专题三:python基础 复习课件 2022—2023学年高中信息技术浙教版(2019)必修1(60张PPT)
文档属性
| 名称 | 专题三:python基础 复习课件 2022—2023学年高中信息技术浙教版(2019)必修1(60张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 6.7MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2022-11-10 15:20:01 | ||
图片预览







文档简介
(共60张PPT)
Python 基础
必修一:数据与计算(一轮复习)
算法基础
算法定义与特征
定义:“算法”指的是计算机解决问题的步骤,是为了解决问题而需要让计算机有序执行的,无歧义的,有限步骤的集合。
有穷性
有0个或多个输入
可行性
确定性
有1个或多个输出
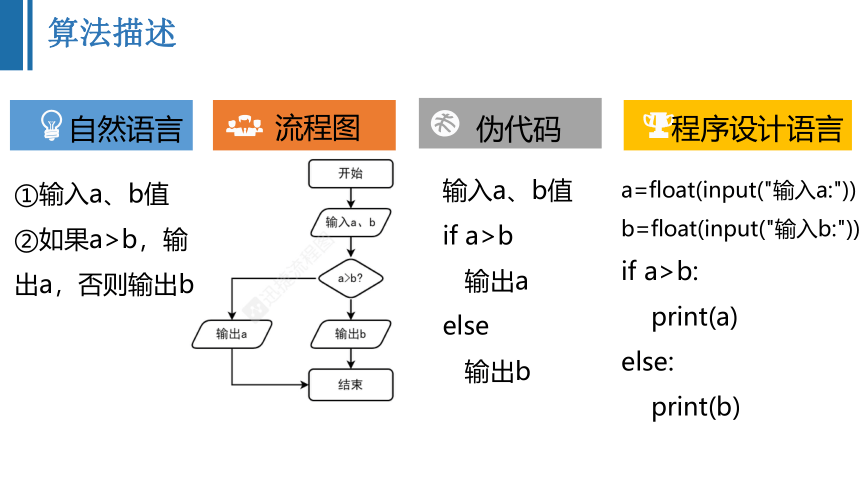
算法描述
自然语言
流程图
伪代码
程序设计语言
①输入a、b值
②如果a>b,输出a,否则输出b
输入a、b值
if a>b
输出a
else
输出b
a=float(input("输入a:"))
b=float(input("输入b:"))
if a>b:
print(a)
else:
print(b)
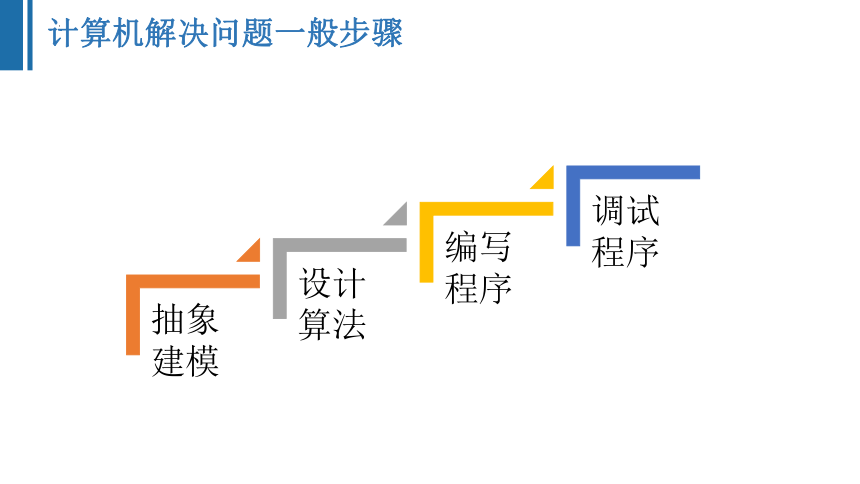
计算机解决问题一般步骤
Python基础
变量与赋值语句
普通赋值:
a=“abc”
增量赋值:
a+=5
序列赋值:
a,b=b,a
连续赋值:
a=b=“abc”
变量:变量是存放数据值的容器
命名规则:
①变量名只能包含字母数字字符和下划线
②不能以数字开头
③变量名不能是关键字
④变量名称区分大小写
(True False)
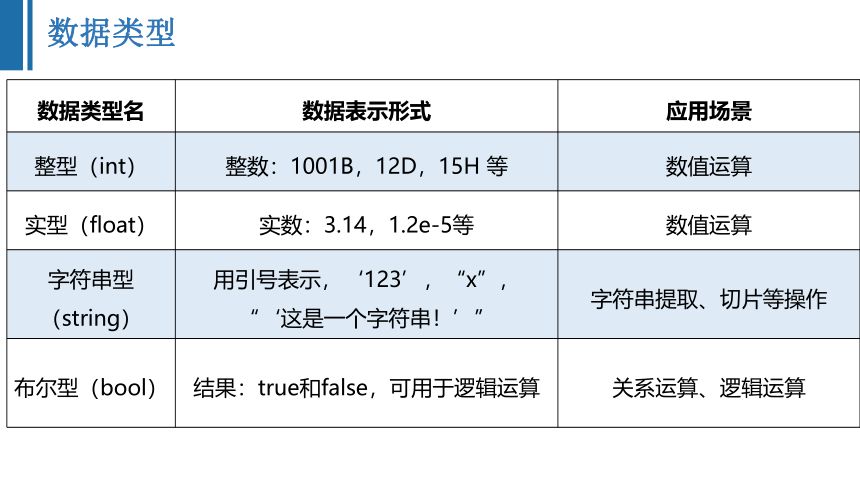
数据类型
数据类型名 数据表示形式 应用场景
整型(int) 整数:1001B,12D,15H 等 数值运算
实型(float) 实数:3.14,1.2e-5等 数值运算
字符串型(string) 用引号表示,‘123’,“x”,“‘这是一个字符串!’” 字符串提取、切片等操作
布尔型(bool) 结果:true和false,可用于逻辑运算 关系运算、逻辑运算
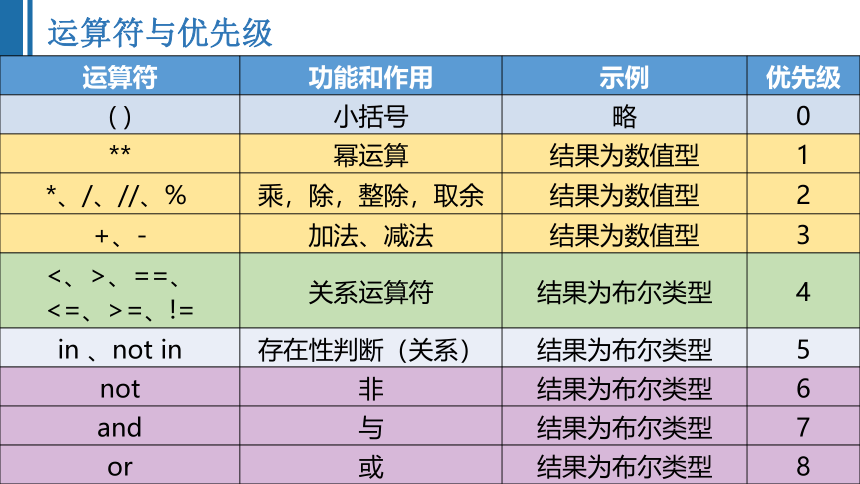
运算符与优先级
运算符 功能和作用 示例 优先级
( ) 小括号 略 0
** 幂运算 结果为数值型 1
*、/、//、% 乘,除,整除,取余 结果为数值型 2
+、- 加法、减法 结果为数值型 3
<、>、==、 <=、>=、!= 关系运算符 结果为布尔类型 4
in 、not in 存在性判断(关系) 结果为布尔类型 5
not 非 结果为布尔类型 6
and 与 结果为布尔类型 7
or 或 结果为布尔类型 8
表达式
(1)表达式按优先级运算,优先级相同则从左到右
(2)Python中认为 数值0、“”(空字符串)与False等价,非零数和非空字符串与True等价
(3)字符串比较 : 从左到右逐位比较ASCII码值
”123”<”23”=True
(4)数值类型的运算结果保留更精确的值。例1+2.0=3.0
控制结构——选择结构
if <判断条件>:
语句块1
elif <判断条件>:
语句块2
else:
语句块3
if <判断条件>:
语句块
if <判断条件>:
语句块1
else:
语句块2
控制结构——for循环
仅限于次数确定的有限循环
for i in <序列>:
循环体
序列:
①range()
②字符串序列(字符)
③列表序列(元素)
控制结构——循环结构
可用于次数不确定的循环
while 判断语句:
循环体
break:结束并退出当前层循环;
continue:结束当前次循环,进入下一次循环
①判断语句 始终为True(死循环)
②判断语句 始终为False(不循环)
n = 0 # 循环控制变量
while n < 10: # 循环继续的条件
n += 1 # 步长
print(n) # 循环体
控制结构——循环结构
for i in range(1,7):
for j in range(1,7):
if i+j!=6:
_____________
print(i,j)
划线处填break时,输出结果:
5 1
划线处填continue时,输出结果:
1 5
2 4
3 3
4 2
5 1
函数与模块
内建函数
函数 举例
print() 格式化输出:% format
input() 与int\float\split 一起使用
int() int(“123”) int(4.6) int(-4.6)
float() float(“12.3”) float(4)
abs() abs(-5)
len() len(“123”) len([2,[1,2])
str() a=12 str(a) ”12”
chr() chr(48) ”0”
ord() ord(“0”) 48
round() round(4.5) 4
round(5.5) 6
自定义函数
def 函数名 (参数集合):
<函数体>
[return 函数值]
格式:
from math import sqrt
print(isprime(15))
def isprime(n):
for i in range(2,int(sqrt(n)+1)):
if n%i==0:
return False
return Ture
第三方库
调用:先导入,再使用
导入函数
from random import randint
randint(0,9)
导入模块(库)
import random
random.randint(0,9)
math模块
调用:先导入,再使用
名称
math.e
math.pi
math.ceil() math.ceil(2.1)
math.floor() math.floor()
math.pow() math.pow()
math.log()
math.sin()
math.cos()
math.tan()
math.degrees()
math.randians()
random模块
调用:先导入,再使用
名称 作用
random.random() 随机生成一个[0,1)范围内的实数
random. uniform(a,b) 随机生成一个[a,b]范围内的实数
random. randint(a,b) 随机生成一个[a,b]范围内的整数
random.choice(seq) 从序列中随机挑选一个元素
random.sample(seq,k) 从序列中随机挑选k个元素
random.shuffle(seq) 将序列的所有元素随机排序
image模块
from PIL import Image
im=Image.open(“school.jpg”) #打开图像文件
print(im.format) #获取图像文件格式
print(im.size) #获取图像尺寸大小
print(im.mode) #获取图像的颜色模式
im.rotate(45).show() #将图像旋转45°后显示
image模块(P87图像处理案例)
#导入模块
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
#打开图像,生成数字矩阵
img=np.narry(Image.open("lena.jpg").convert("L"))
Numpy模块
NumPy是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
img=np.narry(Image.open("lena.jpg").convert("L"))
165 203 180
198 230 223
102 98 85
[[165,203,180],
[198,230,223],
[102,98,85]]
image模块(P87图像处理案例)
#调整每个像素值
rows,cols=img.shape #图片长宽分别赋值给rows、cols
for i in range(rows): #横坐标
for j in range(cols): #纵坐标
if(img[i,j]>128): #img[I,j] 某一个像素点
img[i,j]=1 #设置为白色
else:
img[i,j]=0 #设置为黑色
#生成新图像并显示
plt.figure("lena")
plt.imshow(img,cmap="gray")
plt.axis("off")
plt.show()
jieba分词模块
函数 对应模式
cuts cut(s,cut_all=False) 精准分词模式:将句子最精确地切分开,不存在冗余。适合于文本分析。
cut(s,cut_all=Ture) 全模式分词:将句子中所有可能是词的词语都切分出来,速度快,但存在冗余。
cut_for_search(s) 搜索引擎模式分词:在精确模式的基础上对长词再进行切分,将更短的词语切分出来。适合于搜索引擎分词。
jieba分词模块
s="我来到了西北皇家理工学院,发现这儿真不错"
seg_list=jieba.cut(s,cut_all=True)
我/来到/了/西北/皇家/理工/理工学/理工学院/工学/工学院/学院/,/发现/这儿/真不/真不错/不错
s="我来到了西北皇家理工学院,发现这儿真不错"
seg_list=jieba.cut(s,cut_all=False)
我/来到/了/西北/皇家/理工学院/,/发现/这儿/真不错
s="我来到了西北皇家理工学院,发现这儿真不错"
seg_list=jieba.cut_for_search(s)
我/来到/了/西北/皇家/理工/工学/学院/理工学/工学院/理工学院/,/发现/这儿/真不错
wordcloud模块
font_path : 设置字体;如:font_path = '黑体.ttf'
width :画布宽度
height : 画布高度
mask : 使用二维遮罩绘制词云
background_color : 设置背景颜色
mode : 设置颜色模式
fit_words(frequencies) :根据词频生成词云
generate(text) :根据文本生成词云
generate_from_frequencies(frequencies[, ...]) :根据词频生成词云
generate_from_text(text) :根据文本生成词云
to_array() :转化为 numpy array
to_file(filename) :输出到文件
wordcloud模块
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
txt = open("你是我的荣耀.txt",'r',encoding='utf-8').read()
words = jieba.cut(txt) #使用jieba库函数分词
counts = {}
for word in words:
if len(word) == 1: #排除长度为1的字符分词结果
continue
else:
counts[word] = counts.get(word,0)+1 #用get方法建立新词
items = list(counts.items()) #将字典中的键值对转为列表
items.sort(key=lambda x:x[1],reverse=True) #按照统计结果降序排序
wordcloud模块
ciyun = []
for i in range(50):
word,count = items[i]
print(word,count)
ciyun.append(word)
text_cut = ' '.join(ciyun) #转为字符串,并用空格分隔
wordscloud = WordCloud(background_color='white',
font_path = '汉仪乐喵体.ttf',
width=1000,height=1000,margin=2).generate(text_cut)
wordscloud.to_file("词云.png")
plt.imshow(wordscloud) #生成图片
plt.axis('off') #关闭坐标轴
plt.show()
#运行结果:
text = open(r‘C:\Users\jjj\Desktop/12.txt’,‘r’).read() #读取一个txt文件
bg_pic = imread(r‘C:\Users\jjj\Desktop/3.png’) #读入背景图片
wordlist_after_jieba = jieba.cut(text, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
#生成词云
font = r'C:\Windows\Fonts\simfang.ttf'
wc = WordCloud(mask=bg_pic,background_color='white',font_path=font,
scale=1.5).generate(wl_space_split) #根据分词结果生成词云
image_colors = ImageColorGenerator(bg_pic)
#显示词云图片
plt.imshow(wc)
plt.axis('off')
plt.show()
# 保存图片
wc.to_file(r'C:\Users\jjj\Desktop/333.jpg')
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(10,10),dpi=80) #创建对象
plt.xlim(0,10) #x轴取值范围
plt.ylim(0,1) #y轴取值范围
plt.xlabel("x")#x轴标签
plt.ylabel("y")#y轴标签
plt.title("sin(x) and cos(x)") #标题
matplotlib模块
x=np.linspace(0,10,100) #产生序列
y1=np.sin(x)
y2=np.cos(x)
plt.scatter(x,y1,label="sin(x)",color="red")
plt.plot(x,y2,label="cos(x)")
plt.legend()
plt.show() #显示图像
matplotlib模块
plot() #线型图
bar() #垂直柱状图
barh() #水平条形图
scatter() #散点图
pie() #饼图
matplotlib模块
Pandas模块
Pandas模块——一维数据结构Series
Series是一维数据结构,包含一个索引列和一个数据列。索引值默认从0开始,也可以指定索引值。
属 性 说 明
index Series的下标索引,默认从0开始的整数
values 存放Series值的一个数组
Series(创建)
import pandas as pd
①通过列表创建
s1=pd.Series([12,13,14],index=["a","b","c"])
print(s1)
②通过字典创建
s1=pd.Series({"a":12,"b":13,"c":14})
print(s1)
Series(访问)
③访问记录
s1[2]、s1[“b”]
④检索满足条件的记录
print(s1[s1>12])
⑤访问连续多条记录
print(s1[0:2])
import pandas as pd
①打印索引
print(s1.index)
②打印值
print(s1.values)
Series(修改)
s1[2]=100
s1[“b”]=100
s1.b=100
Pandas模块——二维数据结构DataFrame
DataFrame是二维数据结构,包含一个索引列和若干数据列。DataFrame是共享一个索引的Series的集合
属 性 说 明
index DataFrame行索引
columns DataFrame列标题
values 存放二维数据
T 行列转置
DataFrame (创建)
①通过列表创建
df=[["小黑",78,90,96],["小灰",90,92,100],["小白",92,95,98]]
df1=pd.DataFrame(df,columns=["姓名","语文","数学","技术"])
DataFrame (创建)
②通过字典创建
df_1= {"姓名":["小黑","小灰","小白"],"语文":[78,90,92],"数学":
[90,92,95],"技术":[96,100,98]}
df2 = pd.DataFrame(df_1)
columns= [“姓名”,“语文”,“数学”,“技术”]
DataFrame (创建)
③读取二维数据文件创建
df = pd.read_excel(“excel文件名")
df = pd.read_csv(“csv文件名")
df= pd.read_txt(“txt文件名")
df=pd.read_table(“txt文件名")
DataFrame (访问)
#修改索引
df1.index = ["01","02","03"]
#输出列标题
print(df1.columns)
#输出值区域
print(df1.values)
DataFrame (访问)
单列 单行 单个值
访问 df1.姓名 df1["姓名"] (属性、列名) df1.loc[0] df1[0:1] (索引) df1.at[0,“姓名"]
at[行,列]
显示
DataFrame (修改)
单列 单行 单个值
修改 df1.姓名=["Abby",'Cici','Jane'] df1.loc[0] df1[0:1]=[“x”,99,99,99] df1.at[0,“姓名”]=“Sunny”
显示
DataFrame (转置、重命名)
转置:df1.T
重命名rename
df1.rename(index={0:"a",1:"b",2:"c"},
columns={“姓名”:“age”})
DataFrame (行、列算术运算)
#求和—sum(axis=0/1)
df1.sum(axis=0)
df1.技术.sum()
df1[“技术”].sum()
axis=0(统计列数据),
axis=1(统计行数据)
2) count #非空数据个数
mean(axis=0/1) #平均值
max(axis=0/1) #统计最大值
min(axis=0/1) #统计最小值
DataFrame (返回行数据)
head(2)
tail(1)
条件筛选
df1[df1.语文>=90])
df1[df1[“语文”]>=90]
DataFrame (删除数据)
df1.drop(“数学”,axis=1)
当要删除列时,axis需要特别设置为1,否则默认0删除的是行
df1.drop(0)
DataFrame (添加数据)
添加列数据——insert
df1.insert(1,"英语",[95,78,85])
添加行数据——append
data2 = {“姓名”:“李四”,”英语”:76“语文”:97,”数学”:88,”技术”:90}
df2 = pd.DataFrame(data2)
print(df1.append(df2,ignore_index=True))
DataFrame (分组)
df1 = pd.DataFrame(data1)
print(df1.groupby(“科目”,as_index=False).sum())
print(df1.groupby("姓名").mean())
DataFrame (排序)
df1.sort_values("成绩",ascending=False,inplace=True)
DataFrame (合并两表)
df3=concat(df1,df2)
DataFrame
import pandas as pd
df = pd.read_excel("成绩单.xls")
df_sort = df.sort_values("信息技术",ascending=False)
df_t = df_sort.head(10)
df_filter = df_t[[“姓名”,“性别”,“信息技术”]] #保留三列内容
df_group = df_filter.groupby("性别",as_index=False) print(df_group.mean())
turtle 模块
turtle库是Python语言中一个很流行的绘制图像的函数库,想象一只小乌龟,在一个横轴为x、纵轴为y的坐标系原点(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行的路径上绘制了图形。
turtle 模块
turtle 库常用函数或命令
函数或命令 说明
forward(distance) 向当前画笔方向移动distance像素长度
backward(distance) 向当前画笔相反方向移动distance像素长度
right(degree) 顺时针移动degree°
left(degree) 逆时针移动degree°
goto(x,y) 将画笔移动到坐标为x,y的位置
circle(r) 画半径为r的圆,半径为正(负),表示圆心在画笔的左边(右边)画圆
fillcolor(colorstring) 绘制图形的填充颜色
color(color1, color2) 同时设置pencolor=color1, fillcolor=color2
done( ) 暂停程序,停止画笔绘制,但绘图窗体不关闭,直到用户关闭Python Turtle图形化窗口为止;它的目的是给用户时间来查看图形,没有它,图形窗口会在程序完成是立即关闭。
turtle 模块
编程1:逆时针方向画一个边长为100的正方形。
import turtle as t
t.forward(100)
t.left(90)
t.forward(100)
t.left(90)
t.forward(100)
t.left(90)
t.forward(100)
t.left(90)
t.done()
import turtle as t
for i in range(4):
t.forward(100)
t.left(90)
t.done()
改为循环结构
turtle 模块
编程2:分别画半径为:5,10,15,…,95,100的20个圆。
import turtle as t
for i in range(5,101,5):
t.circle(i)
t.done()
绘制任意正多边形
正多边形的各边边长相等,各内角度数也相等。因此绘制一个正多边形,可以通过“画一条边,旋转一定角度后再画一条边”的重复操作来完成。如下图是绘制正六边型的过程。
计算模型可以表示如下:
假设正多边形的边数为n,边长为a。
则内角度数d的值为:d=(n-2)*180/n
每次旋转的角度为:180-d
抽象与建模
绘制任意正多边形
import turtle as t
n=int(input("输入正多边形的边数:"))
a=int(input("输入正多边形的边长:"))
d=(n-2)*180/n
for i in range(n):
t.forward(a)
t.left(180-d)
t.done()
程序编写
Python 基础
必修一:数据与计算(一轮复习)
算法基础
算法定义与特征
定义:“算法”指的是计算机解决问题的步骤,是为了解决问题而需要让计算机有序执行的,无歧义的,有限步骤的集合。
有穷性
有0个或多个输入
可行性
确定性
有1个或多个输出
算法描述
自然语言
流程图
伪代码
程序设计语言
①输入a、b值
②如果a>b,输出a,否则输出b
输入a、b值
if a>b
输出a
else
输出b
a=float(input("输入a:"))
b=float(input("输入b:"))
if a>b:
print(a)
else:
print(b)
计算机解决问题一般步骤
Python基础
变量与赋值语句
普通赋值:
a=“abc”
增量赋值:
a+=5
序列赋值:
a,b=b,a
连续赋值:
a=b=“abc”
变量:变量是存放数据值的容器
命名规则:
①变量名只能包含字母数字字符和下划线
②不能以数字开头
③变量名不能是关键字
④变量名称区分大小写
(True False)
数据类型
数据类型名 数据表示形式 应用场景
整型(int) 整数:1001B,12D,15H 等 数值运算
实型(float) 实数:3.14,1.2e-5等 数值运算
字符串型(string) 用引号表示,‘123’,“x”,“‘这是一个字符串!’” 字符串提取、切片等操作
布尔型(bool) 结果:true和false,可用于逻辑运算 关系运算、逻辑运算
运算符与优先级
运算符 功能和作用 示例 优先级
( ) 小括号 略 0
** 幂运算 结果为数值型 1
*、/、//、% 乘,除,整除,取余 结果为数值型 2
+、- 加法、减法 结果为数值型 3
<、>、==、 <=、>=、!= 关系运算符 结果为布尔类型 4
in 、not in 存在性判断(关系) 结果为布尔类型 5
not 非 结果为布尔类型 6
and 与 结果为布尔类型 7
or 或 结果为布尔类型 8
表达式
(1)表达式按优先级运算,优先级相同则从左到右
(2)Python中认为 数值0、“”(空字符串)与False等价,非零数和非空字符串与True等价
(3)字符串比较 : 从左到右逐位比较ASCII码值
”123”<”23”=True
(4)数值类型的运算结果保留更精确的值。例1+2.0=3.0
控制结构——选择结构
if <判断条件>:
语句块1
elif <判断条件>:
语句块2
else:
语句块3
if <判断条件>:
语句块
if <判断条件>:
语句块1
else:
语句块2
控制结构——for循环
仅限于次数确定的有限循环
for i in <序列>:
循环体
序列:
①range()
②字符串序列(字符)
③列表序列(元素)
控制结构——循环结构
可用于次数不确定的循环
while 判断语句:
循环体
break:结束并退出当前层循环;
continue:结束当前次循环,进入下一次循环
①判断语句 始终为True(死循环)
②判断语句 始终为False(不循环)
n = 0 # 循环控制变量
while n < 10: # 循环继续的条件
n += 1 # 步长
print(n) # 循环体
控制结构——循环结构
for i in range(1,7):
for j in range(1,7):
if i+j!=6:
_____________
print(i,j)
划线处填break时,输出结果:
5 1
划线处填continue时,输出结果:
1 5
2 4
3 3
4 2
5 1
函数与模块
内建函数
函数 举例
print() 格式化输出:% format
input() 与int\float\split 一起使用
int() int(“123”) int(4.6) int(-4.6)
float() float(“12.3”) float(4)
abs() abs(-5)
len() len(“123”) len([2,[1,2])
str() a=12 str(a) ”12”
chr() chr(48) ”0”
ord() ord(“0”) 48
round() round(4.5) 4
round(5.5) 6
自定义函数
def 函数名 (参数集合):
<函数体>
[return 函数值]
格式:
from math import sqrt
print(isprime(15))
def isprime(n):
for i in range(2,int(sqrt(n)+1)):
if n%i==0:
return False
return Ture
第三方库
调用:先导入,再使用
导入函数
from random import randint
randint(0,9)
导入模块(库)
import random
random.randint(0,9)
math模块
调用:先导入,再使用
名称
math.e
math.pi
math.ceil() math.ceil(2.1)
math.floor() math.floor()
math.pow() math.pow()
math.log()
math.sin()
math.cos()
math.tan()
math.degrees()
math.randians()
random模块
调用:先导入,再使用
名称 作用
random.random() 随机生成一个[0,1)范围内的实数
random. uniform(a,b) 随机生成一个[a,b]范围内的实数
random. randint(a,b) 随机生成一个[a,b]范围内的整数
random.choice(seq) 从序列中随机挑选一个元素
random.sample(seq,k) 从序列中随机挑选k个元素
random.shuffle(seq) 将序列的所有元素随机排序
image模块
from PIL import Image
im=Image.open(“school.jpg”) #打开图像文件
print(im.format) #获取图像文件格式
print(im.size) #获取图像尺寸大小
print(im.mode) #获取图像的颜色模式
im.rotate(45).show() #将图像旋转45°后显示
image模块(P87图像处理案例)
#导入模块
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
#打开图像,生成数字矩阵
img=np.narry(Image.open("lena.jpg").convert("L"))
Numpy模块
NumPy是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
img=np.narry(Image.open("lena.jpg").convert("L"))
165 203 180
198 230 223
102 98 85
[[165,203,180],
[198,230,223],
[102,98,85]]
image模块(P87图像处理案例)
#调整每个像素值
rows,cols=img.shape #图片长宽分别赋值给rows、cols
for i in range(rows): #横坐标
for j in range(cols): #纵坐标
if(img[i,j]>128): #img[I,j] 某一个像素点
img[i,j]=1 #设置为白色
else:
img[i,j]=0 #设置为黑色
#生成新图像并显示
plt.figure("lena")
plt.imshow(img,cmap="gray")
plt.axis("off")
plt.show()
jieba分词模块
函数 对应模式
cuts cut(s,cut_all=False) 精准分词模式:将句子最精确地切分开,不存在冗余。适合于文本分析。
cut(s,cut_all=Ture) 全模式分词:将句子中所有可能是词的词语都切分出来,速度快,但存在冗余。
cut_for_search(s) 搜索引擎模式分词:在精确模式的基础上对长词再进行切分,将更短的词语切分出来。适合于搜索引擎分词。
jieba分词模块
s="我来到了西北皇家理工学院,发现这儿真不错"
seg_list=jieba.cut(s,cut_all=True)
我/来到/了/西北/皇家/理工/理工学/理工学院/工学/工学院/学院/,/发现/这儿/真不/真不错/不错
s="我来到了西北皇家理工学院,发现这儿真不错"
seg_list=jieba.cut(s,cut_all=False)
我/来到/了/西北/皇家/理工学院/,/发现/这儿/真不错
s="我来到了西北皇家理工学院,发现这儿真不错"
seg_list=jieba.cut_for_search(s)
我/来到/了/西北/皇家/理工/工学/学院/理工学/工学院/理工学院/,/发现/这儿/真不错
wordcloud模块
font_path : 设置字体;如:font_path = '黑体.ttf'
width :画布宽度
height : 画布高度
mask : 使用二维遮罩绘制词云
background_color : 设置背景颜色
mode : 设置颜色模式
fit_words(frequencies) :根据词频生成词云
generate(text) :根据文本生成词云
generate_from_frequencies(frequencies[, ...]) :根据词频生成词云
generate_from_text(text) :根据文本生成词云
to_array() :转化为 numpy array
to_file(filename) :输出到文件
wordcloud模块
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
txt = open("你是我的荣耀.txt",'r',encoding='utf-8').read()
words = jieba.cut(txt) #使用jieba库函数分词
counts = {}
for word in words:
if len(word) == 1: #排除长度为1的字符分词结果
continue
else:
counts[word] = counts.get(word,0)+1 #用get方法建立新词
items = list(counts.items()) #将字典中的键值对转为列表
items.sort(key=lambda x:x[1],reverse=True) #按照统计结果降序排序
wordcloud模块
ciyun = []
for i in range(50):
word,count = items[i]
print(word,count)
ciyun.append(word)
text_cut = ' '.join(ciyun) #转为字符串,并用空格分隔
wordscloud = WordCloud(background_color='white',
font_path = '汉仪乐喵体.ttf',
width=1000,height=1000,margin=2).generate(text_cut)
wordscloud.to_file("词云.png")
plt.imshow(wordscloud) #生成图片
plt.axis('off') #关闭坐标轴
plt.show()
#运行结果:
text = open(r‘C:\Users\jjj\Desktop/12.txt’,‘r’).read() #读取一个txt文件
bg_pic = imread(r‘C:\Users\jjj\Desktop/3.png’) #读入背景图片
wordlist_after_jieba = jieba.cut(text, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
#生成词云
font = r'C:\Windows\Fonts\simfang.ttf'
wc = WordCloud(mask=bg_pic,background_color='white',font_path=font,
scale=1.5).generate(wl_space_split) #根据分词结果生成词云
image_colors = ImageColorGenerator(bg_pic)
#显示词云图片
plt.imshow(wc)
plt.axis('off')
plt.show()
# 保存图片
wc.to_file(r'C:\Users\jjj\Desktop/333.jpg')
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(10,10),dpi=80) #创建对象
plt.xlim(0,10) #x轴取值范围
plt.ylim(0,1) #y轴取值范围
plt.xlabel("x")#x轴标签
plt.ylabel("y")#y轴标签
plt.title("sin(x) and cos(x)") #标题
matplotlib模块
x=np.linspace(0,10,100) #产生序列
y1=np.sin(x)
y2=np.cos(x)
plt.scatter(x,y1,label="sin(x)",color="red")
plt.plot(x,y2,label="cos(x)")
plt.legend()
plt.show() #显示图像
matplotlib模块
plot() #线型图
bar() #垂直柱状图
barh() #水平条形图
scatter() #散点图
pie() #饼图
matplotlib模块
Pandas模块
Pandas模块——一维数据结构Series
Series是一维数据结构,包含一个索引列和一个数据列。索引值默认从0开始,也可以指定索引值。
属 性 说 明
index Series的下标索引,默认从0开始的整数
values 存放Series值的一个数组
Series(创建)
import pandas as pd
①通过列表创建
s1=pd.Series([12,13,14],index=["a","b","c"])
print(s1)
②通过字典创建
s1=pd.Series({"a":12,"b":13,"c":14})
print(s1)
Series(访问)
③访问记录
s1[2]、s1[“b”]
④检索满足条件的记录
print(s1[s1>12])
⑤访问连续多条记录
print(s1[0:2])
import pandas as pd
①打印索引
print(s1.index)
②打印值
print(s1.values)
Series(修改)
s1[2]=100
s1[“b”]=100
s1.b=100
Pandas模块——二维数据结构DataFrame
DataFrame是二维数据结构,包含一个索引列和若干数据列。DataFrame是共享一个索引的Series的集合
属 性 说 明
index DataFrame行索引
columns DataFrame列标题
values 存放二维数据
T 行列转置
DataFrame (创建)
①通过列表创建
df=[["小黑",78,90,96],["小灰",90,92,100],["小白",92,95,98]]
df1=pd.DataFrame(df,columns=["姓名","语文","数学","技术"])
DataFrame (创建)
②通过字典创建
df_1= {"姓名":["小黑","小灰","小白"],"语文":[78,90,92],"数学":
[90,92,95],"技术":[96,100,98]}
df2 = pd.DataFrame(df_1)
columns= [“姓名”,“语文”,“数学”,“技术”]
DataFrame (创建)
③读取二维数据文件创建
df = pd.read_excel(“excel文件名")
df = pd.read_csv(“csv文件名")
df= pd.read_txt(“txt文件名")
df=pd.read_table(“txt文件名")
DataFrame (访问)
#修改索引
df1.index = ["01","02","03"]
#输出列标题
print(df1.columns)
#输出值区域
print(df1.values)
DataFrame (访问)
单列 单行 单个值
访问 df1.姓名 df1["姓名"] (属性、列名) df1.loc[0] df1[0:1] (索引) df1.at[0,“姓名"]
at[行,列]
显示
DataFrame (修改)
单列 单行 单个值
修改 df1.姓名=["Abby",'Cici','Jane'] df1.loc[0] df1[0:1]=[“x”,99,99,99] df1.at[0,“姓名”]=“Sunny”
显示
DataFrame (转置、重命名)
转置:df1.T
重命名rename
df1.rename(index={0:"a",1:"b",2:"c"},
columns={“姓名”:“age”})
DataFrame (行、列算术运算)
#求和—sum(axis=0/1)
df1.sum(axis=0)
df1.技术.sum()
df1[“技术”].sum()
axis=0(统计列数据),
axis=1(统计行数据)
2) count #非空数据个数
mean(axis=0/1) #平均值
max(axis=0/1) #统计最大值
min(axis=0/1) #统计最小值
DataFrame (返回行数据)
head(2)
tail(1)
条件筛选
df1[df1.语文>=90])
df1[df1[“语文”]>=90]
DataFrame (删除数据)
df1.drop(“数学”,axis=1)
当要删除列时,axis需要特别设置为1,否则默认0删除的是行
df1.drop(0)
DataFrame (添加数据)
添加列数据——insert
df1.insert(1,"英语",[95,78,85])
添加行数据——append
data2 = {“姓名”:“李四”,”英语”:76“语文”:97,”数学”:88,”技术”:90}
df2 = pd.DataFrame(data2)
print(df1.append(df2,ignore_index=True))
DataFrame (分组)
df1 = pd.DataFrame(data1)
print(df1.groupby(“科目”,as_index=False).sum())
print(df1.groupby("姓名").mean())
DataFrame (排序)
df1.sort_values("成绩",ascending=False,inplace=True)
DataFrame (合并两表)
df3=concat(df1,df2)
DataFrame
import pandas as pd
df = pd.read_excel("成绩单.xls")
df_sort = df.sort_values("信息技术",ascending=False)
df_t = df_sort.head(10)
df_filter = df_t[[“姓名”,“性别”,“信息技术”]] #保留三列内容
df_group = df_filter.groupby("性别",as_index=False) print(df_group.mean())
turtle 模块
turtle库是Python语言中一个很流行的绘制图像的函数库,想象一只小乌龟,在一个横轴为x、纵轴为y的坐标系原点(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行的路径上绘制了图形。
turtle 模块
turtle 库常用函数或命令
函数或命令 说明
forward(distance) 向当前画笔方向移动distance像素长度
backward(distance) 向当前画笔相反方向移动distance像素长度
right(degree) 顺时针移动degree°
left(degree) 逆时针移动degree°
goto(x,y) 将画笔移动到坐标为x,y的位置
circle(r) 画半径为r的圆,半径为正(负),表示圆心在画笔的左边(右边)画圆
fillcolor(colorstring) 绘制图形的填充颜色
color(color1, color2) 同时设置pencolor=color1, fillcolor=color2
done( ) 暂停程序,停止画笔绘制,但绘图窗体不关闭,直到用户关闭Python Turtle图形化窗口为止;它的目的是给用户时间来查看图形,没有它,图形窗口会在程序完成是立即关闭。
turtle 模块
编程1:逆时针方向画一个边长为100的正方形。
import turtle as t
t.forward(100)
t.left(90)
t.forward(100)
t.left(90)
t.forward(100)
t.left(90)
t.forward(100)
t.left(90)
t.done()
import turtle as t
for i in range(4):
t.forward(100)
t.left(90)
t.done()
改为循环结构
turtle 模块
编程2:分别画半径为:5,10,15,…,95,100的20个圆。
import turtle as t
for i in range(5,101,5):
t.circle(i)
t.done()
绘制任意正多边形
正多边形的各边边长相等,各内角度数也相等。因此绘制一个正多边形,可以通过“画一条边,旋转一定角度后再画一条边”的重复操作来完成。如下图是绘制正六边型的过程。
计算模型可以表示如下:
假设正多边形的边数为n,边长为a。
则内角度数d的值为:d=(n-2)*180/n
每次旋转的角度为:180-d
抽象与建模
绘制任意正多边形
import turtle as t
n=int(input("输入正多边形的边数:"))
a=int(input("输入正多边形的边长:"))
d=(n-2)*180/n
for i in range(n):
t.forward(a)
t.left(180-d)
t.done()
程序编写