浙教版必修一4.2.1 大数据处理的基本思想与架构 课件
文档属性
| 名称 | 浙教版必修一4.2.1 大数据处理的基本思想与架构 课件 |

|
|
| 格式 | pptx | ||
| 文件大小 | 7.2MB | ||
| 资源类型 | 试卷 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2023-02-21 00:00:00 | ||
图片预览




文档简介
(共18张PPT)
第四章 数据处理与应用
4.2 大数据处理
4.2.1 大数据处理的基本思想与架构
学习目标
了解大数据处理架构和基本思路。
了解静态数据、流数据和图数据三者的区别。
大数据具有数据量大、数据来源于类型多样、处理速度快等特点,简单的表格处理软件已经无法满足大数据的处理需求,同时,大数据技术、理论和处理方法也在不断发展,为大数据的处理提供了越来越有力的支持。
医疗大数据可视化
处理大数据时,一般采用分治思想(“分而治之”)。
分--将问题分解为规模更小的子问题
治--将规模更小的子问题逐个击破解决
合--将已解决的子问题合并,最终得出原问题的解
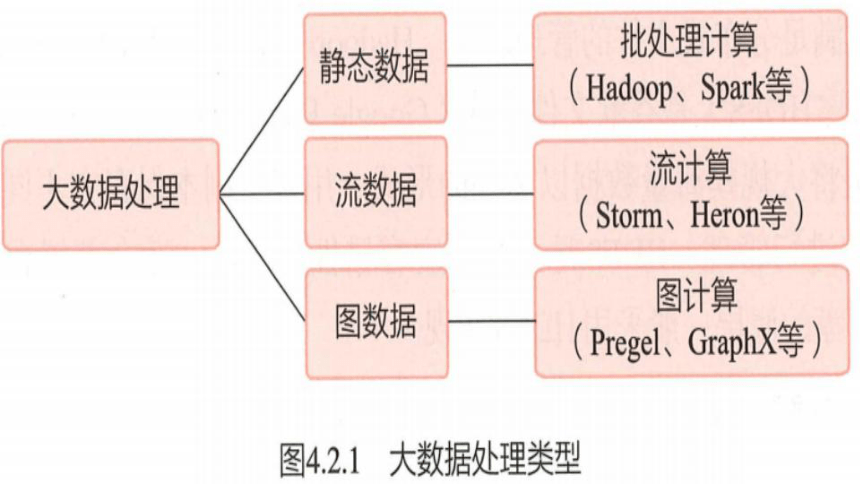
大数据处理按照类型可划分为对静态数据的批处理、对流数据的实时计算和对图结构数据的图计算。
静态数据--指在处理时已收集完成、在计算时不会发生改变的数据,一般采用批处理方式;
流数据--指不间断地、持续地到达的实时数据,随着时间的流逝,流数据的价值也随之降低,通过实时分析计算可以得到更有价值的分析结果;
图数据--现实世界中的许多数据,如社交网络、道路交通等数据,可采用图计算模式进行处理。
知识点一:批处理计算(静态数据:处理时已收集完成、在计算时不会发生改变的数据)
新课讲授
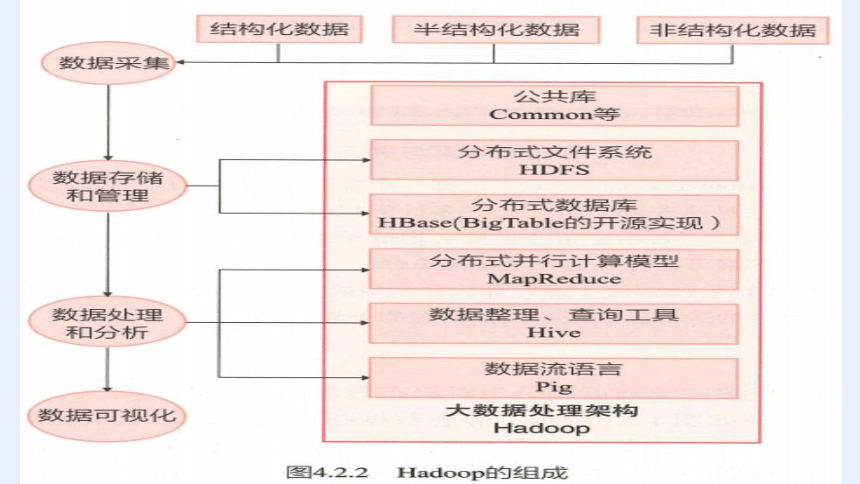
Hadoop:是一个可运行于大规模计算机集群上的分布式系统基础架构,适用于静态数据的批处理计算。
Spark:与Hadoop相似,启用了内存存储中间结果,运行速度比Hadoop快很多。
(1)分布式文件系统HDFS
是谷歌文件系统(GFS)的开源实现。
主要功能:将大规模海量数据以文件的形式、用多个副本保存在不同的存储节点中,并用分布式系统进行管理。
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。比如:云盘、网盘的底层一般采用HDFS实现。
(2)分布式数据库HBase
是一个高可靠、高性能、可伸缩、分布式的列式数据库,是谷歌BigTable数据库的开源实现。
HBase建立在HDFS提供的底层存储基础上,采用基于列的存储方式,主要用来存储非结构化数据和半结构化数据。
(3)分布式并行计算模型MapReduce
主要由Map(映射)和Reduce(归纳)2个函数构成。
二、流计算(流数据:不间断地、持续地到达的实时数据)
主要的流计算软件系统:
IBM InfoSphere Streams(捕获和分析动态数据)
Twitter Storm(推特风暴)
Yahoo!S4(雅虎分布式流计算)
淘宝(银河流数据处理平台)
Facebook Puma
Heron(是Storm的替代产品)
三、图计算(图数据:以图的形式呈现的,或者是可以转换为图以后再进行分析的数据,如社交网络、网络浏览与购买行为、传染病的传播路径等。)
目前通用的图处理软件主要包括两类:
四、实时处理与批处理的整合
Twitter开源了大数据处理系统Summingbird,该系统实现了批处理与流计算在一个平台架构下的整合。平台的整合缩短了批处理与流处理之间的切换延时时间,有利于减少系统的开销,降低使用成本。
小节:
数据整理的目的:是检测和修正错漏的数据、整合数据资源、规整数据格式、提高数据质量。
常见的数据问题:数据缺失、数据重复、数据异常、逻辑错误、格式不一致等。
数据计算:Excel软件中,公式以“=”开头,由常数、函数、单元格引用和运算符组成的式子(公式不仅用于计算,更重要的是构建计算模型)。
数据图表呈现:1.分析数据;2.创建图表(柱形图、折线图、饼图、雷达图、散点图、气泡图等);3.检查图表。
1.下列关于流数据的描述不正确的是( )
A.数据在处理时已收集完成
B.数据价值随着时间的流逝降低
C.实时分析流数据可以得到更有价值的分析结果
D.可以采用流计算进行实时分析
随堂练习
A
2. 下列关于Hadoop架构的描述正确的是( )
A.是一个对大数据进行聚合式处理的基础架构
B.不能运行于大规模计算机集群上
C.采用NTFS文件系统管理数据文件
D.采用MapReduce编程模型处理大规模数据集
D
3.下列软件主要用于进行流计算的有( )
A.GraphX
B.Storm
C.Pregel
D.Spark
B
4.实时处理与批处理整合的优势有( )
①在同一个平台既可以做批处理,也可以做流计算
②缩短了批处理与流处理之间的切换延时时间
③有利于降低使用成本
④增加系统开销
A.①②③
B.①②④
C.②③④
D.①③④
A
第四章 数据处理与应用
4.2 大数据处理
4.2.1 大数据处理的基本思想与架构
学习目标
了解大数据处理架构和基本思路。
了解静态数据、流数据和图数据三者的区别。
大数据具有数据量大、数据来源于类型多样、处理速度快等特点,简单的表格处理软件已经无法满足大数据的处理需求,同时,大数据技术、理论和处理方法也在不断发展,为大数据的处理提供了越来越有力的支持。
医疗大数据可视化
处理大数据时,一般采用分治思想(“分而治之”)。
分--将问题分解为规模更小的子问题
治--将规模更小的子问题逐个击破解决
合--将已解决的子问题合并,最终得出原问题的解
大数据处理按照类型可划分为对静态数据的批处理、对流数据的实时计算和对图结构数据的图计算。
静态数据--指在处理时已收集完成、在计算时不会发生改变的数据,一般采用批处理方式;
流数据--指不间断地、持续地到达的实时数据,随着时间的流逝,流数据的价值也随之降低,通过实时分析计算可以得到更有价值的分析结果;
图数据--现实世界中的许多数据,如社交网络、道路交通等数据,可采用图计算模式进行处理。
知识点一:批处理计算(静态数据:处理时已收集完成、在计算时不会发生改变的数据)
新课讲授
Hadoop:是一个可运行于大规模计算机集群上的分布式系统基础架构,适用于静态数据的批处理计算。
Spark:与Hadoop相似,启用了内存存储中间结果,运行速度比Hadoop快很多。
(1)分布式文件系统HDFS
是谷歌文件系统(GFS)的开源实现。
主要功能:将大规模海量数据以文件的形式、用多个副本保存在不同的存储节点中,并用分布式系统进行管理。
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。比如:云盘、网盘的底层一般采用HDFS实现。
(2)分布式数据库HBase
是一个高可靠、高性能、可伸缩、分布式的列式数据库,是谷歌BigTable数据库的开源实现。
HBase建立在HDFS提供的底层存储基础上,采用基于列的存储方式,主要用来存储非结构化数据和半结构化数据。
(3)分布式并行计算模型MapReduce
主要由Map(映射)和Reduce(归纳)2个函数构成。
二、流计算(流数据:不间断地、持续地到达的实时数据)
主要的流计算软件系统:
IBM InfoSphere Streams(捕获和分析动态数据)
Twitter Storm(推特风暴)
Yahoo!S4(雅虎分布式流计算)
淘宝(银河流数据处理平台)
Facebook Puma
Heron(是Storm的替代产品)
三、图计算(图数据:以图的形式呈现的,或者是可以转换为图以后再进行分析的数据,如社交网络、网络浏览与购买行为、传染病的传播路径等。)
目前通用的图处理软件主要包括两类:
四、实时处理与批处理的整合
Twitter开源了大数据处理系统Summingbird,该系统实现了批处理与流计算在一个平台架构下的整合。平台的整合缩短了批处理与流处理之间的切换延时时间,有利于减少系统的开销,降低使用成本。
小节:
数据整理的目的:是检测和修正错漏的数据、整合数据资源、规整数据格式、提高数据质量。
常见的数据问题:数据缺失、数据重复、数据异常、逻辑错误、格式不一致等。
数据计算:Excel软件中,公式以“=”开头,由常数、函数、单元格引用和运算符组成的式子(公式不仅用于计算,更重要的是构建计算模型)。
数据图表呈现:1.分析数据;2.创建图表(柱形图、折线图、饼图、雷达图、散点图、气泡图等);3.检查图表。
1.下列关于流数据的描述不正确的是( )
A.数据在处理时已收集完成
B.数据价值随着时间的流逝降低
C.实时分析流数据可以得到更有价值的分析结果
D.可以采用流计算进行实时分析
随堂练习
A
2. 下列关于Hadoop架构的描述正确的是( )
A.是一个对大数据进行聚合式处理的基础架构
B.不能运行于大规模计算机集群上
C.采用NTFS文件系统管理数据文件
D.采用MapReduce编程模型处理大规模数据集
D
3.下列软件主要用于进行流计算的有( )
A.GraphX
B.Storm
C.Pregel
D.Spark
B
4.实时处理与批处理整合的优势有( )
①在同一个平台既可以做批处理,也可以做流计算
②缩短了批处理与流处理之间的切换延时时间
③有利于降低使用成本
④增加系统开销
A.①②③
B.①②④
C.②③④
D.①③④
A