4.2.2编程处理数据之1利用pandas模块处理数据——DataFrame对象课件2021—2022学年浙教版(2019)必修1数据与计算(31张PPT)
文档属性
| 名称 | 4.2.2编程处理数据之1利用pandas模块处理数据——DataFrame对象课件2021—2022学年浙教版(2019)必修1数据与计算(31张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 15.2MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2021-12-26 00:00:00 | ||
图片预览









文档简介
(共31张PPT)
处
程
编
理
4.2.2.1 利用pandas模块处理数据
数
据
DataFrame对象
录
目
01
创建DataFrame对象
02
DataFrame对象
查看DataFrame对象
03
修改DataFrame对象
04
添加DataFrame对象中行列数据
05
删除DataFrame对象中行列数据
06
DataFrame对象分组操作
07
DataFrame对象排序操作
08
DataFrame对象其他操作
09
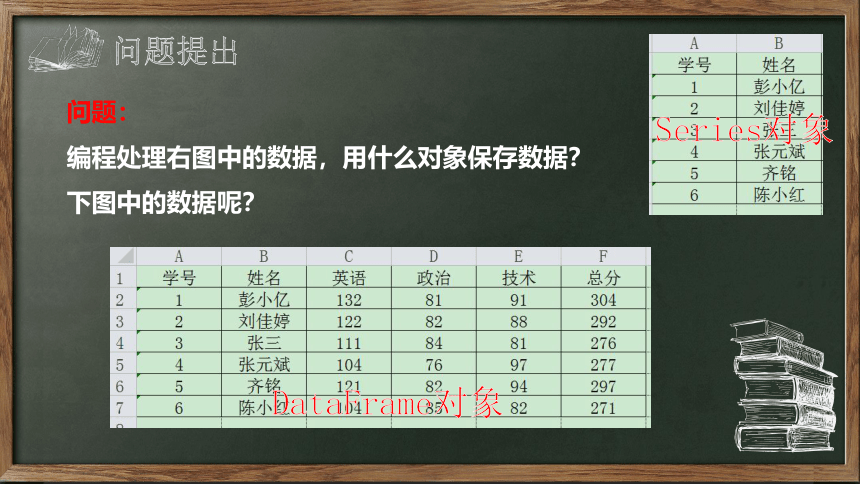
问题提出
问题:
编程处理右图中的数据,用什么对象保存数据?
下图中的数据呢?
DataFrame对象
Series对象
DataFrame是一种类似于关系表的表格型数据结构,DataFrame对象是一个二维表格,由1个索引列(index)和若干个数据列组成。其中,每列中的元素类型必须一致,而不同的列可以拥有不同的元素类型。
一、Pandas模块——DataFrame对象
列名:columns
二维数据:values
行索引:index,但DataFrame与excel不同,默认从0开始
数据结构 维度 组成部分 属性
Series 一维 由一个数组的数据(values)和一个与数据关联的索引(index) index、values
DataFrame
二维
由1个索引列(index)和若干个数据列组成
index、columns、values、T
一、Pandas模块——DataFrame对象
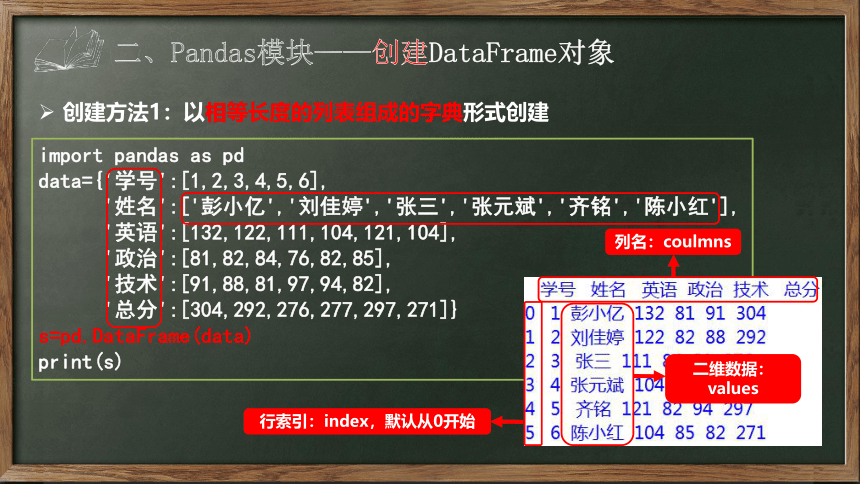
二、Pandas模块——创建DataFrame对象
创建方法1:以相等长度的列表组成的字典形式创建
import pandas as pd
data={'学号':[1,2,3,4,5,6],
'姓名':['彭小亿','刘佳婷','张三','张元斌','齐铭','陈小红'],
'英语':[132,122,111,104,121,104],
'政治':[81,82,84,76,82,85],
'技术':[91,88,81,97,94,82],
'总分':[304,292,276,277,297,271]}
s=pd.DataFrame(data)
print(s)
行索引:index,默认从0开始
列名:coulmns
二维数据:
values
import pandas as pd
data={'学号':[1,2,3,4,5,6],
'姓名':['彭小亿','刘佳婷','张三','张元斌','齐铭','陈小红'],
'英语':[132,122,111,104,121,104],
'政治':[81,82,84,76,82,85],
'技术':[91,88,81,97,94,82],
'总分':[304,292,276,277,297,271]}
s=pd.DataFrame(data,
index=['no1','no2','no3','no4','no5','no6'])
print(s)
二、Pandas模块——创建DataFrame对象
创建方法2:指定行索引
行索引:index
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df)
二、Pandas模块——创建DataFrame对象
创建方法3:从excel文件读入二维数据表,pd.read_excel()
★ to_excel() : 用dataframe创建excel
三、Pandas模块——查看DataFrame列数据
查看方法1:通过属性检索,查看列数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df.姓名)
查看方法2:通过字典检索,查看列数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df['姓名'] )
三、Pandas模块——查看DataFrame行数据
查看方法1:通过索引切片、dataFrame的head()函数和tail()函数,查看行数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df[2:5])
print('----------------------')
print(df.head(2))
print('----------------------')
print(df.tail(3))
print('----------------------')
三、Pandas模块——查看DataFrame行数据
查看方法2:通过索引切片查看指定行数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df[2:3])
三、Pandas模块——查看DataFrame行数据
查看方法3:布尔型数据选取满足条件的行
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df[df['英语']>110])
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df[df.英语>110])
三、Pandas模块——查看DataFrame一个数值
查看方法:at[ ]方法获取某行某列的值
对象名.at[行索引,"列标签"]
import pandas as pd
df=pd.read_excel('test.xlsx ')
print(df.at[2,'姓名'])
三、Pandas模块——查看DataFrame数据
查看方法1:循环查看行索引
import pandas as pd
df=pd.read_excel('test.xlsx')
for i in df.index:
print(i)
查看方法2:循环查看数据
import pandas as pd
df=pd.read_excel('test.xlsx')
for i in df.values:
print(i)
查看方法3:循环查看列标题
import pandas as pd
df=pd.read_excel('test.xlsx')
for i in df.columns:
print(i)
查看方法4:循环查看列标题
import pandas as pd
df=pd.read_excel('test.xlsx')
for i in df:
print(i)
三、Pandas模块——查看DataFrame数据
查看方法5:直接用关键字查看相关数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df.index)
print('-----------------------')
print(df.values)
print('-----------------------')
print(df.columns)
print('-----------------------')
print(df)
print('-----------------------')
四、Pandas模块——修改DataFrame列数据
修改方法1:通过属性或字典检索修改列数据
import pandas as pd
df=pd.read_excel('test.xlsx ')
df.姓名=['a','b','c','d','e','f']
print(df)
import pandas as pd
df=pd.read_excel('test.xlsx ')
Df['姓名']=['a','b','c','d','e','f']
print(df)
四、Pandas模块——修改DataFrame行数据
修改方法1:通过索引切片修改行数据
import pandas as pd
df=pd.read_excel('test.xlsx ')
df[2:3]=[3,'李华',34,23,234,45]
print(df)
四、Pandas模块——修改DataFrame某个数据
修改方法1:通过at[]方法修改单个数据
import pandas as pd
df=pd.read_excel('test.xlsx ')
df.at[3,'技术']=98
print(df)
四、Pandas模块——修改DataFrame数据
修改方法1:转置
import pandas as pd
df=pd.read_excel('test.xlsx ')
print(df.T)
五、Pandas模块——DataFrame添加行数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df)
df.append({'学号':7,'姓名':'梁国辉','英语':148,
'政治':92,'技术':97,'总分':337},ignore_index=True)
print(df)
添加数据错误: append()函数添加行数据
append()函数不改变原有df对象中的数据
五、Pandas模块——DataFrame添加行数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df)
df1=df.append({'学号':7,'姓名':'梁国辉','英语':148,
'政治':92,'技术':97,'总分':337},ignore_index=True)
print(df1)
添加数据正确:append()函数添加行数据
索引默认往上加,
添加在最后一行。
五、Pandas模块——DataFrame添加列数据
import pandas as pd
df=pd.read_excel('test.xlsx ')
df.insert(3,"性别",['男','女','男','男','男','女',])
print(df)
添加数据正确:insert(i,columns,data)添加列数据
i:插入位置
columns:列标签
data:添加数据或数据列表
六、Pandas模块——DataFrame删除数据函数
删除数据:drop()函数删除行数据或列数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df)
df2=df.drop(0)
print(df2)
df3=df.drop('学号',axis=1)
print(df3)
drop()函数不改变原有df对象中的数据
axis=0表示删除行;axis=0表示删除列
del df[‘学号’] 会永久删除df对象学号列数据
df2=df.drop(0 ',axis=0)
七、Pandas模块——DataFrame数据分组函数
import pandas as pd
df=pd.read_excel('test1.xlsx')
df1=df.groupby('性别',as_index=False)
print(df1)
print(df1.mean())
数据分组:groupby()函数分组数据
groupby(labels,axis=0,as_index=True)
mean()求平均值
df1=df.groupby('性别',as_index=False).mean()
八、Pandas模块——DataFrame数据排序
import pandas as pd
df=pd.read_excel('test1.xlsx')
df1=df.sort_values('总分',ascending=True)
print(df1)
数据排序:sort_values()函数排列数据
ascendng=True:升序排序ascendng=False:降序排序
import pandas as pd
df=pd.read_excel('test1.xlsx')
df.sort_values('总分',ascending=True,inplace=True)
print(df1)
九、Pandas模块——DataFrame其他函数
import pandas as pd
df=pd.read_excel('test1.xlsx')
print(df.姓名.count())
print("---------------")
print(df['总分'].max())
print("---------------")
print(round(df['技术'].mean(),2))
十、Pandas模块——处理数据的DataFrame常用函数
DataFrame常用函数 函数 说明
count() 返回非空(NaN)数据项的数量;一般按列求;
sum() mean() max() min() 求和、求平均、求最大、求最小;一般按列求;
groupby() 按列或行分组统计;一般按列求;
head() tail() 返回前n个、后n个数据记录;
drop() 按行列删除数据,通过axis=0/1确定行列;
append() 在末尾添加1行或多行数据;
insert() 在指定位置插入1列;
rename() 修改列标签或行索引;
sort_values() 排序,通过axis=0/1确定行列;
describe() 返回各列的基本描述统计值,包含计数、平均值、标准差、最大值、最小值、4分位差
concat()/plot() 合并DataFrame对象/绘图
某班级计划在某商店购买秋季运动会的奖品,奖品数据如下:
商品名称 商品价格(元) 购买数量
笔记簿 15 25
铅笔 2 50
橡皮 5 30
三角尺 6.5 10
圆规 9 10
课堂练习1
请你用pandas的DataFrame数据结构,存储以上表格数据。
1.创建一个名为jpdata的变量,用于存储以上表格数据默认行索引,
列标签为:“商品名称”,“商品价格(元)”,“购买数量”,“购买金额”(的初值为0)。
2.请分别计算每种商品的购买金额并存储到“购买金额”数据列中。
1. 读取’a.xlsx’表格数据到pandas模块DataFrame对象的代码:
2. 查看“价格”列数据,可以用哪两种方法?
方法一:___________________________________________
方法二:___________________________________________
3. 读取第一行记录的“规格”数据,可以用什么方法?
____________________________________
4. 读取第一行数据,可以用哪些方法?
__________________________________
课堂练习2
5. 读取前两行数据呢?后两行数据呢?
前两行数据:__________________________
后两行数据:__________________________
6. 计算价格平均值,代码如何写?
___________________________
7. 以“采价点”分组,计算分组后各超市价格平均值呢?代码则么写?
__________________________
8. 小明想按“存量(吨)”降序排列df对象中的数据,如何写代码?
__________________________
9. 如何删除“采集时间”列数据?删除之后,原表格会发生变化吗?
__________________________
课堂练习2
观
谢
谢
看
处
程
编
理
4.2.2.1 利用pandas模块处理数据
数
据
DataFrame对象
录
目
01
创建DataFrame对象
02
DataFrame对象
查看DataFrame对象
03
修改DataFrame对象
04
添加DataFrame对象中行列数据
05
删除DataFrame对象中行列数据
06
DataFrame对象分组操作
07
DataFrame对象排序操作
08
DataFrame对象其他操作
09
问题提出
问题:
编程处理右图中的数据,用什么对象保存数据?
下图中的数据呢?
DataFrame对象
Series对象
DataFrame是一种类似于关系表的表格型数据结构,DataFrame对象是一个二维表格,由1个索引列(index)和若干个数据列组成。其中,每列中的元素类型必须一致,而不同的列可以拥有不同的元素类型。
一、Pandas模块——DataFrame对象
列名:columns
二维数据:values
行索引:index,但DataFrame与excel不同,默认从0开始
数据结构 维度 组成部分 属性
Series 一维 由一个数组的数据(values)和一个与数据关联的索引(index) index、values
DataFrame
二维
由1个索引列(index)和若干个数据列组成
index、columns、values、T
一、Pandas模块——DataFrame对象
二、Pandas模块——创建DataFrame对象
创建方法1:以相等长度的列表组成的字典形式创建
import pandas as pd
data={'学号':[1,2,3,4,5,6],
'姓名':['彭小亿','刘佳婷','张三','张元斌','齐铭','陈小红'],
'英语':[132,122,111,104,121,104],
'政治':[81,82,84,76,82,85],
'技术':[91,88,81,97,94,82],
'总分':[304,292,276,277,297,271]}
s=pd.DataFrame(data)
print(s)
行索引:index,默认从0开始
列名:coulmns
二维数据:
values
import pandas as pd
data={'学号':[1,2,3,4,5,6],
'姓名':['彭小亿','刘佳婷','张三','张元斌','齐铭','陈小红'],
'英语':[132,122,111,104,121,104],
'政治':[81,82,84,76,82,85],
'技术':[91,88,81,97,94,82],
'总分':[304,292,276,277,297,271]}
s=pd.DataFrame(data,
index=['no1','no2','no3','no4','no5','no6'])
print(s)
二、Pandas模块——创建DataFrame对象
创建方法2:指定行索引
行索引:index
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df)
二、Pandas模块——创建DataFrame对象
创建方法3:从excel文件读入二维数据表,pd.read_excel()
★ to_excel() : 用dataframe创建excel
三、Pandas模块——查看DataFrame列数据
查看方法1:通过属性检索,查看列数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df.姓名)
查看方法2:通过字典检索,查看列数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df['姓名'] )
三、Pandas模块——查看DataFrame行数据
查看方法1:通过索引切片、dataFrame的head()函数和tail()函数,查看行数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df[2:5])
print('----------------------')
print(df.head(2))
print('----------------------')
print(df.tail(3))
print('----------------------')
三、Pandas模块——查看DataFrame行数据
查看方法2:通过索引切片查看指定行数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df[2:3])
三、Pandas模块——查看DataFrame行数据
查看方法3:布尔型数据选取满足条件的行
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df[df['英语']>110])
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df[df.英语>110])
三、Pandas模块——查看DataFrame一个数值
查看方法:at[ ]方法获取某行某列的值
对象名.at[行索引,"列标签"]
import pandas as pd
df=pd.read_excel('test.xlsx ')
print(df.at[2,'姓名'])
三、Pandas模块——查看DataFrame数据
查看方法1:循环查看行索引
import pandas as pd
df=pd.read_excel('test.xlsx')
for i in df.index:
print(i)
查看方法2:循环查看数据
import pandas as pd
df=pd.read_excel('test.xlsx')
for i in df.values:
print(i)
查看方法3:循环查看列标题
import pandas as pd
df=pd.read_excel('test.xlsx')
for i in df.columns:
print(i)
查看方法4:循环查看列标题
import pandas as pd
df=pd.read_excel('test.xlsx')
for i in df:
print(i)
三、Pandas模块——查看DataFrame数据
查看方法5:直接用关键字查看相关数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df.index)
print('-----------------------')
print(df.values)
print('-----------------------')
print(df.columns)
print('-----------------------')
print(df)
print('-----------------------')
四、Pandas模块——修改DataFrame列数据
修改方法1:通过属性或字典检索修改列数据
import pandas as pd
df=pd.read_excel('test.xlsx ')
df.姓名=['a','b','c','d','e','f']
print(df)
import pandas as pd
df=pd.read_excel('test.xlsx ')
Df['姓名']=['a','b','c','d','e','f']
print(df)
四、Pandas模块——修改DataFrame行数据
修改方法1:通过索引切片修改行数据
import pandas as pd
df=pd.read_excel('test.xlsx ')
df[2:3]=[3,'李华',34,23,234,45]
print(df)
四、Pandas模块——修改DataFrame某个数据
修改方法1:通过at[]方法修改单个数据
import pandas as pd
df=pd.read_excel('test.xlsx ')
df.at[3,'技术']=98
print(df)
四、Pandas模块——修改DataFrame数据
修改方法1:转置
import pandas as pd
df=pd.read_excel('test.xlsx ')
print(df.T)
五、Pandas模块——DataFrame添加行数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df)
df.append({'学号':7,'姓名':'梁国辉','英语':148,
'政治':92,'技术':97,'总分':337},ignore_index=True)
print(df)
添加数据错误: append()函数添加行数据
append()函数不改变原有df对象中的数据
五、Pandas模块——DataFrame添加行数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df)
df1=df.append({'学号':7,'姓名':'梁国辉','英语':148,
'政治':92,'技术':97,'总分':337},ignore_index=True)
print(df1)
添加数据正确:append()函数添加行数据
索引默认往上加,
添加在最后一行。
五、Pandas模块——DataFrame添加列数据
import pandas as pd
df=pd.read_excel('test.xlsx ')
df.insert(3,"性别",['男','女','男','男','男','女',])
print(df)
添加数据正确:insert(i,columns,data)添加列数据
i:插入位置
columns:列标签
data:添加数据或数据列表
六、Pandas模块——DataFrame删除数据函数
删除数据:drop()函数删除行数据或列数据
import pandas as pd
df=pd.read_excel('test.xlsx')
print(df)
df2=df.drop(0)
print(df2)
df3=df.drop('学号',axis=1)
print(df3)
drop()函数不改变原有df对象中的数据
axis=0表示删除行;axis=0表示删除列
del df[‘学号’] 会永久删除df对象学号列数据
df2=df.drop(0 ',axis=0)
七、Pandas模块——DataFrame数据分组函数
import pandas as pd
df=pd.read_excel('test1.xlsx')
df1=df.groupby('性别',as_index=False)
print(df1)
print(df1.mean())
数据分组:groupby()函数分组数据
groupby(labels,axis=0,as_index=True)
mean()求平均值
df1=df.groupby('性别',as_index=False).mean()
八、Pandas模块——DataFrame数据排序
import pandas as pd
df=pd.read_excel('test1.xlsx')
df1=df.sort_values('总分',ascending=True)
print(df1)
数据排序:sort_values()函数排列数据
ascendng=True:升序排序ascendng=False:降序排序
import pandas as pd
df=pd.read_excel('test1.xlsx')
df.sort_values('总分',ascending=True,inplace=True)
print(df1)
九、Pandas模块——DataFrame其他函数
import pandas as pd
df=pd.read_excel('test1.xlsx')
print(df.姓名.count())
print("---------------")
print(df['总分'].max())
print("---------------")
print(round(df['技术'].mean(),2))
十、Pandas模块——处理数据的DataFrame常用函数
DataFrame常用函数 函数 说明
count() 返回非空(NaN)数据项的数量;一般按列求;
sum() mean() max() min() 求和、求平均、求最大、求最小;一般按列求;
groupby() 按列或行分组统计;一般按列求;
head() tail() 返回前n个、后n个数据记录;
drop() 按行列删除数据,通过axis=0/1确定行列;
append() 在末尾添加1行或多行数据;
insert() 在指定位置插入1列;
rename() 修改列标签或行索引;
sort_values() 排序,通过axis=0/1确定行列;
describe() 返回各列的基本描述统计值,包含计数、平均值、标准差、最大值、最小值、4分位差
concat()/plot() 合并DataFrame对象/绘图
某班级计划在某商店购买秋季运动会的奖品,奖品数据如下:
商品名称 商品价格(元) 购买数量
笔记簿 15 25
铅笔 2 50
橡皮 5 30
三角尺 6.5 10
圆规 9 10
课堂练习1
请你用pandas的DataFrame数据结构,存储以上表格数据。
1.创建一个名为jpdata的变量,用于存储以上表格数据默认行索引,
列标签为:“商品名称”,“商品价格(元)”,“购买数量”,“购买金额”(的初值为0)。
2.请分别计算每种商品的购买金额并存储到“购买金额”数据列中。
1. 读取’a.xlsx’表格数据到pandas模块DataFrame对象的代码:
2. 查看“价格”列数据,可以用哪两种方法?
方法一:___________________________________________
方法二:___________________________________________
3. 读取第一行记录的“规格”数据,可以用什么方法?
____________________________________
4. 读取第一行数据,可以用哪些方法?
__________________________________
课堂练习2
5. 读取前两行数据呢?后两行数据呢?
前两行数据:__________________________
后两行数据:__________________________
6. 计算价格平均值,代码如何写?
___________________________
7. 以“采价点”分组,计算分组后各超市价格平均值呢?代码则么写?
__________________________
8. 小明想按“存量(吨)”降序排列df对象中的数据,如何写代码?
__________________________
9. 如何删除“采集时间”列数据?删除之后,原表格会发生变化吗?
__________________________
课堂练习2
观
谢
谢
看