取文件
显示输出
1.读取文件
实践活动一:读取文本数据
阅读任务单活动一的学习材料;
输入并尝试理解相关语句。
1.读取文件
f = open(“d:/三国演义.txt", "r", encoding='utf-8')
txt = f.read()
#读取文件内容
#打开指定文件,创建返回一个文件对象
1.读取文件
问题:运行代码,看不到效果。有什么办法可以观察和了解程序的进展呢?
1.读取文件
调试方法:
函数print() / print(type())
输出变量值或变量类型,观察程序的进展。
1.读取文件
f = open(" d:/三国演义.txt", "r", encoding='utf-8')
txt = f.read()
试一试:下面代码执行后的结果。
print(txt)
print(type(txt))
1.读取文件
1.读取文件
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
2.中文分词
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
2.中文分词
中文分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
如:小明是一名学生。
小明 是 一名 学生 。.
2.中文分词
.jieba模块,对中文有着很强大的分词能力。
由于它是第三方模块,使用前需要下载安装。
2.中文分词
实践活动二:
请同学们参照任务单中说明完成jieba模块的安装。
自学中文分词相关内容。
2.中文分词
.import jieba
. words=jieba.lcut(txt)
#导入jieba模块
#将txt中的中文拆分为词语保存到words中
2.中文分词
。import jieba
。f = open("d:/三国演义.txt", "r", encoding='utf-8')
。txt = f.read()
。words=jieba.lcut(txt)
2.中文分词
试一试:
利用前面用到的调试方法,观察程序的进展。
2.中文分词
2.中文分词
中文分词
词频统计
词频排序
读取文件
显示输出
3.词频统计
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
3.词频统计
解析算法:表达式
枚举算法:
逐一判断
实践活动三:如何统计词语的出现次数呢?
3.词频统计
如何利用枚举算法来统计词频呢?
提示:高频词应该是具有明确指向意义的词语,不包括单字的词。
3.词频统计
统计表中添加该词,次数为1
统计开始
False
统计结束
True
是
单字词
False
True
False
True
统计表中已有该词
统计表中
该词次数+1
3.词频统计
依序从词表中取一词
3.词频统计
想一想:如何记录词语内容及其出现次数呢?
(假设词频为:汉朝15次,建宁6次,英雄60次)
{5940675A-B579-460E-94D1-54222C63F5DA}?汉朝
?建宁
?英雄
?……
……?
{5940675A-B579-460E-94D1-54222C63F5DA}?15
?6
?60
?……
?……
方案1
A[0]
A[1]
A[2]
A[3]
B[0]
B[1]
B[2]
B[3]
{5940675A-B579-460E-94D1-54222C63F5DA}?汉朝
?15
?建宁
?6
?……
方案2
A[0]
A[1]
A[2]
A[3]
这种记录方式,一旦词语顺序发生调整和变化,容易出现次数对应上的错误。
3.词频统计
{ }
:
6
:
新的数据类型——字典
'香蕉'
5
字典是无序集合。
,
,
'苹果'
:
'山楂'
2
键值对(key-value)
字典中键与值是一一对应的,数据没有先后顺序关系。
3.词频统计
活动:
参考任务单活动三的材料,学习字典的相关内容。
尝试编写相关代码,实现词频统计。
3.词频统计
counts = {}
#建立空字典,用于存储词和出现次数
#单字的词语忽略不计
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
3.词频统计
试一试:
利用前面用到的调试方法,观察程序的进展。
3.词频统计
3.词频统计
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
.枚举、字典
4.词频排序
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
.枚举、字典
4.词频排序
实践活动四:如何实现按词频排序?
思考问题1:词频存储在字典中。字典中的元素能否进行排序呢?
思考问题2:如何实现按词语的出现次数进行排序?
参看任务单的学习材料。动手尝试编程实现。
4.词频排序
items = list(counts.items())
#字典转化为列表
items.sort( )
#按出现次数进行降序排列
降序
按出现次数排序
reverse = True
key = lambda x:x[1],
4.词频排序
试一试:
运行调试程序,观察程序进展。
4.词频排序
4.词频排序
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut( )
.字典、枚举
list ( )
sort ( )
5.显示输出
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
.字典、枚举
list ( )
sort ( )
5.显示输出
实践:请同学们思考并自行完成显示输出功能。
5.显示输出
#输出前20个元素的值
for i in range(20):
print (items[i][0], items[i][1])
5.显示输出
查找文章高频词
中文分词
词频统计
词频排序
读取文件
显示输出
open() read()
.jieba
lcut()
.字典、枚举
list ( )
sort ( )
循环结构
小明的收获
曹操 595
孔明 534
将军 508
却说 446
玄德 396
丞相 323
关公 320
二人 307
荆州 297
玄德曰 275
不可 272
不能 262
如此 252
孔明曰 247
张飞 228
主公 223
商议 217
刘备 196
引兵 190
军士 184
拓 展
《三国演义》作品核心人物
拓 展
蜀国主要人物在全书活动分布情况
5.显示输出
课后练习
1.请同学们修改程序,实现如下功能:查找出场次数最多的5个人物。
2.尝试着分析其它作品如《乡土中国》《老人与海》,说一说你的发现。
同课章节目录
- 第1章 认识数据与大数据
- 主题学习项目:体质数据促健康
- 1.1 数据、信息与知识
- 1.2 数字化与编码
- 1.3 数据科学与大数据
- 第2章 算法与程序实现
- 主题学习项目:编程控灯利出行
- 2.1 解决问题的一般过程和用计算机解决问题
- 2.2 算法的概念及描述
- 2.3 程序设计基本知识
- 2.4 常见算法的程序实现
- 第3章 数据处理与应用
- 主题学习项目:用水分析助决策
- 3.1 数据处理的一般过程
- 3.2 数据采集与整理
- 3.3 数据分析与可视化
- 3.4 数据分析报告与应用
- 第4章 走进智能时代
- 主题学习项目:智能交互益拓展
- 4.1 认识人工智能
- 4.2 利用智能工具解决问题
- 4.3 人工智能的应用与影响