4.2.2.1.2DataFrame 课件 2022—2023学年浙教版(2019)高中信息技术必修1(52张PPT)
文档属性
| 名称 | 4.2.2.1.2DataFrame 课件 2022—2023学年浙教版(2019)高中信息技术必修1(52张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 3.1MB | ||
| 资源类型 | 教案 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2022-12-05 00:00:00 | ||
图片预览





文档简介
(共52张PPT)
第4章 数据 处理与应用
浙教版 信息技术(高中)
必修1 数据与计算
4.2.2.1.2 DataFrame
学习目标
1
2
3
4
大数据处理的基本思想
批处理计算和流计算、图计算,编程处理数据
文本数据处理,文本数据分析与应用
数据可视化
1
2
重点难点
重点:大数据处理的思想和编程处理数据。
难点:编程处理数据。
s1=pd.Series({“s01”:166,“s02”:178,“s03”:180},index = [“s02”,“s04”])
Series回忆
import pandas as pd
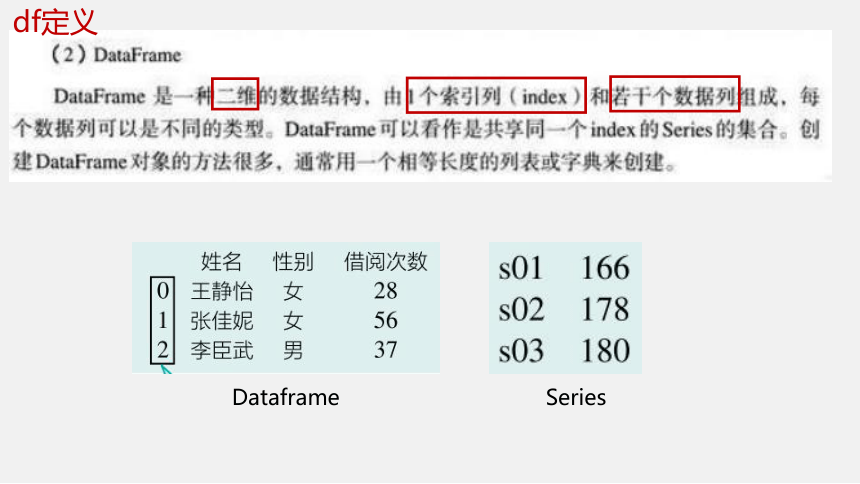
Dataframe
Series
df定义
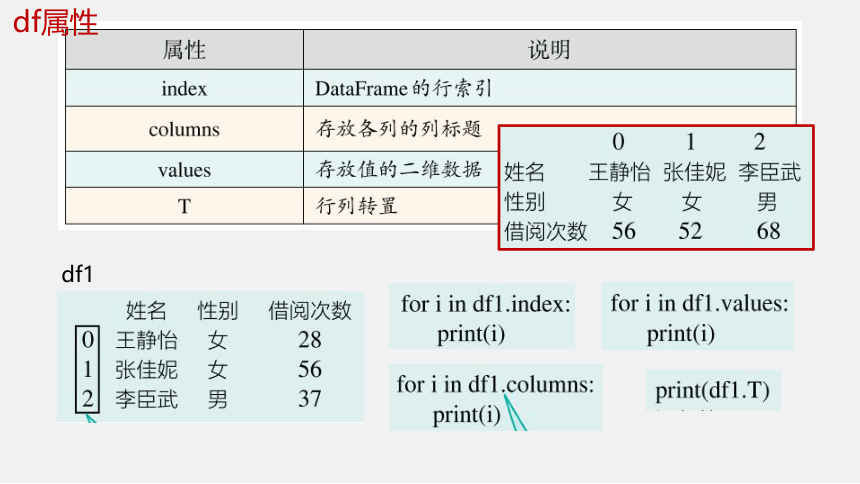
df1
df属性
data=[["王静怡",28],["张佳妮",56],["李臣武",37]]
df1=pd.DataFrame(data,columns=["姓名","借阅次数"])
data = {“姓名”:pd.Series([“王静怡”,“张佳妮”,“李臣武”],index=[“a”,“b”,“c”]),“借阅次数”:pd.Series([28,56,37],index=[“b”,“c”,“d”])}
df1=pd.DataFrame(data)
df2=pd.DataFrame(data,index = [‘d’,‘c’,‘b’])
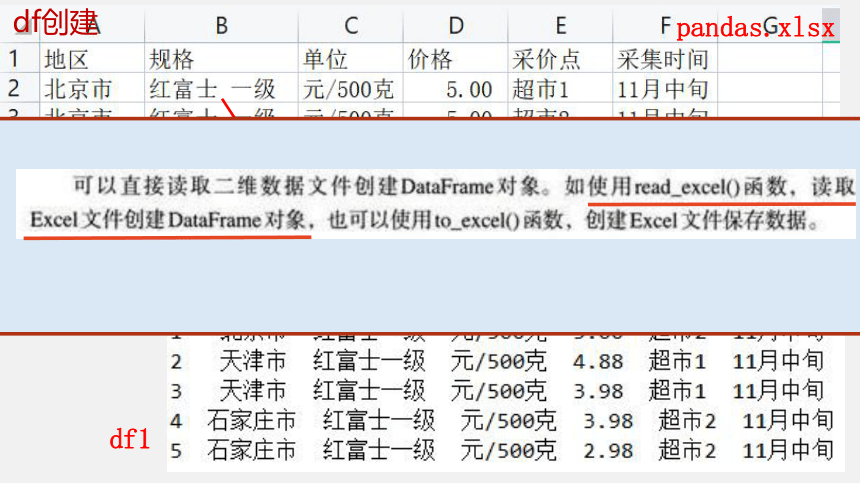
df创建
df练习
pandas.xlsx
df1
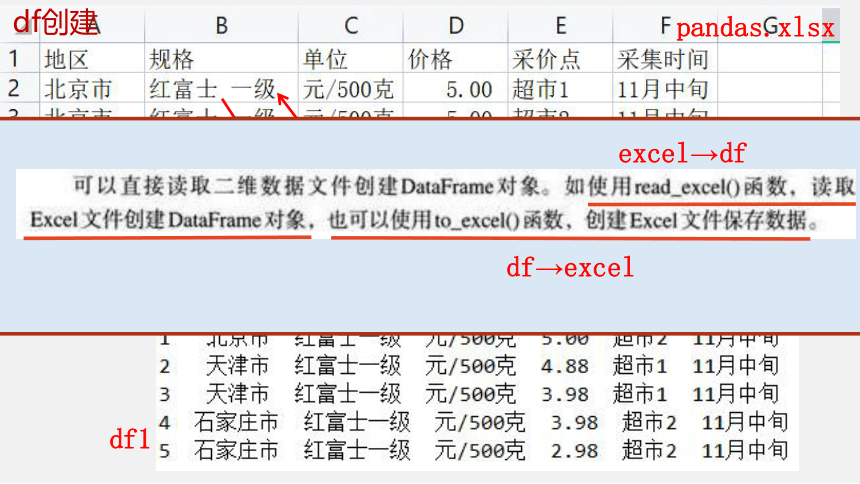
df创建
excel→df
df→excel
pandas.xlsx
df1
df创建
csv→df pd.read_csv()
逗号作为分隔符
pandas.csv
df1
df→csv pd.to_csv()
df创建
索引1列数据:
索引1行数据:只能切片
df1[1]
×
df1[1:2]
索引1个数据:
df1.at[行,列]
df1[列][行]
df1
df索引
筛选出采价点为超市1的商品
30
52
68
df修改
count() 返回每一行/列的非N个数
1、获取各产品的最高价、最低价和平均价
df1.max():每一列的最大值
df1.max(axis=1):每一行的最大值
1、获取各产品的最高价、最低价和平均价
df_max=df1.max()
df_min=df1.min()
df_mean=df1.mean()
1、获取各门科目的最高分和最低分
2、获取李四的总分
df1
deseribe() 返回各列的基本描述统计值,包含计数、平均数、标准差、最大值、最小值及4分位差
2、获取每个地区所产苹果的平均价格
groupby() 对各列或各行中的数据进行分组。
然后可对其中每一组数据进行不同的操作
df_mean=df1.mean()
2、获取每个地区所产苹果的平均价格
df_mean=df1.mean()
df_m=df1.groupby(“地区”).mean()
df_m=df1.groupby(“地区”).mean()
df_m=df1.groupby(“地区”,as_index=False).mean()
某DataFrame对象df,包含"准考证号""学校""姓名""数学""语文"等数据列,下列语句中,可以以学校为单位,统计出各校学生"数学"成绩平均值的有( )
①df.groupby('学校").mean()
②df.groupby('数学').mean()
③df.groupby('学校').数学.mean()
④df.groupby('学校').describe()
A. ①②③ B.①②④ C.①③④ D.②③④
C
3、获取价格最高的2个产品信息
df_max=df1.max()
3、获取价格最高的2个产品信息
3、获取价格最高的2个产品信息
df_s=df1.sort_values(“价格”)
3、获取价格最高的2个产品信息
df_s=df1.sort_values(“价格”)
df_t=df1.sort_values(“价格”).tail(2)
3、获取价格最高的2个产品信息
df_t=df1.sort_values(“价格”).tail(2)
df_h=df1.sort_values(“价格”,ascending=False).head(2)
将三个人按照语文成绩降序排序
4、删除第1个商品信息以及数据列“规格”
5、将df2加到df1下面
df_a=df1.append(df2)
df1
df2
df_a=df1.append(df2,ignore_index=True)
6
7
df_a=df1.append(df2,ignore_index=True,inplace=True)
A
小李将 2022 年北京冬奥会的奖牌榜保存在 Excel 工作簿“2022BJ.xlsx”文件中
(1)在 Excel 软件中打开“2022BJ.xlsx”文件,为了计算各国的奖牌总数,小李先在 F2 单元 格中利用求和函数得出挪威的奖牌总数,然后利用填充柄完成区域 F3:F30 的各国奖牌总数的计 算,则在 F4 单元格中中国的奖牌总数的计算公式是_________。
=SUM(C4:E4)
(2)为了提高效率,小李利用 Python 编程对 Excel 工作簿文件进行数据分析,设计如下 Python程序代码,请根据要求在划线处填入合适的代码或完成相应操作的选择。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图形中的中文正常编码显示
df=pd.read_excel("__________________") # 读取 Excel 文件
print(______________________________________________________)
# 筛选出金牌数前 10 名(即顺序号小于等于 10)的记录并打印
dfs= ______________________________________________________
# 筛选出奖牌总数前 10 名的记录,并按从高到低排序输出给 dfs
print(dfs) # 打印 dfs
2022BJ.xlsx
df[df.顺序<=10]或者df[df["顺序"]<=10]
df.sort_values(“金牌”,ascending=False).head(10)
df.sort_values(“金牌”,ascending=False)[:10]
(2)为了提高效率,小李利用 Python 编程对 Excel 工作簿文件进行数据分析,设计如下 Python程序代码,请根据要求在划线处填入合适的代码或完成相应操作的选择。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图形中的中文正常编码显示
df=pd.read_excel("__________________") # 读取 Excel 文件
print(______________________________________________________)
# 筛选出金牌数前 10 名(即顺序号小于等于 10)的记录并打印
dfs= ______________________________________________________
# 筛选出奖牌总数前 10 名的记录,并按从高到低排序输出给 dfs
print(dfs) # 打印 dfs
2022BJ.xlsx
df[df.顺序<=10]或者df[df["顺序"]<=10]
df.sort_values(“金牌”,ascending=False).head(10)
df.sort_values(“金牌”,ascending=True).tail(10)
(2)为了提高效率,小李利用 Python 编程对 Excel 工作簿文件进行数据分析,设计如下 Python程序代码,请根据要求在划线处填入合适的代码或完成相应操作的选择。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图形中的中文正常编码显示
df=pd.read_excel("__________________") # 读取 Excel 文件
print(______________________________________________________)
# 筛选出金牌数前 10 名(即顺序号小于等于 10)的记录并打印
dfs= ______________________________________________________
# 筛选出奖牌总数前 10 名的记录,并按从高到低排序输出给 dfs
print(dfs) # 打印 dfs
2022BJ.xlsx
df[df.顺序<=10]或者df[df["顺序"]<=10]
df.sort_values(“金牌”,ascending=False).head(10)
dfs=df.sort_values("奖牌总数",ascending=True)[:-11:-1]
某年全国主要农产品生产价格指数数据表如图a所示。
(1)制作某年全国主要农产品生产价格季平均的图表如图b所示。该图表类型是________。(填:线型图/垂直柱形图/水平柱形图/散点图)
垂直柱形图
(2)实现的代码如下,请在画线处填上合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['Simhei']#支持中文显示
df=pd.read_excel(”月考14.xlsx”)
#在df对象中添加一列”季平均”,值为四季度平均值
df[”季平均”]=①________________
#按照”季平均”对df对象进行降序排序
②________________
df.mean(axis=1)
df_sort=df.sort_values(”季平均”,ascending=False)
(3)若现要在上述程序基础上对df对象按“类别”分组并求出每列最大值并存入df_gpb,请补充完整下列语句实现该功能
df.groupby(”类别”).max()
s3=pd.Series({“s01”:166,“s02”:178,“s03”:180},index = [“s02”,“s04”])
Series创建
import pandas as pd
s1=pd.Series([166,178,180])
s2=pd.Series({“s01”:166,“s02”:178,“s03”:180})
Series引用
166
166和178
166和180
s2
大于170的?
Series修改
166和178改成170和180
s2
Series运算
s1
s3
s1+s3
df创建
data=[[20,30],[40,50],[60,70]]
df1=pd.DataFrame(data,columns=["a","b"])
筛选出采价点为超市1的商品
df引用
将pandas.xlsx转变为df1
df函数
求平均价格
求各个地区的平均价格
求价格最高的两个商品
df函数
将df2添加到df1下面
df函数
删除“单位”列,第3行
df函数
count()
describe()
rename()
insert()
concat()
谢 谢!
Thanks!
第4章 数据 处理与应用
浙教版 信息技术(高中)
必修1 数据与计算
4.2.2.1.2 DataFrame
学习目标
1
2
3
4
大数据处理的基本思想
批处理计算和流计算、图计算,编程处理数据
文本数据处理,文本数据分析与应用
数据可视化
1
2
重点难点
重点:大数据处理的思想和编程处理数据。
难点:编程处理数据。
s1=pd.Series({“s01”:166,“s02”:178,“s03”:180},index = [“s02”,“s04”])
Series回忆
import pandas as pd
Dataframe
Series
df定义
df1
df属性
data=[["王静怡",28],["张佳妮",56],["李臣武",37]]
df1=pd.DataFrame(data,columns=["姓名","借阅次数"])
data = {“姓名”:pd.Series([“王静怡”,“张佳妮”,“李臣武”],index=[“a”,“b”,“c”]),“借阅次数”:pd.Series([28,56,37],index=[“b”,“c”,“d”])}
df1=pd.DataFrame(data)
df2=pd.DataFrame(data,index = [‘d’,‘c’,‘b’])
df创建
df练习
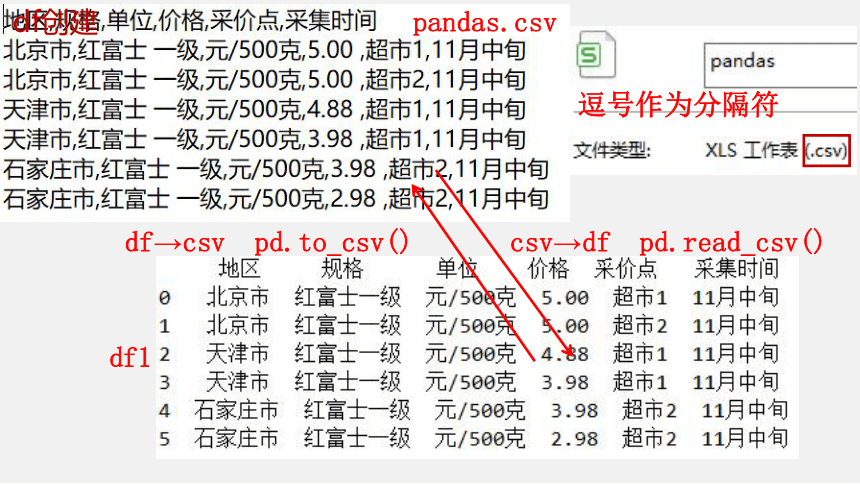
pandas.xlsx
df1
df创建
excel→df
df→excel
pandas.xlsx
df1
df创建
csv→df pd.read_csv()
逗号作为分隔符
pandas.csv
df1
df→csv pd.to_csv()
df创建
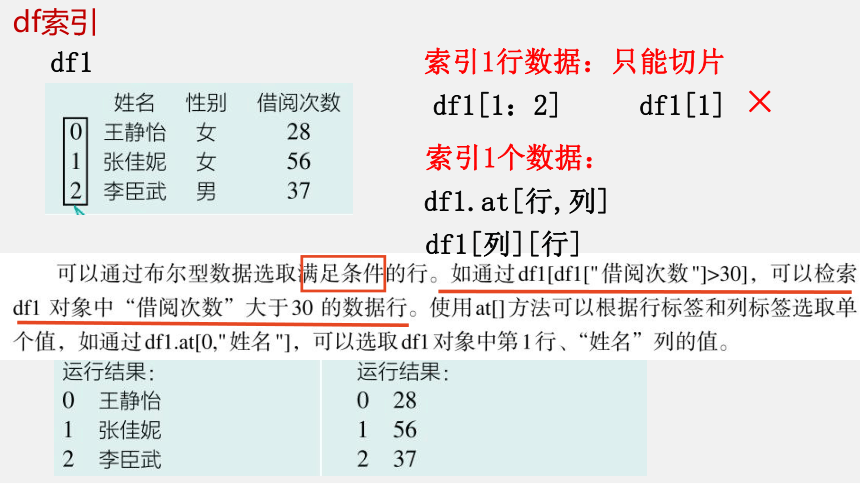
索引1列数据:
索引1行数据:只能切片
df1[1]
×
df1[1:2]
索引1个数据:
df1.at[行,列]
df1[列][行]
df1
df索引
筛选出采价点为超市1的商品
30
52
68
df修改
count() 返回每一行/列的非N个数
1、获取各产品的最高价、最低价和平均价
df1.max():每一列的最大值
df1.max(axis=1):每一行的最大值
1、获取各产品的最高价、最低价和平均价
df_max=df1.max()
df_min=df1.min()
df_mean=df1.mean()
1、获取各门科目的最高分和最低分
2、获取李四的总分
df1
deseribe() 返回各列的基本描述统计值,包含计数、平均数、标准差、最大值、最小值及4分位差
2、获取每个地区所产苹果的平均价格
groupby() 对各列或各行中的数据进行分组。
然后可对其中每一组数据进行不同的操作
df_mean=df1.mean()
2、获取每个地区所产苹果的平均价格
df_mean=df1.mean()
df_m=df1.groupby(“地区”).mean()
df_m=df1.groupby(“地区”).mean()
df_m=df1.groupby(“地区”,as_index=False).mean()
某DataFrame对象df,包含"准考证号""学校""姓名""数学""语文"等数据列,下列语句中,可以以学校为单位,统计出各校学生"数学"成绩平均值的有( )
①df.groupby('学校").mean()
②df.groupby('数学').mean()
③df.groupby('学校').数学.mean()
④df.groupby('学校').describe()
A. ①②③ B.①②④ C.①③④ D.②③④
C
3、获取价格最高的2个产品信息
df_max=df1.max()
3、获取价格最高的2个产品信息
3、获取价格最高的2个产品信息
df_s=df1.sort_values(“价格”)
3、获取价格最高的2个产品信息
df_s=df1.sort_values(“价格”)
df_t=df1.sort_values(“价格”).tail(2)
3、获取价格最高的2个产品信息
df_t=df1.sort_values(“价格”).tail(2)
df_h=df1.sort_values(“价格”,ascending=False).head(2)
将三个人按照语文成绩降序排序
4、删除第1个商品信息以及数据列“规格”
5、将df2加到df1下面
df_a=df1.append(df2)
df1
df2
df_a=df1.append(df2,ignore_index=True)
6
7
df_a=df1.append(df2,ignore_index=True,inplace=True)
A
小李将 2022 年北京冬奥会的奖牌榜保存在 Excel 工作簿“2022BJ.xlsx”文件中
(1)在 Excel 软件中打开“2022BJ.xlsx”文件,为了计算各国的奖牌总数,小李先在 F2 单元 格中利用求和函数得出挪威的奖牌总数,然后利用填充柄完成区域 F3:F30 的各国奖牌总数的计 算,则在 F4 单元格中中国的奖牌总数的计算公式是_________。
=SUM(C4:E4)
(2)为了提高效率,小李利用 Python 编程对 Excel 工作簿文件进行数据分析,设计如下 Python程序代码,请根据要求在划线处填入合适的代码或完成相应操作的选择。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图形中的中文正常编码显示
df=pd.read_excel("__________________") # 读取 Excel 文件
print(______________________________________________________)
# 筛选出金牌数前 10 名(即顺序号小于等于 10)的记录并打印
dfs= ______________________________________________________
# 筛选出奖牌总数前 10 名的记录,并按从高到低排序输出给 dfs
print(dfs) # 打印 dfs
2022BJ.xlsx
df[df.顺序<=10]或者df[df["顺序"]<=10]
df.sort_values(“金牌”,ascending=False).head(10)
df.sort_values(“金牌”,ascending=False)[:10]
(2)为了提高效率,小李利用 Python 编程对 Excel 工作簿文件进行数据分析,设计如下 Python程序代码,请根据要求在划线处填入合适的代码或完成相应操作的选择。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图形中的中文正常编码显示
df=pd.read_excel("__________________") # 读取 Excel 文件
print(______________________________________________________)
# 筛选出金牌数前 10 名(即顺序号小于等于 10)的记录并打印
dfs= ______________________________________________________
# 筛选出奖牌总数前 10 名的记录,并按从高到低排序输出给 dfs
print(dfs) # 打印 dfs
2022BJ.xlsx
df[df.顺序<=10]或者df[df["顺序"]<=10]
df.sort_values(“金牌”,ascending=False).head(10)
df.sort_values(“金牌”,ascending=True).tail(10)
(2)为了提高效率,小李利用 Python 编程对 Excel 工作簿文件进行数据分析,设计如下 Python程序代码,请根据要求在划线处填入合适的代码或完成相应操作的选择。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使图形中的中文正常编码显示
df=pd.read_excel("__________________") # 读取 Excel 文件
print(______________________________________________________)
# 筛选出金牌数前 10 名(即顺序号小于等于 10)的记录并打印
dfs= ______________________________________________________
# 筛选出奖牌总数前 10 名的记录,并按从高到低排序输出给 dfs
print(dfs) # 打印 dfs
2022BJ.xlsx
df[df.顺序<=10]或者df[df["顺序"]<=10]
df.sort_values(“金牌”,ascending=False).head(10)
dfs=df.sort_values("奖牌总数",ascending=True)[:-11:-1]
某年全国主要农产品生产价格指数数据表如图a所示。
(1)制作某年全国主要农产品生产价格季平均的图表如图b所示。该图表类型是________。(填:线型图/垂直柱形图/水平柱形图/散点图)
垂直柱形图
(2)实现的代码如下,请在画线处填上合适的代码。
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['Simhei']#支持中文显示
df=pd.read_excel(”月考14.xlsx”)
#在df对象中添加一列”季平均”,值为四季度平均值
df[”季平均”]=①________________
#按照”季平均”对df对象进行降序排序
②________________
df.mean(axis=1)
df_sort=df.sort_values(”季平均”,ascending=False)
(3)若现要在上述程序基础上对df对象按“类别”分组并求出每列最大值并存入df_gpb,请补充完整下列语句实现该功能
df.groupby(”类别”).max()
s3=pd.Series({“s01”:166,“s02”:178,“s03”:180},index = [“s02”,“s04”])
Series创建
import pandas as pd
s1=pd.Series([166,178,180])
s2=pd.Series({“s01”:166,“s02”:178,“s03”:180})
Series引用
166
166和178
166和180
s2
大于170的?
Series修改
166和178改成170和180
s2
Series运算
s1
s3
s1+s3
df创建
data=[[20,30],[40,50],[60,70]]
df1=pd.DataFrame(data,columns=["a","b"])
筛选出采价点为超市1的商品
df引用
将pandas.xlsx转变为df1
df函数
求平均价格
求各个地区的平均价格
求价格最高的两个商品
df函数
将df2添加到df1下面
df函数
删除“单位”列,第3行
df函数
count()
describe()
rename()
insert()
concat()
谢 谢!
Thanks!