4.2.2.1 Pandas 模块 第3课 DataFrame函数 课件-2021-2022学年高中信息技术浙教版(2019)必修1 (20张PPT)
文档属性
| 名称 | 4.2.2.1 Pandas 模块 第3课 DataFrame函数 课件-2021-2022学年高中信息技术浙教版(2019)必修1 (20张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 13.8MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2021-12-21 00:00:00 | ||
图片预览






文档简介
(共20张PPT)
1、pandas模块
4.2.2 编程处理数据
第3课 DataFrame-函数
一、学习目标:
1、学会用二维数据文件创建DataFrame对象。
2、学会用函数编辑DataFrame对象中的行和列。
3、学会用函数统计与计算DataFrame对象中的数据。
4、学会用函数排序DataFrame对象中的数据。
二、知识点:
1、用二维数据文件创建DataFrame对象。
2、DataFrame常用函数基本操作。
1、读取Excel文件创建DF对象。
常用语法:pd.read_excel(io,sheet_name=0,header=0)
参数说明:
io:字符串,文件对象(或包含路径);
sheet_name:指定导入的工作表,=字符串,或=整数,
默认值为0,即第1个工作表中的数据作为DF对象;
字符串表示工作表名称;整数为索引,表示工作表位置。
header:指定作为列名的行,默认值为0,即第一行的值为列名;
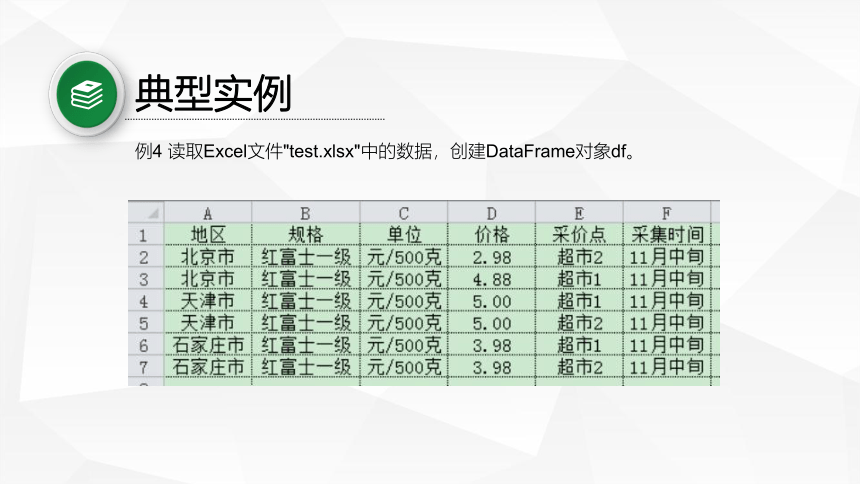
典型实例
例4 读取Excel文件"test.xlsx"中的数据,创建DataFrame对象df。
代码
import pandas as pd
#列名对齐
pd.set_option("display.unicode.east_asian_width",True)
df=pd.read_excel("test.xlsx")
print(df)
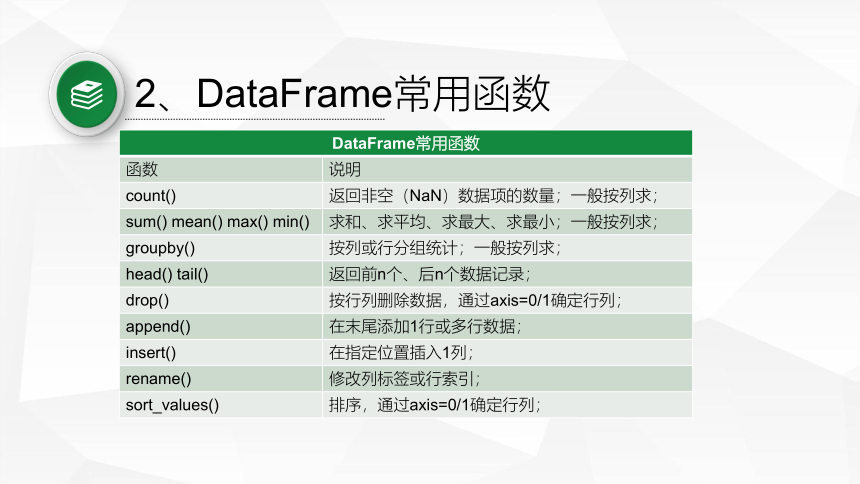
2、DataFrame常用函数
DataFrame常用函数 函数 说明
count() 返回非空(NaN)数据项的数量;一般按列求;
sum() mean() max() min() 求和、求平均、求最大、求最小;一般按列求;
groupby() 按列或行分组统计;一般按列求;
head() tail() 返回前n个、后n个数据记录;
drop() 按行列删除数据,通过axis=0/1确定行列;
append() 在末尾添加1行或多行数据;
insert() 在指定位置插入1列;
rename() 修改列标签或行索引;
sort_values() 排序,通过axis=0/1确定行列;
典型实例
例7 对df对象中的数据进行以下编辑:
在最后追加一行数据;
在“价格”后添加“库存量(千克)”数据列
删除“规格”列数据;
删除第1行数据;
修改第3行,第2列的值为“红富士三级”;
按行添加数据:append()函数
常用语法:append(data,ignore_index=True)
参数说明:data:表示需添加的数据,一般为字典;
ignore_index=True:忽略行索引,必选参数。
返回值:默认返回一个新的DF对象。
DF常用函数基本操作
#在最后添加1行数据
data1={"地区":"石家庄市","规格":"红富士一级",
"单位":"元/500克","价格":4.00,
"采价点":"集市3","采集时间":"11月中旬"}
df_add=df.append(data1,ignore_index=True)
print(df_add)
按列添加数据:insert()函数
常用语法:insert(i,columns,data)
参数说明:i:插入位置;
columns:列标签;
data:添加数据或数据列表。
DF常用函数基本操作
#在“价格”后添加“库存量(千克)”数据列
df.insert(4,"库存量(千克)",300)
print(df)
DF常用函数基本操作
按行列删除数据:drop()函数
常用语法:drop(labels,axis=0,inplace=False)
参数说明:labels:表示行索引或列标签;
axis:确定行列,默认值=0,按行删除;=1,按列删除;
inplace:可选参数,默认值=False,不改变原DF对象数据;
=True,改变原DF对象数据
返回值:默认返回一个新的DF对象。
DF常用函数基本操作
#删除“规格”列数据
df_delc=df.drop("规格",axis=1)
print(df_delc)
#删除第1行数据
df_delr=df.drop(0)
print(df_delr)
DF常用函数基本操作
按行索引和列标签修改单个值:at[ ]方法
常用语法:at[index,columns]=value
参数说明:index:行索引;
columns:列标签;
value:新值。
#修改第3行,第2列的值为“红富士三级”
df.at[2,"规格"]="红富士三级"
print(df)
典型实例
例8 将df对象中的数据按“地区”分组,并计算分组后各组数据的平均值。
DF常用函数基本操作
分组统计:groupby()函数
常用语法:groupby(labels,axis=0,as_index=True)
参数说明:labels:分组列标签;
axis:确定行列,默认值=0,按行分组;=1,按列分组;
as_index:分组后的行索引,默认值=True,以分组标签为索引;
=False,以行标签为索引,一般设置为False。
返回值:默认返回一个新的DF对象。
求平均值:mean()
#按“地区”分组,并计算分组后各组数据的平均值
g=df.groupby("地区",as_index=False).mean()
print(g)
典型实例
例9 对df对象中的数据,按“价格”值降序排序。
DF常用函数基本操作
按索引排序:sort_index()函数
按值排序:sort_values()函数
常用语法:sort_index(ascending=True)
sort_values(labels,axis=0,ascending=True)
参数说明:labels:排序列标签;
axis:确定行列,默认值=0,纵向排序;=1,横向排序;
ascending:确定升/降序,默认值=True,升序;=False,降序
返回值:默认返回一个新的DF对象。
DF常用函数基本操作
#按“价格”值降序排序
df_sort=df.sort_values("价格",ascending=False)
print(df_sort)
#按行索引值降序排序
df_sort_index=df.sort_index(ascending=False)
print(df_sort_index)
课堂练习:
“身边的百家姓”项目实践体验
1、pandas模块
4.2.2 编程处理数据
第3课 DataFrame-函数
一、学习目标:
1、学会用二维数据文件创建DataFrame对象。
2、学会用函数编辑DataFrame对象中的行和列。
3、学会用函数统计与计算DataFrame对象中的数据。
4、学会用函数排序DataFrame对象中的数据。
二、知识点:
1、用二维数据文件创建DataFrame对象。
2、DataFrame常用函数基本操作。
1、读取Excel文件创建DF对象。
常用语法:pd.read_excel(io,sheet_name=0,header=0)
参数说明:
io:字符串,文件对象(或包含路径);
sheet_name:指定导入的工作表,=字符串,或=整数,
默认值为0,即第1个工作表中的数据作为DF对象;
字符串表示工作表名称;整数为索引,表示工作表位置。
header:指定作为列名的行,默认值为0,即第一行的值为列名;
典型实例
例4 读取Excel文件"test.xlsx"中的数据,创建DataFrame对象df。
代码
import pandas as pd
#列名对齐
pd.set_option("display.unicode.east_asian_width",True)
df=pd.read_excel("test.xlsx")
print(df)
2、DataFrame常用函数
DataFrame常用函数 函数 说明
count() 返回非空(NaN)数据项的数量;一般按列求;
sum() mean() max() min() 求和、求平均、求最大、求最小;一般按列求;
groupby() 按列或行分组统计;一般按列求;
head() tail() 返回前n个、后n个数据记录;
drop() 按行列删除数据,通过axis=0/1确定行列;
append() 在末尾添加1行或多行数据;
insert() 在指定位置插入1列;
rename() 修改列标签或行索引;
sort_values() 排序,通过axis=0/1确定行列;
典型实例
例7 对df对象中的数据进行以下编辑:
在最后追加一行数据;
在“价格”后添加“库存量(千克)”数据列
删除“规格”列数据;
删除第1行数据;
修改第3行,第2列的值为“红富士三级”;
按行添加数据:append()函数
常用语法:append(data,ignore_index=True)
参数说明:data:表示需添加的数据,一般为字典;
ignore_index=True:忽略行索引,必选参数。
返回值:默认返回一个新的DF对象。
DF常用函数基本操作
#在最后添加1行数据
data1={"地区":"石家庄市","规格":"红富士一级",
"单位":"元/500克","价格":4.00,
"采价点":"集市3","采集时间":"11月中旬"}
df_add=df.append(data1,ignore_index=True)
print(df_add)
按列添加数据:insert()函数
常用语法:insert(i,columns,data)
参数说明:i:插入位置;
columns:列标签;
data:添加数据或数据列表。
DF常用函数基本操作
#在“价格”后添加“库存量(千克)”数据列
df.insert(4,"库存量(千克)",300)
print(df)
DF常用函数基本操作
按行列删除数据:drop()函数
常用语法:drop(labels,axis=0,inplace=False)
参数说明:labels:表示行索引或列标签;
axis:确定行列,默认值=0,按行删除;=1,按列删除;
inplace:可选参数,默认值=False,不改变原DF对象数据;
=True,改变原DF对象数据
返回值:默认返回一个新的DF对象。
DF常用函数基本操作
#删除“规格”列数据
df_delc=df.drop("规格",axis=1)
print(df_delc)
#删除第1行数据
df_delr=df.drop(0)
print(df_delr)
DF常用函数基本操作
按行索引和列标签修改单个值:at[ ]方法
常用语法:at[index,columns]=value
参数说明:index:行索引;
columns:列标签;
value:新值。
#修改第3行,第2列的值为“红富士三级”
df.at[2,"规格"]="红富士三级"
print(df)
典型实例
例8 将df对象中的数据按“地区”分组,并计算分组后各组数据的平均值。
DF常用函数基本操作
分组统计:groupby()函数
常用语法:groupby(labels,axis=0,as_index=True)
参数说明:labels:分组列标签;
axis:确定行列,默认值=0,按行分组;=1,按列分组;
as_index:分组后的行索引,默认值=True,以分组标签为索引;
=False,以行标签为索引,一般设置为False。
返回值:默认返回一个新的DF对象。
求平均值:mean()
#按“地区”分组,并计算分组后各组数据的平均值
g=df.groupby("地区",as_index=False).mean()
print(g)
典型实例
例9 对df对象中的数据,按“价格”值降序排序。
DF常用函数基本操作
按索引排序:sort_index()函数
按值排序:sort_values()函数
常用语法:sort_index(ascending=True)
sort_values(labels,axis=0,ascending=True)
参数说明:labels:排序列标签;
axis:确定行列,默认值=0,纵向排序;=1,横向排序;
ascending:确定升/降序,默认值=True,升序;=False,降序
返回值:默认返回一个新的DF对象。
DF常用函数基本操作
#按“价格”值降序排序
df_sort=df.sort_values("价格",ascending=False)
print(df_sort)
#按行索引值降序排序
df_sort_index=df.sort_index(ascending=False)
print(df_sort_index)
课堂练习:
“身边的百家姓”项目实践体验