编程处理数据-pandas模块处理数据 导学案 2021—2022学年 浙教版(2019)高中信息技术必修1
文档属性
| 名称 | 编程处理数据-pandas模块处理数据 导学案 2021—2022学年 浙教版(2019)高中信息技术必修1 |

|
|
| 格式 | docx | ||
| 文件大小 | 340.1KB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2022-05-21 00:00:00 | ||
图片预览



文档简介
编程处理数据---pandas模块处理数据导学案
学习目标:
了解Python常用扩展模块的功能。
掌握pandas模块的调用方法、数据结构等基本知识。
3、能使用pandas模块对数据进行编辑、计算和统计分析,并能从中提取有用信息形成结论。
4、掌握matplotlib模块的调用方法和使用matplotlib模块对数据进行可视化的基本方法。
二、知识要点:
pandas模块(Series和DataFrame模块)
1.创建Series: pandas.Series(values[,index])
values可以是字典或列表,当是字典时,索引为字典的索引;当是列表时,索引默认从0起递增的整数,也可添加第二个参数index,指定索引。
默认索引 import pandas as pd s=pd.Series([166,178,180]) print(s) 0 166 1 178 2 180 dtype: int64 指定索引 import pandas as pd s=pd.Series([166,178,180],['s1','s2','s3']) print(s) s1 166 s2 178 s3 180 dtype: int64
常用对象属性
属性 说明
index Series的下标索引,其值默认是从0起递增的整数
values 存放Series值的一个数组
2、DataFrame
是一种二维的数据结构,由1个索引列(index)和若干个数据列组成,每个数据列可以是不同的类型
创建二维数组
例:
创建DataFrame:
①用一个相同长度的列表或字典创建
pandas.DataFrame(data)
相同长度的列表创建 import pandas as pd data=[['A','B','C'],[1,2,3]] s=pd.DataFrame(data) print(s) 运行结果: 0 1 2 0 A B C 1 1 2 3 字典创建 import pandas as pd data={'姓名':['王静怡','张佳妮','李呈武'],'性别':['女','女','男'],'借阅次数':[28,56,37]} s=pd.DataFrame(data)//也可以再加columns调整数据列顺序 print(s) 运行结果: 姓名 性别 借阅次数 0 王静怡 女 28 1 张佳妮 女 56 2 李呈武 男 37
③直接读取二维数据文件创建DataFrame对象
二维数据文件有:excel, csv文件等,可使用 read_excel( )函数, read_csv( )函数等
例:
读取Excel文件 “test.xlsx”中的数据,创建DataFrame对象df
import pandas as pd
df=pd.read_excel(“test.xlsx’) #该文件使用的是相对路径,所以excel文件要和python保存在同一目录下
print(df)
DataFrame对象常用属性
属性 说明
index DataFrame的行索引
columns 存放各列的列标题
values 存放值的二维数据
T 行列转置(行变列,列变行)
例:_
for i in df.index:
print(i)
for i in df.columns:
print(i)
for i in df.values:
print(i)
print(df.T)
DataFrame的索引
(一)行索引:
df.head( )默认前5行值和df.tail( )默认后5行值
df.head( n ) 前n行的值,
df.tail(n) 后n行的值
df[n:m] 访问行索引n至m-1行数据
df[n:n+1]访问行索引第n行数据
df.values[n]:访问行索引值是第n的数据
例:
import pandas as pd
df=pd.read_excel(“test.xlsx’)
print(df.head( )) #显示表格中前5行的数据
(二)列索引:
df[‘列名’] 字典
df.列名 属性
df[[‘列名’,’列名2’,’列名3’,…’列名n’]]
例:
print(df[‘姓名’])
print(df.信息)
print(df[['姓名','英语','生物']]) #多列值
第n行第n列索引
at[ ] 方法
print(df.at[3, '姓名']) 显示第4行的姓名值
(三)布尔型数据选取满足条件:
df[ 条件表达式 ]条件表达式应由df[‘列标题名’] 和关系运算符组成的表达式组成
例:
print (df[df['语文']>108]) 或print(df[df.语文>108])
多个条件筛选:
print(df[(df.语文>100)&(df.数学>110)&(df.英语>100)])
结果:
(四)DataFrame对象中的行列的编辑:
(1)列的操作:
插入、删除、重命名
直接插入
增加列可以直接通过标签索引方式进行,当新增的列中的数值不一样时,可以插入列表或者数组结构进行赋值
from pandas import DataFrame
data = {"name":("张三","李四","王五","赵六"),"sex":("男","女","女","男"), "aged":(20,19,20,21), "score":(80,60,70,90)}
df = DataFrame(data) #使用字典创建DataFrame对象
print(df)
df["city"] = ["北京","西安","长春","珠海"]
print(df)
insert( )函数插入 (影响原始数据)
insert(loc, column, value, allow_duplicates=False)
loc:一个整数,表示第几列 (默认第0列开始)
column:表示列名
value:该列的值,series.list均可
allow_duplicates:列名是否可以重复,默认值是False
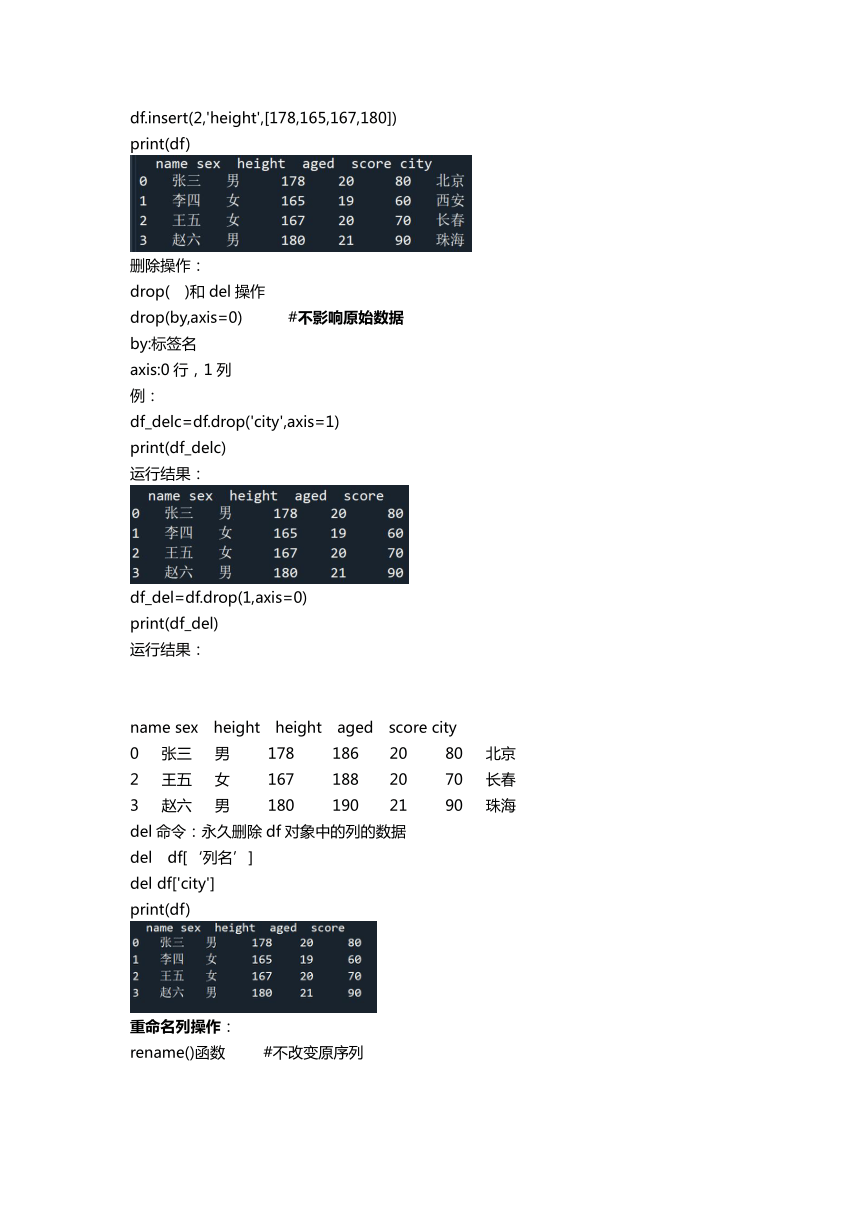
df.insert(2,'height',[178,165,167,180])
print(df)
删除操作:
drop( )和del操作
drop(by,axis=0) #不影响原始数据
by:标签名
axis:0行,1列
例:
df_delc=df.drop('city',axis=1)
print(df_delc)
运行结果:
df_del=df.drop(1,axis=0)
print(df_del)
运行结果:
name sex height height aged score city
0 张三 男 178 186 20 80 北京
2 王五 女 167 188 20 70 长春
3 赵六 男 180 190 21 90 珠海
del命令:永久删除df对象中的列的数据
del df[‘列名’]
del df['city']
print(df)
重命名列操作:
rename()函数 #不改变原序列
格式:rename(columns={'原列名':'更改后列名'})
例:
df_ren=df.rename(columns={'name':'姓名'})
print(df_ren)
(2)行的操作:
append( )追加数据行 # 不改变原序列
例 :
import pandas as pd
df1=pd.DataFrame(`1`,columns=['a'])
df2=pd.DataFrame(`2`,columns=['a'])
df3=pd.DataFrame([3,4],columns=['a'])
df4=df1.append(df2,ignore_index=True) #默认ignore_index=False
df=df4.append(df3)
print(df)
运行结果
drop( )册除行 #不改变原序列
DataFrame对象中数据的统计与计算
groupby( )函数:可以对DataFrame对象各列或各行的数据进行分组,然后对其中每一组数据进行不同的操作
groupby(by,as_index=True)
by 分类的列标签,
as_index:True表示以组标签(列名)为索引,False不以组标签为索引。
例:
import pandas as pd
df=pd.read_excel('水果销售.xlsx')
print(df)
g=df.groupby('地区',as_index=True)
print(g.mean())
g=df.groupby('采价点',as_index=True)
print(g.mean())
运行结果
print(pdf.groupby('地区')['价格'].mean())
DataFrame对象中数据的排序
sort_index( )函数的使用:按索引排序
sort_values( )函数的使用:按值排序
sort_values(by,axis=0,ascending=True)
by: 索引(根据选择的是行还是列,填相应的标签)
axis:0表示行,表示列
ascending:True升序,False降序
例:
df_sort=df.sort_values(‘价格’,ascending=False) #按价格值降序排序
print(df_sort)
运行结果:
DataFrame常用函数
函数 说明
count() 返回非空(NaN)数据项的数量
sum()、mean() 求和、求平均值,通过axis=0/1确定行列
max()、min() 返回最大、最小值
describe() 返回各列的基本描述统计值,包含计数、
head(n)、tail(n) 返回DataFrame的钱n个、后n个数据记录
groupby() 对各列或各行中的数据进行分组,然后可对其中每一组数据进行不同的操作
sort_values() 排序,axis=0/1确定行列
drop() 删除数据,通过axis=0/1确定行列,axis=0表示行,axis=1表示列
append() 在指定元素的结尾插入内容(插入value,行),ignore_index=True时插入时不需要指定index
insert() 在指定位置插入列
rename() 修改列名或者索引
concat() 合并DataFrame对象
at[] 根据行标签和列标签这只单个值
plot() 绘图
#以下演示均在df上操作 info=[[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]] columns=['a','b','c','d','e'] df=pd.DataFrame(info,columns=columns) print(df) 运行结果: a b c d e 0 1 2 3 4 5 1 6 7 8 9 10 2 11 12 13 14 15
①count()
count(axis=0,numeric_only=False)
axis:0或‘索引‘表示行,1或’列‘表示列
print(df.count(axis=0))
print(df.count(axis=1))
numeric_only:仅包含数字和布尔数据
print(df.count()) 运行结果: a 3 b 3 c 3 d 3 e 3 print(df[‘a’].count()) 运行结果 3
②sum()、mean()
sum(axis=0)
print(df.sum()) 运行结果 a 18 b 21 c 24 d 27 e 30 dtype: int64 print(df.mean()) 运行结果: a 6.0 b 7.0 c 8.0 d 9.0 e 10.0 dtype: float64 print(df.sum(axis=1)) 运行结果 0 15 1 40 2 65 dtype: int64
③max()、min()
max(axis=0),用法同sum
print(df.max()) 运行结果 a 18 b 21 c 24 d 27 e 30 dtype: int64
④describe()
print(df.describe()) 运行结果: a b c d e count 3.0 3.0 3.0 3.0 3.0 该列数据项数量 mean 6.0 7.0 8.0 9.0 10.0 该列平均值 std 5.0 5.0 5.0 5.0 5.0 该列标准差 min 1.0 2.0 3.0 4.0 5.0 该列最小值 25% 3.5 4.5 5.5 6.5 7.5 该列前25%的数据 50% 6.0 7.0 8.0 9.0 10.0 该列前50%的数据 75% 8.5 9.5 10.5 11.5 12.5 该列前75%的数据 max 11.0 12.0 13.0 14.0 15.0 该列前100%的数据
matplotlib
matplotlib.pyplot中常用绘图函数
函数 说明
figure() 创建一个新的图表对象,并设置为当前绘图对象 注:不创建figure对象,直接调用plot等绘图函数进行绘图,matplotlib会自动创建一个figure对象
plot() 绘制线形图
bar() 绘制垂直柱状图
barh() 绘制平行柱状图
scatter() 绘制散点图
title() 设置图表标题
xlim()、ylim() 设置X、Y轴的取值范围
xlabel()、ylabel() 设置X、Y轴的标签
legend() 显示图例
show() 显示创建的所有绘图对象
①figure()
figure(num=None,figsize=fiuguer.figsize)
num:窗口的标识id
figsize:窗口的大小,如figsize=(8,4),即为长8英寸,宽4英寸
②plot()
常用参数
plot([x],y[,color][,label][,linewidth])
x:横坐标数据
y:纵坐标数据
color:线的颜色
label:线的标题
linewidth:线宽
③bar()
常用参数
参数 接收值 说明 默认值
x array x轴 无
height array 柱形图的高度,也就是y轴的高度 无
width 数值 柱形图的宽度 0.8
color string 柱形图填充的颜色
label string 解释每个图像代表的含义 None
x=range(1,5) height=[10,7,5,8] plt.bar(x,height,width=0.6,color='b',label='test') plt.show()
③barh()
水平柱形图
参数 接收值 说明 默认值
y array y轴 无
width array 水平柱形图的宽度,即为值 无
height 数值 柱子的宽度 0.8
color string 柱形图填充的颜色
label string 解释每个图像代表的含义 None
y=range(1,5) width=[10,7,5,8] plt.barh(y,width,height=0.6,color='b',label='aaaaaa') plt.show()
④scatter()
参数 接收值 说明
x array x轴
y array y轴
color string 颜色
label string 解释每个图像代表的含义
x=range(1,5) y=[10,7,5,8] plt.scatter(x,y,color='b',label='test') plt.show()
⑤title()
title(label),将图表标题设置为label
plt.title(‘test’)
⑥xlim()、ylim()
xlim(left,right),将x轴的范围设置为[left,right]
⑥xlabel()、ylabel ()
xlabel(label)、ylabel(label)
设置x轴标签和y轴标签
⑦legend()
显示图例标签
plt.legend()
⑧show()
学习目标:
了解Python常用扩展模块的功能。
掌握pandas模块的调用方法、数据结构等基本知识。
3、能使用pandas模块对数据进行编辑、计算和统计分析,并能从中提取有用信息形成结论。
4、掌握matplotlib模块的调用方法和使用matplotlib模块对数据进行可视化的基本方法。
二、知识要点:
pandas模块(Series和DataFrame模块)
1.创建Series: pandas.Series(values[,index])
values可以是字典或列表,当是字典时,索引为字典的索引;当是列表时,索引默认从0起递增的整数,也可添加第二个参数index,指定索引。
默认索引 import pandas as pd s=pd.Series([166,178,180]) print(s) 0 166 1 178 2 180 dtype: int64 指定索引 import pandas as pd s=pd.Series([166,178,180],['s1','s2','s3']) print(s) s1 166 s2 178 s3 180 dtype: int64
常用对象属性
属性 说明
index Series的下标索引,其值默认是从0起递增的整数
values 存放Series值的一个数组
2、DataFrame
是一种二维的数据结构,由1个索引列(index)和若干个数据列组成,每个数据列可以是不同的类型
创建二维数组
例:
创建DataFrame:
①用一个相同长度的列表或字典创建
pandas.DataFrame(data)
相同长度的列表创建 import pandas as pd data=[['A','B','C'],[1,2,3]] s=pd.DataFrame(data) print(s) 运行结果: 0 1 2 0 A B C 1 1 2 3 字典创建 import pandas as pd data={'姓名':['王静怡','张佳妮','李呈武'],'性别':['女','女','男'],'借阅次数':[28,56,37]} s=pd.DataFrame(data)//也可以再加columns调整数据列顺序 print(s) 运行结果: 姓名 性别 借阅次数 0 王静怡 女 28 1 张佳妮 女 56 2 李呈武 男 37
③直接读取二维数据文件创建DataFrame对象
二维数据文件有:excel, csv文件等,可使用 read_excel( )函数, read_csv( )函数等
例:
读取Excel文件 “test.xlsx”中的数据,创建DataFrame对象df
import pandas as pd
df=pd.read_excel(“test.xlsx’) #该文件使用的是相对路径,所以excel文件要和python保存在同一目录下
print(df)
DataFrame对象常用属性
属性 说明
index DataFrame的行索引
columns 存放各列的列标题
values 存放值的二维数据
T 行列转置(行变列,列变行)
例:_
for i in df.index:
print(i)
for i in df.columns:
print(i)
for i in df.values:
print(i)
print(df.T)
DataFrame的索引
(一)行索引:
df.head( )默认前5行值和df.tail( )默认后5行值
df.head( n ) 前n行的值,
df.tail(n) 后n行的值
df[n:m] 访问行索引n至m-1行数据
df[n:n+1]访问行索引第n行数据
df.values[n]:访问行索引值是第n的数据
例:
import pandas as pd
df=pd.read_excel(“test.xlsx’)
print(df.head( )) #显示表格中前5行的数据
(二)列索引:
df[‘列名’] 字典
df.列名 属性
df[[‘列名’,’列名2’,’列名3’,…’列名n’]]
例:
print(df[‘姓名’])
print(df.信息)
print(df[['姓名','英语','生物']]) #多列值
第n行第n列索引
at[ ] 方法
print(df.at[3, '姓名']) 显示第4行的姓名值
(三)布尔型数据选取满足条件:
df[ 条件表达式 ]条件表达式应由df[‘列标题名’] 和关系运算符组成的表达式组成
例:
print (df[df['语文']>108]) 或print(df[df.语文>108])
多个条件筛选:
print(df[(df.语文>100)&(df.数学>110)&(df.英语>100)])
结果:
(四)DataFrame对象中的行列的编辑:
(1)列的操作:
插入、删除、重命名
直接插入
增加列可以直接通过标签索引方式进行,当新增的列中的数值不一样时,可以插入列表或者数组结构进行赋值
from pandas import DataFrame
data = {"name":("张三","李四","王五","赵六"),"sex":("男","女","女","男"), "aged":(20,19,20,21), "score":(80,60,70,90)}
df = DataFrame(data) #使用字典创建DataFrame对象
print(df)
df["city"] = ["北京","西安","长春","珠海"]
print(df)
insert( )函数插入 (影响原始数据)
insert(loc, column, value, allow_duplicates=False)
loc:一个整数,表示第几列 (默认第0列开始)
column:表示列名
value:该列的值,series.list均可
allow_duplicates:列名是否可以重复,默认值是False
df.insert(2,'height',[178,165,167,180])
print(df)
删除操作:
drop( )和del操作
drop(by,axis=0) #不影响原始数据
by:标签名
axis:0行,1列
例:
df_delc=df.drop('city',axis=1)
print(df_delc)
运行结果:
df_del=df.drop(1,axis=0)
print(df_del)
运行结果:
name sex height height aged score city
0 张三 男 178 186 20 80 北京
2 王五 女 167 188 20 70 长春
3 赵六 男 180 190 21 90 珠海
del命令:永久删除df对象中的列的数据
del df[‘列名’]
del df['city']
print(df)
重命名列操作:
rename()函数 #不改变原序列
格式:rename(columns={'原列名':'更改后列名'})
例:
df_ren=df.rename(columns={'name':'姓名'})
print(df_ren)
(2)行的操作:
append( )追加数据行 # 不改变原序列
例 :
import pandas as pd
df1=pd.DataFrame(`1`,columns=['a'])
df2=pd.DataFrame(`2`,columns=['a'])
df3=pd.DataFrame([3,4],columns=['a'])
df4=df1.append(df2,ignore_index=True) #默认ignore_index=False
df=df4.append(df3)
print(df)
运行结果
drop( )册除行 #不改变原序列
DataFrame对象中数据的统计与计算
groupby( )函数:可以对DataFrame对象各列或各行的数据进行分组,然后对其中每一组数据进行不同的操作
groupby(by,as_index=True)
by 分类的列标签,
as_index:True表示以组标签(列名)为索引,False不以组标签为索引。
例:
import pandas as pd
df=pd.read_excel('水果销售.xlsx')
print(df)
g=df.groupby('地区',as_index=True)
print(g.mean())
g=df.groupby('采价点',as_index=True)
print(g.mean())
运行结果
print(pdf.groupby('地区')['价格'].mean())
DataFrame对象中数据的排序
sort_index( )函数的使用:按索引排序
sort_values( )函数的使用:按值排序
sort_values(by,axis=0,ascending=True)
by: 索引(根据选择的是行还是列,填相应的标签)
axis:0表示行,表示列
ascending:True升序,False降序
例:
df_sort=df.sort_values(‘价格’,ascending=False) #按价格值降序排序
print(df_sort)
运行结果:
DataFrame常用函数
函数 说明
count() 返回非空(NaN)数据项的数量
sum()、mean() 求和、求平均值,通过axis=0/1确定行列
max()、min() 返回最大、最小值
describe() 返回各列的基本描述统计值,包含计数、
head(n)、tail(n) 返回DataFrame的钱n个、后n个数据记录
groupby() 对各列或各行中的数据进行分组,然后可对其中每一组数据进行不同的操作
sort_values() 排序,axis=0/1确定行列
drop() 删除数据,通过axis=0/1确定行列,axis=0表示行,axis=1表示列
append() 在指定元素的结尾插入内容(插入value,行),ignore_index=True时插入时不需要指定index
insert() 在指定位置插入列
rename() 修改列名或者索引
concat() 合并DataFrame对象
at[] 根据行标签和列标签这只单个值
plot() 绘图
#以下演示均在df上操作 info=[[1,2,3,4,5],[6,7,8,9,10],[11,12,13,14,15]] columns=['a','b','c','d','e'] df=pd.DataFrame(info,columns=columns) print(df) 运行结果: a b c d e 0 1 2 3 4 5 1 6 7 8 9 10 2 11 12 13 14 15
①count()
count(axis=0,numeric_only=False)
axis:0或‘索引‘表示行,1或’列‘表示列
print(df.count(axis=0))
print(df.count(axis=1))
numeric_only:仅包含数字和布尔数据
print(df.count()) 运行结果: a 3 b 3 c 3 d 3 e 3 print(df[‘a’].count()) 运行结果 3
②sum()、mean()
sum(axis=0)
print(df.sum()) 运行结果 a 18 b 21 c 24 d 27 e 30 dtype: int64 print(df.mean()) 运行结果: a 6.0 b 7.0 c 8.0 d 9.0 e 10.0 dtype: float64 print(df.sum(axis=1)) 运行结果 0 15 1 40 2 65 dtype: int64
③max()、min()
max(axis=0),用法同sum
print(df.max()) 运行结果 a 18 b 21 c 24 d 27 e 30 dtype: int64
④describe()
print(df.describe()) 运行结果: a b c d e count 3.0 3.0 3.0 3.0 3.0 该列数据项数量 mean 6.0 7.0 8.0 9.0 10.0 该列平均值 std 5.0 5.0 5.0 5.0 5.0 该列标准差 min 1.0 2.0 3.0 4.0 5.0 该列最小值 25% 3.5 4.5 5.5 6.5 7.5 该列前25%的数据 50% 6.0 7.0 8.0 9.0 10.0 该列前50%的数据 75% 8.5 9.5 10.5 11.5 12.5 该列前75%的数据 max 11.0 12.0 13.0 14.0 15.0 该列前100%的数据
matplotlib
matplotlib.pyplot中常用绘图函数
函数 说明
figure() 创建一个新的图表对象,并设置为当前绘图对象 注:不创建figure对象,直接调用plot等绘图函数进行绘图,matplotlib会自动创建一个figure对象
plot() 绘制线形图
bar() 绘制垂直柱状图
barh() 绘制平行柱状图
scatter() 绘制散点图
title() 设置图表标题
xlim()、ylim() 设置X、Y轴的取值范围
xlabel()、ylabel() 设置X、Y轴的标签
legend() 显示图例
show() 显示创建的所有绘图对象
①figure()
figure(num=None,figsize=fiuguer.figsize)
num:窗口的标识id
figsize:窗口的大小,如figsize=(8,4),即为长8英寸,宽4英寸
②plot()
常用参数
plot([x],y[,color][,label][,linewidth])
x:横坐标数据
y:纵坐标数据
color:线的颜色
label:线的标题
linewidth:线宽
③bar()
常用参数
参数 接收值 说明 默认值
x array x轴 无
height array 柱形图的高度,也就是y轴的高度 无
width 数值 柱形图的宽度 0.8
color string 柱形图填充的颜色
label string 解释每个图像代表的含义 None
x=range(1,5) height=[10,7,5,8] plt.bar(x,height,width=0.6,color='b',label='test') plt.show()
③barh()
水平柱形图
参数 接收值 说明 默认值
y array y轴 无
width array 水平柱形图的宽度,即为值 无
height 数值 柱子的宽度 0.8
color string 柱形图填充的颜色
label string 解释每个图像代表的含义 None
y=range(1,5) width=[10,7,5,8] plt.barh(y,width,height=0.6,color='b',label='aaaaaa') plt.show()
④scatter()
参数 接收值 说明
x array x轴
y array y轴
color string 颜色
label string 解释每个图像代表的含义
x=range(1,5) y=[10,7,5,8] plt.scatter(x,y,color='b',label='test') plt.show()
⑤title()
title(label),将图表标题设置为label
plt.title(‘test’)
⑥xlim()、ylim()
xlim(left,right),将x轴的范围设置为[left,right]
⑥xlabel()、ylabel ()
xlabel(label)、ylabel(label)
设置x轴标签和y轴标签
⑦legend()
显示图例标签
plt.legend()
⑧show()