-2021-2022学年高中信息技术浙教版(2019)必修1 4.2.1 大数据处理的基本思想与框架 课件(20张PPT)
文档属性
| 名称 | -2021-2022学年高中信息技术浙教版(2019)必修1 4.2.1 大数据处理的基本思想与框架 课件(20张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 6.2MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2021-10-12 00:00:00 | ||
图片预览







文档简介
(共20张PPT)
4.2.1大数据处理的基本思想与框架
第四章
第四章
目录
分治思想
批处理
流计算
图计算
大数据具有数据量大、数据来源与类型多样、处理速度快等特点
分--将问题分解为规模更小的子问题
治--将规模更小的子问题逐个击破
合--将已解决的子问题合并,最终得出原问题的解
什么是分治思想?
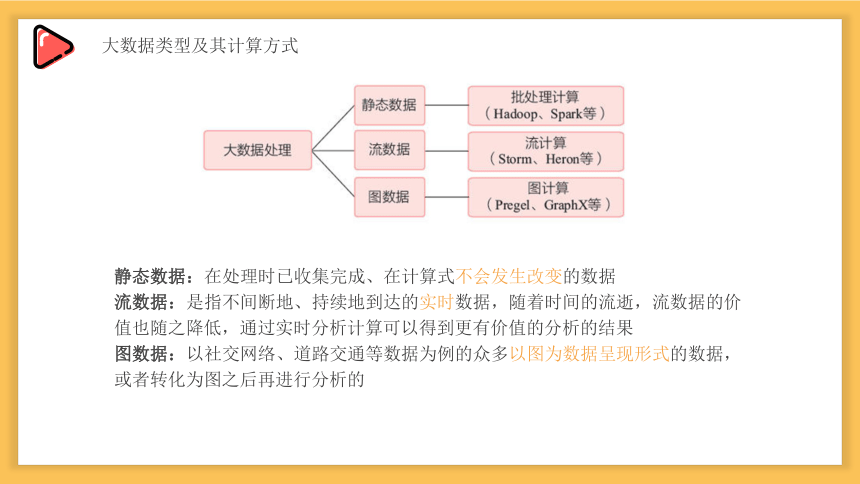
大数据类型及其计算方式
静态数据:在处理时已收集完成、在计算式不会发生改变的数据
流数据:是指不间断地、持续地到达的实时数据,随着时间的流逝,流数据的价值也随之降低,通过实时分析计算可以得到更有价值的分析的结果
图数据:以社交网络、道路交通等数据为例的众多以图为数据呈现形式的数据,或者转化为图之后再进行分析的
批处理计算
Hadoop进化史
最早起源于Nutch项目
Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页的抓取、索引、查询等功能
随着抓取网页的数量增加、遇到了严重的拓展性问题——如何解决数十亿网页的存储和索引问题
Google
2003年谷歌发表了两篇论文为该问题提供了解决方案
GFS:Google File System
MapReduce:并行式计算模型
BigTable:数据库
Doug Cutting
用了两年时间,将论文实现了出来
2008年Hadoop成为Apache的顶级项目
批处理计算
运用Hadoop企业一览
数据仓库,商业智能 (facebook,twitter,淘宝,京东,暴风,新浪,58同城....,移动大云)
互联网广告计算 (亿赞普,科捷,各类大互联网企业)
大搜索引擎项目 (Yahoo,国产盘古,人民搜索)
站内搜索引擎项目 (Ebay,支付宝)
内容推荐引擎 (人人,新浪微博,优酷)
病毒分析,垃圾邮件识别(Yahoo,趋势科技,360)
云计算服务项目 (亚马逊云,阿里云)
地图项目 (月球表面探测地图)
科研项目 (欧洲量子对撞机)
金融项目 (股票分析,阿里金融)
批处理计算
Hadoop是一个可运行与大规模计算机集群上的分布式系统架构,适用于静态数据的批处理计算。
Spark是一种与Hadoop相似的、应用较为广泛的开源分布式计算架构。Spark使用了内存存储中间结果,运行速度比Hadoop快很多。
批处理计算
HDFS
主要功能:将大规模海量数据以文件的形式、用多个副本保存在不同的存储结点上,并用分布式系统进行管理是GFS的开源实现
特点:容错性高,可以部署在廉价的机器中
应用:云盘、网盘
HBase
主要功能:基于列的存储方式,用来存储非结构化和半结构化的数据,有良好的横向扩展能力,可管理PB级的大数据, 是BigTable的开源实现
特点:高可靠、高性能、可伸缩、分布式
批处理计算
MapReduce
核心思想:将任务分解并发布到多个节点上进行处理,最后汇总输出
处理海量数据,(>1TB)
由Map(映射)和Reduce(归纳)组成
自动实现分布式并行计算
计算分配到大量机器上
Heron
Heron
流计算
近年来,在Web应用、网络监控、传感监测等领域,兴起了一种新的数据密集型应用——流数据,即数据以大量、快速、时变的流形式持续到达
流计算
流计算可以简单、高效、可靠地实现实时数据的获取、传输和存储。
主要流计算软件:
IBM InfoSphere Streams(捕获和分析动态数据)
Twitter Storm(推特风暴)
Yahoo!S4(雅虎分布式流计算)
淘宝
Facebook Puma
Heron
图计算
图计算:现实中的数据大多以图的形式呈现,或者转换为图以后再进行分析
图计算
社交网络数据转换成图结构
实时处理于批处理的整合
平台的整合缩短了批处理与流处理之间的切换延时时间,有利于减少系统的开销,降低使用成本。
练一练
A
1.下列关于流数据的描述不正确的是( )
A.数据在处理时已经采集完成
B.数据价值随着时间的流逝降低
C.实时分析流数据可以得到更有价值的结果
D.可以采用流计算进行实时分析
练一练
2.下列关于Hadoop架构的描述正确的是( )
A.是一个对大数据进行聚合式处理的基础软件框架
B.不能运行于大规模计算机集群上
C.采用NTFS文件系统管理数据文件
D.采用MapReduce编程模型处理大规模数据集
D
练一练
3.下列软件主要用于进行流计算的有( )
A.Hadoop
B.Storm
C.Pregel
D.Spark
B
练一练
4.实时处理与批处理整合的优势有( )
①可以在同一个平台做批处理计算和流计算
②缩短了批处理计算和流计算之间的切换延时
③有利于降低使用成本
④增加了系统开销
A.①②③
B.①②④
C.②③④
D.①③④
A
谢谢观看
第四章
第四章
4.2.1大数据处理的基本思想与框架
第四章
第四章
目录
分治思想
批处理
流计算
图计算
大数据具有数据量大、数据来源与类型多样、处理速度快等特点
分--将问题分解为规模更小的子问题
治--将规模更小的子问题逐个击破
合--将已解决的子问题合并,最终得出原问题的解
什么是分治思想?
大数据类型及其计算方式
静态数据:在处理时已收集完成、在计算式不会发生改变的数据
流数据:是指不间断地、持续地到达的实时数据,随着时间的流逝,流数据的价值也随之降低,通过实时分析计算可以得到更有价值的分析的结果
图数据:以社交网络、道路交通等数据为例的众多以图为数据呈现形式的数据,或者转化为图之后再进行分析的
批处理计算
Hadoop进化史
最早起源于Nutch项目
Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页的抓取、索引、查询等功能
随着抓取网页的数量增加、遇到了严重的拓展性问题——如何解决数十亿网页的存储和索引问题
2003年谷歌发表了两篇论文为该问题提供了解决方案
GFS:Google File System
MapReduce:并行式计算模型
BigTable:数据库
Doug Cutting
用了两年时间,将论文实现了出来
2008年Hadoop成为Apache的顶级项目
批处理计算
运用Hadoop企业一览
数据仓库,商业智能 (facebook,twitter,淘宝,京东,暴风,新浪,58同城....,移动大云)
互联网广告计算 (亿赞普,科捷,各类大互联网企业)
大搜索引擎项目 (Yahoo,国产盘古,人民搜索)
站内搜索引擎项目 (Ebay,支付宝)
内容推荐引擎 (人人,新浪微博,优酷)
病毒分析,垃圾邮件识别(Yahoo,趋势科技,360)
云计算服务项目 (亚马逊云,阿里云)
地图项目 (月球表面探测地图)
科研项目 (欧洲量子对撞机)
金融项目 (股票分析,阿里金融)
批处理计算
Hadoop是一个可运行与大规模计算机集群上的分布式系统架构,适用于静态数据的批处理计算。
Spark是一种与Hadoop相似的、应用较为广泛的开源分布式计算架构。Spark使用了内存存储中间结果,运行速度比Hadoop快很多。
批处理计算
HDFS
主要功能:将大规模海量数据以文件的形式、用多个副本保存在不同的存储结点上,并用分布式系统进行管理是GFS的开源实现
特点:容错性高,可以部署在廉价的机器中
应用:云盘、网盘
HBase
主要功能:基于列的存储方式,用来存储非结构化和半结构化的数据,有良好的横向扩展能力,可管理PB级的大数据, 是BigTable的开源实现
特点:高可靠、高性能、可伸缩、分布式
批处理计算
MapReduce
核心思想:将任务分解并发布到多个节点上进行处理,最后汇总输出
处理海量数据,(>1TB)
由Map(映射)和Reduce(归纳)组成
自动实现分布式并行计算
计算分配到大量机器上
Heron
Heron
流计算
近年来,在Web应用、网络监控、传感监测等领域,兴起了一种新的数据密集型应用——流数据,即数据以大量、快速、时变的流形式持续到达
流计算
流计算可以简单、高效、可靠地实现实时数据的获取、传输和存储。
主要流计算软件:
IBM InfoSphere Streams(捕获和分析动态数据)
Twitter Storm(推特风暴)
Yahoo!S4(雅虎分布式流计算)
淘宝
Facebook Puma
Heron
图计算
图计算:现实中的数据大多以图的形式呈现,或者转换为图以后再进行分析
图计算
社交网络数据转换成图结构
实时处理于批处理的整合
平台的整合缩短了批处理与流处理之间的切换延时时间,有利于减少系统的开销,降低使用成本。
练一练
A
1.下列关于流数据的描述不正确的是( )
A.数据在处理时已经采集完成
B.数据价值随着时间的流逝降低
C.实时分析流数据可以得到更有价值的结果
D.可以采用流计算进行实时分析
练一练
2.下列关于Hadoop架构的描述正确的是( )
A.是一个对大数据进行聚合式处理的基础软件框架
B.不能运行于大规模计算机集群上
C.采用NTFS文件系统管理数据文件
D.采用MapReduce编程模型处理大规模数据集
D
练一练
3.下列软件主要用于进行流计算的有( )
A.Hadoop
B.Storm
C.Pregel
D.Spark
B
练一练
4.实时处理与批处理整合的优势有( )
①可以在同一个平台做批处理计算和流计算
②缩短了批处理计算和流计算之间的切换延时
③有利于降低使用成本
④增加了系统开销
A.①②③
B.①②④
C.②③④
D.①③④
A
谢谢观看
第四章
第四章