4.2.1 大数据处理的基本思想与框架 课件 2022—2023学年浙教版(2019)高中信息技术必修1(18张PPT)
文档属性
| 名称 | 4.2.1 大数据处理的基本思想与框架 课件 2022—2023学年浙教版(2019)高中信息技术必修1(18张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 2.6MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2022-12-05 00:00:00 | ||
图片预览




文档简介
(共18张PPT)
4.2.1大数据处理的基本思想与框架
第四章
第四章
目录
分治思想
批处理
流计算
图计算
全球每秒钟发送3百万封电子邮件,一分钟读一篇的话,足够一个人昼夜不息的读5.5 年..
每天会有2.88万个小时的视频上传到Youtube,足够一个人昼夜不息的观看3.3 年...
每个月网民在社交软件上要花费7千亿分钟,被移动互联网使用者发送和接收的数据高达1.3EB...Google.上每天需要处理24PB的数据...
数据体量巨大(Volumme)
速度快(Velocity)
数据类型多(Variety)
价值密度低(Value)
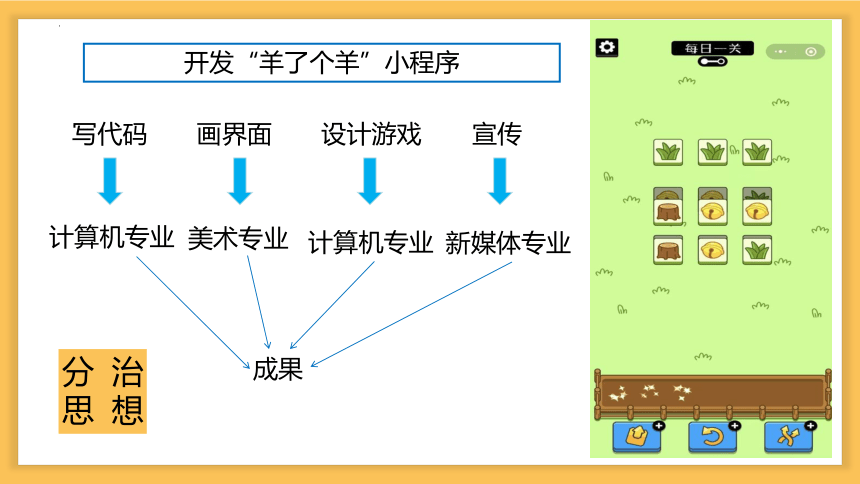
开发“羊了个羊”小程序
写代码
画界面
设计游戏
宣传
计算机专业
美术专业
计算机专业
新媒体专业
成果
分治思想
★ 分——将问题分解为规模更小的子问题
★ 治——将规模更小的子问题逐个击破
★ 合——将已解决的子问题合并,最终得出原问题的解
大数据处理思想——分治
大数据处理分类
大数据
处理
静态数据
流数据
图数据
★静态数据:在处理时已收集完成、在计算式不会发生改变的数据
★流数据:是指不间断地、持续地到达的实时数据,随着时间的流逝,流数据的价值也随之降低,通过实时分析计算可以得到更有价值的分析的结果
★图数据:以社交网络、道路交通等数据为例的众多以图为数据呈现形式的数据,或者转化为图之后再进行分析
静态数据——批处理
Hadoop是一个运行于计算机集群上的分布式系统基础架构,适用于静态数据的批处理计算。
Spark是一种与hadoop相似的,应用较广的开源分布式计算架构。Spark启用了内存存储中间结果,运行速度比hadoop快。
批处理计算
HDFS
数据以文件的形式、用多副本保存在不同的存储节点中,并进行分布式管理
容错性高,可以部署在廉价的机器中
应用:云盘、网盘
HBase
功能:采用基于列的存储方式,用于存储半结构化和非结构化数据,具有良好的横向扩展能力,可管理PB级的大数据, 是BigTable的开源实现。
特点:高可靠、高性能、可伸缩、分布式
Hbase(数据存储与管理)
分布式并行计算模型MapReduce
MapReduce主要用于处理大规模数据集的并行运算,由Map(映射)和Reduce(归纳)两部分组成。
它的核心思想就是将任务分解并发到多个节点上进行处理,最后汇总输出。
批处理计算
大数据处理框架
不间断地、持续地到达的实时数据。流数据的价值会随着时间 的流逝而降低。
对采集的数据实时分析和计算并反馈实时结果。经处理系统处理完成的数据流直接丢弃或存储
用户可以实时查询最新数据分析结果,数据不断更新,实时推荐给用户
流计算应用:广告推送、个性化推荐、实时交通
流计算软件:Storm、Streams、S4、Puma
流数据——流计算
流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据。
用户通过流处理系统获取的一般是实时结果,而传统的数据处理方式获取的都是过去某一个历史时刻的快照。
流处理系统会实时地把生成的结果不断的推动给用户,传统数据需要用户主动查询才能获取数据。
平台的整合缩短了批处理与流处理之间的切换延时时间,有利于减少系统的开销,降低使用成本。
传统数据与流数据
现实世界中以图形式展现的数据。如社交网络、道路交通等。
图处理软件:Pregel、GraphX
图数据——图计算
练一练
1.下列关于流数据的描述不正确的是( )
A.数据在处理时已经采集完成
B.数据价值随着时间的流逝降低
C.实时分析流数据可以得到更有价值的结果
D.可以采用流计算进行实时分析
A
练一练
2.下列关于Hadoop架构的描述正确的是( )
A.是一个对大数据进行聚合式处理的基础软件框架
B.不能运行于大规模计算机集群上
C.采用NTFS文件系统管理数据文件
D.采用MapReduce编程模型处理大规模数据集
D
练一练
3.下列软件主要用于进行流计算的有( )
A.Hadoop B.Storm
C.Pregel D.Spark
B
练一练
4.实时处理与批处理整合的优势有( )
①可以在同一个平台做批处理计算和流计算
②缩短了批处理计算和流计算之间的切换延时
③有利于降低使用成本
④增加了系统开销
A.①②③ B.①②④ C.②③④ D.①③④
A
4.2.1大数据处理的基本思想与框架
第四章
第四章
目录
分治思想
批处理
流计算
图计算
全球每秒钟发送3百万封电子邮件,一分钟读一篇的话,足够一个人昼夜不息的读5.5 年..
每天会有2.88万个小时的视频上传到Youtube,足够一个人昼夜不息的观看3.3 年...
每个月网民在社交软件上要花费7千亿分钟,被移动互联网使用者发送和接收的数据高达1.3EB...Google.上每天需要处理24PB的数据...
数据体量巨大(Volumme)
速度快(Velocity)
数据类型多(Variety)
价值密度低(Value)
开发“羊了个羊”小程序
写代码
画界面
设计游戏
宣传
计算机专业
美术专业
计算机专业
新媒体专业
成果
分治思想
★ 分——将问题分解为规模更小的子问题
★ 治——将规模更小的子问题逐个击破
★ 合——将已解决的子问题合并,最终得出原问题的解
大数据处理思想——分治
大数据处理分类
大数据
处理
静态数据
流数据
图数据
★静态数据:在处理时已收集完成、在计算式不会发生改变的数据
★流数据:是指不间断地、持续地到达的实时数据,随着时间的流逝,流数据的价值也随之降低,通过实时分析计算可以得到更有价值的分析的结果
★图数据:以社交网络、道路交通等数据为例的众多以图为数据呈现形式的数据,或者转化为图之后再进行分析
静态数据——批处理
Hadoop是一个运行于计算机集群上的分布式系统基础架构,适用于静态数据的批处理计算。
Spark是一种与hadoop相似的,应用较广的开源分布式计算架构。Spark启用了内存存储中间结果,运行速度比hadoop快。
批处理计算
HDFS
数据以文件的形式、用多副本保存在不同的存储节点中,并进行分布式管理
容错性高,可以部署在廉价的机器中
应用:云盘、网盘
HBase
功能:采用基于列的存储方式,用于存储半结构化和非结构化数据,具有良好的横向扩展能力,可管理PB级的大数据, 是BigTable的开源实现。
特点:高可靠、高性能、可伸缩、分布式
Hbase(数据存储与管理)
分布式并行计算模型MapReduce
MapReduce主要用于处理大规模数据集的并行运算,由Map(映射)和Reduce(归纳)两部分组成。
它的核心思想就是将任务分解并发到多个节点上进行处理,最后汇总输出。
批处理计算
大数据处理框架
不间断地、持续地到达的实时数据。流数据的价值会随着时间 的流逝而降低。
对采集的数据实时分析和计算并反馈实时结果。经处理系统处理完成的数据流直接丢弃或存储
用户可以实时查询最新数据分析结果,数据不断更新,实时推荐给用户
流计算应用:广告推送、个性化推荐、实时交通
流计算软件:Storm、Streams、S4、Puma
流数据——流计算
流处理系统处理的是实时的数据,而传统的数据处理系统处理的是预先存储好的静态数据。
用户通过流处理系统获取的一般是实时结果,而传统的数据处理方式获取的都是过去某一个历史时刻的快照。
流处理系统会实时地把生成的结果不断的推动给用户,传统数据需要用户主动查询才能获取数据。
平台的整合缩短了批处理与流处理之间的切换延时时间,有利于减少系统的开销,降低使用成本。
传统数据与流数据
现实世界中以图形式展现的数据。如社交网络、道路交通等。
图处理软件:Pregel、GraphX
图数据——图计算
练一练
1.下列关于流数据的描述不正确的是( )
A.数据在处理时已经采集完成
B.数据价值随着时间的流逝降低
C.实时分析流数据可以得到更有价值的结果
D.可以采用流计算进行实时分析
A
练一练
2.下列关于Hadoop架构的描述正确的是( )
A.是一个对大数据进行聚合式处理的基础软件框架
B.不能运行于大规模计算机集群上
C.采用NTFS文件系统管理数据文件
D.采用MapReduce编程模型处理大规模数据集
D
练一练
3.下列软件主要用于进行流计算的有( )
A.Hadoop B.Storm
C.Pregel D.Spark
B
练一练
4.实时处理与批处理整合的优势有( )
①可以在同一个平台做批处理计算和流计算
②缩短了批处理计算和流计算之间的切换延时
③有利于降低使用成本
④增加了系统开销
A.①②③ B.①②④ C.②③④ D.①③④
A