浙教版 信息技术 必修1 4.2 大数据处理 课件(共35张PPT)
文档属性
| 名称 | 浙教版 信息技术 必修1 4.2 大数据处理 课件(共35张PPT) |

|
|
| 格式 | pptx | ||
| 文件大小 | 8.0MB | ||
| 资源类型 | 试卷 | ||
| 版本资源 | 浙教版(2019) | ||
| 科目 | 信息技术(信息科技) | ||
| 更新时间 | 2021-03-01 00:00:00 | ||
图片预览









文档简介
第4章 数据 处理与应用
浙教版 信息技术(高中)
必修1 数据与计算
4.2 大数据处理
学习目标
1
2
3
4
大数据处理的基本思想
批处理计算和流计算、图计算,编程处理数据
文本数据处理,文本数据分析与应用
数据可视化
1
2
重点难点
重点:大数据处理的思想和编程处理数据。
难点:编程处理数据。
课堂导入
大数据具有数据量大、数据来源与类型多样、处理速度快等特点,简单的表格处理软件已经无法满足大数据的处理需求,同时,大数据技术、理论和处理方法也在不断发展,为大数据的处理提供了越来越有力的支持。
4.2.1大数据处理的基本思想与架构
处理大数据时,一般采用分治思想。就是把一个复杂的问题分成两个或更多相同的可相似的子问题,找到求这几个子问题的解法后,再找出合适的方法把它们组合成求整个问题的解法。
统计文件filename中各单词出现的频率,用python编程实现的代码如下:
wordcount={}
for word in open(filename,’r’).read():
wordcount[word]+=1
拓展链接
分布式计算与并行处理
分布式计算(Distributed Computing)是把一个需要非常巨大的计算能力才能解决的问题分成许多小部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果。例如,利用分布在世界各地成千上万台闲置计算机的计算能力,分析来自外太空的电讯号,探索可能存在的外星智慧生命。
并行处理(Parallel Processing)是计算机系统中能同时执行两个或更多处理的一种计算方法。并行处理的主要目的是节省大型和复杂问题的处理时间。
大数据处理
静态数据
流数据
图数据
批处理计算(Hadoop、spark等)
流计算(storm、heron等)
图计算(pregel、graphx等)
图4.2.1 大数据处理类型
1、批处理计算
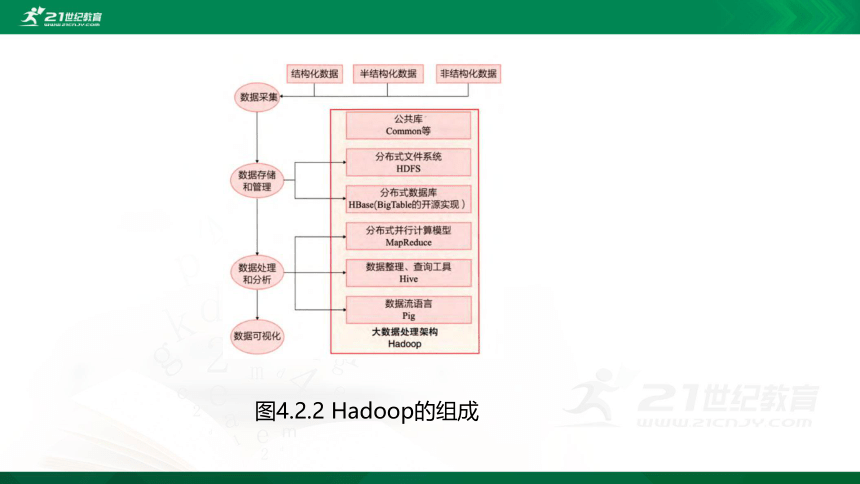
Hadoop是一个运行于计算机集群上的分布式系统基础架构,适用于静态数据
的批处理计算。
Spark是一种与hadoop相似的,应用较广的开源分布式计算架构。Spark
启用了内存存储中间结果,运行速度比hadoop快。
图4.2.2 Hadoop的组成
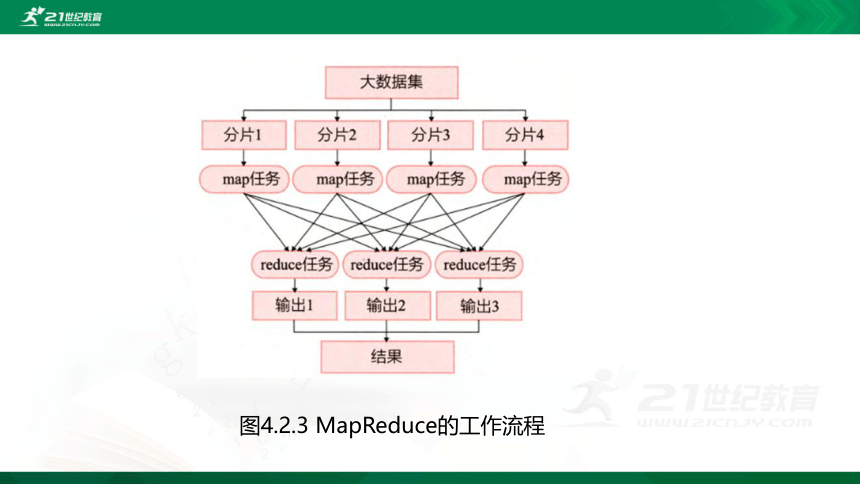
图4.2.3 MapReduce的工作流程
拓展链接:
Hadoop的发展历史
Hadoop最早起源于Nutch项目。Nutch是一个开源的网络搜索引擎,由Doug Cutting于2002年创建。随着网页数量的增加,项目组遇到了数十亿网页的存储和索引问题。
2003年底,谷歌发表了关于谷歌分布式文件系统的论文。该论文描述了谷歌搜索引擎网页相关数据的存储架构,该架构可解决Nutch 遇到的网页抓取和索引过程中产生的超大文件存储需求问题。由于谷歌仅开源了思想而未开源代码,Nutch项目组便根据论文开源实现了Nutch的分布式文件系统(NDFS).
2004年,谷歌发表了关于谷歌分布式计算框架MapReduce的论文,该框架可用于处理海量网页的索引问题。Nutch的开发人员依据论文完成了MapReduce的开源实现。
2006年初,NDFS和MapReduce从Nutch项目分离,Doug Cutting用儿子的棕黄色大象玩具的名字为项目起名为Hadoop.同年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2008年1月,Hadoop成为Apache顶级项目,迎来了它的快速发展期。
2.流计算
图4.2.4 流计算的发展
图4.2.5 Twitter的分层数据处理架构
拓展链接
主要的流计算软件系统
目前,处理流数据的软件系统主要有IBM InfoSphere Streams、Twitter Storm、Yahoo!S4、银河流数据处理平台(淘宝)、Facebook Puma等。Storm和S4是目前较为流行的开源分布式实时计算系统。Heron是Storm的替代产品,其外部接口和Storm保持兼容,在流数据处理性能方面与Storm相比有了大幅提升。
3、图计算
图4.2.6 蛋白质激素构成图(由2.7万个节点和794万条边组成)
目前通用的图处理软件主要包括两类:一类是图数据库,如Neo4j、InfiniGraph、OrientDB等;加一类是并行图处理系统,如Google Pregel、Apache Giraph等
4、实时处理与批处理的整合
2014年9月,大数据处理系统summingbird,它实现了批处理和流计算的整合(Hadoop+storm)。
结合生活实践,查找资料,列举静态数据、
流数据处理实例。
问题与讨论:
Hadoop应用实例:
北京城市数据映像-流动的城市
“北京城市数据映像”项目采集了北京市地铁一卡
通数据、出租车GPS定位轨迹数据、移动手机基站定
位、地理位置微博数据、工商业POI地点等约2TB的数
据。数据计算平台采用了服务器集群、Hadoop和HBase
架构。
通过收集北京市各相关行业的数据,运用大数据分
析和可视化表达技术,将城市的发展和变化过程变得直
观、透明和可视。大数据分析为城市管理提供了技术支
撑,是发现、分析城市问题的新思维和技术方法。
拓展链接
4.2.2 编程处理数据
1、利用pandas模块处理数据
Pandas 提供了series和DataFrame两种数据结构,这两种数据结构可完成
数据的整理、计算、统计、分析及简单可视化。
import pandas as pd
(1)series(一维)
S1=pd.series([166,178,180])
Print(s1)
运行结果:
0 166
1 178
2 180
dtype:int64
S1=pd.series([166,178,180])
Print(s1)
运行结果:
0 166
1 178
2 180
dtype:int64
创建1个series结构类型的对象s1,存储3名同学的身高值。
例2 查看例1中s1对象的index、values属性值。
for i in s1.index:
print(i)
运行结果:
0
1
2
for i in s1.values:
print(i)
运行结果:
166
178
180
for i in s1:
print(i)
运行结果:
166
178
180
(2)dataFrame(二维)
例3 使用相等长度列表的字典构建一个DataFrame对象dfl,存储3名同学的姓名、性别、图书借阅次数数据。
import pandas as pd
data=(“姓名”:[“王静怡”,“张佳妮”,“李臣武”],”性别”:[“女”,“女”,“男”],”借阅次数”:[28, 56, 37])
dfl=pd. DataFrame(data,columns=["姓名",“性别",“借阅次数"])
print (df1)
运行结果:
设定dfl中数据列的顺序
姓名 性别 借阅次数
0 王静怡 女 28
1 张佳妮 女 56
2 李臣武 男 37
例4
读取Excel文件“test.xlsx”中的数据,创建DataFrame对象df。
import pandas as pd
df=pd.read_excel ("test.xlsx")
print (df)
运行结果:
地区 规格 单位 价格 采价点 采集时间
0 北京市 红富士一级 元/500克 2.98 超市2 11月中旬
1 北京市 红富士一级 元/500克 4.88 超市1 11月中旬
2 天津市 红富士一级 元/500克 5.00 超市1 11月中旬
3 天津市 红富士一级 元/500克 5.00 超市2 11月中旬
石家庄市 红富士一级 元/500克 3.98 超市1 11月中旬
石家庄市 红富士一级 元/500克 3.98 超市2 11月中旬
例5 查看df1对象的索引、列标题、值,并将行、列转置。
for i in df1.index:
print(i)
运行结果:
0
1
2
for i in df1.columns:
print(i)
运行结果:
姓名
性别
借阅次数
for i in df1.index:
print(i)
运行结果:
[‘王静怡’‘女’56]
[‘张佳怩’‘女’52]
[‘李臣武’‘男’68]
Df1.T #转置行、列
运行结果:
0 1 2
姓名 王静怡 张佳怡 李臣武
性别 女 女 男
借阅次数 56 52 68
2.利用matplotlib模块绘图
表4.2.4 常用绘图函数
例10 绘制正弦曲线图
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace (0, 10, 1000)
yl=np.sin (x)
y2=np.sin (x**2)
plt.figure (figsize= (8, 4) ) #创建图表对象
plt.title (“sin (x) and sin (x**2) ”) #设置图表标题文字
plt.plot (x,y1,label=“sin (x) ”,color=“r”,linewidth=2) #绘制线形图
plt.scatter (x,y2,label="sin (x**2) ") #绘制散点图
plt.ylim (-1. 5, 1. 5) #设置y坐标轴的取值范围
plt.xlim (0, 10) #设置x坐标轴的取值范围
plt.legend() #显示图例
plt.show ()
图4.2.9 正弦图
4.2.3 文本数据处理
1、文本数据的一般过程
图4.2.13 典型的文本处理过程
文本数据源
分词
特征提取
数据分析
结果呈现
2、文本数据分析与应用
(1)标签云
(2)文本情感分析
图4.2.16 城市心情
拓展链接
图4.2.17 某语文作文智能阅卷流程
4.2.4 数据可视化
图4.2.20 国家统计局分析大陆总人口情况
图4.2.21 用户满意度和收货天数关系图
图4.2.22 卡特里娜飓风路径图
谢 谢!
Thanks!
https://www.21cnjy.com/help/help_extract.php
浙教版 信息技术(高中)
必修1 数据与计算
4.2 大数据处理
学习目标
1
2
3
4
大数据处理的基本思想
批处理计算和流计算、图计算,编程处理数据
文本数据处理,文本数据分析与应用
数据可视化
1
2
重点难点
重点:大数据处理的思想和编程处理数据。
难点:编程处理数据。
课堂导入
大数据具有数据量大、数据来源与类型多样、处理速度快等特点,简单的表格处理软件已经无法满足大数据的处理需求,同时,大数据技术、理论和处理方法也在不断发展,为大数据的处理提供了越来越有力的支持。
4.2.1大数据处理的基本思想与架构
处理大数据时,一般采用分治思想。就是把一个复杂的问题分成两个或更多相同的可相似的子问题,找到求这几个子问题的解法后,再找出合适的方法把它们组合成求整个问题的解法。
统计文件filename中各单词出现的频率,用python编程实现的代码如下:
wordcount={}
for word in open(filename,’r’).read():
wordcount[word]+=1
拓展链接
分布式计算与并行处理
分布式计算(Distributed Computing)是把一个需要非常巨大的计算能力才能解决的问题分成许多小部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果。例如,利用分布在世界各地成千上万台闲置计算机的计算能力,分析来自外太空的电讯号,探索可能存在的外星智慧生命。
并行处理(Parallel Processing)是计算机系统中能同时执行两个或更多处理的一种计算方法。并行处理的主要目的是节省大型和复杂问题的处理时间。
大数据处理
静态数据
流数据
图数据
批处理计算(Hadoop、spark等)
流计算(storm、heron等)
图计算(pregel、graphx等)
图4.2.1 大数据处理类型
1、批处理计算
Hadoop是一个运行于计算机集群上的分布式系统基础架构,适用于静态数据
的批处理计算。
Spark是一种与hadoop相似的,应用较广的开源分布式计算架构。Spark
启用了内存存储中间结果,运行速度比hadoop快。
图4.2.2 Hadoop的组成
图4.2.3 MapReduce的工作流程
拓展链接:
Hadoop的发展历史
Hadoop最早起源于Nutch项目。Nutch是一个开源的网络搜索引擎,由Doug Cutting于2002年创建。随着网页数量的增加,项目组遇到了数十亿网页的存储和索引问题。
2003年底,谷歌发表了关于谷歌分布式文件系统的论文。该论文描述了谷歌搜索引擎网页相关数据的存储架构,该架构可解决Nutch 遇到的网页抓取和索引过程中产生的超大文件存储需求问题。由于谷歌仅开源了思想而未开源代码,Nutch项目组便根据论文开源实现了Nutch的分布式文件系统(NDFS).
2004年,谷歌发表了关于谷歌分布式计算框架MapReduce的论文,该框架可用于处理海量网页的索引问题。Nutch的开发人员依据论文完成了MapReduce的开源实现。
2006年初,NDFS和MapReduce从Nutch项目分离,Doug Cutting用儿子的棕黄色大象玩具的名字为项目起名为Hadoop.同年2月,Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2008年1月,Hadoop成为Apache顶级项目,迎来了它的快速发展期。
2.流计算
图4.2.4 流计算的发展
图4.2.5 Twitter的分层数据处理架构
拓展链接
主要的流计算软件系统
目前,处理流数据的软件系统主要有IBM InfoSphere Streams、Twitter Storm、Yahoo!S4、银河流数据处理平台(淘宝)、Facebook Puma等。Storm和S4是目前较为流行的开源分布式实时计算系统。Heron是Storm的替代产品,其外部接口和Storm保持兼容,在流数据处理性能方面与Storm相比有了大幅提升。
3、图计算
图4.2.6 蛋白质激素构成图(由2.7万个节点和794万条边组成)
目前通用的图处理软件主要包括两类:一类是图数据库,如Neo4j、InfiniGraph、OrientDB等;加一类是并行图处理系统,如Google Pregel、Apache Giraph等
4、实时处理与批处理的整合
2014年9月,大数据处理系统summingbird,它实现了批处理和流计算的整合(Hadoop+storm)。
结合生活实践,查找资料,列举静态数据、
流数据处理实例。
问题与讨论:
Hadoop应用实例:
北京城市数据映像-流动的城市
“北京城市数据映像”项目采集了北京市地铁一卡
通数据、出租车GPS定位轨迹数据、移动手机基站定
位、地理位置微博数据、工商业POI地点等约2TB的数
据。数据计算平台采用了服务器集群、Hadoop和HBase
架构。
通过收集北京市各相关行业的数据,运用大数据分
析和可视化表达技术,将城市的发展和变化过程变得直
观、透明和可视。大数据分析为城市管理提供了技术支
撑,是发现、分析城市问题的新思维和技术方法。
拓展链接
4.2.2 编程处理数据
1、利用pandas模块处理数据
Pandas 提供了series和DataFrame两种数据结构,这两种数据结构可完成
数据的整理、计算、统计、分析及简单可视化。
import pandas as pd
(1)series(一维)
S1=pd.series([166,178,180])
Print(s1)
运行结果:
0 166
1 178
2 180
dtype:int64
S1=pd.series([166,178,180])
Print(s1)
运行结果:
0 166
1 178
2 180
dtype:int64
创建1个series结构类型的对象s1,存储3名同学的身高值。
例2 查看例1中s1对象的index、values属性值。
for i in s1.index:
print(i)
运行结果:
0
1
2
for i in s1.values:
print(i)
运行结果:
166
178
180
for i in s1:
print(i)
运行结果:
166
178
180
(2)dataFrame(二维)
例3 使用相等长度列表的字典构建一个DataFrame对象dfl,存储3名同学的姓名、性别、图书借阅次数数据。
import pandas as pd
data=(“姓名”:[“王静怡”,“张佳妮”,“李臣武”],”性别”:[“女”,“女”,“男”],”借阅次数”:[28, 56, 37])
dfl=pd. DataFrame(data,columns=["姓名",“性别",“借阅次数"])
print (df1)
运行结果:
设定dfl中数据列的顺序
姓名 性别 借阅次数
0 王静怡 女 28
1 张佳妮 女 56
2 李臣武 男 37
例4
读取Excel文件“test.xlsx”中的数据,创建DataFrame对象df。
import pandas as pd
df=pd.read_excel ("test.xlsx")
print (df)
运行结果:
地区 规格 单位 价格 采价点 采集时间
0 北京市 红富士一级 元/500克 2.98 超市2 11月中旬
1 北京市 红富士一级 元/500克 4.88 超市1 11月中旬
2 天津市 红富士一级 元/500克 5.00 超市1 11月中旬
3 天津市 红富士一级 元/500克 5.00 超市2 11月中旬
石家庄市 红富士一级 元/500克 3.98 超市1 11月中旬
石家庄市 红富士一级 元/500克 3.98 超市2 11月中旬
例5 查看df1对象的索引、列标题、值,并将行、列转置。
for i in df1.index:
print(i)
运行结果:
0
1
2
for i in df1.columns:
print(i)
运行结果:
姓名
性别
借阅次数
for i in df1.index:
print(i)
运行结果:
[‘王静怡’‘女’56]
[‘张佳怩’‘女’52]
[‘李臣武’‘男’68]
Df1.T #转置行、列
运行结果:
0 1 2
姓名 王静怡 张佳怡 李臣武
性别 女 女 男
借阅次数 56 52 68
2.利用matplotlib模块绘图
表4.2.4 常用绘图函数
例10 绘制正弦曲线图
import numpy as np
import matplotlib.pyplot as plt
x=np.linspace (0, 10, 1000)
yl=np.sin (x)
y2=np.sin (x**2)
plt.figure (figsize= (8, 4) ) #创建图表对象
plt.title (“sin (x) and sin (x**2) ”) #设置图表标题文字
plt.plot (x,y1,label=“sin (x) ”,color=“r”,linewidth=2) #绘制线形图
plt.scatter (x,y2,label="sin (x**2) ") #绘制散点图
plt.ylim (-1. 5, 1. 5) #设置y坐标轴的取值范围
plt.xlim (0, 10) #设置x坐标轴的取值范围
plt.legend() #显示图例
plt.show ()
图4.2.9 正弦图
4.2.3 文本数据处理
1、文本数据的一般过程
图4.2.13 典型的文本处理过程
文本数据源
分词
特征提取
数据分析
结果呈现
2、文本数据分析与应用
(1)标签云
(2)文本情感分析
图4.2.16 城市心情
拓展链接
图4.2.17 某语文作文智能阅卷流程
4.2.4 数据可视化
图4.2.20 国家统计局分析大陆总人口情况
图4.2.21 用户满意度和收货天数关系图
图4.2.22 卡特里娜飓风路径图
谢 谢!
Thanks!
https://www.21cnjy.com/help/help_extract.php