8.1.2样本相关系数课件-2020-2021学年高二下学期数学人教A版(2019)选择性必修第三册(36张PPT)
文档属性
| 名称 | 8.1.2样本相关系数课件-2020-2021学年高二下学期数学人教A版(2019)选择性必修第三册(36张PPT) |  | |
| 格式 | pptx | ||
| 文件大小 | 9.4MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 人教A版(2019) | ||
| 科目 | 数学 | ||
| 更新时间 | 2021-08-02 10:30:18 | ||
图片预览









文档简介
8.1 成对数据的统计相关性
第八章 成对数据的统计分析
8.1.2 样本相关系数
学习目标:
1. 结合实例,了解样本相关系数的统计含义,了解样本相关系数与“标准化”处理后的成对数据两分量向量夹角的关系;
2. 结合实例,会通过相关系数比较多组成对数据的相关性.
教学重点:
求样本相关系数,通过样本相关系数判断或比较成对数据的相关性强弱.
教学难点:
求样本相关系数,理解样本相关系数的统计含义.
通过观察散点图中成对样本数据的分布规律,我们可以大致推断两个变量是否存在相关关系、是正相关还是负相关、是线性相关还是非线性相关等.散点图虽然直观,但无法确切地反映成对样本数据的相关程度,也就无法量化两个变量之间相关程度的大小.能否像引入平均值、方差等数字特征对单个变量数据进行分析那样,引入一个适当的“数字特征”,对成对样本数据的相关程度进行定量分析呢?
思考:
一、样本相关系数
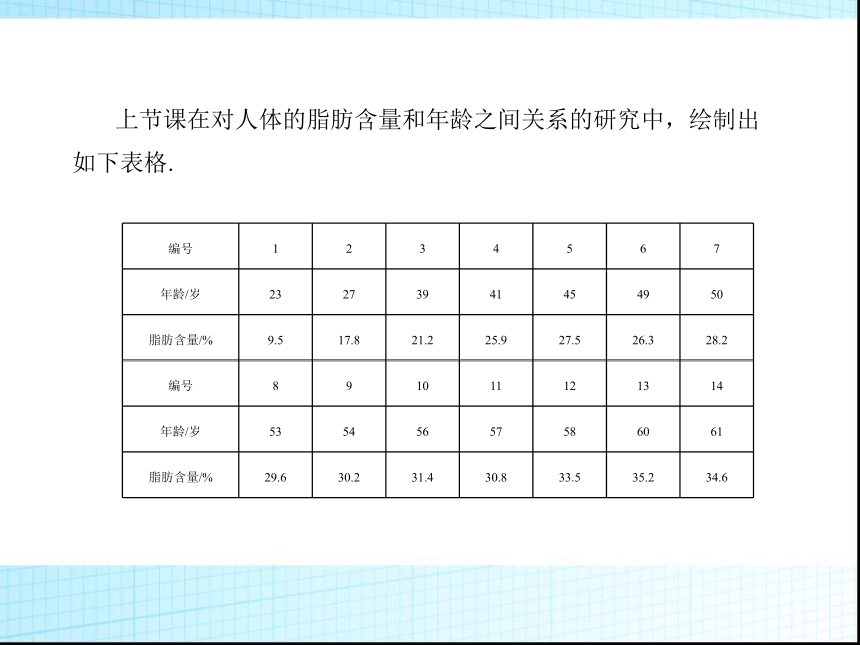
上节课在对人体的脂肪含量和年龄之间关系的研究中,绘制出如下表格.
编号
1
2
3
4
5
6
7
年龄/岁
23
27
39
41
45
49
50
脂肪含量/%
9.5
17.8
21.2
25.9
27.5
26.3
28.2
编号
8
9
10
11
12
13
14
年龄/岁
53
54
56
57
58
60
61
脂肪含量/%
29.6
30.2
31.4
30.8
33.5
35.2
34.6
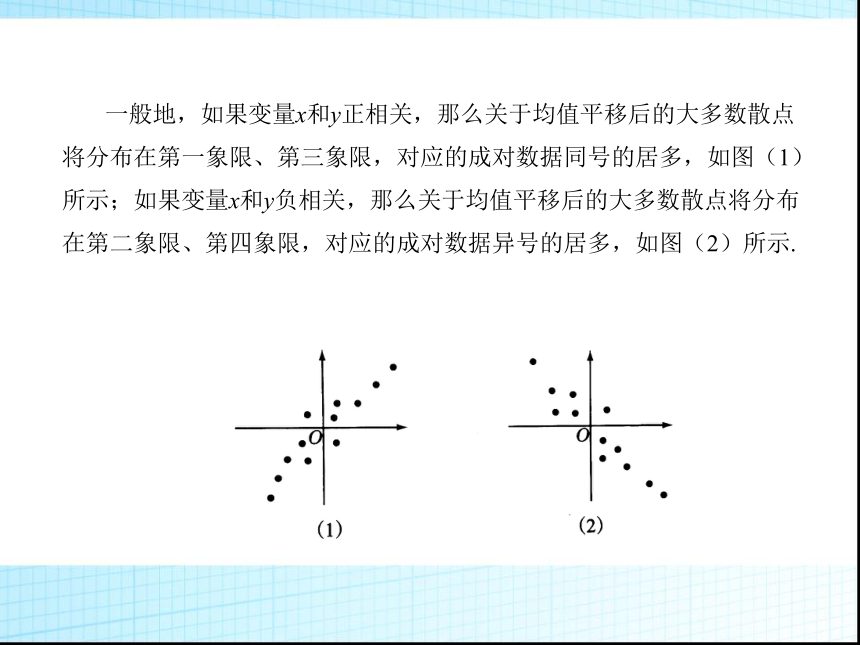
利用上述方法处理表中的数据,得到下图.这时的散点大多数分布在第一象限、第三象限,大多数散点的横、纵坐标同号.显然,这样的规律是由人体脂肪含量与年龄正相关所决定的.
一般地,如果变量x和y正相关,那么关于均值平移后的大多数散点将分布在第一象限、第三象限,对应的成对数据同号的居多,如图(1)所示;如果变量x和y负相关,那么关于均值平移后的大多数散点将分布在第二象限、第四象限,对应的成对数据异号的居多,如图(2)所示.
二、样本相关系数与正、负相关的关系
这样,我们利用成对样本数据构造了样本相关系数r.样本相关系数r是一个描述成对样本数据的数字特征,它的正负性和绝对值的大小可以反映成对样本数据的变化特征:
当????>????时,称成对样本数据正相关.这时,当其中一个数据的值变小时,另一个数据的值通常也变小;当其中一个数据的值变大时,另一个数据的值通常也变大.
当?????
三、样本相关系数与线性相关程度的关系
思考:样本相关系数r的大小与成对样本数据的相关程度有什么内在联系呢?
先考察一下r的取值范围.
四、用样本相关系数估计总体相关系数
不过,在实际中,获得总体中所有的成对数据往往是不容易的.因此,我们还是要用样本估计总体的思想来解决问题.也就是说,我们先要通过抽样获取两个变量的一些成对样本数据,再计算出样本相关系数,通过样本相关系数去估计总体相关系数,从而了解两个变量之间的相关程度.对于简单随机样本而言,样本具有随机性,因此样本相关系数r也具有随机性.一般地,样本容量越大,用样本相关系数估计两个变量的相关系数的效果越好.
例1 有人收集了某城市居民年收入(所有居民在一年内收入的总和)与A商品销售额的10年数据,如表所示.
第n年
1
2
3
4
5
6
7
8
9
10
居民年收入/亿元
32.2
31.1
32.9
35.8
37.1
38.0
39.0
43.0
44.6
46.0
A商品销售额/万元
25.0
30.0
34.0
37.0
39.0
41.0
42.0
44.0
48.0
51.0
画出散点图,推断成对样本数据是否线性相关,并通过样本相关系数推断居民年收入与A商品销售额的相关程度和变化趋势的异同.
练一练
D
练一练
练一练
C
练一练
3.若对甲、乙、丙3组不同的成对数据作线性相关性检验,得到这3组成对数据的样本相关系数依次为0.83,0.72,-0.90,则线性相关程度最强的组是________(填“甲”“乙”或“丙”)
练一练
丙
4.某公司为了准确地把握市场,做好产品生产计划,对过去四年的数据进行整理得到了第x年与年销量y(单位:万件)之间的关系如表:
练一练
x
1
2
3
4
y
12
28
42
56
在图中画出表中数据的散点图,推断两个变量是否线性相关,计算样本相关系数,并估计它们的相关程度.
练一练
练一练
练一练
课堂小结
——你学到了那些新知识呢?
样本相关系数的含义,通过相关系数比较多组成对数据的相关性.
第八章 成对数据的统计分析
8.1.2 样本相关系数
学习目标:
1. 结合实例,了解样本相关系数的统计含义,了解样本相关系数与“标准化”处理后的成对数据两分量向量夹角的关系;
2. 结合实例,会通过相关系数比较多组成对数据的相关性.
教学重点:
求样本相关系数,通过样本相关系数判断或比较成对数据的相关性强弱.
教学难点:
求样本相关系数,理解样本相关系数的统计含义.
通过观察散点图中成对样本数据的分布规律,我们可以大致推断两个变量是否存在相关关系、是正相关还是负相关、是线性相关还是非线性相关等.散点图虽然直观,但无法确切地反映成对样本数据的相关程度,也就无法量化两个变量之间相关程度的大小.能否像引入平均值、方差等数字特征对单个变量数据进行分析那样,引入一个适当的“数字特征”,对成对样本数据的相关程度进行定量分析呢?
思考:
一、样本相关系数
上节课在对人体的脂肪含量和年龄之间关系的研究中,绘制出如下表格.
编号
1
2
3
4
5
6
7
年龄/岁
23
27
39
41
45
49
50
脂肪含量/%
9.5
17.8
21.2
25.9
27.5
26.3
28.2
编号
8
9
10
11
12
13
14
年龄/岁
53
54
56
57
58
60
61
脂肪含量/%
29.6
30.2
31.4
30.8
33.5
35.2
34.6
利用上述方法处理表中的数据,得到下图.这时的散点大多数分布在第一象限、第三象限,大多数散点的横、纵坐标同号.显然,这样的规律是由人体脂肪含量与年龄正相关所决定的.
一般地,如果变量x和y正相关,那么关于均值平移后的大多数散点将分布在第一象限、第三象限,对应的成对数据同号的居多,如图(1)所示;如果变量x和y负相关,那么关于均值平移后的大多数散点将分布在第二象限、第四象限,对应的成对数据异号的居多,如图(2)所示.
二、样本相关系数与正、负相关的关系
这样,我们利用成对样本数据构造了样本相关系数r.样本相关系数r是一个描述成对样本数据的数字特征,它的正负性和绝对值的大小可以反映成对样本数据的变化特征:
当????>????时,称成对样本数据正相关.这时,当其中一个数据的值变小时,另一个数据的值通常也变小;当其中一个数据的值变大时,另一个数据的值通常也变大.
当?????
三、样本相关系数与线性相关程度的关系
思考:样本相关系数r的大小与成对样本数据的相关程度有什么内在联系呢?
先考察一下r的取值范围.
四、用样本相关系数估计总体相关系数
不过,在实际中,获得总体中所有的成对数据往往是不容易的.因此,我们还是要用样本估计总体的思想来解决问题.也就是说,我们先要通过抽样获取两个变量的一些成对样本数据,再计算出样本相关系数,通过样本相关系数去估计总体相关系数,从而了解两个变量之间的相关程度.对于简单随机样本而言,样本具有随机性,因此样本相关系数r也具有随机性.一般地,样本容量越大,用样本相关系数估计两个变量的相关系数的效果越好.
例1 有人收集了某城市居民年收入(所有居民在一年内收入的总和)与A商品销售额的10年数据,如表所示.
第n年
1
2
3
4
5
6
7
8
9
10
居民年收入/亿元
32.2
31.1
32.9
35.8
37.1
38.0
39.0
43.0
44.6
46.0
A商品销售额/万元
25.0
30.0
34.0
37.0
39.0
41.0
42.0
44.0
48.0
51.0
画出散点图,推断成对样本数据是否线性相关,并通过样本相关系数推断居民年收入与A商品销售额的相关程度和变化趋势的异同.
练一练
D
练一练
练一练
C
练一练
3.若对甲、乙、丙3组不同的成对数据作线性相关性检验,得到这3组成对数据的样本相关系数依次为0.83,0.72,-0.90,则线性相关程度最强的组是________(填“甲”“乙”或“丙”)
练一练
丙
4.某公司为了准确地把握市场,做好产品生产计划,对过去四年的数据进行整理得到了第x年与年销量y(单位:万件)之间的关系如表:
练一练
x
1
2
3
4
y
12
28
42
56
在图中画出表中数据的散点图,推断两个变量是否线性相关,计算样本相关系数,并估计它们的相关程度.
练一练
练一练
练一练
课堂小结
——你学到了那些新知识呢?
样本相关系数的含义,通过相关系数比较多组成对数据的相关性.